EJB3.1 - La persistance en Java
EJB3.1 - La persistance en Java
 Au sein d'une architecture Java EE, les EJB sont utilisés pour créer les services. Cette technologie ne s'arrête cependant pas à cette couche, mais permet aussi de créer l'abstraction de l'accès aux données. Ce sont les entités qui remplissent cette fonction.
Au sein d'une architecture Java EE, les EJB sont utilisés pour créer les services. Cette technologie ne s'arrête cependant pas à cette couche, mais permet aussi de créer l'abstraction de l'accès aux données. Ce sont les entités qui remplissent cette fonction.
Tout comme les beans sessions, entre le client et la logique métier, les beans entités forment la passerelle entre la logique applicative et les sources de données. Ils offrent une abstraction quasi complète du stockage des données, permettant à l'application de rendre persistantes ou de charger des données de manière totalement transparente.
Les applications d'entreprise sont composées d'une logique métier, d'interactions avec d'autres systèmes, d'interfaces utilisateur et ... de persistance. La plupart des données manipulées par les applications doivent être stockées dans des bases de données afin de pouvoir être ensuite récupérées et analysées.
Les bases de données sont importantes :
Les données persistantes sont omniprésentes - la plupart du temps, elles utilisent les bases de données relationnelles comme moteur sous-jacent. Dans un système de gestion de base de données relationnelles (SGBD), les données sont organisées en tables formées de lignes et de colonnes ; elles sont identifiées par des clés primaires (des colonnes spéciales ne contenant que des valeurs uniques) et, parfois, par des index. Les relations entre tables utilisent les clés étrangères et joignent les tables en respectant des contraintes d'intégrité.
Pour en savoir plus sur les SGBD.
Tout ce vocabulaire est totalement étranger à un langage orienté objet comme Java. En Java, nous manipulons des objets qui sont des instances de classes ; les objets héritent les uns des autres, peuvent utiliser des collections d'autres objets et, parfois, se désignent eux-mêmes de façon récursive. Nous disposons de classes concrètes, de classes abstraites, d'interfaces, d'énumérations, d'annotations, de méthodes, d'attributs, etc.
Cependant, bien que les objets encapsulent soigneusement leur état et leur comportement, cet état n'est accessible que lorsque la machine virtuelle (JVM) s'exécute : lorsqu'elle s'arrête ou que le ramasse-miettes nettoie la mémoire, tout disparaît. Ceci dit, certains objets n'ont pas besoin d'être persistants.
Par données persistantes, nous désignons les données qui sont délibérément stockées de façon permanente sur un support magnétique, une mémoire flash, etc. Un objet est persistant s'il peut stocker son état afin de pouvoir le réutiliser par la suite.
Il existe différent moyens de faire persister l'état en Java. L'un d'eux consiste à utiliser le mécanisme de sérialisation qui consiste à convertir un objet en une suite de bits : nous pouvons ainsi sérialiser les objets sur disque, sur une connexion réseau (notamment Internet), sous un format indépendant des systèmes d'exploitation. Java fournit un mécanisme simple, transparent et standard de sérialisation des objets via l'implémentation de l'interface java.io.Serializable. Cependant, bien qu'elle soit très simple, cette technique est assez fruste : elle ne fournit ni le langage d'interrogation ni support des accès concurrents intensifs ou de mise en cluster.
Pour en savoir plus sur la sérialisation.
.
Un autre moyen de mémoriser l'état consiste à utiliser JDBC (Java Database Connectivity), qui est l'API standard pour accéder aux bases de données relationnelles. Nous pouvons ainsi nous connecter à une base et exécuter des requêtes SQL (Structured Query Language) pour récupérer un résultat. Cette API fait partie de la plate-forme Java depuis la version 1.1 mais, bien qu'elle soit toujours très utilisée, elle a tendance à être désormais éclipsée par les outils de correspondance entre modèle objet et modèle relationnel (ORM, Object-Relational Mapping), plus puissant.
Pour en savoir plus sur JDBC.
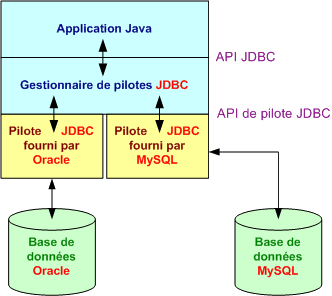
Le principe d'un ORM consiste à déléguer l'accès aux bases de données relationnelles à des outils ou des frameworks externes qui produisent une vue orientée objet des données relationnelles et vice versa. Ces outils établissent donc une correspondance bidirectionnelle entre la base et les objets.
Différents frameworks fournissent ce service, notamment Hibernate, TopLink et Java Data Objects (JDO), mais il est préférable d'utiliser JPA (Java Persistence API) car elle est directement intégrée à Java EE 6.
JPA 1.0 a été créée avec Java EE 5 pour résoudre le problème de la persistance des données en reliant les modèles objets et relationnels. Avec Java EE 6, JPA 2.0 conserve la simplicité et la robustesse de la version précédente tout en lui ajoutant de nouvelles fonctionnalités. Grâce à cette API, vous pouvez accéder à des données relationnelles et les manipuler à partir des EJB (Entreprise Java Beans), des composants web ou même des applications Java SE.
JPA est une couche d'abstraction au-dessus de JDBC, qui fournit une indépendance vis-à-vis de SQL. Toutes les classes et annotations de cette API se trouvent dans le paquetage javax.persistence.
Ses composants principaux sont les suivants :
Cette seconde version ajoute de nouvelles API, étend JPQL et intègre de nouvelles fonctionnalités :
L'implémentation de référence de JPA est EclipseLink, anciennement TopLink d'Oracle. Ce framework est à la fois souple et puissant. Il supporte la persistance XML au travers de JAXB (Java XML Binding). Il est également désigné sous les termes de fournisseur de persistance ou, simplement, de fournisseur. Il offre un ORM, un OXM (Object XML Mapping) et la persistance des objets sur EIS (Enterprise Information Systems) à l'aide de JCA (Java EE Connector Architecture).
Les beans entités ont été créés pour simplifier la gestion des données au niveau d'une application, mais aussi pour faciliter la sauvegarde en base de données. Plus concrètement, ces beans entités vous permettent de prendre en charge la persistance des données de votre application dans une ou plusieurs des sources de données, tout en gardant les relations entre celles-ci.
Ces composants établissent donc la relation entre votre application et vos bases de données. Contrairement aux beans sessions, les données d'un bean entité sont conservées, même après l'arrêt de l'application.
Les données de l'application sont typiquement : des utilisateurs, des factures, des produits, des adresses, des informations sur une image, ... Dans le monde de Java, et plus généralement dans le monde objet, il est commun d'utiliser des classes pour chacun des types d'objets utilisés. On parle souvent d'objet métier ou entité (Entity) pour représenter les caractéristiques de ces objets.
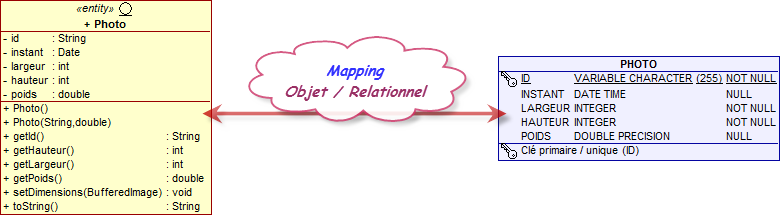
La liaison entre les données et l'application par un objet s'appelle le mapping (relier). On parle de mapping Objet/Relationnel lorsque nous nous connectons, de cette manière, une base de donnée avec une application objet.
Attention : l'utilisation des beans entités permet de représenter une entité de l'application et non une fonctionnalité. Par exemple, Photo est un bean entité, mais StockerPhoto serait plutôt un bean session ; une photo étant vouée à rester persistante (garder un état particulier pendant un bon moment), alors que le stockage effectif de la photo est une opération, qui par définition est de courte durée.
Contrairement au bean session, les données du bean entité ont donc généralement une durée de vie longue ; elles sont enregistrées et stockées dans des systèmes de persistance (base de données).
Lorsque nous évoquons l'association d'objets à une base de données relationnelle, la persistance des objets ou les requêtes adressées aux objets, il est préférable d'utiliser le terme d'entités plutôt que celui d'objets.
Ces derniers sont des instances qui existent en mémoire ; les entités sont des objets qui ont une durée de vie limitée en mémoire et qui par contre persistent (longuement) dans une base de données. Les entités peuvent être associées à une base de données, être concrètes ou abstraites, elles disposent de l'héritage, peuvent être mise en relation, etc.
Le principe d'un ORM consiste à déléguer à des outils ou des frameworks externes (JPA, dans notre cas) la création d'une correspondance entre les objets et les tables. Le monde des classes, des objets et des attributs peut alors être associé aux bases de données constituées de tables formées de lignes et de colonnes. Cette association offre une vue orientée objet aux développeurs, qui peuvent alors utiliser de façon transparente des entités à la place des tables.
Ainsi, l'objet à rendre persistant, via un mapping Objet/Relationnel, correspond à une table de la base de données.
Chaque propriété de cet objet est liée à un champ de la table.
Chaque instance de cet objet représente généralement un enregistrement (une ligne) de la table.
Après toutes ces considérations techniques, je vous propose de voir comment créer notre propre bean entité Photo qui va permettre de rendre persistant un certain nombre d'informations relatives au stockage d'une photo. Dans le code suivant, vous remarquez que sur notre entité Photo, quelques attributs sont annotés (id, instant) alors que d'autres ne le sont pas.
import java.awt.image.BufferedImage; import java.util.Date; import javax.persistence.*; @Entity public class Photo { @Id private String id; @Temporal(TemporalType.TIMESTAMP) private Date instant; @Column(nullable = false) private int largeur; @Column(nullable = false) private int hauteur; private long poids; public String getId() { return id; } public int getHauteur() { return hauteur; } public Date getInstant() { return instant; } public int getLargeur() { return largeur; } public long getPoids() { return poids; } public Photo() { } public Photo(String nom, long poids) { id = nom; instant = new Date(); this.poids = poids; } public void setDimensions(BufferedImage image) { largeur = image.getWidth(); hauteur = image.getHeight(); } @Override public String toString() { return id++largeur++hauteur+; } }
@Entity public class Photo { @Id @GeneratedValue private String id; ... }
JPA permet de faire correspondre les entités à des bases de données et de les interroger en utilisant différents critères. La puissance de cette API vient du fait qu'elle offre la possibilité d'interroger les entités et leurs relations de façon orientée objet sans devoir utiliser les clés étrangères ou les colonnes de la base de données sous-jacentes.
L'élément central de l'API, responsable de l'orchestration des entités, est le gestionnaire d'entité : son rôle consiste à gérer les entités, à lire et à écrire dans une base de données et à autoriser les opérations CRUD simples sur les entités, ainsi que des requêtes complexes avec JPQL.
@Stateless public class Archiver { private final String répertoire = ; @PersistenceContext (unitName="Photos-ejbPU") // s'il existe une seule unité de persistance, la désignation de son nom n'est pas obligatoire EntityManager persistance; public void stocker(String nom, byte[] octets) throws IOException { File fichier = new File(répertoire+nom); if (fichier.exists()) return; FileOutputStream flux = new FileOutputStream(fichier); flux.write(octets); flux.close(); BufferedImage image = ImageIO.read(fichier); Photo photo = new Photo(nom, fichier.length()); photo.setDimensions(image); persistance.persist(photo); } ... }
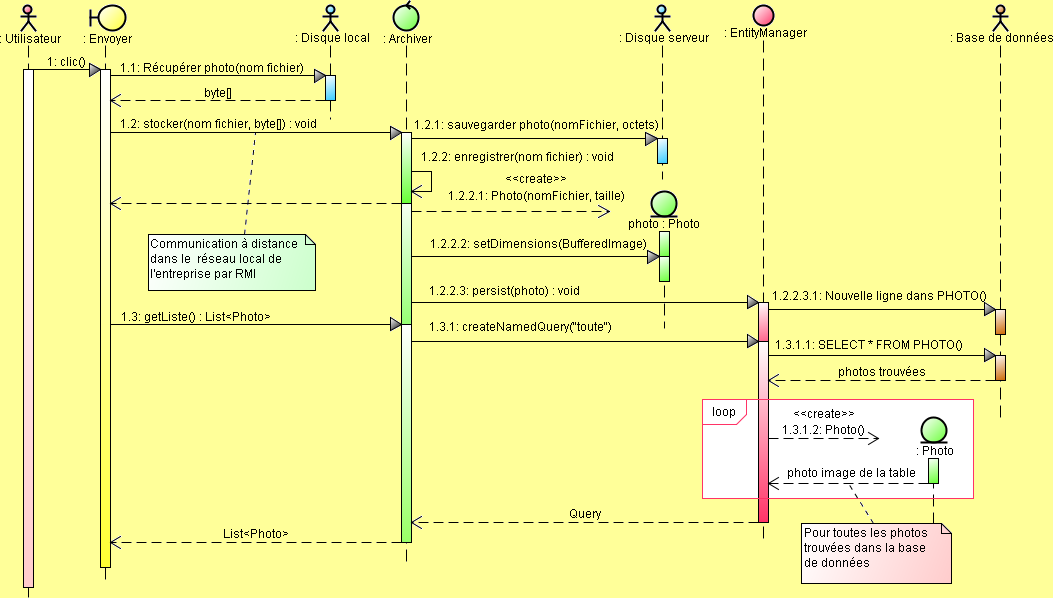
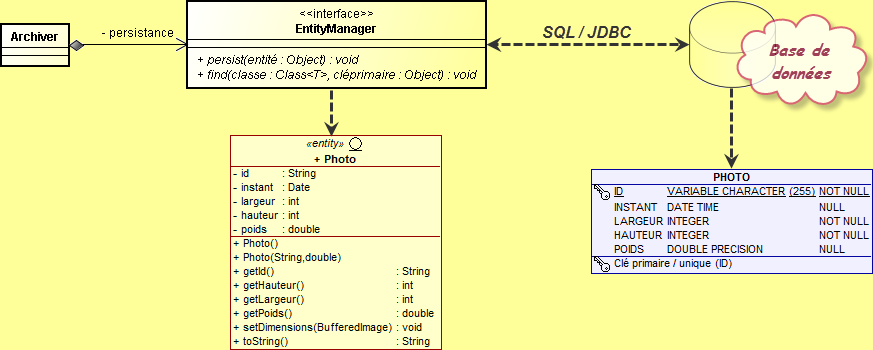
La figure suivante montre comment l'interface EntityManager peut être utilisée par notre bean session Archiver pour manipuler l'entité Photo :
Voici une autre portion de code qui montre comment créer l'unité de persistence Photos-ejbPU, au travers cette fois-ci d'une simple application Java SE (standalone) sans passer par un bean session intermédiaire :
11 import javax.persistence.*; 12 13 public class Visionneuse extends JFrame implements ActionListener { 14 private static FichiersPhotoRemote fichiers; 15 private static EntityManagerFactory fabrique; 16 private static EntityManager persistance; ... 25 private Photo photo; ... 80 public static void main(String[] args) throws Exception { 81 Context ctx = new InitialContext(); 82 fichiers = (FichiersPhotoRemote) ctx.lookup(photos.FichiersPhotoRemote.class.getName()); 83 fabrique = Persistence.createEntityManagerFactory("Photos-ejbPU"); 84 persistance = fabrique.createEntityManager(); 85 persistance.getTransaction().begin(); 86 new Visionneuse(); 87 } ...
Le gestionnaire d'entités permet également d'interroger les entités. Dans ce cas, une requête JPA est semblable à une requête sur une base de données, sauf qu'elle utilise JPQL au lieu de SQL. La syntaxe utilise la notation pointée habituelle. Pour récupérer, par exemple toutes les photos enregistrées, il suffirait d'écrire :
SELECT photo FROM Photo AS photo
Une instruction JPQL peut exécuter des requêtes dynamiques (créées à l'exécution), des requêtes statiques (définies lors de la compilation), voire des instructions SQL natives. Les requêtes statiques, également appelées requêtes nommées, sont définies par des annotations directement sur le bean entité.
L'instruction JPQL précédente peut, par exemple, être définie comme une requête nommée sur l'entité Photo :
@Entity @NamedQuery(name=, query=) public class Photo { @Id private String id; ... }
A l'aide de la méthode createNamedQuery() de EntityManager nous permet d'exécuter la requête nommée et nous renvoie ainsi la liste des photos correspondant aux critères de recherche, c'est-à-dire toutes les photos stockées :
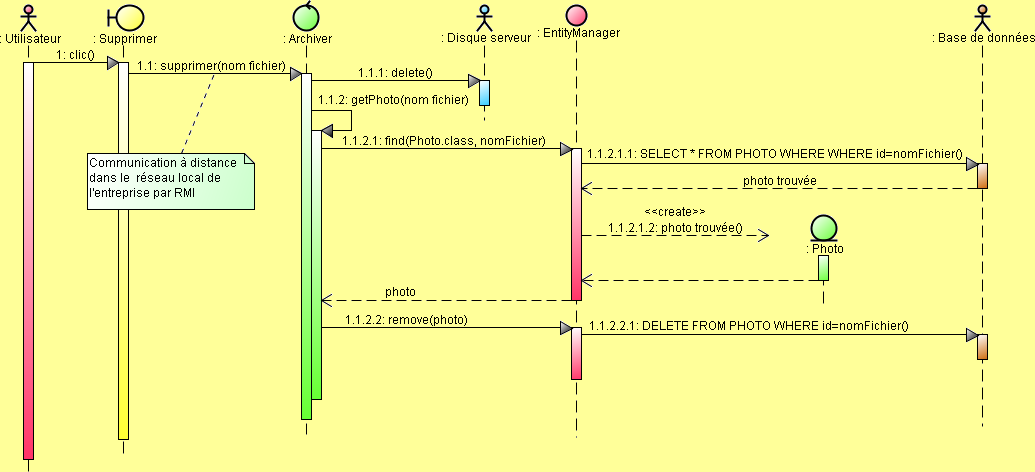
@Stateless public class Archiver { private final String répertoire = ; @PersistenceContext EntityManager persistance; ... public List<Photo> getListe() { return persistance.createNamedQuery().getResultList(); } public Photo getPhoto(String nom) { return persistance.find(Photo.class, nom); } public void supprimer(String nom) { new File(répertoire+nom).delete(); Photo photo = getPhoto(nom); persistance.remove(photo); } }
Les entités sont simplement des POJO (Plain Old Java Objects) qui sont gérés ou non par le gestionnaire d'entités. Lorsqu'elles sont gérées, elles ont une identité de persistance et leur état est synchronisé avec la base de données. Lorsqu'elles ne le sont pas (elles sont, par exemple, détachées du gestionnaire d'entités), elles peuvent être utilisées comme n'importe quelle autre classe Java : ce qui signifie que les entités ont un cycle de vie.
Lorsque vous créez une instance de l'entité Photo à l'aide de l'opérateur new, l'objet existe en mémoire et JPA ne le connaît pas (il peut même finir par être supprimé par le ramasse-miettes) ; lorsqu'il devient géré par le gestionnaire d'entités, son état est associé et synchronisé aves la table PHOTO. L'appel de la méthode remove() de EntityManager supprime les données de la base, mais l'objet Java continue d'exister en mémoire jusqu'à ce que le ramasse-miettes le détruise.

Les opérations qui s'appliquent aux entités peuvent se classer en quatre catégories : persistance, mis à jour, suppression et chargement qui correspondent respectivement aux opérations d'insertion, de mis à jour, de suppression et de sélection dans la base de données.
Chaque opération possède un événement "Pre" et "Post" (sauf le chargement, qui n'a qu'un événement "Post") qui peuvent être interceptés par le gestionnaire d'entités pour invoquer dès lors une méthode métier. Comme nous le découvrirons dans une autre étude, il existe donc des annotations @PrePersist, @PostPersist, etc. Ces annotations peuvent être associées à des méthodes d'entités (appelées fonctions de rappel) ou à des classes externes (appelées écouteurs). Vous pouvez considérer les fonctions de rappel et les écouteurs comme des triggers d'une base de données relationnelle.
Partie intégrante du framework Java EE 6, l'unité de persistance (JPA) est la boîte noire qui permet de rendre persistants les beans entités. Plus qu'un simple fournisseur de persistance, celle-ci va permettre aux développeurs d'optimiser leurs applications selon la gestion de leurs beans entités.
L'unité de persistance est l'élément clé de la gestion des beans entités au sein d'une application. Effectivement, les beans entités étant des objets simples, ils doivent être managés par une unité de persistance qui permet d'intégrer l'utilisation de ces beans entités au sein d'applications Java EE et même au travers de Java SE (sans passer par un bean session).
Bien que la mise en place des beans entités EJB 3.1 au sein d'une application soit assez simple, la persistance des informations doit être configurée pour permettre la sauvegarde des données dans la ou les source(s) de données.
La solution adoptée pour la gestion de ces beans entités est l'utilisation d'une unité de persistance (ou contexte de persistance) qui prend en charge la sauvegarde des informations dans la source de données, de manière autonome (indépendamment des beans entités).
Une unité de persistance est caractérisée par les points suivants :
Une unité de persistance étant vouée à être enregistrée dans une source de données, le rôle de l'unité de persistance est :
Il est possible d'avoir un bean entité attaché ou détaché de l'unité de persistance. Quand un bean entité est attaché à un contexte de persistance, les modifications appliquées à l'objet sont alors automatiquement synchronisées avec la base de donnés, via le gestionnaire d'entité (EntityManager). A l'inverse, un bean entité est dit détaché lorsqu'il n'a aucun lien avec le gestionnaire d'entité (EntityManager).
Auparavant, les beans entités se cantonnaient uniquement au sein de Java EE. Depuis la version EJB 3, l'utilisation des beans entités n'est plus fermée au monde Java EE ou à un conteneur EJB. Vous pouvez désormais déployer vos entités dans de nombreuses applications :
Ce dernier point est, sans doute, le plus appréciable. En effet, il vous permet d'inclure facilement et simplement un système de persistance de données à une application Java SE.
La nouvelle spécification définit un fichier de description qui regroupe l'ensemble des informations de persistance. Ce fichier décrit les beans entités qui vous seront utiles pour l'application, l'emplacement de la base de données, ainsi que le fournisseur de persistance qui correspond généralement au serveur d'applications.
Ce fichier sera alors lu par le conteneur d'EJB lors du déploiement de l'application (EAR, EJB-JAR, WAR, ...). Au moment du déploiement le conteneur vérifie la description proposée et contrôle la concordance avec les éléments qu'il connaît : les beans entités sont-ils présents dans le serveur d'application ? la base de données est-elle accessible ? etc. Si tout se passe bien, le conteneur crée alors une instance de persistance avec les paramètres demandés. Cette unité de persistance sera ainsi toujours opérationnelle et active à tout instant.
Vous devez nommer ce fichier de description de persistance : persistence.xml et placer ce dernier dans le répertoire <META-INF> à la racine du projet. 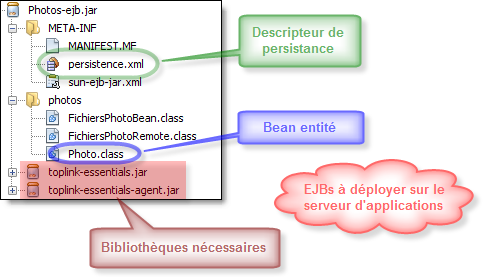
Attention : vous devez nommer correctement le fichier persistence.xml. Si le nom ne correspond pas, le conteneur n'associera aucun contexte de persistance à l'application.
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"> <persistence-unit name="PhotoListe-ejbPU" transaction-type="JTA"> <provider>org.eclipse.persistence.jpa.PersistenceProvider</provider> <jta-data-source>photo</jta-data-source> <properties> <property name="eclipselink.ddl-generation" value="create-tables"/> </properties> </persistence-unit> </persistence>
<?xml version="1.0" encoding="UTF-8"?> <persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd"> <persistence-unit name="Photos-ejbPU" transaction-type="RESOURCE_LOCAL"> <provider>org.eclipse.persistence.jpa.PersistenceProvider</provider> <class>photos.Photo</class> <properties> <property name="eclipselink.jdbc.user" value="manu"/> <property name="eclipselink.jdbc.password" value="manu"/> <property name="eclipselink.jdbc.url" value="jdbc:derby://localhost:1527/photos"/> <property name="eclipselink.target-database" value="DERBY"/> <property name="eclipselink.jdbc.driver" value="org.apache.derby.jdbc.ClientDriver"/> <property name="eclipselink.ddl-generation" value="drop-and-create-table" /> <property name="eclipselink.logging.level" value="INFO"/> </properties> </persistence-unit> </persistence>
Ce fichier est un document XML. Comme tout document XML, il doit respecter un certain canevas. Ici, l'élément racine est la balise <persistence>. La balise racine ne contient ensuite qu'une ou plusieurs balises <persistence-unit>. Cette dernière décrit comment mettre en place une unité de persistance. Il est ainsi possible d'avoir plusieurs unités de persistance dans le cas, par exemple, où notre application utilise plusieurs bases de données (une unité de persistance par base de données).
<persistence-unit> : déclare une unité de persistance.
- L'attribut name affecte un nom unique à cette unité dans votre application. Le nom est utilisé pour identifier l'unité de persistance lors de son utilisation avec les annotations @PersistenceContext et @PersistenceUnit pour la création, respectivement, d'un EntityManager ou d'un EntityManagerFactory (voir plus loin dans notre étude).
- L'attribut type définit si l'unité de persistance est gérée et intégrée dans une transaction Java EE (JTA) ou si vous souhaitez gérer de façon manuelle les transactions (RESOURCE_LOCAL) via l'EntityManager (ou l'EntityManagerFactory). La valeur par défaut en environnement Java EE est JTA et RESOURCE_LOCAL en environnement Java SE. Des détails concernant ce type sont donnés plus loin.
Je le rappelle, pensez bien qu'il est nécessaire de définir plusieurs unités de persistance si vous souhaitez utiliser plusieurs sources de données.
Voici maintenant une description des balises qui spécifie les paramètres de l'unité de persistance. Vous devez donc placer ces balises à l'intérieur d'une balise <persistence-unit> :Une unité de persistance mappe un ensemble de beans entités. Par défaut, dans un environnement Java EE, le conteneur analyse l'ensemble des classes du fichier *.jar contenant le fichier persistence.xml. Pour définir manuellement les classes à mapper, vous pouvez utiliser les balises suivantes :
Finalement, l'ensemble des classes à mapper est défini par l'ensemble des :
Généralement, vous n'avez pas à utiliser les balises <jar-file> et <class> sauf si vous souhaitez mapper une classe à plusieurs unités de persistance.
Le fait de proposer un fichier de description est un très gros atout. Il vous est possible, à tout moment, de changer votre serveur de base de données ou même de serveur d'applications, sans que vous ayez à recompiler et à reconstruire votre application d'entreprise. Ce fichier sert ainsi de fichier de configuration.
Après avoir découvert le rôle d'un bean entité et comment le rendre persistant, nous allons mettre en pratique ces différentes définitions. Ainsi, nous verrons comment construire un bean entité et comment le gérer au travers de l'unité de persistance. L'unité de persistance, elle-même, sera mis en oeuvre au travers d'un bean session.
Afin de visualiser l'intérêt d'utiliser des beans entités, je vous propose de faire la démonstration au travers d'un projet. Ce projet consiste à réaliser un tout petit serveur de photos qui me permet de stocker un ensemble réduit de clichés numériques qui seront bien sûr possibles de consulter par la suite.



Dans notre exemple, la base de données se situe avec le serveur d'application Java EE. Elle peut se situer, bien entendu, sur une machine distincte. Le fonctionnement demeure totalement identique.
Vous allez le découvrir, la gestion des bases de données avec les beans entités sont très simples à mettre en oeuvre puisque les tables sont automatiquement créées au moment même où vous déployez votre application d'entreprise (contenant des beans entités) dans votre serveur d'applications. Nous devons quand même réaliser une petite opération, c'est effectivement de créer la base de données, qui va accueillir les différentes tables prévues par l'application d'entreprise, référencée par le service de nommage JNDI.
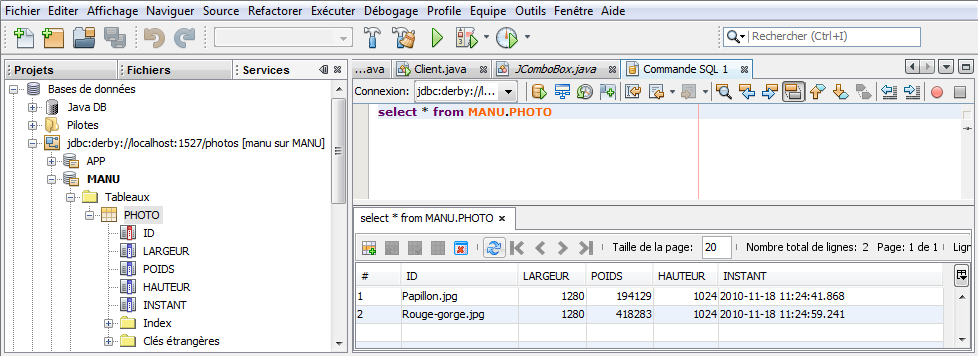
Je vous propose de voir comment créer cette base de données en utilisant le serveur d'applications Glassfish avec sa base de données interne Derby au moyen de l'environnement NetBeans.
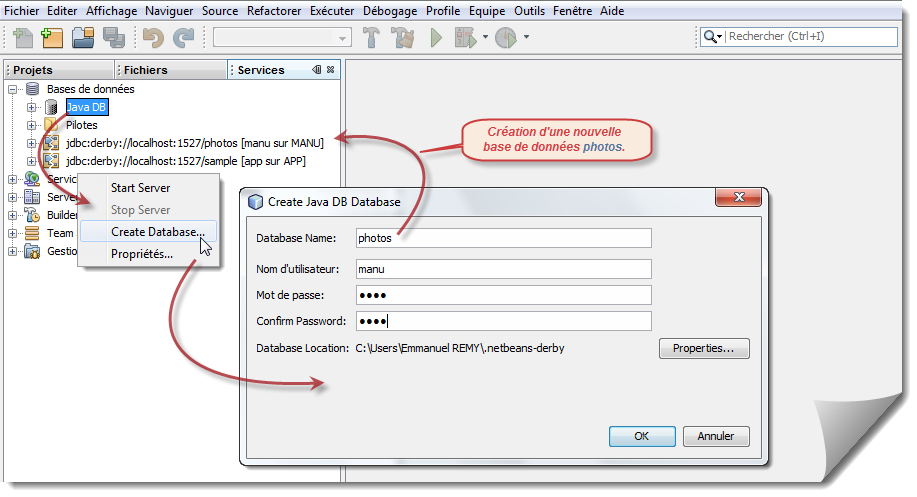
Nous aurions pu attendre avant de mettre en place cette base de données. Effectivement, nous aurions pu créer la base de données juste au moment de la mise en oeuvre du bean entité. Le système vérifie si la base de données existe et propose de la construire le cas échéant.
Nous allons maintenant constituer notre projet dans sa globalité, d'une part la gestion complète côté serveur d'applications et d'autre part l'application cliente qui va utiliser ce service. Nous l'avons déjà largement évoqué lors de l'étude précédente, l'idéal est de constituer un projet d'entreprise avec donc les deux modules :
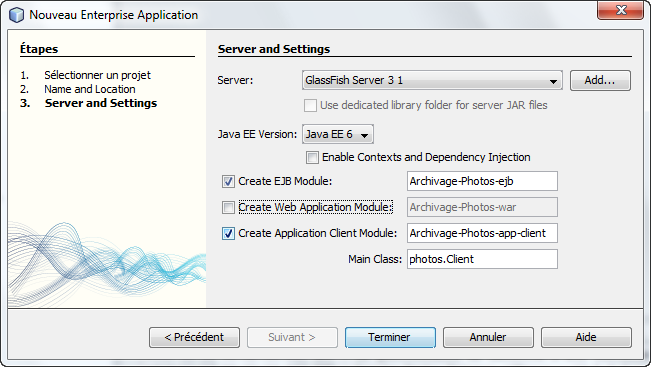
Nous allons maintenant nous occuper de la persisance dans sa globalité, d'une part l'entité représentant les informations importantes à sauvegarder pour chacune des photos stockées et d'autre part l'unité de persistance qui s'occupera de réaliser le mapping objet/relationnel.
Voici la procédure à suivre dans l'environnement de Netbeans :

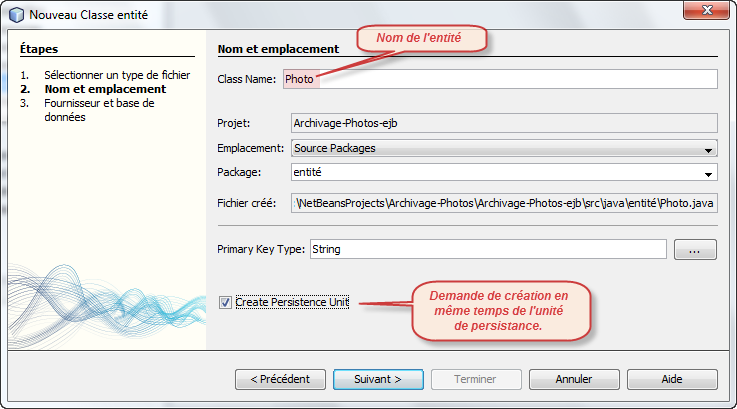

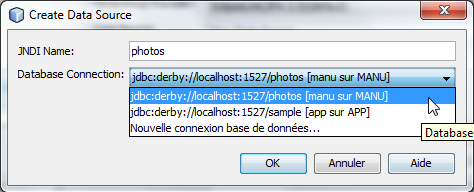

package entité; import java.awt.image.BufferedImage; import java.util.Date; import javax.persistence.*; @Entity @NamedQuery(name=, query=) public class Photo implements java.io.Serializable { @Id private String id; @Temporal(TemporalType.TIMESTAMP) private Date instant; private int largeur; private int hauteur; private long poids; public String getId() { return id; } public int getHauteur() { return hauteur; } public Date getInstant() { return instant; } public int getLargeur() { return largeur; } public long getPoids() { return poids; } public Photo() { } public Photo(String nom, long poids) { id = nom; instant = new Date(); this.poids = poids; } public void setDimensions(BufferedImage image) { largeur = image.getWidth(); hauteur = image.getHeight(); } @Override public String toString() { return id++largeur++hauteur+; } }
Un point important lors de la mise en oeuvre d'une entité. Vous remarquez que Netbeans propose systématiquement que chaque entité implémente l'interface Serializable. Ce choix est parfaitement judicieux si vous désirez que cette information se propage sur le réseau afin que le client puisse en bénéficier.
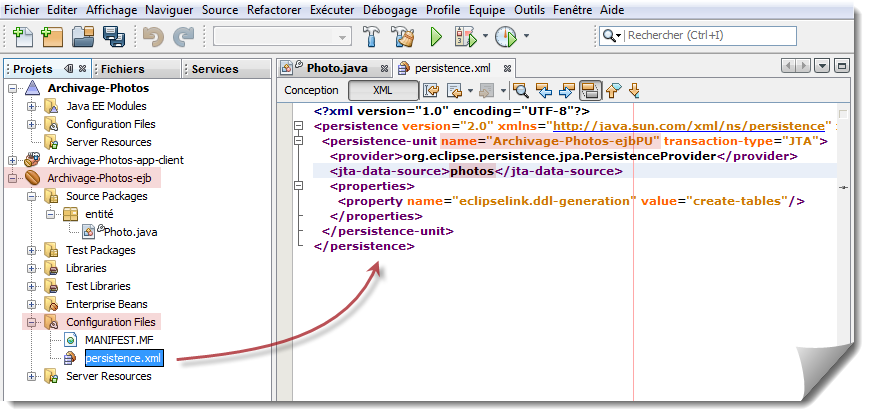
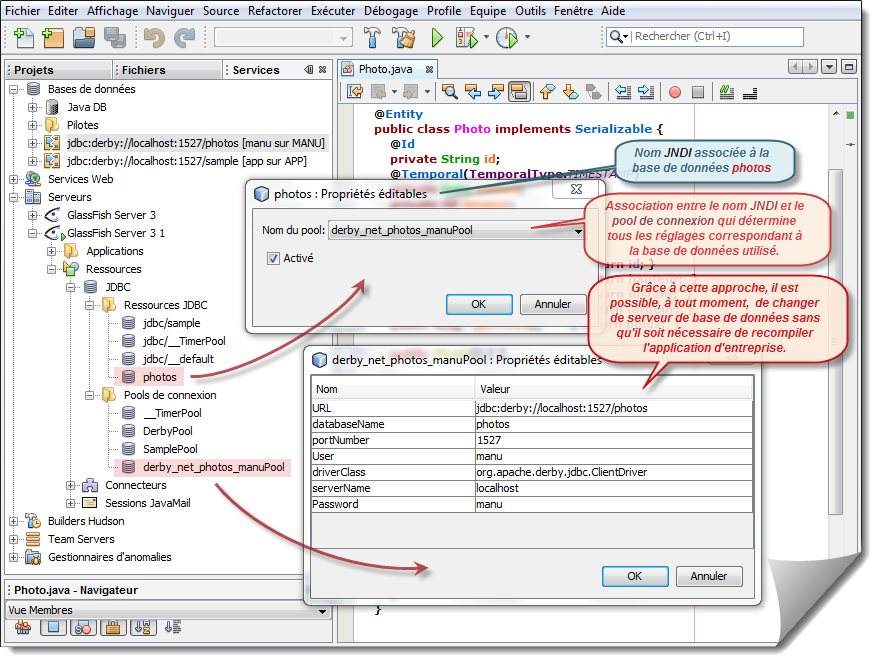
Avec ce système, nous obtenons beaucoup d'indirection avant d'atteindre la base de données effective. En effet, l'unité de persistance Archivage-Photos-ejbPU fait référence au nom JNDI photos qui lui même fait référence au pool de connexion derby_net_photosPool (nom par défaut proposé par Netbeans). C'est ce dernier élément qui possède toutes les caractéristiques essentielles de la base de données : serveur utilisé, driver associé, numéro de service, nom de la base, nom d'utilisateur, etc.
Toujours dans notre module EJB, nous devons maintenant implémenter le bean session qui va s'occuper de tout le traitement nécessaire côté serveur ; d'une part l'enregistrement physique des différentes photos sur le disque dur du serveur et d'autre part la gestion complète de la persistance des entités relatives aux informations supplémentaires des photos archivées.
Voici la procédure à suivre dans l'environnement de Netbeans :


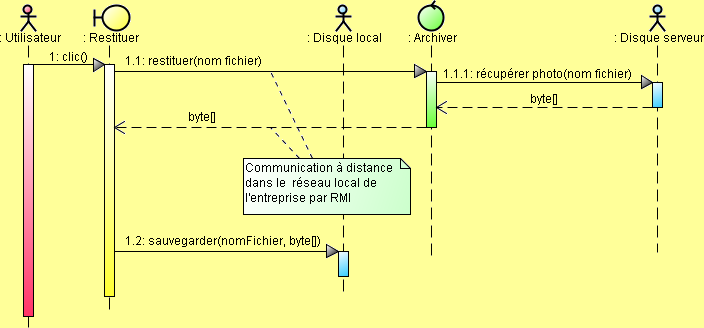
package session; import javax.ejb.Remote; import entité.Photo; @Remote public interface ArchiverRemote { void stocker(String nom, byte[] octets) throws java.io.IOException; byte[] restituer(String nom) throws java.io.IOException; List<Photo> getListe(); Photo getPhoto(String nom); void supprimer(String nom); }
package session; import java.util.List; import javax.ejb.*; import javax.persistence.*; import entité.Photo; import java.awt.image.BufferedImage; import java.io.*; import javax.imageio.ImageIO; @Stateless public class Archiver implements ArchiverRemote { private final String répertoire = ; @PersistenceContext EntityManager persistance; @Override public void stocker(String nom, byte[] octets) throws IOException { File fichier = new File(répertoire+nom); if (fichier.exists()) return; FileOutputStream fluxphoto = new FileOutputStream(fichier); fluxphoto.write(octets); fluxphoto.close(); enregistrer(nom); } @Asynchronous private void enregistrer(String nom) throws IOException { File fichier = new File(répertoire+nom); BufferedImage image = ImageIO.read(fichier); Photo photo = new Photo(nom, fichier.length()); photo.setDimensions(image); persistance.persist(photo); } public byte[] restituer(String nom) throws IOException {
File fichier = new File(répertoire+nom);
if (!fichier.exists()) return null;
FileInputStream fluxphoto = new FileInputStream(fichier);
byte[] octets = new byte[(int)fichier.length()];
fluxphoto.read(octets);
fluxphoto.close();
return octets;
} @Override public List<Photo> getListe() { return persistance.createNamedQuery().getResultList(); } @Override public Photo getPhoto(String nom) { return persistance.find(Photo.class, nom); } @Override public void supprimer(String nom) { new File(répertoire+nom).delete(); Photo photo = getPhoto(nom); persistance.remove(photo); } }
Même si cela n'est pas précisé explicitement, c'est bien l'unité de peristance Archivage-Photos-ejbPU qui est utilisée puisque c'est la seule qui est définie dans le projet.
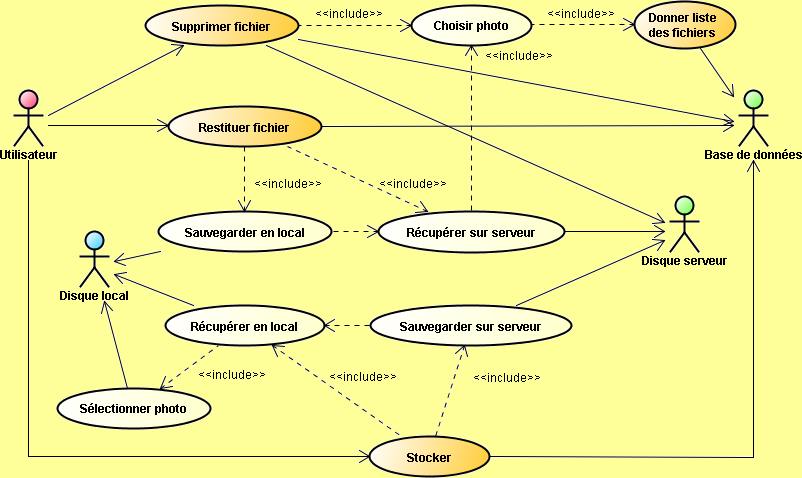
Nous concluons notre étude par la mise en oeuvre de l'application cliente qui pourra être déployée automatiquement depuis le serveur d'application du moment que nous restons dans le réseau local de l'entreprise (le numéro de service 3700 pour les objets distants de type bean session va être bloqué par le pare-feu de l'entreprise). Pour une bonne ergonomie, cette application cliente est bien entendue constituée d'une IHM dont je rappelle les fonctionnalités suivantes :
package photos; import java.awt.BorderLayout; import java.awt.event.*; import java.io.*; import javax.ejb.EJB; import javax.imageio.ImageIO; import javax.swing.*; import session.ArchiverRemote; import entité.Photo; public class Client extends JFrame { private JTabbedPane onglets = new JTabbedPane(); private JPanel panneauLocal = new JPanel(new BorderLayout()); private JPanel panneauServeur = new JPanel(new BorderLayout()); private JToolBar outilsLocal = new JToolBar(); private JToolBar outilsDistant = new JToolBar(); private JLabel photoLocale = new JLabel(); private JLabel photoDistante = new JLabel(); private JLabel description = new JLabel(); private JComboBox listePhotos = new JComboBox(); private JFileChooser sélecteur = new JFileChooser(); private Photo photo; private File fichier; private byte[] octets; private boolean effacer = true; @EJB private static ArchiverRemote archivage; public Client() { super(); add(onglets); onglets.add(, panneauLocal); onglets.add(, panneauServeur); panneauLocal.add(outilsLocal, BorderLayout.NORTH); panneauLocal.add(new JScrollPane(photoLocale)); outilsLocal.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { sélecteur.setFileSelectionMode(JFileChooser.FILES_ONLY); if (sélecteur.showOpenDialog(Client.this)==JFileChooser.APPROVE_OPTION) { fichier = sélecteur.getSelectedFile(); photoLocale.setIcon(new ImageIcon(fichier.getPath())); } } }); outilsLocal.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (fichier!=null) try { byte[] octets = new byte[(int) fichier.length()]; FileInputStream lecture = new FileInputStream(fichier); lecture.read(octets); lecture.close(); archivage.stocker(fichier.getName(), octets); listingPhotos(); } catch (Exception ex) { setTitle(); } } }); panneauServeur.add(outilsDistant, BorderLayout.NORTH); panneauServeur.add(new JScrollPane(photoDistante)); panneauServeur.add(description, BorderLayout.SOUTH); outilsDistant.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { sélecteur.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY); if (sélecteur.showSaveDialog(Client.this)==JFileChooser.APPROVE_OPTION) { try { fichier = new File(sélecteur.getSelectedFile() + +photo.getId()); FileOutputStream fluxImage = new FileOutputStream(fichier); fluxImage.write(octets); fluxImage.close(); } catch (Exception ex) { setTitle(); } } } }); outilsDistant.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { archivage.supprimer(photo.getId()); listingPhotos(); } }); outilsDistant.add(listePhotos); listePhotos.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { if (!effacer) try { photo = (Photo) listePhotos.getSelectedItem(); octets = archivage.restituer(photo.getId()); ByteArrayInputStream fluxImage = new ByteArrayInputStream(octets); photoDistante.setIcon(new ImageIcon(ImageIO.read(fluxImage))); } catch (Exception ex) { setTitle(); } } }); listingPhotos(); setSize(500, 400); setLocationByPlatform(true); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } private void listingPhotos() { effacer = true; listePhotos.removeAllItems(); for (Photo photo : archivage.getListe()) listePhotos.addItem(photo); effacer = false; if (listePhotos.getItemCount()>0) listePhotos.setSelectedIndex(0); } public static void main(String[] args) { new Client(); } }