Les flux et les fichiers
Les flux et les fichiers
 Cette étude explique comment prendre de l'information
en entrée à partir de n'importe qu'elle source de données
capable d'émettre une suite d'octets et symétriquement, comment
envoyer en sortie de l'information vers une destination acceptant une suite
d'octets. (En informatique, la base de l'information est toujours l'octet, surtout
lorsque nous réalisons des transferts dits en série).
Cette étude explique comment prendre de l'information
en entrée à partir de n'importe qu'elle source de données
capable d'émettre une suite d'octets et symétriquement, comment
envoyer en sortie de l'information vers une destination acceptant une suite
d'octets. (En informatique, la base de l'information est toujours l'octet, surtout
lorsque nous réalisons des transferts dits en série).
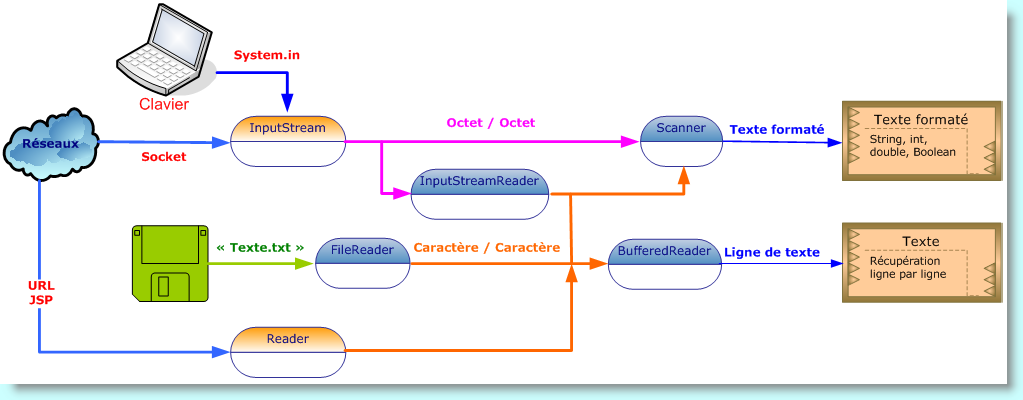
Ces sources et destinations des séquences d'octets peuvent être des fichiers - c'est souvent le cas - mais également des connexions sur un réseau, des blocs en mémoire, le clavier de la console, etc.


Il faut garder à l'esprit le caractère général des entrées/sorties : par exemple, l'information stockée dans des fichiers est traitée pratiquement de la même façon que celle provenant d'une connexion réseau. Bien entendu, même si le stockage des données se réduit toujours en définitive à une suite d'octets, il est souvent plus efficace de considérer que les données possèdent une structuration de plus haut niveau, comme une suite de caractères, d'entiers ou d'objets, qui eux-mêmes peuvent représenter des informations d'encore plus hauts niveaux comme la musique ou les images.

Dans le langage de programmation java, l'objet à partir duquel nous pouvons lire une suite d'octets se nomme flux d'entrée. Par ailleurs, nous appelons flux de sortie l'objet vers lequel nous pouvons écrire une suite d'octets.
Ce sont les classes abstraites InputStream et OutputStream qui implémentent ces deux types de flux.
Je rappelle qu'une classe abstraite apporte essentiellement un mécanisme de factorisation du comportement commun d'un essemble de classes à un niveau supérieur. Cela conduit à un code plus propre et une meilleure lisibilité de l'arbre d'héritage. Cette approche est utilisée pour les entrées/sorties en Java.
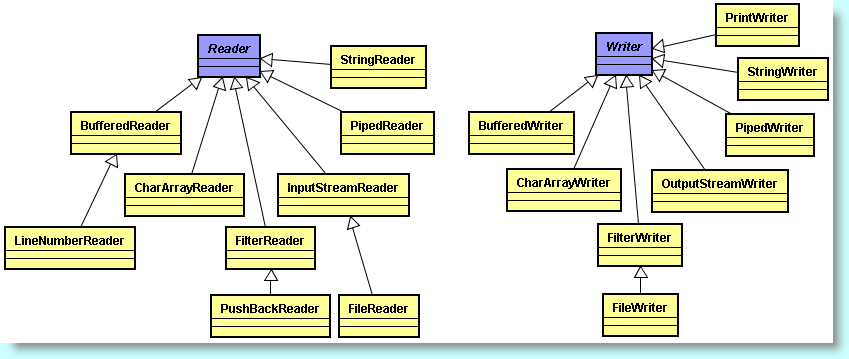
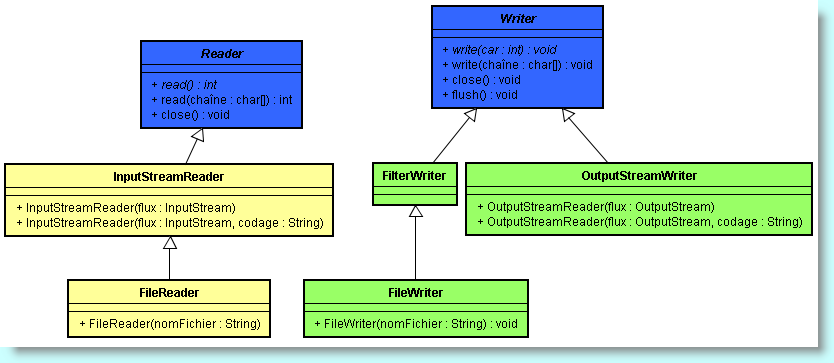
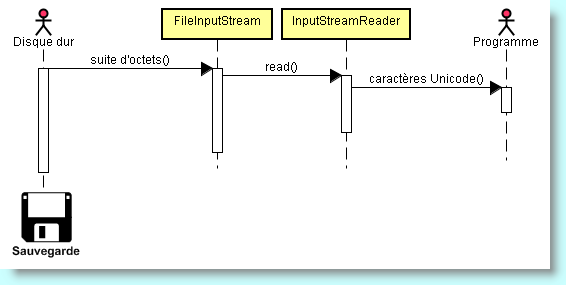
Comme les flux d'octets conviennent mal au traitement d'informations codées en Unicode (on se souvient qu'Unicode utilise deux octets par caractère), il a été introduit une hiérarchie de classes spéciale pour le traitement de caractères. Ces classes héritent des superclasses abstraites spéciales Reader et Writer qui possèdent des opérations d'écriture et de lecture reconnaissant les caractères Unicode de deux octets et non des caractères d'un seul octet.
Ainsi pour la classe FileInputStream, cette méthode lit un octet dans un fichier. L'objet prédéfini System.in de la sous-classe de InputStream permet de saisir l'information à partir du clavier.
Pour en savoir plus sur la gestion des threads avec les flux.
§
int nombreDisponible = lecture.available(); if (nombreDisponible > 0) { byte[] octets = new byte[nombreDisponible]; lecture.read(octets); }
Les programmeurs Java auront peu l'utilité d'une classe flux qui ne possède que des méthodes concrètes encapsulant les fonctions de base read() et write(), car un programme n'a que rarement besoin de lire ou d'écrire des flux d'octets. Les données que vous allez rencontrer contiennent en général des nombres, des chaînes et des objets.
Java fait dériver de nombreuses classes flux des classes de base InputStream et OutputStream qui vont précisément permettre de traiter les données dans ces formats habituels et non plus au plus bas niveau de l'octet.
D'autre part, pour le texte Unicode, il existe les sous-classes de Reader et Writer. Les méthodes de base de ces deux classes sont comparables à celles d'InputStream et d'OutputStream comme read() et write(). Elles opèrent exactement comme les méthodes correspondantes des classes InputStream et OutputStream, sauf bien entendu que la méthode read() renvoie soit un caractère Unicode (sous forme d'un entier entre 0 et 65535), soit -1 si la fin du fichier est atteinte.
Comme nous venons de l'évoquer, la plupart du temps, nous n'avons pas besoin de traiter les informations venant d'un flux au niveau le plus bas, c'est-à-dire au niveau de l'octet. Toutefois, il existe bien un exemple qui semblerait s'y prêter : la copie de fichiers. Dans ce cas particulier, nous n'avons pas besoin d'interpréter le contenu du fichier. Il s'agit simplement de prendre l'ensemble des octets comme ils se présentent et de les placer ensuite dans le nouveau fichier.
package flux; import java.awt.*; import java.awt.event.*; import java.io.*; import javax.swing.*; public class CopieFichier extends JFrame { private JFileChooser sélection = new JFileChooser(); private JToolBar boutons = new JToolBar(); private JLabel résultat = new JLabel(); private final String stockage = ; public CopieFichier() { super(); add(boutons, BorderLayout.NORTH); boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showSaveDialog(null) == JFileChooser.APPROVE_OPTION) { try { résultat.setText(); File fichier = sélection.getSelectedFile(); FileInputStream lecture = new FileInputStream(fichier); FileOutputStream écriture = new FileOutputStream(stockage+fichier.getName()); byte[] octets; int nombre = lecture.available(); if (nombre > 0) { octets = new byte[nombre]; lecture.read(octets); écriture.write(octets); lecture.close(); écriture.close(); résultat.setText(); } } catch (FileNotFoundException ex) { résultat.setText(); } catch (IOException ex) { résultat.setText(); } } } }); boutons.addSeparator(); boutons.add(résultat); boutons.addSeparator(); pack(); setLocationRelativeTo(null); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) { new CopieFichier(); } }
... public class CopieFichier extends JFrame { private JFileChooser sélection = new JFileChooser(); private JToolBar boutons = new JToolBar(); private JLabel résultat = new JLabel(); private final String stockage = ; private final int BUFFER = 4096; public CopieFichier() { super(); add(boutons, BorderLayout.NORTH); boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showSaveDialog(null) == JFileChooser.APPROVE_OPTION) { try { résultat.setText(); File fichier = sélection.getSelectedFile(); FileInputStream lecture = new FileInputStream(fichier); FileOutputStream écriture = new FileOutputStream(stockage+fichier.getName()); byte[] octets = new byte[BUFFER]; while (lecture.available() > 0) { if (lecture.available() < BUFFER) octets = new byte[lecture.available()]; lecture.read(octets); écriture.write(octets); // écriture.flush(); } lecture.close(); écriture.close(); résultat.setText(); } catch (FileNotFoundException ex) { résultat.setText(); } catch (IOException ex) { résultat.setText(); } } } }); ...
En Java, les classes utilisées pour la gestion des flux sont très nombreuses et spécialisées. En effet, chacune d'entre elles ne s'occupe que d'un travail particulier comme, par exemple, la classe FileInputStream qui est capable de récupérer un octet dans un fichier stocké sur le disque dur. Cette classe est très compétente tout en étant simple d'utilisation puisque tout le mécanisme complexe de gestion de disque n'est pas visible à l'utilisateur. Ce dernier doit juste donner le nom du fichier concerné au constructeur de la classe. Toutefois, cette classe n'est pas compétente quand à la gestion des données de plus haut niveau comme des entiers ou des objets. Il faut alors utiliser une classe supplémentaire qui sache récupérer les octets donnés par la classe FileInputStream et qui les transforment en éléments de plus haut niveau. Par exemple, la classe DataInputStream change les octets en données : entières, réelles, booléennes...
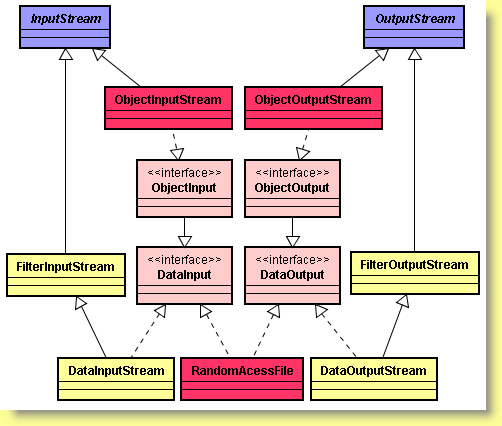
Hiérarchie des classes d'entrées/sorties sous forme de flux d'octets
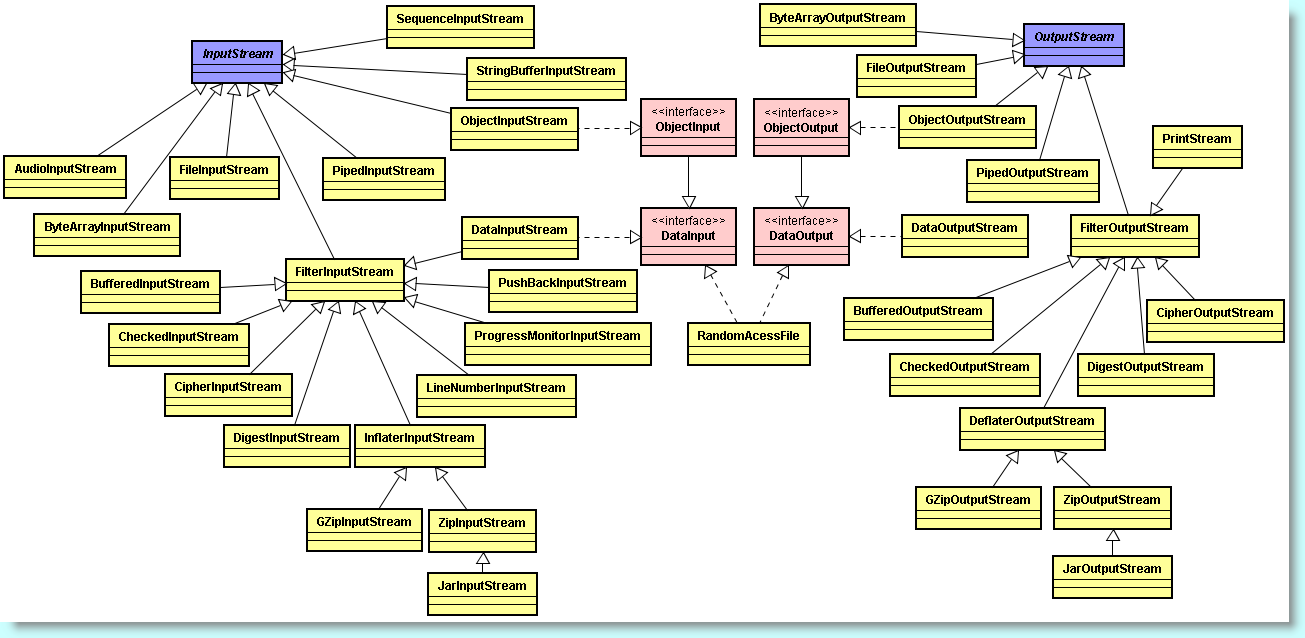
Séparons les représentants de la faune des flux selon leur utilité. Quatre classes abstraites sont à l'origine de la faune : InputStream, OutputStream, Reader et Writer. Nous ne pouvons créer des objets directement sur ces classes puisqu'elles sont abstraites, mais d'autres méthodes peuvent tout-à-fait faire appel ou renvoyer ces classes.
Par exemple, la classe Socket, classe qui implémente les fonctionnalités du réseau, possède deux méthodes getInputStream() et getOutputStream() qui renvoient respectivement un InputStream ou un OutputStream. Nous utilisons ensuite des objets issus de la hiérarchie des classes de flux pour lire ou écrire des informations de haut niveau qui transitent sur le réseau.
Nous avons vu que les classes InputStream et OutputStream ne permettent que de lire et d'écrire des octets un par un ou des tableaux d'octets. Elles ne possèdent pas de méthode pour lire ou écrire des chaînes de caractères ou des nombres. Des classes plus puissantes sont nécessaires. Par exemple, DataInputStream et DataOutputStream permettent de lire et d'écrire tous les types de base de Java.
Pour le texte Unicode, il existe donc des sous-classes de Reader et de Writer. Les méthodes de base de ces deux classes sont comparables à celles d'InputStream et d'OuputStream :
abstract int read() et abstract void write(int octet) : Ces deux méthodes opèrent comme les méthodes correspondantes des classes InputStream et OutputStream, sauf bien entendu que la méthode read() renvoie soit une unité de code Unicode (sous forme d'un entier entre 0 et 65535), soit -1 si la fin du flux est atteint.
Hiérarchies des flux de texte Unicode en entrée et en sortie
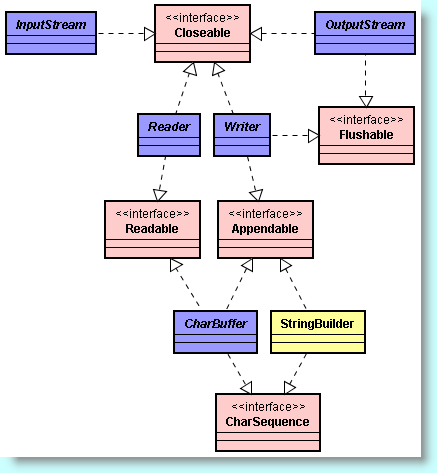
De plus, depuis Java SE 5.0, nous avons à notre disposition quatre nouvelles interfaces : Closeable, Flushable, Readable et Appendable :
Interfaces liées aux flux
Java utilise la notion de couche un peu comme pour les réseaux, et chaque classe filtre les informations pour obtenir la valeur désirée. Même si cela paraît complexe, c'est en réalité très simple d'utilisation puisque chaque classe fait peu de choses. Ce principe a également été mis en oeuvre afin d'utiliser des classes légères et donc d'avoir une gestion des flux rapide et optimisée. Mais surtout ce système permet de construire une incroyable variété de séquences de flux effectivement utilisables.
Les deux schémas proposés ci-dessous vous permet de mieux comprendre les mécanismes que je viens d'évoquer. Remarquez qu'il est également possible de mettre en oeuvre des données compressées grâce aux classes respectives ZipInputStream et ZipOutputStream.
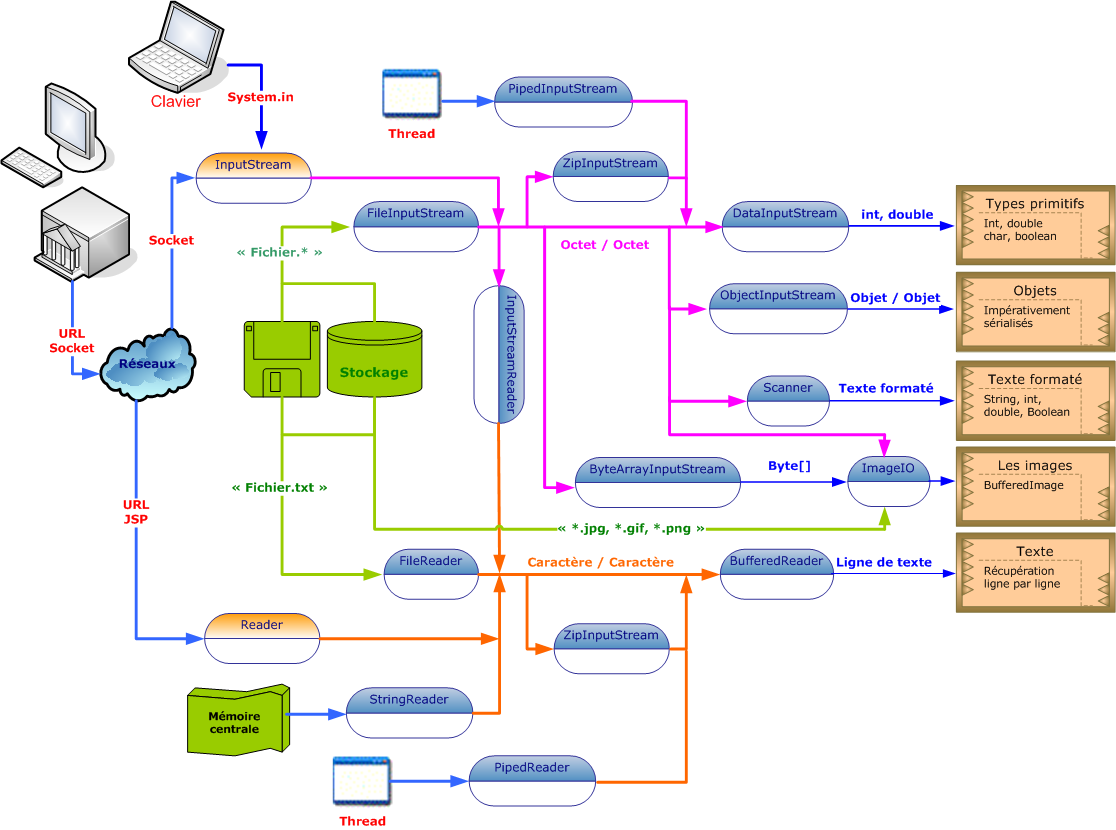
Quelques classes de flux en entrée avec quelques liaisons possibles
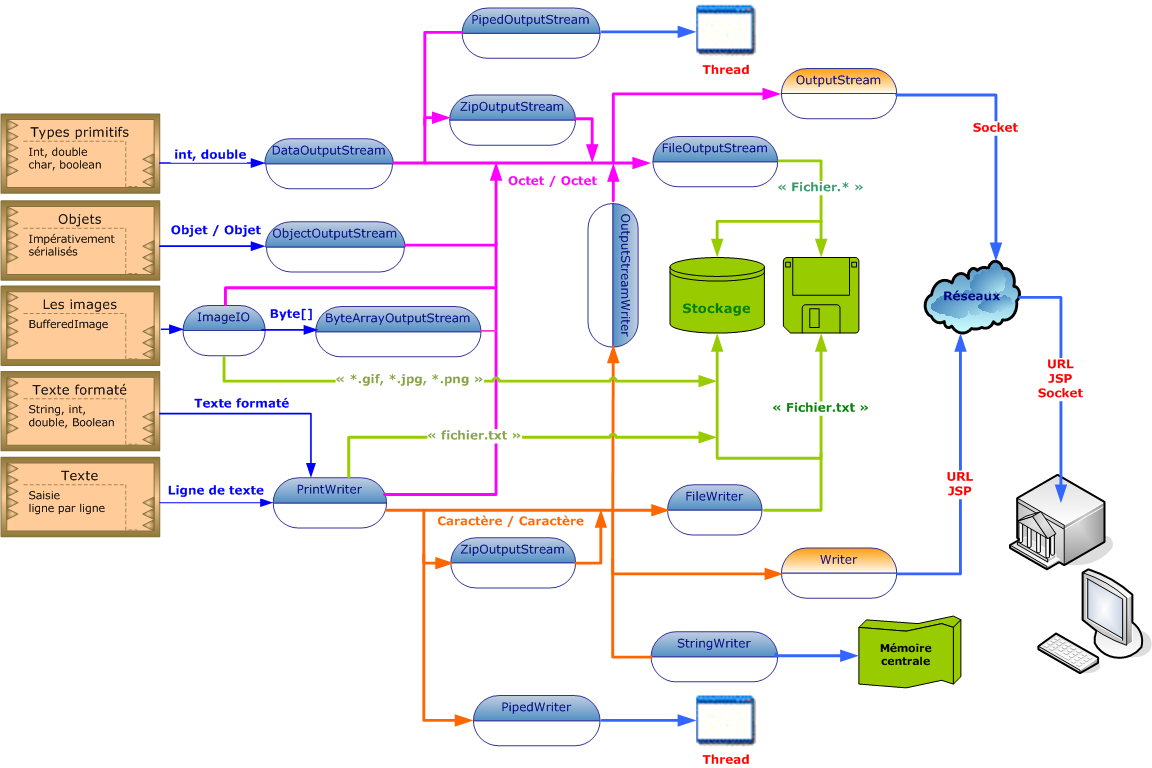
Quelques classes de flux en sortie avec quelques liaisons possibles
A titre informatif prenons tout-de-suite des exemples de structures :
FileInputStream lecture = new FileInputStream("Formes.dessin");
Comme nous l'avons découvert dans nos exemples, il est possible également d'utiliser un objet File intermédiaire :
File fichier = new File("Formes.dessin");
FileInputStream lecture = new FileInputStream(fichier);
Il peut être utile de connaître le répertoire courant de l'utilisateur puisque toutes les classes de java.io interprètent les chemins relatifs à partir de ce dernier : cette information est obtenue par un appel à System.getProperty("user.dir").
byte octet = (byte) lecture.read();
DataInputStream primitif = ... ;
double réel = primitif.readDouble();
De même que FileInputStream ne possède pas de méthode pour lire les types numériques, DataInputStream n'a pas de méthode pour accéder aux données d'un fichier. Chaque classe de flux proposent des fonctionnalités spécialisées et réduites. Ainsi, au travers de cet exemple, nous voyons que FileInputStream est capable de proposer une suite d'octets issus d'un fichier sur le disque dur (ce qui d'ailleurs n'est pas rien) et que cette suite d'octets peut ensuite être formatée à l'aide de la classe DataInputStream pour aboutir à une information plus intuitive et plus adaptée à la situation, en retrouvant ainsi les valeurs numériques pouvant être exploitées directement. Pour conclure, chaque classe de flux possède ses propres compétences.
Pour en savoir plus sur le flux de données.
§
FileInputStream lecture = new FileInputStream("Formes.dessin");
DataInputStream primitif = new DataInputStream(lecture) ;
double réel = primitif.readDouble();
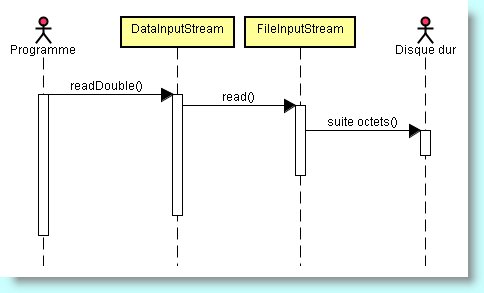
Comme au préalable, le flux ainsi obtenu continue à accéder aux données du fichier associé au flux d'entrée, mais nous disposons maintenant d'une interface beaucoup plus puissante.
DataInputStream primitif = new DataInputStream(new BufferedInputStream(new FileInputStream("Formes.dessin")));
double réel = primitif.readDouble();
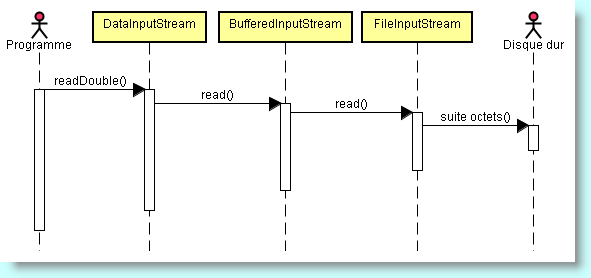
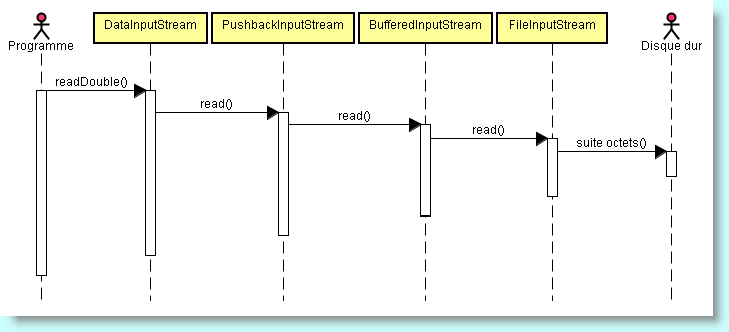
DataInputStream se trouve le dernier dans la chaîne des constructeurs - parce que nous voulons disposer des méthodes de DataInputStream et que celles-ci doivent elles-mêmes utiliser la méthode bufférisée read(). Malgré sa grande laideur, ce type de codage est incontournable et finalement très simple à réalisé : vous devez continuer à empiler des constructeurs de flux jusqu'à obtenir les fonctionnalités voulues.
PushbackInputStream intermédiaire = new PushbackInputStream(new BufferedInputStream(new FileInputStream("Formes.dessin")));
Parcourez à tout hasard l'octet suivant :int octet = intermédiaire.read();
Quitte à le renvoyer à sa place s'il ne correspond pas à votre attente :if (octet != '<') intermédiaire.unread(octet);
Le problème est que read() et unread() sont les seules méthodes applicables à ce type de flux d'entrée. Si vous désirez à la fois anticiper sur la lecture et lire les nombres, il vous faut un flux d'entrée du type précédent et un flux d'entrée de données : PushbackInputStream intermédiaire = new PushbackInputStream(new BufferedInputStream(new FileInputStream("Formes.dessin")));
DataInputStream primitif = new DataInputStream(intermédiaire);
double réel = primitif.readDouble();
ZipInputStream compressé = new ZipInputStream(new FileInputStream("Formes.dessin"));
DataInputStream primitif = new DataInputStream(compressé);
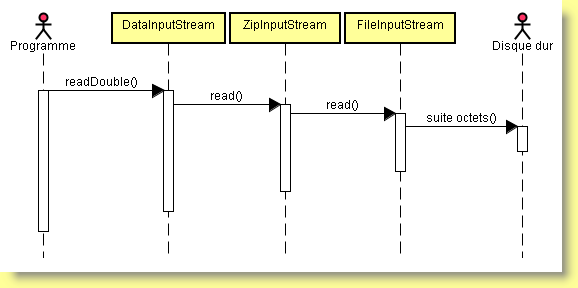
En définitive, si l'on passe sur les monstrueux constructeurs nécessaires à l'empilement des flux, pouvoir combiner les flux en Java est une fonctionnalité très agréable.
Pour en savoir plus sur les flux compressés.
§
Nous allons reprendre tout simplement le sujet précédent auquel nous rajoutons une simple bufférisation intermédiaire.
package flux; import java.awt.*; import java.awt.event.*; import java.io.*; import javax.swing.*; public class CopieFichier extends JFrame { private JFileChooser sélection = new JFileChooser(); private JToolBar boutons = new JToolBar(); private JLabel résultat = new JLabel(); private final String stockage = ; private final int BUFFER = 4096; public CopieFichier() { super(); add(boutons, BorderLayout.NORTH); boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showSaveDialog(null) == JFileChooser.APPROVE_OPTION) { try { résultat.setText(); File fichier = sélection.getSelectedFile(); BufferedInputStream lecture = new BufferedInputStream(new FileInputStream(fichier)); BufferedOutputStream écriture = new BufferedOutputStream(new FileOutputStream(stockage+fichier.getName())); byte[] octets = new byte[BUFFER]; while (lecture.available() > 0) { if (lecture.available() < BUFFER) octets = new byte[lecture.available()]; lecture.read(octets); écriture.write(octets); // écriture.flush(); } lecture.close(); écriture.close(); résultat.setText(); } catch (FileNotFoundException ex) { résultat.setText(); } catch (IOException ex) { résultat.setText(); } } } }); boutons.addSeparator(); boutons.add(résultat); boutons.addSeparator(); pack(); setLocationRelativeTo(null); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) { new CopieFichier(); } }
Lorsque vous sauvegardez vos données dans un fichier (ou autre type de flux de destination), quelque soit leurs natures, vous avez toujours le choix entre le format binaire, donc non éditable, et l'enregistrement sous forme de texte. Par exemple, l'entier 1234 est représenté en binaire (en notation hexadécimale) comme la séquence d'octets 00 00 04 D2. En format texte, c'est la chaîne "1234". Si les entrées/sorties binaires sont rapides et efficaces, elles ne sont pas faites pour l'oeil humain, à l'inverse des entrées/sorties textes que nous allons maintenant examiner.
Lorsque nous sauvegardons des chaînes de caractères, nous devons prendre en compte l'encodage des caractères en Java. Ainsi dans l'encodage UTF-16 (Unicode), le codage en caractères de la chaîne "1234" en est fait (en notation hexadécimale) 00 31 00 32 00 33 00 34.
Malheureusement, la plupart des environnements possèdent aujourd'hui leur propre système de codage de caractères. Ce schéma de codage peut utiliser un octet, deux octets, ou même un nombre variable d'octets. Par exemple, avec l'encodage ISO-8859-1, encodage très utilisé aux états-unis et dans l'Europe de l'ouest, la chaîne précédente sera 31 32 33 34, sans les octets à zéro.
Le codage ISO-8859-15 gagne maintenant en importance, il remplace certains caractères les moins utiles du jeu ISO-8859-1 avec les lettres accentuées en français et en finnois, et surtout, il remplace le caractère de devise internationnale ¤ par le symbole de l'euro € dans le point de code 0xA4.
Si un codage Unicode est écrit vers un fichier texte, il est très improbable que le fichier obtenu reste lisible en utilisant les outils de l'environnement de la machine hôte. Pour contourner ce problème, Java comprend tout un ensemble de flux filtrés qui permettent de passer le texte en codage Unicode aux différents codages de caractères des systèmes d'exploitation.
Toutes ces classes
descendent des classes abstraites Reader et Writer,
et leurs noms sont calqués sur ceux que nous venons de voir. Ainsi la
classe InputStreamReader transforme un flux d'entrées
contenant des octets dans un codage particulier en un lecteur émettant
des caractères Unicode. A l'inverse, la classe OutputStreamWriter transforme un flux de caractères Unicode en un flux d'octets dans un
codage particulier de type caractères.
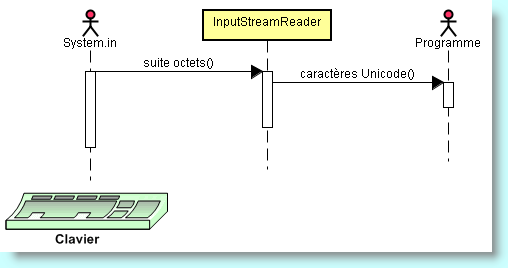
InputStreamReader in = new InputStreamReader(System.in);
Ce lecteur de flux d'entrées utilise par défaut le jeu de caractères normal du système hôte. Par exemple, se sera le codage ISO 8859-1 pour l'Europe de l'ouest (encore appelé ISO Latin-1 ou, pour les programmeurs Windows, "code ANSI"). Nous pouvons choisir un codage différent en le spécifiant au moment de la construction de l'InputStreamReader.
InputStreamReader in = new InputStreamReader(new FileInputStream("monnaie.txt"), "ISO8859_15");
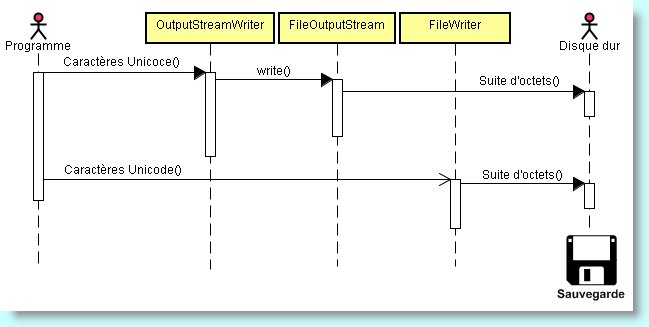
FileWriter fichier = new FileWriter("Texte.txt"));
OutputStreamWriter out = new OutputStreamWriter(new FileOutputStream("Texte.txt"));
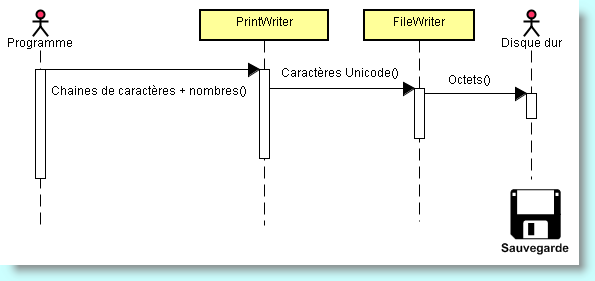
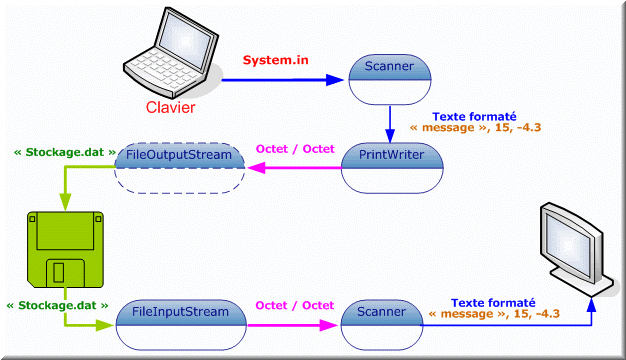
Pour sortir du texte, nous pouvons utiliser l'objet PrintWriter. Cet outil permet d'afficher des chaînes et des nombres dans le format texte. Il existe pas mal de constructeur adaptés à la situation que vous désirez. Par défaut, la construction d'un PrintWriter est associée à un FileWriter. Ainsi les deux constructions suivantes sont équivalentes :
PrintWriter sortie = new PrintWriter("Texte.txt");
PrintWriter sortie = new PrintWriter(new FileWriter("Texte.txt"));
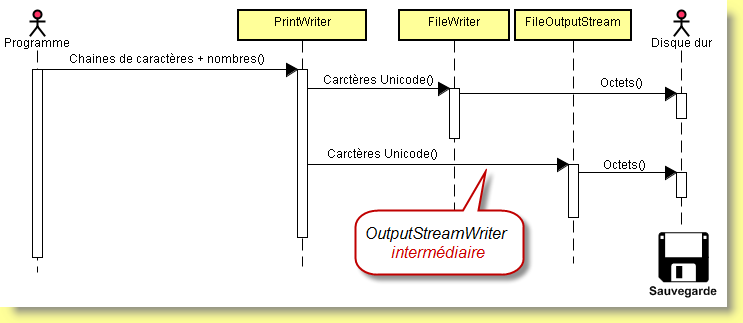
PrintWriter sortie = new PrintWriter(new FileOutputStream("Texte.txt"));
Le constructeur PrintWriter(OutputStream ...) ajoute automatiquement un OutputStreamWriter pour convertir le flux de caractères Unicode vers un flux d'octets classique.
§
PrintWriter sortie = new PrintWriter("Texte.txt");
String nom = "REMY";
double réel = 12.5;
sortie.print(nom);
sortie.print(' ');
sortie.println(réel);
//-------------------------------- Résultat
REMY 12.5
L'ensemble des valeurs envoyées dans le flux sont converties en caractères pour être ensuite transformées en flot d'octets, et pour finir, sont enregistrées dans le fichier "Texte.txt".
La méthode println() ajoute automatiquement, à la suite des caractères envoyées qui constituent la chaîne, les caractères supplémentaires de fin de ligne qui conviennent au système cible ("\r\n" pour Windows, "\n" pour UNIX ou "\r" pour Macintosh). Ces chaînes supplémentraires sont renvoyées par l'appel à la méthode System.getProperty("line.separator").
PrintWriter sortie = new PrintWriter(new FileWriter("Texte.txt"), true); // autoflush
Les méthodes print() ne lancent pas d'exception. La méthode checkError() permet de savoir s'il s'est produit un problème avec le flux.
§
Nous ne pouvons pas envoyer du binaire à un objet PrintWriter. Il ne sait traiter que des sorties au format texte.
§
Nous savons déjà que nous pouvons utiliser :
Ainsi, nous pouvons légitimement penser qu'il existe une classe permettant de lire les données au format texte symétrique de DataInputStream.
Scanner entrée = new Scanner(new FileInputStream("Texte.txt"));
BufferedReader entrée = new BufferedReader(new FileReader("Texte.txt"));
String ligne; while ((ligne = entrée.readLine()) != null ) { // Faire quelque chose avec ligne }
BufferedReader clavier = new BufferedReader(new InputStreamReader(System.in));
String ligne = clavier.readLine(); double réel = Double.parseDouble(ligne);
Scanner clavier = new Scanner(System.in);
double réel = clavier.nextDouble();
Nous allons démontrer les fonctionnalités de chacun de ces flux d'entrée de texte. Pour cela, nous allons fabriquer un tout petit éditeur qui affiche et qui édite le contenu d'un fichier texte. Nous utilisons sur l'interface graphique un JTextArea. Je rappelle que ce composant est tout-à-fait capable de récupérer le texte d'un fichier directement à partir de sa méthode read(). Toutefois, afin de bien valider le comportement de chacun de ces flux d'entrée de texte, nous proposerons, à la place de cette méthode native read(), tous les flux ainsi que toutes les procédures de lecture correspondant au choix effectué.
Editeur de fichier texte au travers d'un composant JTextArea
package flux; import java.awt.*; import java.awt.event.*; import java.io.*; import javax.swing.*; public class Edition extends JFrame { private JFileChooser sélection = new JFileChooser(); private JToolBar boutons = new JToolBar(); private JTextArea éditeur = new JTextArea(30, 60); private JLabel nomFichier = new JLabel(); public Edition() { super(); add(boutons, BorderLayout.NORTH); add(new JScrollPane(éditeur)); éditeur.setBackground(Color.YELLOW); boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showOpenDialog(null) == JFileChooser.APPROVE_OPTION) { File fichier = sélection.getSelectedFile(); nomFichier.setText(fichier.getPath()); try { éditeur.read(new FileReader(fichier), null); } catch (FileNotFoundException ex) { nomFichier.setText(); } catch (IOException ex) { nomFichier.setText(); } } } }); boutons.addSeparator(); boutons.add(nomFichier); pack(); setLocationRelativeTo(null); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) { new Edition(); } }
... boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showOpenDialog(null) == JFileChooser.APPROVE_OPTION) { File fichier = sélection.getSelectedFile(); nomFichier.setText(fichier.getPath()); try { BufferedReader lecture = new BufferedReader(new FileReader(fichier)); éditeur.setText(); String ligne; while ((ligne = lecture.readLine()) != null) éditeur.append(ligne+\n); } catch (FileNotFoundException ex) { nomFichier.setText(); } catch (IOException ex) { nomFichier.setText(); } } } }); ...
... boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showOpenDialog(null) == JFileChooser.APPROVE_OPTION) { File fichier = sélection.getSelectedFile(); nomFichier.setText(fichier.getPath()); try { LineNumberReader lecture = new LineNumberReader(new FileReader(fichier)); éditeur.setText(); String ligne; while ((ligne = lecture.readLine()) != null) { int numéro = lecture.getLineNumber(); éditeur.append(numéro++ligne+\n); } } catch (FileNotFoundException ex) { nomFichier.setText(); } catch (IOException ex) { nomFichier.setText(); } } } }); ...
... boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showOpenDialog(null) == JFileChooser.APPROVE_OPTION) { File fichier = sélection.getSelectedFile(); nomFichier.setText(fichier.getPath()); try { Scanner lecture = new Scanner(fichier); éditeur.setText(); while (lecture.hasNextLine()) éditeur.append(lecture.nextLine()+\n); } catch (FileNotFoundException ex) { nomFichier.setText(); } } } }); ...
Le passage par la classe Scanner simplifie considérablement le code :
... boutons.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (sélection.showOpenDialog(null) == JFileChooser.APPROVE_OPTION) { File fichier = sélection.getSelectedFile(); nomFichier.setText(fichier.getPath()); try { Scanner lecture = new Scanner(fichier); éditeur.setText(); int numéro = 0; while (lecture.hasNextLine()) éditeur.append(++numéro++lecture.nextLine()+\n); } catch (FileNotFoundException ex) { nomFichier.setText(); } } } }); ...
La classe Scanner est une classe très polyvalente. Sa spécialité, c'est la décomposition de texte. Certe, cette classe Scanner peut prendre en entrée des textes venant d'un fichier ou d'un flux quelconque, mais également et tout simplement des chaînes de caractères.
Si vous ne spécifiez pas de jeu de délimiteurs, le paramètre par défaut est " \t\n\r", à savoir tous les caractères d'espace vide (espace, tabulation, nouvelle ligne et retour chariot).
§
Un objet Scanner peut décomposer le texte qu'il reçoit en entrée en occurences séparées par un espace blanc ou par tout autre caractère de délimitation ou expression régulière. Scanner définit aussi une variété de méthodes utilitaires pour analyser les occurences sous forme de valeur booléenne, entières ou à virgule flottante, avec une analyse syntaxique des nombres prenant en compte les paramètres de localisation. Elle possède des méthodes skip() pour éviter les occurences correspondant à un motif spécifié, ainsi que des méthodes permettant de chercher vers l'avant des occurences correspondante à un motif spécifié.
La classe Scanner n'analyse pas seulement des littéraux entiers ou réels. Elle sait aussi reconnaître les séparateurs de milliers ainsi que le séparateur de la partie décimale conformément au pays concerné. Dans le cas de la France, nous pouvons donc avoir en entrée la valeur suivante : 1 234,45.
Si vous ne spécifiez pas de jeu de délimiteurs, le paramètre par défaut est " \t\n\r", à savoir tous les caractères d'espace vide (espace, tabulation, nouvelle ligne et retour chariot).
Si vous ne spécifiez pas de jeu de délimiteurs, le paramètre par défaut est " \t\n\r", à savoir tous les caractères d'espace vide (espace, tabulation, nouvelle ligne et retour chariot).
Deux classes permettent d'encapsuler des chaînes de caractères sous forme de flux : une pour la lecture StringReader, et une pour l'écriture StringWriter.
StringReader est une autre classe très utile ; elle enveloppe la fonctionnalité d'un stream autour d'un objet String. Voici comment l'utiliser :
String texte = "Il été une fois ...";
StringReader flux = new StringReader(texte);
...
char I = (char)flux.read();
char l = (char)flux.read();
La classe StringReader s'avère utile pour lire les données d'un String comme si elle provenaient d'un flux, comme un fichier, un tube ou une socket. Par exemple, vous créez un analyseur syntaxique qui souhaite lire des motifs à partir d'un flux. Mais vous souhaitez fournir une méthode capable de traiter une grande chaîne. Vous pouvez facilement en ajouter une en utilisant StringReader.
Par ailleurs, la classe StringWriter nous permet d'écrire dans un tampon de caractères par l'intermédiaire d'un flux de sortie. Le tampon interne grossit à volonté pour s'adapter aux données. Lorsque nous avons terminé, nous pouvons récupérer son contenu sous forme de String. Dans l'exemple ci-dessous, nous créons un objet StringWriter que nous enveloppons dans un objet PrintWriter par commodité :
StringWriter tampon = new StringWriter();
PrintWriter sortie = new PrintWriter(tampon);
...
sortie.println("Un jour, un élan a frappé ma soeur ") ;
sortie.println("Non, vraiment !") ;
...
String résultat = tampon.toString() ;
Tout d'abord, nous imprimons quelques lignes sur le flux de sortie, pour lui fournir des données, puis nous récupérons le résultat sous la forme d'une chaîne de caractères avec la méthode toString().
C'est notamment le cas pour les pages JSP. En effet, lorsque nous désirons fabriquer de nouvelles balises, il est possible de récupérer le corps de cette dernière au moyen de la méthode invoke(). Cependant, cette méthode attend normalement en argument un flux de type Writer. C'est à ce moment là que nous pouvons donc proposer un flux de type StringWriter ainsi, il sera facile de retrouver le texte qui constitue le corps de la balise au moyen de la méthode toString().
Voici une portion de code qui relate cette analyse :
21 public void doTag() throws JspException, IOException { 22 StringWriter corps = new StringWriter(); 23 this.getJspBody().invoke(corps); 24 intitulé = corps.toString(); 25 ((Tableau) this.getParent()).nouvelleColonne(this); 26 }
Nous pouvons travailler avec des classes qui, d'une part sont capable de travailler sur du texte, et en même temps de transiter l'information sous forme de flots d'octets - plutôt qu'avec des flots de caractères. C'est particulièrement utile lorsque nous devons propager des messages sur le réseau. En effet, la communication entre deux processus répartis sur deux ordinateurs différents ne s'effectue qu'au travers des sockets. Ces dernières ne proposent le transfert d'information qu'au moyen de flux d'octets. Deux classes permettent de maitrîser parfaitement cette architecture ; Il s'agit de la classe PrintWriter pour la sortie, et la classe Scanner pour l'entrée. De plus, ces classes ont la particularité de pouvoir travailler sur du texte normal aussi bien que sur du texte formaté, c'est à dire, du texte fabriqué à partir de valeur entière, réelle, etc.
Nous pouvons travailler en entrée avec la classe BufferedReader déjà vus, mais attention cette dernière récupère des flots de caractères, il est alors nécessaire d'utiliser également la classe InputStreamReader pour transformer le flots d'octets en flots de caractères. Par ailleurs, la classe Scanner est plus avantageuse puisqu'elle est capable de reconnaître des nombres dans la suite des caractères proposés dans le texte récupéré.
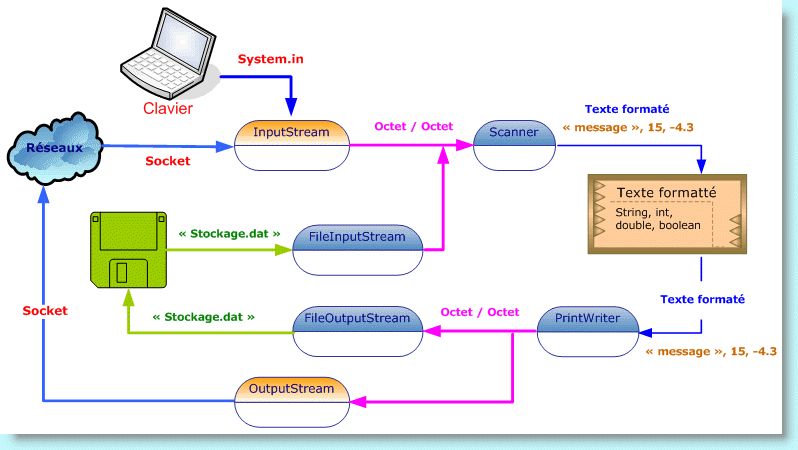
Nous allons maintenant fabriquer deux programmes. Le premier programme permet de stocker un ensemble d'informations de type quelconques (String, int, double) dans un fichier sous formes de texte. Ce fichier, lui, ne sera pas éditable. Le deuxième programme récupère cette série d'information afin de l'afficher ensuite à l'écran.
Sauvegarde et restitution de textes (formatés) dans un fichier non éditable
package texte; import java.io.*; public class EcritureFichier { public static void main(String[] args) throws FileNotFoundException { PrintWriter écrire = new PrintWriter("Stockage.dat"); écrire.println("message"); int entier = 15; écrire.println(entier); double réel = -4.3; écrire.println(réel); écrire.close(); } }
message 15 -4.3 // Attention, l'écriture du réel reste en format américain. Il faudra en tenir compte lors de la lecture par la classe Scanner.
package texte; import java.io.*; import java.util.*; import static java.lang.System.*; public class LectureFichier { public static void main(String[] args) throws FileNotFoundException { Scanner lire = new Scanner(new FileInputStream("Stockage.dat")); lire.useLocale(Locale.US); String message = lire.next(); out.println("Texte = "+message); int entier = lire.nextInt(); out.println("Entier = "+entier); double réel = lire.nextDouble(); out.println("Réel = "+réel); } }
Dans cet exemple, nous avons stocké différents types d'information dans un fichier texte. Nous pouvons utiliser ce principe mais cette fois-ci pour transiter différents types d'information sur le réseau. En réalité, mis à part la mise en oeuvre des sockets, la gestion des flux s'établie de la même façon.
Ce sujet est traité dans la partie Programmation réseau.
§
A titre de conclusion, je vous propose de prendre un dernier exemple qui valide bien les fonctionnalités des flux de texte, en sortie comme en entrée. Nous allons mettre en oeuvre une petite application graphique qui réalise du tracé de formes (Cercle, Carré, etc.). Ces formes seront introduites, après sélection de son type et de sa largeur, au moyen d'un clic de la souris sur la zone d'édition. Une fois que le tracé est réalisé, il est possible d'enregistrer l'ensemble du dessin dans un fichier au format texte.
Les formes sont en réalité des objets. Chaque objet sera inscrit dans une ligne à part entière dans le fichier texte. Le début de la ligne stipulera le type de la forme. Les informations écrites ensuites sur la même ligne précisera la valeur des attributs de l'objet. Chacune de ces informations atomiques seront séparées par le symbole ":".
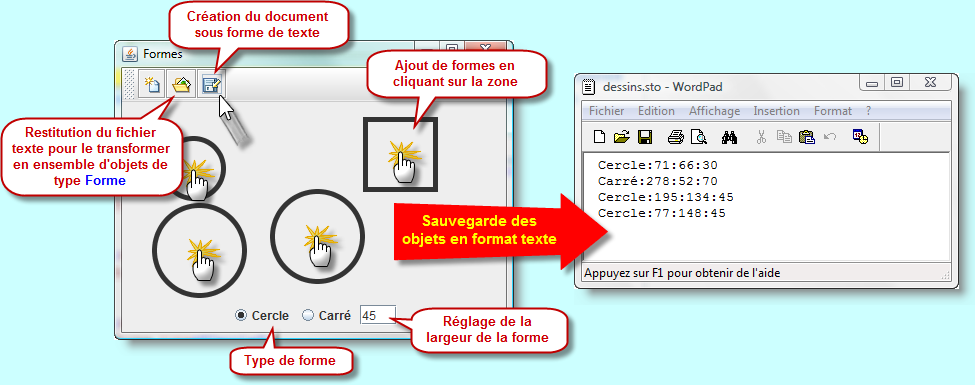
package flux; import javax.swing.*; import java.awt.*; import java.awt.event.*; import java.io.*; import java.lang.reflect.Constructor; import java.util.*; public class Formes extends JFrame { private JRadioButton cercle = new JRadioButton(, true); private JRadioButton carré = new JRadioButton(); private JFormattedTextField largeur = new JFormattedTextField(50); private ButtonGroup groupe = new ButtonGroup(); private JPanel boutons = new JPanel(); private Panneau panneau = new Panneau(); private JToolBar barre = new JToolBar(); public Formes() { super(); largeur.setColumns(3); add(barre, BorderLayout.NORTH); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.effacer(); } }); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.ouvrir(); } }); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.enregistrer(); } }); panneau.addMouseListener(new MouseAdapter() { @Override public void mouseClicked(MouseEvent e) { int dimension = (Integer)largeur.getValue(); if (cercle.isSelected()) panneau.ajoutForme(new Cercle(e.getX(), e.getY(), dimension)); else panneau.ajoutForme(new Carré(e.getX(), e.getY(), dimension)); } }); add(panneau); boutons.add(cercle); boutons.add(carré); boutons.add(largeur); groupe.add(cercle); groupe.add(carré); add(boutons, BorderLayout.SOUTH); setSize(400, 300); setLocationRelativeTo(null); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) { new Formes(); } abstract class Forme { protected int x, y; public Forme() {} public Forme(int x, int y) { this.x = x; this.y = y; } public void déplace(int dx, int dy) { x += dx; y += dy; } abstract public void affiche(Graphics g); abstract public int getDimension(); public int getX() { return x; } public int getY() { return y; } } class Cercle extends Forme { private int rayon = 50; public Cercle(int x, int y, int r) { super(x, y); rayon = r; } public Cercle(int x, int y) { super(x, y); } public Cercle() {} public int getDimension() { return rayon; } public void affiche(Graphics g) { g.drawOval(x-rayon, y-rayon, 2*rayon, 2*rayon); } } class Carré extends Forme { private int côté = 100; public Carré(int x, int y, int c) { super(x, y); côté = c; } public Carré(int x, int y) { super(x, y); } public Carré() {} public int getDimension() { return côté; } public void affiche(Graphics g) { g.drawRect(x-côté/2, y-côté/2, côté, côté); } } class Panneau extends JComponent { private ArrayList<Forme> formes = new ArrayList<Forme>(); @Override protected void paintComponent(Graphics g) { Graphics2D surface = (Graphics2D) g; surface.setStroke(new BasicStroke(5)); surface.setRenderingHint(RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON); for (Forme forme : formes) forme.affiche(g); } public void ajoutForme(Forme forme) { formes.add(forme); repaint(); } public void effacer() { formes.clear(); revalidate(); repaint(); } public void enregistrer() { try { PrintWriter écrire = new PrintWriter(); for (Forme f : formes) écrire.printf(\n, f.getClass().getSimpleName(), f.getX(), f.getY(), f.getDimension()); écrire.close(); } catch (FileNotFoundException ex) { setTitle(); } } public void ouvrir() { try { Scanner lecture = new Scanner(new FileReader()); formes.clear(); while (lecture.hasNextLine()) { Scanner ligne = new Scanner(lecture.nextLine()); ligne.useDelimiter(); if (ligne.next().equals()) formes.add(new Cercle(ligne.nextInt(), ligne.nextInt(), ligne.nextInt())); else formes.add(new Carré(ligne.nextInt(), ligne.nextInt(), ligne.nextInt())); } repaint(); } catch (FileNotFoundException ex) { setTitle(); } } } }
Nous retrouvons les deux principales classes pour la gestion des flux de texte en sortie et en entrée, savoir PrintWriter et Scanner. De plus, dans ce projet, j'utilise deux fois la classe Scanner, la première pour récupérer chaque ligne du fichier et la seconde pour récupérer chaque élément de la ligne en prenant en compte l'opérateur de séparation ":".
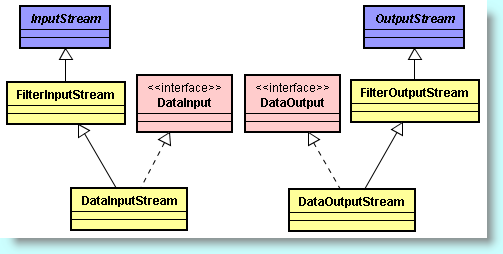
Il est généralement nécessaire d'écrire ou de relire le résultat d'un calcul. Les flux de données possèdent des méthodes pour lire tous les types de base de Java. Les classes DataInputStream et DataOutputStream sont spécialisées dans ce domaine.
En réalité, ces classes implémentent les interfaces respectives DataInput et DataOutput qui spécifient les méthodes de traitement sur les nombres, les caractères, les valeurs booléennes, et même les chaînes de caractères (en format binaire).
Par exemple, la méthode writeInt() écrit toujours un entier sur 4 octets consécutifs, quel que soit le nombre de chiffres, et la méthode writeDouble() écrit toujours un réel avec 8 octets consécutifs. Les sorties binaires qui en résultent ne sont évidemment pas directement lisibles par l'homme, mais l'espace nécessaire en mémoire ou sur le disque sera le même pour une valeur d'un type donné, optimisant ainsi les entrées/sorties. C'est notamment beaucoup plus rapide que le transcodage supplémentaire d'une chaîne vers son équivalent numérique.
Personne d'autre n'utilisant UTF-8 modifié, n'employez la méthode writeUTF() que pour écrire des chaînes destinées à une même machine virtuelle Java, par exemple si vous écrivez un programme qui génère des bytecodes. Vous utiliserez la méthode writeChars() dans tous les autres cas.
Le format de données binaires est compact et indépendant des plate-formes. Il convient à l'accès direct, sauf pour les chaînes UTF. Le seul inconvénient - majeur - des fichiers binaires est que l'oeil humain ne peut les lires.
DataInputStream lecture = new DataInputStream(new FileInputStream("sauvegarde.sto"));
DataOutputStream écriture = new DataOutputStream(new FileIOutputStream("sauvegarde.sto"));
A titre de conclusion, je vous propose de reprendre l'application précédente. Cette fois-ci toutefois, l'enregistrement des objets ne se fera plus en format texte, mais plutôt au travers de données primitives.
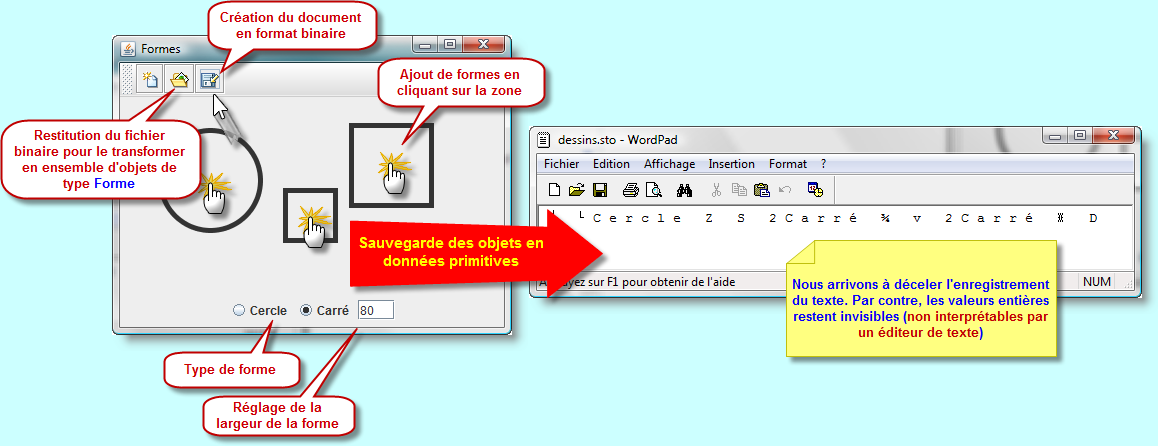
...
public void enregistrer() {
try {
DataOutputStream écrire = new DataOutputStream(new FileOutputStream());
écrire.writeInt(formes.size()); // précise le nombre de formes sauvegardées
for (Forme forme : formes) {
écrire.writeUTF(forme.getClass().getSimpleName());
écrire.writeInt(forme.getX());
écrire.writeInt(forme.getY());
écrire.writeInt(forme.getDimension());
}
écrire.close();
}
catch (FileNotFoundException ex) { setTitle(); }
catch (IOException ex) { setTitle(); }
}
public void ouvrir() {
try {
DataInputStream lecture = new DataInputStream(new FileInputStream());
formes.clear();
int nombreForme = lecture.readInt();
for (int i=0; i<nombreForme; i++) {
String typeForme = lecture.readUTF();
int x = lecture.readInt();
int y = lecture.readInt();
int dimension = lecture.readInt();
if (typeForme.toString().equals()) formes.add(new Cercle(x, y, dimension));
else formes.add(new Carré(x, y, dimension));
}
lecture.close();
repaint();
}
catch (FileNotFoundException ex) { setTitle(); }
catch (IOException ex) { setTitle(); }
}
}
}
La classe de flux RandomAccessFile permet de chercher ou d'écrire des données depuis n'importe quel emplacement d'un fichier. Elle implémente les deux interfaces DataInput et DataOutput.
Les fichiers sur disque sont en accès direct, mais le flux de données provenant d'un réseau ne le sont pas.
§
RandomAccessFile lecture = new RandomAccessFile("direct.sto", "r");
RandomAccessFile lectureEcriture = new RandomAccessFile("direct.sto", "rw");
Un fichier existant ouvert en accès direct en tant que RandomAccessFile n'est pas écrasé.
§
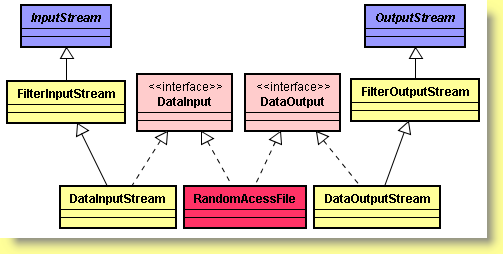
L'intérêt de la classe RandomAccessFile est qu'elle implément simultanément DataInput et DataOutput, ce qui permet d'utiliser des méthodes (pour lire et pour écrire) dont les types d'arguments sont ceux des interfaces DataInput et DataOutput. Ainsi par exemple, lorsqu'une méthode attend un DataInput, nous pouvons tout aussi bien choisir un DataInputStream qu'un RandomAccessFile.
Nous allons reprendre l'application précédente dans laquelle nous allons rajouter de nouvelles fonctionnalités. Effectivement, je vous propose de permettre la modification d'une forme déjà introduite. Cette modification est alors prise en compte instantanément dans le fichier directement à l'endroit où elle été déjà enregistrée.
Quelques petites modifications supplémentaires ont été apportées. D'une part, vous remarquez que le bouton d'enregistrement n'existe plus. Effectivement à chaque introduction d'une nouvelle forme, elle est automatiquement enregistrée dans le fichier. A ce sujet, j'ai conservé l'ancienne façon d'enregistrer, avec donc un DataOutputStream, pour bien montrer que cette classe est tout-à-fait compatible avec un RandomAccessFile. Par ailleurs, j'ai rajouté une case à cocher pour permettre le mode modification ainsi qu'une liste déroulante pour sélectionner la forme à rééditer.
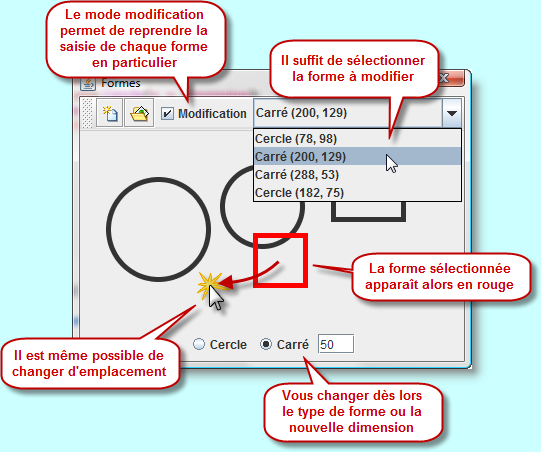
package flux; import javax.swing.*; import java.awt.*; import java.awt.event.*; import java.io.*; import java.util.*; public class Formes extends JFrame { private JRadioButton cercle = new JRadioButton(, true); private JRadioButton carré = new JRadioButton(); private JFormattedTextField largeur = new JFormattedTextField(50); private ButtonGroup groupe = new ButtonGroup(); private JPanel boutons = new JPanel(); private Panneau panneau = new Panneau(); private JToolBar barre = new JToolBar(); private JCheckBox modification = new JCheckBox(); private JComboBox choix = new JComboBox(); public Formes() { super(); largeur.setColumns(3); add(barre, BorderLayout.NORTH); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.effacer(); } }); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.ouvrir(); } }); barre.add(modification); barre.add(choix); ActionListener rafraîchir = new ActionListener() { public void actionPerformed(ActionEvent e) { if (choix.getItemCount()>0) panneau.rafraîchir(); } }; modification.addActionListener(rafraîchir); choix.addActionListener(rafraîchir); ActionListener changerForme = new ActionListener() { public void actionPerformed(ActionEvent e) { if (modification.isSelected()) panneau.changerForme(); } }; cercle.addActionListener(changerForme); carré.addActionListener(changerForme); largeur.addActionListener(changerForme); panneau.addMouseListener(new MouseAdapter() { @Override public void mouseClicked(MouseEvent e) { int dimension = (Integer)largeur.getValue(); if (cercle.isSelected()) panneau.gérerForme(new Cercle(e.getX(), e.getY(), dimension)); else panneau.gérerForme(new Carré(e.getX(), e.getY(), dimension)); } }); add(panneau); boutons.add(cercle); boutons.add(carré); boutons.add(largeur); groupe.add(cercle); groupe.add(carré); add(boutons, BorderLayout.SOUTH); setSize(400, 300); setLocationRelativeTo(null); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) { new Formes(); } abstract class Forme { ... } class Cercle extends Forme { ... } class Carré extends Forme { ... } class Panneau extends JComponent { private ArrayList<Forme> formes = new ArrayList<Forme>(); @Override protected void paintComponent(Graphics g) { Graphics2D surface = (Graphics2D) g; surface.setStroke(new BasicStroke(5)); surface.setRenderingHint(RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON); for (Forme forme : formes) forme.affiche(g); if (modification.isSelected()) { surface.setColor(Color.RED); formes.get(choix.getSelectedIndex()).affiche(g); } } public void gérerForme(Forme forme) { if (modification.isSelected()) { formes.set(choix.getSelectedIndex(), forme); modifier(forme); } else { formes.add(forme); enregistrer(); } repaint(); } public void rafraîchir() { Forme forme = formes.get(choix.getSelectedIndex()); if (forme.getClass().getSimpleName().equals()) cercle.setSelected(true); else carré.setSelected(true); largeur.setValue(forme.getDimension()); repaint(); } public void changerForme() { Forme forme = formes.get(choix.getSelectedIndex()); int x = forme.getX(); int y = forme.getY(); int dimension = (Integer)largeur.getValue(); if (cercle.isSelected()) forme = new Cercle(x, y, dimension); else forme = new Carré(x, y, dimension); formes.set(choix.getSelectedIndex(), forme); modifier(forme); repaint(); } public void effacer() { formes.clear(); choix.removeAllItems(); modification.setSelected(false); revalidate(); repaint(); } public void enregistrer() { try { DataOutputStream écrire = new DataOutputStream(new FileOutputStream()); écrire.writeInt(formes.size()); for (Forme forme : formes) { écrireChaîneFixe(écrire, forme.getClass().getSimpleName()); écrire.writeInt(forme.getX()); écrire.writeInt(forme.getY()); écrire.writeInt(forme.getDimension()); } écrire.close(); } catch (FileNotFoundException ex) { setTitle(); } catch (IOException ex) { setTitle(); } } public void ouvrir() { try { DataInputStream lecture = new DataInputStream(new FileInputStream()); formes.clear(); choix.removeAllItems(); modification.setSelected(false); int nombreForme = lecture.readInt(); for (int i=0; i<nombreForme; i++) { StringBuilder type = new StringBuilder(7); for (int c=0; c<7; c++) { char ch = lecture.readChar(); if (ch != 0) type.append(ch); } int x = lecture.readInt(); int y = lecture.readInt(); int dimension = lecture.readInt(); if (type.toString().equals()) formes.add(new Cercle(x, y, dimension)); else formes.add(new Carré(x, y, dimension)); choix.addItem(type.toString()++x++y+); } lecture.close(); repaint(); } catch (FileNotFoundException ex) { setTitle(); } catch (IOException ex) { setTitle(); } } public void modifier(Forme forme) { try { RandomAccessFile écrire = new RandomAccessFile(, ); final int TAILLE_FORME = 2*7+4+4+4; écrire.seek(4+choix.getSelectedIndex()*TAILLE_FORME); écrireChaîneFixe(écrire, forme.getClass().getSimpleName()); écrire.writeInt(forme.getX()); écrire.writeInt(forme.getY()); écrire.writeInt(forme.getDimension()); écrire.close(); } catch (FileNotFoundException ex) { setTitle(); } catch (IOException ex) { setTitle(); } } private void écrireChaîneFixe(DataOutput écrire, String type) throws IOException { for (int i=0; i<7; i++) { char ch = 0; if (i < type.length()) ch = type.charAt(i); écrire.writeChar(ch); } } } }
Personnellement, je trouve que l'utilisation de ce type de flux est plus compliqué à gérer que tout ce que nous venons de voir. Effectivement, vous êtes obligés d'avoir une structure rigide au niveau de l'enregistrement de vos données. Il est impératif d'avoir une taille identique pour chaque élément que vous introduisez. Dans notre exemple, je suis dans l'obligation de gérer ma chaîne de caractères, qui évoque le type de forme, avec une taille bien précise, en proposant un enregistrement caractère par caractère. Sauf pour les très gros fichiers, je préfère faire une gestion de modification en mémoire et d'enregistrer ensuite tout le contenu du fichier à l'aide de la classe DataOutputStream.
Les fichiers ZIP sont des archives contenant un ou plusieurs fichiers dans un format en principe compressé. Un fichier ZIP possède un en-tête comprenant un certain nombre d'informations comme le nom du fichier et la méthode de compression utilisée.
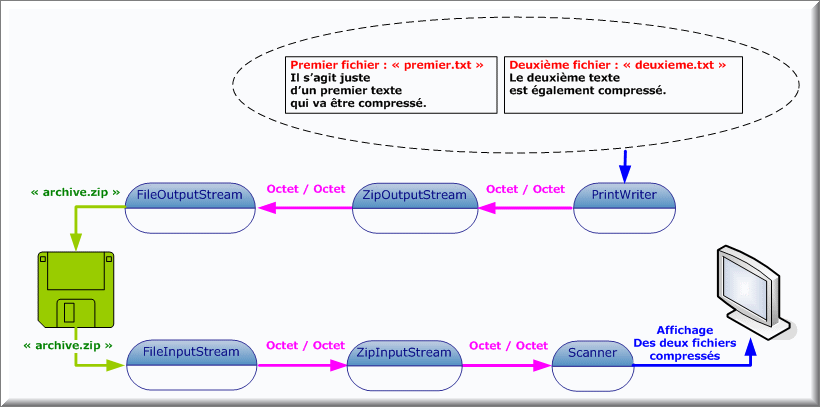
Si vous désirez récupérer des données compressées sur le réseau, vous devez employer un InputStream donné par la socket en lieu et place du flux de fichier FileInputStream.
package compression; import java.io.*; import java.util.zip.*; import java.util.Scanner; import static java.lang.System.*; public class LireArchive { public static void main(String[] args) throws FileNotFoundException, IOException { ZipInputStream archive = new ZipInputStream(new FileInputStream("archive.zip")); ZipEntry fichier; while ((fichier = archive.getNextEntry())!=null) { Scanner lecture = new Scanner(archive); out.println("Fichier : "+fichier.getName()); out.println("-------------------------------------------"); while (lecture.hasNextLine()) { out.println(lecture.nextLine()); } out.println("-------------------------------------------"); // archive.closeEntry(); } archive.close(); } }
Le flux d'entrée ZIP lance une exception ZipException quand une erreur de lecture au niveau d'un fichier ZIP se produit. Cette erreur apparaît normalement lorsque le fichier ZIP est corrompu.
package compression; import java.io.*; import java.util.zip.*; public class EcrireArchive { public static void main(String[] args) throws FileNotFoundException, IOException { ZipOutputStream archive = new ZipOutputStream(new FileOutputStream("archive.zip")); PrintWriter écrire = new PrintWriter(archive, true); archive.putNextEntry(new ZipEntry("Premier.txt")); écrire.println("Il s'agit juste"); écrire.println("d'un premier texte"); écrire.println("qui va être compressé."); archive.putNextEntry(new ZipEntry("Deuxieme.txt")); écrire.println("Le deuxième texte"); écrire.println("est également compressé."); archive.close(); } }
Les fichiers ZIP illustrent bien la puissance d'abstraction d'un flux. Aussi bien la source que la destination de données sont totalement modifiables. Vous empilez l'objet Reader le mieux approprié sur un flux de fichiers ZIP pour lire les données se trouvant sous une forme compressée. L'objet Reader ne sait pas que les données sont décompressées lorsque nous l'activons.
De plus, la source d'octets au format ZIP n'est pas nécessairement un fichier : les données peuvent provenir d'une connexion réseau. De même, lorsque le chargeur de classes d'un applet lit un fichier JAR, il lit et décompresse des données provenant du réseau.
Les fichier JAR sont tout simplement des fichiers ZIP possédant une entrée appelée manifeste. Nous pouvons lire le manifeste avec les classes JarInputStream et JarOutputStream.
§
L'emploi d'enregistrement de longueur fixe convient très bien à des données de même type. En programmation orientée objets, les objets sont rarement de même type. Considérons un tableau appelé formes constitué de l'ensemble des formes situées sur une zone graphique. Certaines cases auront des instances de Cercle, d'autres des instances de Carré, etc.
Il est tout à fait possible, mais très fastidieux, de faire cela à la main. Heureusement, il existe un mécanisme très puissant, appelé "sérialisation des objets" qui travaille à votre place en automatisant presque complètement le processus précédent.
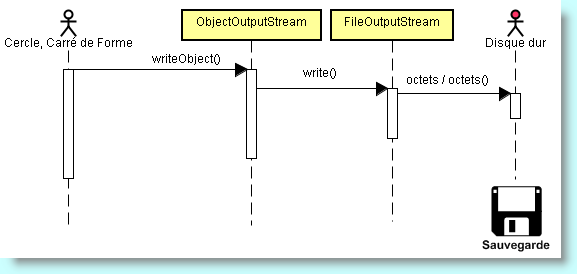
ObjectOutputStream écrire = new ObjectOutputStream(new FileOutputStream("dessins.sto"));
écrire.writeObject(new Cercle(10, 25, 100));
écrire.writeObject(new Carré(75, 12, 48));
ObjectInputStream lire = new ObjectInputStream(new FileInputStream("dessins.sto"));
Cercle cercle = (Cercle) lire.readObject();
Carré carré = (Carré) lire.readObject();
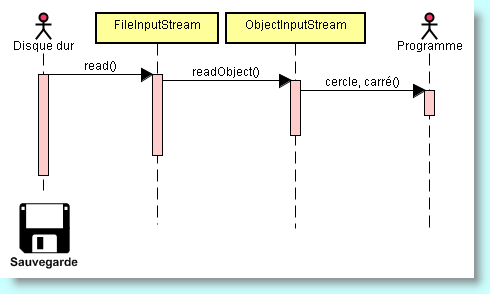
Il faut, lorsque nous rechargeons des objets, respecter exactement le nombre d'objets enregistrés, leur succession, et leurs types. Chaque appel à readObject() lit un autre objet du type Object, qu'il est alors nécessaire de transtyper dans son type exact.
Si le véritable type de l'objet n'est pas connu ou n'est pas utile, il suffit de le transtyper dans le type d'une quelconque de ses superclasses, ou même de le laisser dans le type Object. Il est possible d'obtenir dynamiquement le type d'un objet à l'aide de la méthode getClass().
En réalité, les classes de flux d'objet implémentent les interfaces DataInput et DataOutput au travers des interfaces plus spécifiques ObjectInput et ObjectOutput.
Bien évidemment, les valeur numériques se trouvant à l'intérieur des objets (x, y et rayon d'un objet de type Cercle par exemple) sont enregistrées et rechargées automatiquement.
§
Il faut cependant modifier légèrement toute classe devant être enregistrée et rechargée à partir d'un flux d'objets : la classe doit implémenter l'interface Serializable.
class Forme implements Serializable { ... }
Comme l'interface Serializable ne possède
pas de méthode, il n'y a absolument rien à changer dans vos classes.
Pour rendre une classe sérialisable, il n'y a rien à faire de
plus.
§
Nous allons reprendre notre petite application graphique qui réalise du tracé de formes (Cercle, Carré, etc.). Je rappelle que ces formes sont introduites, après sélection de son type et de sa largeur, au moyen d'un clic de la souris sur la zone d'édition. Une fois que le tracé est réalisé, il est possible de l'enregistrer dans un fichier en sauvegardant directement chacun des objets graphiques.
Les formes étant des objets, il est donc possible de les enregistrer directement dans l'ordre dans lequel ils ont été introduits. La seule condition, c'est qu'ils soient sérialisables. Il faut aussi penser à dénombrer l'ensemble des éléments introduits.
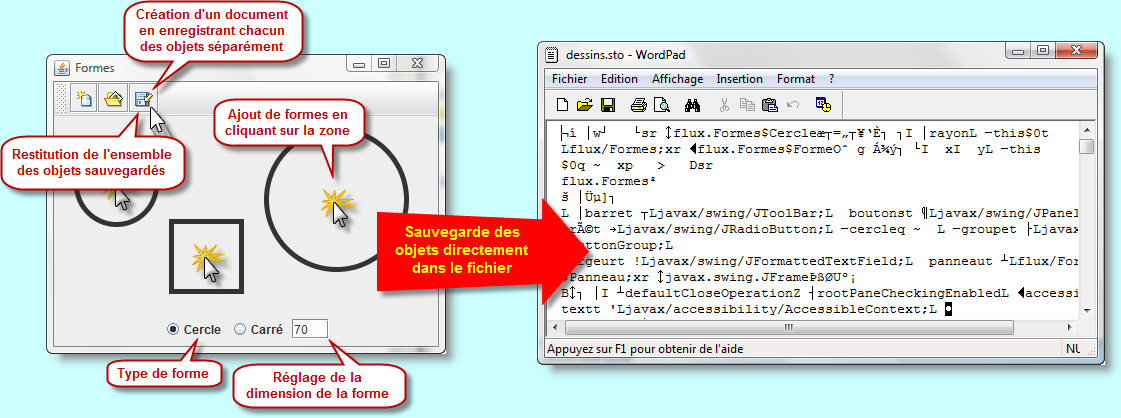
package flux; import javax.swing.*; import java.awt.*; import java.awt.event.*; import java.io.*; import java.lang.reflect.Constructor; import java.util.*; public class Formes extends JFrame { private JRadioButton cercle = new JRadioButton(, true); private JRadioButton carré = new JRadioButton(); private JFormattedTextField largeur = new JFormattedTextField(50); private ButtonGroup groupe = new ButtonGroup(); private JPanel boutons = new JPanel(); private Panneau panneau = new Panneau(); private JToolBar barre = new JToolBar(); public Formes() { super(); largeur.setColumns(3); add(barre, BorderLayout.NORTH); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.effacer(); } }); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.ouvrir(); } }); barre.add(new AbstractAction(, new ImageIcon()) { public void actionPerformed(ActionEvent e) { panneau.enregistrer(); } }); panneau.addMouseListener(new MouseAdapter() { @Override public void mouseClicked(MouseEvent e) { int dimension = (Integer)largeur.getValue(); if (cercle.isSelected()) panneau.ajoutForme(new Cercle(e.getX(), e.getY(), dimension)); else panneau.ajoutForme(new Carré(e.getX(), e.getY(), dimension)); } }); add(panneau); boutons.add(cercle); boutons.add(carré); boutons.add(largeur); groupe.add(cercle); groupe.add(carré); add(boutons, BorderLayout.SOUTH); setSize(400, 300); setLocationRelativeTo(null); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) { new Formes(); } abstract class Forme implements Serializable { // changement important à réaliser pour que toute la hiérarchie de forme soit sérialisable protected int x, y; public Forme() {} public Forme(int x, int y) { this.x = x; this.y = y; } public void déplace(int dx, int dy) { x += dx; y += dy; } abstract public void affiche(Graphics g); abstract public int getDimension(); public int getX() { return x; } public int getY() { return y; } } class Cercle extends Forme { private int rayon = 50; public Cercle(int x, int y, int r) { super(x, y); rayon = r; } public Cercle(int x, int y) { super(x, y); } public Cercle() {} public int getDimension() { return rayon; } public void affiche(Graphics g) { g.drawOval(x-rayon, y-rayon, 2*rayon, 2*rayon); } } class Carré extends Forme { private int côté = 100; public Carré(int x, int y, int c) { super(x, y); côté = c; } public Carré(int x, int y) { super(x, y); } public Carré() {} public int getDimension() { return côté; } public void affiche(Graphics g) { g.drawRect(x-côté/2, y-côté/2, côté, côté); } } class Panneau extends JComponent { private ArrayList<Forme> formes = new ArrayList<Forme>(); @Override protected void paintComponent(Graphics g) { Graphics2D surface = (Graphics2D) g; surface.setStroke(new BasicStroke(5)); surface.setRenderingHint(RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON); for (Forme forme : formes) forme.affiche(g); } public void ajoutForme(Forme forme) { formes.add(forme); repaint(); } public void effacer() { formes.clear(); revalidate(); repaint(); } public void enregistrer() { try { ObjectOutputStream écrire = new ObjectOutputStream(new FileOutputStream()); écrire.writeInt(formes.size()); for (Forme forme : formes) écrire.writeObject(forme); écrire.close(); } catch (FileNotFoundException ex) { setTitle(); } catch (IOException ex) { setTitle(); } } public void ouvrir() { try { ObjectInputStream lire = new ObjectInputStream(new FileInputStream()); formes.clear(); int nombre = lire.readInt(); for (int i=0; i<nombre; i++) formes.add((Forme)lire.readObject()); lire.close(); repaint(); } catch (FileNotFoundException ex) { setTitle(); } catch (ClassNotFoundException ex) { setTitle(); } catch (IOException ex) { setTitle(); } } } }
... public void enregistrer() { try { ObjectOutputStream écrire = new ObjectOutputStream(new FileOutputStream()); écrire.writeObject(formes); écrire.close(); } catch (FileNotFoundException ex) { setTitle(); } catch (IOException ex) { setTitle(); } } public void ouvrir() { try { ObjectInputStream lire = new ObjectInputStream(new FileInputStream()); formes = (ArrayList<Forme>) lire.readObject()); lire.close(); repaint(); } catch (FileNotFoundException ex) { setTitle(); } catch (ClassNotFoundException ex) { setTitle(); } catch (IOException ex) { setTitle(); } } } }
L'enregistrement des objets directement dans le fichier devient alors la technique la plus simple à réaliser grâce à la sérialisation. Par contre la taille du fichier est plus conséquente.
§
Sur cette même application, nous avons réalisé plein de sauvegardes différents. Nous remarquons ici l'intérêt de Java, puisque nous pouvons décider du type d'enregistrement que nous souhaitons faire.
En principe, nos applications ne sont directement concernées que par une seule extrémité de flux. Toutefois, PipedInputStream et PipedOutputStream (ou PipedReader et PipedWriter) permettent de créer deux extrémités d'un stream et de les connecter entre eux. Cela permet, par exemple, de faire communiquer deux Threads concurrents d'une même application au moyen d'un flux.
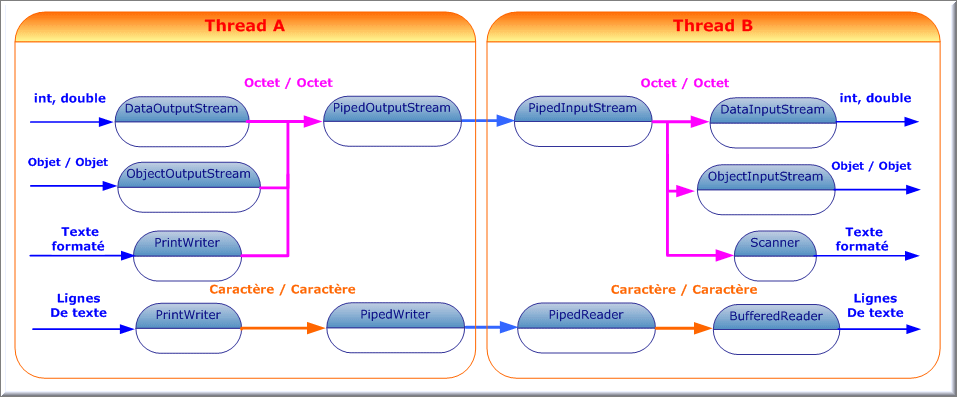
PipedInputStream entrée = new PipedInputStream();
PipedOutputStream sortie = new PipedOutputStream(entrée);
PipedOutputStream sortie = new PipedOutputStream();
PipedInputStream entrée = new PipedInputStream(sortie);
Dans chacun de ces exemples, nous créons un flux d'entrée "entrée" et un flux de sortie "sortie", connectés ensemble. Les données écrites dans le tube de sortie peuvent ensuite être lues par le tube d'entrée. Il est également possible de créer séparément les objets PipedInputStream et PipedOutputStream, puis de les connecter plus tard au moyen de la méthode connect().
De toute façon, pour que ce processus puisse fonctionner, il faut impérativement qu'ils soient connecter ensemble, sinon cela n'aurait aucun sens.
§
PipedReader entrée = new PipedReader();
PipedWriter sortie = new PipedWriter(entrée);
Si le tampon interne du tube est plein, le processus en train d'écrire est bloqué et mis en attente jusqu'à ce que la place soit disponible. Inversement, si le tube est vide, le processus de lecture est bloqué et attend que les données soient présentes
Toutefois, comme pour les autres flux d'octets, nous avons la possibilité d'utiliser des classes de flux de plus haut niveau afin d'encapsuler cette suite d'octets vers des données correspondant à des types connus. Ainsi, nous pouvons utiliser les classes que nous connaissons déjà comme : DataInputStream, ObjectInputStream, Scanner, BufferedReader, etc.
Dans l'exemple ci-dessous, nous développons une application graphique qui permet de récupérer les événements données par la souris, notamment lorsque nous cliquons avec cette dernière. Un Thread récupère chacun de ces événements dans un fichier journal en indiquant les coordonnées de la souris par rapport à la zone cliente de la fenêtre ainsi que l'instant où a eu lieu cet événement.
import java.awt.*; import java.awt.event.*; import java.io.*; import java.util.*; import javax.swing.*; //------------------------------------------------------------------------------------------------- public class Evénement extends JFrame { PipedOutputStream tubeSortie = new PipedOutputStream(); PipedInputStream tubeEntrée = new PipedInputStream(tubeSortie); PrintWriter envoyer = new PrintWriter(tubeSortie, true); Scanner recevoir = new Scanner(tubeEntrée); public static void main(String[] args) throws IOException { new Evénement().setVisible(true); } public Evénement() throws IOException { this.setTitle("Alerte sur les événements"); this.setSize(300, 250); this.setDefaultCloseOperation(EXIT_ON_CLOSE); new Alerte(recevoir).start(); this.getContentPane().addMouseListener(new Souris(envoyer)); } } //------------------------------------------------------------------------------------------------- class Souris extends MouseAdapter { private PrintWriter envoyer; public Souris(PrintWriter envoyer) throws IOException { this.envoyer = envoyer; } public void mouseClicked(MouseEvent evt) { envoyer.println("("+evt.getX()+", "+evt.getY()+')'); } } //------------------------------------------------------------------------------------------------- class Alerte extends Thread { private Scanner recevoir; private PrintWriter journal; public Alerte(Scanner recevoir) throws FileNotFoundException { this.recevoir = recevoir; journal = new PrintWriter(new FileOutputStream("journal.txt"), true); } public void run() { while (true) { String souris = recevoir.nextLine(); journal.println("Souris : "+souris+" : "+new Date()); } } }
Souris : (46, 38) : Mon Jan 23 08:06:37 CET 2006 Souris : (162, 86) : Mon Jan 23 08:06:38 CET 2006 Souris : (124, 200) : Mon Jan 23 08:06:39 CET 2006 Souris : (229, 163) : Mon Jan 23 08:06:39 CET 2006 Souris : (62, 97) : Mon Jan 23 08:06:40 CET 2006 Souris : (15, 59) : Mon Jan 23 08:06:40 CET 2006 Souris : (42, 30) : Mon Jan 23 08:06:40 CET 2006 Souris : (189, 24) : Mon Jan 23 08:06:41 CET 2006
Dans certains cas, il peut être intéressant de travailler avec des flux directement sous forme de tableaux d'octets par l'intermédiaire des classe ByteArrayInputStream ou ByteArrayOutputStream. C'est notamment le cas lorsque nous travaillons avec des images qui transitent sur le réseau ou sur tout autre flux binaire, comme la transmission entre threads.
Effectivement, en local, pour récupérer une image, nous passons directement par la classe ImageIO, sans passer par un intermédiaire quelconque. Dans le cas du réseau, par exemple, il est plus avantageux de récupérer le fichier binaire et d'envoyer les informations brutes, c'est-à-dire le tableau d'octets correspondant sans déformation. Effectivement, la classe ImageIO propose une compression qui n'est pas toujours utile dans le cas notamment d'une simple lecture d'image.
Voici donc toute la procédure à suivre pour récupépérer une image par un tableau d'octets en restant toutefois sur le même poste local :
File fichier = new File(répertoire+"UneImage.jpg"); byte[] octets = new byte[(int)fichier.length()]; FileInputStream photo = new FileInputStream(fichier); photo.read(octets); ByteArrayInputStream fluxImage = new ByteArrayInputStream(octets); BufferedImage image = ImageIO.read(fluxImage);
Voici un autre exemple qui fabrique un tableau d'octets à partir d'une image déjà existante :
BufferedImage image = ... ; ... ByteArrayOutputStream fluxImage = new ByteArrayOutputStream(); ImageIO.write(image, "PNG", fluxImage); byte[] octets = fluxImage.toByteArray();

|
Souvenez-vous qu'à l'utilisation, la méthode concernée affiche le message désiré à l'écran et en même temps récupère la valeur saisie au clavier. Voici un exemple d'utilisation possible :
|
|
Le nombre de formes placées sur la surface de travail est limité à 30. Il doit être possible d'enregistrer l'ensemble du tracé sur le disque dur. En cliquant sur "Nouveau", vous effacer la surface de travail, et vous pouvez de nouveau tracer au maximum les 30 formes. A tout moment, il est possible de récupérer des tracés déjà sauvegardés. Enfin lorsque vous quittez l'application, le système doit vous demander de sauvegarder votre travail. Dans Java, il existe une boîte de dialogue de sélection de fichier toute faite représentée par la classe JFileChooser.
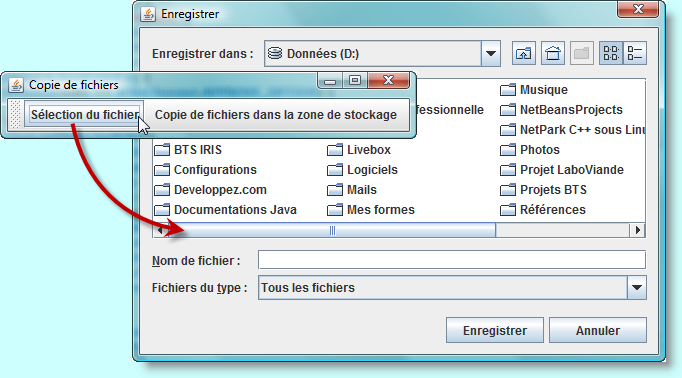
Voici les étapes à suivre pour mettre en oeuvre une boîte de dialogue de fichier et récupérer la sélection de l'utilisateur :
|
 Vous
allez mettre en oeuvre la classe Clavier que vous avez déjà
utilisé qui devra se trouver dans le paquetage saisie et comporter
les quatre méthodes comme cela vous est présenté
ci-contre.
Vous
allez mettre en oeuvre la classe Clavier que vous avez déjà
utilisé qui devra se trouver dans le paquetage saisie et comporter
les quatre méthodes comme cela vous est présenté
ci-contre.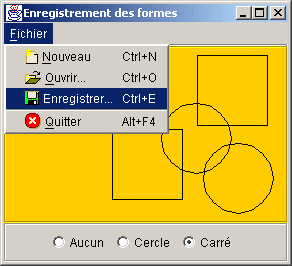 Vous
allez mettre en oeuvre ce petit logiciel qui permet de tracer des formes
de tailles fixes, des cercles et des carrés.
Vous
allez mettre en oeuvre ce petit logiciel qui permet de tracer des formes
de tailles fixes, des cercles et des carrés.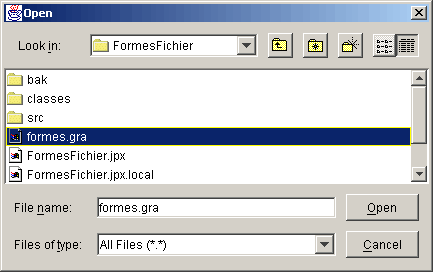
 Les boîtes de dialogue JFileChooser
sont toujours modales. Une boîte de dialogue modale ne permet pas
à l'utilisateur d'interagir avec d'autres fenêtres de l'application
tant qu'elle demeure ouverte. Vous appellerez la méthode showOpenDialog
pour afficher une boîte de dialogue d'ouverture de fichier ou showSaveDialog
pour afficher une boîte de dialogue d'enregistrement de fichier.
Le bouton utilisé pour accepter un fichier est automatiquement
libellé "Open" ou "Save".
Les boîtes de dialogue JFileChooser
sont toujours modales. Une boîte de dialogue modale ne permet pas
à l'utilisateur d'interagir avec d'autres fenêtres de l'application
tant qu'elle demeure ouverte. Vous appellerez la méthode showOpenDialog
pour afficher une boîte de dialogue d'ouverture de fichier ou showSaveDialog
pour afficher une boîte de dialogue d'enregistrement de fichier.
Le bouton utilisé pour accepter un fichier est automatiquement
libellé "Open" ou "Save".