Java Database Connectivity (JDBC) - Langage SQL
Java Database Connectivity (JDBC) - Langage SQL
 Ce chapitre traite essentiellement de la relation entre Java et les bases de données. Dans cette étude, je m'intéresse à l'écriture standard de tout programme Java gérant les bases de données quelque soit l'environnement de développement intégré utilisé. Si vous désirez utiliser des objets spécialisés par rapport à JBuilder, toute une série d'études leurs sont consacrées.
Ce chapitre traite essentiellement de la relation entre Java et les bases de données. Dans cette étude, je m'intéresse à l'écriture standard de tout programme Java gérant les bases de données quelque soit l'environnement de développement intégré utilisé. Si vous désirez utiliser des objets spécialisés par rapport à JBuilder, toute une série d'études leurs sont consacrées.
Pour en savoir plus sur l'environnement de JBuilder avec les objets relatifs aux bases de données.
Les systèmes de base de données non seulement assure le traitement des fichiers, mais en plus organisent les données de manière à faciliter l'obtention des résultats d'une requête complexe. Les bases de données les plus courantes dans les ordinateurs qui utilisent Java sont les bases de données relationnelles.
L'un des principaux obstacles auxquels les programmeurs de bases de données doivent faire face est la grande diversité des formats de bases de données employés actuellement. Chaque serveur de bases de données utilise en fait ses propres techniques, qualifiées de "propriétaires", pour accéder aux données. Afin de simplifier l'utilisation des serveurs de bases de données relationnelles, un langage standard appelé SQL (Structured Query Langage, ou langage de requêtes structuré) a été inventé. Ce langage permet de ne pas avoir à apprendre différents langages de requêtes de bases de données pour les divers formats de bases de données.
Dans le domaine de la programmation de bases de données, l'opération consistant à demander des enregistrements stockés dans une base de données est appelé requête. SQL permet d'envoyer des requêtes complexes à une base de données et d'obtenir les enregistrements demandés, dans l'ordre choisi.
Le programmeur pourra, par exemple, créer une requête demandant de fournir les enregistrements pour lesquels le dernier paiement date de plus de 180 jours et pour lesquels le montant dû est supérieur 100 €. SQL peut également servir à contrôler l'ordre dans lequel les enregistrements sont affichés. Le programmeur peut, par exemple, demander qu'apparaisse d'abord le numéro de Sécurité sociale, puis le nom du bénéficiaire du prêt, le montant dû, etc.
SQL permet d'accomplir toutes ces opérations sans même avoir à apprendre le langage de requête spécifique à la base de données utilisée.
La plupart des formats de bases de données offrent un haut degré de compatibilité avec SQL. En théorie, vous devriez donc pouvoir utiliser les mêmes commandes SQL pour tous les systèmes de gestion de bases de données compatibles avec ce langage. SQL constitue l'approche standard qu'on choisi les éditeurs de logiciels en matière d'accès aux bases de données relationnelles. Parmi les logiciels de bases de données relationnelles les plus connus, mentionnons Microsoft Acces, Sybase, Oracle, Informix, Microsoft SQL Server, MySQL, etc.
Les principales commandes du langage SQL sont spécifiées à la fin de cette étude.
.
Java permet donc aux programmeurs d'écrire du code qui met en oeuvre les requêtes SQL pour retrouver des renseignements dans des bases de données relationnelles, mais ce n'est pas tout. Le langage Java est un langage universel qui, par essence, peut fonctionner sur différentes plate-formes. De plus, il faut que le programme puisse se connecter avec n'importe quel serveur de base de données utilisée dans le commerce. Java doit donc disposer d'un système de connexion polivalent.
La technologie de connectivité de bases de données Java, appelé JDBC (Java Database Connectivity), est une bibliothèque de classes (et surtout d'interfaces) qui permet de travailler avec différents serveurs de bases de données relationnelles. Une fois que la connexion est établie, les interfaces prévues par la JDBC permettent d'obtenir tous les renseignements nécessaires en utilisant tout simplement le langage de requête SQL.
Malheureusement, il y a un "hic" : avant de pouvoir utiliser la bibliothèque de classes JDBC, vous devez configurer une source de données de telle sorte que Java puisse y accéder. Pour cela, vous devez récupérer ce que l'on appelle un pilote correspondant à la base de données relationnelle utilisée. La plupart des fabricants propose de tels pilotes, pour que l'on puisse effectivement se connecter à leur base de données depuis Java.
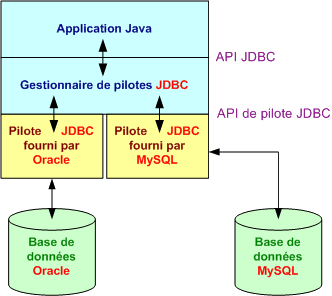 Les programmes Java qui utilisent les interfaces et les classes JDBC peuvent suivre le modèle de programmation traditionnel, qui consiste à formuler des instructions SQL puis à traiter les données qui en résultent. Le format de la base de données et de la plate-forme pour laquelle elle a été conçue n'ont pas d'importance.
Les programmes Java qui utilisent les interfaces et les classes JDBC peuvent suivre le modèle de programmation traditionnel, qui consiste à formuler des instructions SQL puis à traiter les données qui en résultent. Le format de la base de données et de la plate-forme pour laquelle elle a été conçue n'ont pas d'importance.
L'indépendance vis-à-vis de la plate-forme et du format de base de données est assurée par un gestionnaire de pilotes. Les classes de la bibliothèque JDBC sont en effet largement dépendantes de gestionnaires de pilotes, qui permettent de savoir quels pilotes sont nécessaires pour accéder aux enregistrements d'une base de données. Chaque format de base de données utilisé dans un programme nécessite un pilote différent.
Les pilotes de bases de données JDBC sont, la plupart du temps, écrits complètement en Java. L'ensemble du pilote correspond à une bibliothèque (*.jar) et la classe de connexion porte souvent le nom de Driver.
La bibliothèque de classes de JDBC inclut des classes adaptées à chacune des tâches généralement associées aux bases de données. Elle permet en gros de faire trois choses :
Dans cette leçon, nous allons mettre en oeuvre notre première base de données. Les exemples proposé seront simple, le but étant de comprendre tous les mécanismes qui sont en jeu. Le serveur de base de données que j'ai choisi est MySQL, mais il est bien entendu possible d'en choisir un autre, le principe de connexion restant identique.
Il va être nécessaire de régler JBuilder pour qu'il soit capable de se connecter au serveur de base de données MySQL, ce qu'il ne sait pas faire à priori. D'après ce que nous avons étudié au préalable, la connexion ne s'effectue qu'au travers d'un pilote qui doit être récupéré soit par le fournisseur du serveur de base de données, soit éventuellement par l'intermédiaire d'Internet.
Le nom du pilote correspondant au serveur MySQL est de la forme MySQL Connector/J (version). Vous avez, bien entendu, la version pour Linux (tar.gz) et la version pour Windows (zip).
Actuellement, celui que j'utilise s'appelle plus précisément MySQL Connector/J 3.1 . Sur le site, d'autres versions vous sont proposées. Prenez la dernière version stable.
Dernière version stable d’un pilote JDBC pour MySQL : http://dev.mysql.com/downloads/
N'oubliez pas qu'un pilote est constitué d'un ensemble de classes Java qui sont localisées au sein d'une bibliothèque (jar). La première démarche, après avoir récupéré ce fichier compressé, va être d'extraire cette bibliothèque et de la placer à un endroit convenable.
Le fichier que vous venez de récupérer comporte beaucoup plus que la bibliothèque, et il est relativement conséquent.
.
Il ne nous reste maintenant plus qu'à configurer JBuilder pour qu'il reconnaisse cette bibliothèque afin de pouvoir l'intégrer dans les applications gérant les bases de données (pour une connexion avec MySQL, bien entendu).
Souvenez-vous qu'il est possible que ce pilote (cette bibliothèque) soit automatiquement intégré à chaque projet en réglant “Propriété du projet par défaut...”, qui se trouve dans le menu “Projet”. Je n'appliquerais pas cette démarche, parce que tous les projets n'utilisent pas systématiquement les bases de données.
Puisque tout est correctement installé, nous allons voir comment se connecter à une base de données. Cette connexion s'effectue en deux étapes :
Toutes les classes que nous utilisons pour gérer les bases de données nécessite d'importer la paquetage <java.sql>.
import java.sql.*;
Pour tester nos premières requêtes, nous allons constituer une base de données avec une seule table dont voici la définition :
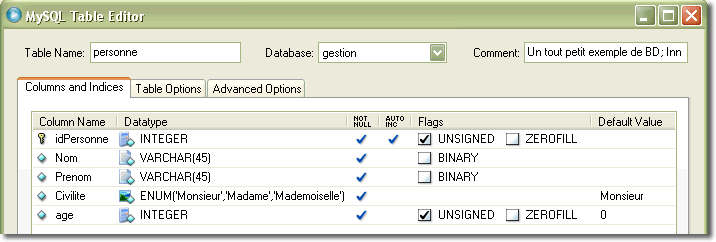
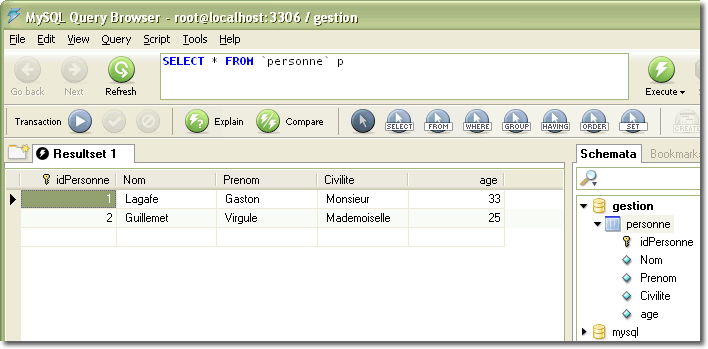
Voici le contenu de la table
Avant tout, nous devons charger en mémoire le pilote que nous souhaitons utiliser pour établir la connexion. Le pilote est représenté par une classe (elle s'appelle toujours Driver - pilote en anglais) et c'est la Machine Virtuelle Java qui s'occupe de son chargement. Cette classe implémente l'interface java.sql.Driver et peut être chargée en appelant la méthode de classe forName de la classe java.lang.Class :
Class.forName("com.mysql.jdbc.Driver"); ou Class.forName("org.gjt.mm.mysql.Driver");
Class.forName(String) : signifie faire construire par la JVM un objet Class contenant toutes les interfaces du programme choisi.
.
Ce chargement manuel est intéressant. Il devient très facile de changer de logiciel de base de données. Seule cette ligne est à modifier. Il suffit de changer le nom du nouveau pilote représentant le nouveau serveur de base de données. Avec cette technique, il est même possible d'utiliser plusieurs serveur de bases de données dans le même programme.
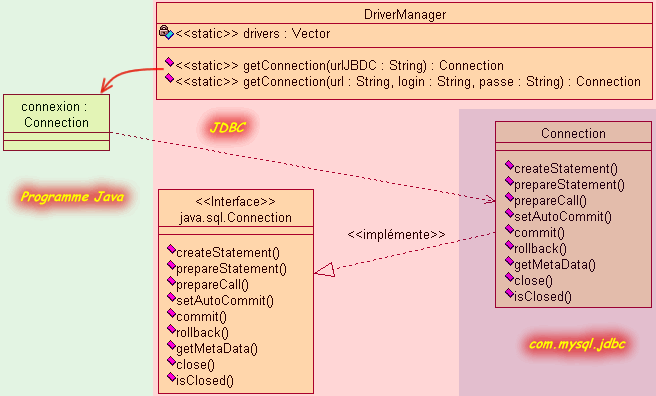
Plus précisément, ce chargement consiste à compléter l'attribut drivers de la classe utilitaire java.sql.DriverManager. Cet attribut est en réalité un vecteur qui permet d'envisager de stocker effectivement plusieurs pilotes et donc de gérer plusieurs serveur de base de données pour une même application Java. Cette classe DriverManager est vraiment prépondérante, puisque c'est elle qui s'occupe de la gestion des serveurs utilisés et qui permet indirectement d'établir la communication entre le programme Java et la (ou les) bases de données.
En réalité, La JDBC est essentiellement composée d'interfaces qui représentent les classes effectives délivrées par la bibliothèque du pilote. Chacune de ces classes porte le même nom que l'interface. La classe DriverManager met juste en relation ces interfaces avec les bonnes classes qui constitue le pilote afin que la communication s'effectue bien sur le bon serveur de base de données. Le programme Java lui ne communique avec la base de données qu'au travers de ces interfaces. Ainsi, grâce à ce système, le programme Java peut s'exécuter avec n'importe quel serveur de base de données. Il suffit juste de récupérer le pilote adapté.
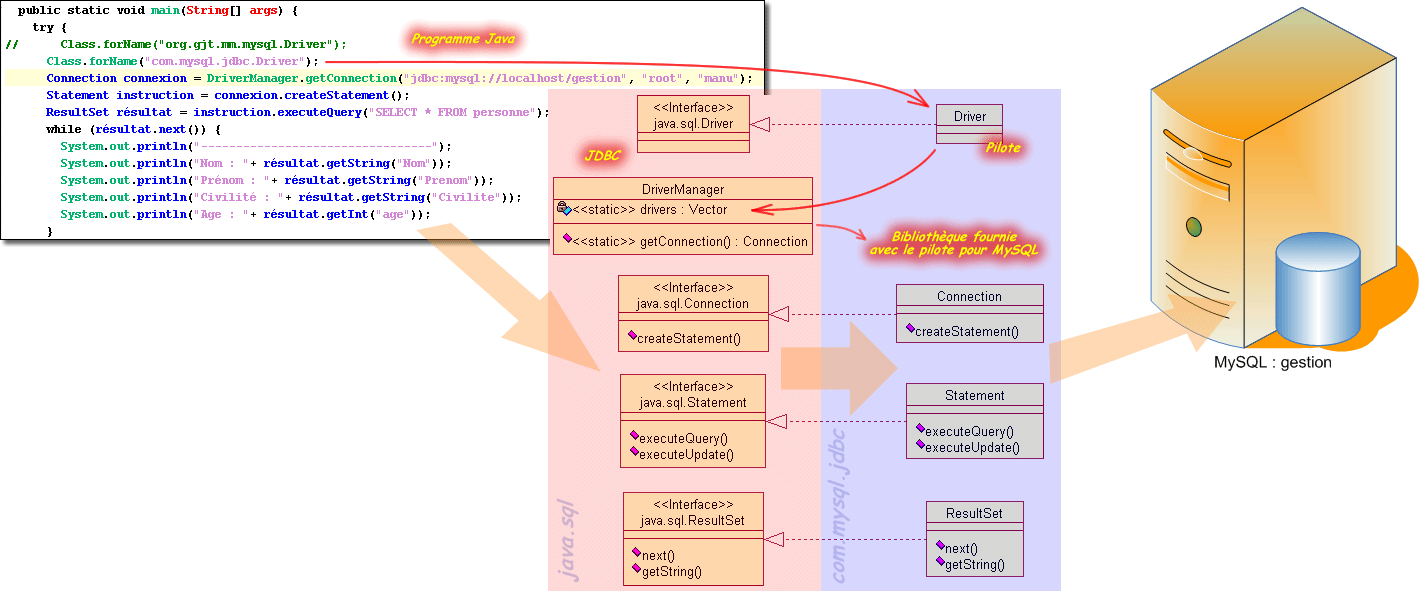
Toute l'infrastructure est prête. Nous pouvons maintenant établir la connexion avec la base de données que nous devons traiter. Nous venons de le voir, le pilote dispose d'un certain nombre d'interface. L'une de ces interfaces disponibles nous sert à établir la connexion avec la base de données ; Il s'agit de java.sql.Connection. C'est une interface spécialisée pour les bases de données et propose de nombreux services.
L'objet de type Connection est capable de nous permettre de décrire :
Par défaut, Connection est en mode auto-commit, c'est-à-dire que chaque changement dans la base est effectivement enregistré après l'exécution de chaque requête.
Pour que cet objet soit correctement initialisé, il est nécessaire de faire appel au service permettant de gérer les pilotes JDBC à l'aide de la classe DriverManager, que nous venons de voir plus haut, et d'effectuer la connexion proprement dite grâce à la méthode de classe getConnection(String).
Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion?user=root&password=manu");
Examinons chacun des termes de cette instruction. La méthode getConnection est appelée :
Lorsque la connexion est enfin réalisée, la méthode getConnection() retourne en résultat un objet de la classe qui implémente l'interface java.sql.Connection. Cet objet est essentiel, puisque c'est ensuite à travers lui que va s'effectuer la communication entre votre programme Java et la base de donnée MySql (par exemple).
Pour établir une connexion, il est nécessaire d'indiquer les informations telles que le protocole utilisé, le lieu où se trouve la base de données, le nom d'utilisateur et son mot de passe. Le protocole ainsi que le lieu où se trouve la base de données s'écrivent sous la forme d'une URL, appelée communément URL JDBC. Elle s'écrit comme suit :
"jdbc:mysql://" + nomHôte + " : " + port + " / " + nomDeLaBase + "?user=" + utilisateur + "&password=" + motDePasse
où :
Le nom d'utilisateur ainsi que son mot de passe sont nécessaires à la mise en place d'une connexion. En effet, il existe différents types d'utilisateurs allant du simple consultant à l'administrateur en passant par le gestionnaire. Pour distinguer chaque utilisateur et déterminer son droit d'accès, l'administrateur de la base crée des comptes utilisateurs caractérisés par un login et un mot de passe.
Nous disposons aussi de la méthode getConnection avec deux paramètres supplémentaires représentant respectivement un utilisateur référencé par l'administrateur de la base de données et son mot de passe. Cette deuxième méthode permet de bien séparer l'utilisateur de la localisation de la base de données. Par ailleurs, la syntaxe s'en trouve simplifiée. Personnellement, je préfère cette deuxième approche.
Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu");
Nous venons de le voir, la connexion renvoyée par la méthode getConnection de la classe java.sql.DriverManager est l'objet qui est principalement utilisé pour effectuer des opérations sur la base de données. La classe de cet objet implémente l'interface java.sql.Connection dont voici les principales méthodes :
Une fois que la connexion est établie, nous pouvons effectuer toutes les requêtes nécessaires afin d'exploiter au mieux l'ensemble des tables qui constitue cette base de données. Il suffit simplement de proposer les requêtes prévues par le langage SQL.
L'étape suivante est donc la communication effective avec la base de données et, nous venons juste de le voir, il existe plusieurs possiblités pour communiquer. Si vous choisissez la communication directe, il faut mettre en oeuvre un objet dont la classe implémente l'interface Statement.
La classe qui implémente l'interface Statement construit un tube de communication bidirectionnel qui permet à l'application java de proposer les requêtes par ce tube. En retour, la base transmet le ou les résultats par le même canal.
Pour créer un objet dont la classe implémente l'interface Statement, il suffit de faire appel à la méthode createStatement() définie à l'intérieur de la classe Connection. Lorsque cet objet est créé, le tube de communication reste ouvert tant que l'objet est chargé en mémoire.
Statement instruction = connexion.createStatement();
instruction représente donc le tube de communication directe qui va permettre la consultation ou la modification de certains éléments de la base de données choisie.
Après la connexion et la mise en place du tube de communication, nous pouvons effectuer différents traitements sur la base de données. Les deux types de traitement les plus utilisées qui correspondent donc à deux méthodes de l' interface java.sql.Statement sont :
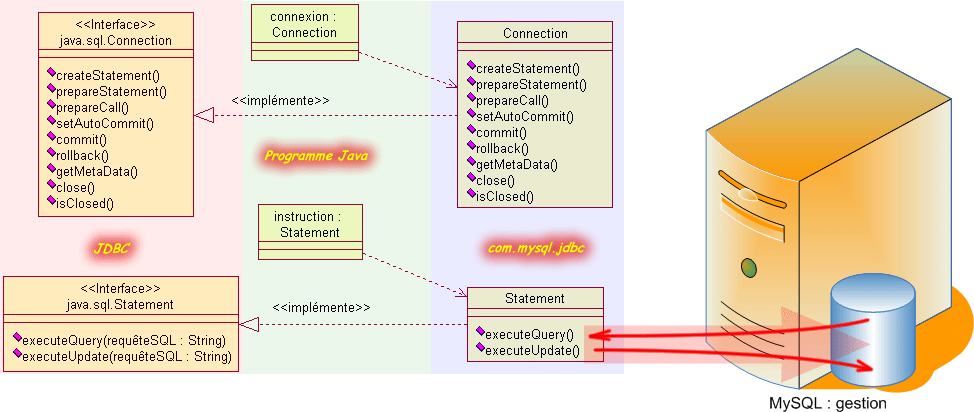
D'après ce que nous venons de découvrir, pour consulter les données issues d'une table, nous devons utiliser la méthode executeQuery de l'objet de type Statement dont les valeurs sont ensuite stockées dans l'objet dont la classe implémente l'interface java.sql.ResultSet.
ResultSet résultat = instruction.executeQuery("SELECT * FROM personne");
Cet objet de type ResultSet contient donc, sous la forme d'une table, toutes les données résultant d'une requête de type SELECT.
ResultSet comme son nom l'indique propose donc un ensemble de résultats qui correspond à la requête demandée.
.
L'intérêt de ResultSet est de pouvoir naviguer à l'intérieur des données avec des méthodes simples. En effet, cet objet fournit un ensemble de méthodes qui offrent la possibilité de se déplacer ligne par ligne à l'intérieur de la table à l'aide d'un curseur spécifique :
Il faut préciser que lorsque nous obtenons la première fois un objet de type ResulSet, le curseur est positionné juste avant la première ligne. Par ailleurs, ces méthodes retournent un booléen afin de préciser si la ligne désirée existe ou pas. Par exemple, lorsque nous utilisons la méthode next(), elle retourne la valeur false lorsque le curseur a dépassé la dernière ligne de la table des données.
Toujours, par rapport au curseur, la classe implémentée par java.sql.ResultSet dispose de méthodes supplémentaires qui contrôle, son emplacement actuel :
Une fois que la ligne désirée est atteinte, vous pouvez ensuite accéder à n'importe quel champ, grâce également à des méthodes appropriées - getXXX ( ) - qui permettent en même temps de récupérer le bon type de variable suivant l'enregistrement prévue dans la base de données. Ansi, les méthodes comme getString, getInt, getDate, getObject, etc. renvoient la valeur d'un des champs d'une ligne. Chacune de ces méthodes existe sous deux formes qui prennent en paramètre :
Voici la liste des méthodes :
String getString(int _int); String getString(String string); boolean getBoolean(int _int); boolean getBoolean(String string); byte getByte(int _int); byte getByte(String string); short getShort(int _int); short getShort(String string); int getInt(int _int); int getInt(String string); long getLong(int _int); long getLong(String string); float getFloat(int _int); float getFloat(String string) ; double getDouble(int _int); double getDouble(String string) ; Date getDate(int _int); Date getDate(String string) ; Time getTime(int _int); Time getTime(String string);
Blob getBlob(int _int); Blob getBlob(String string); Clob getClob(int _int); Clob getClob(String string); Array getArray(int _int); Array getArray(String string);
Il existe une dernière méthode bien utile lorsque nous désirons connaître la constitution exacte d'une table avec notamment le nom des colonnes, les types utilisés, etc. Ce sujet est d'ailleurs traité un peu plus loin dans la leçon. Cette méthode s'appelle getMetaData() dont voici la signature :
ResultSetMetaData getMetaData();
A titre d'exemple, et en reprenant la table Personne de la base de données Gestion, vous avez ci-dessous le codage complet qui visualise en mode console le contenu de l'ensemble de la table (sauf pour la clé primaire).
package testbasedonnées; // Source du programme - lecture de la table < Personne > de la base de données < Gestion > import java.sql.*; public class Principale { public static void main(String[] args) { try { // Class.forName("org.gjt.mm.mysql.Driver"); Class.forName("com.mysql.jdbc.Driver"); Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu"); Statement instruction = connexion.createStatement(); ResultSet résultat = instruction.executeQuery("SELECT * FROM personne"); while (résultat.next()) { System.out.println("---------------------------------"); System.out.println("Nom : "+ résultat.getString("Nom")); System.out.println("Prénom : "+ résultat.getString("Prenom")); System.out.println("Civilité : "+ résultat.getString("Civilite")); System.out.println("Age : "+ résultat.getInt("age")); } } catch (ClassNotFoundException ex) { System.err.println("Erreur Driver");} catch (SQLException ex) { System.err.println("Erreur Localisation BD");} } }
Résultat du programme
---------------------------------
Nom : Lagafe
Prénom : Gaston
Civilité : Monsieur
Age : 33
---------------------------------
Nom : Guillemet
Prénom : Virgule
Civilité : Mademoiselle
Age : 2
Une fois que nous avons obtenu les résultats escomptés, il faut libérer les connexions devenues inutiles. En effet, Chaque serveur de base de données disposent d'un nombre de connexions simultanées limitées. Dès que possible, il nous incombe de donner la main aux autres clients éventuels.
Donc, dans la pratique, une fois votre travail terminé avec ResultSet, Statement ou Connection, appelez immédiatement la méthode close(). En effet, en dehors des considérations de connexions simultanées, ces objets utilisent également de grandes structures de données, et il ne faut pas attendre que le ramasse-miettes s'en charge.
Ceci-dit, il n'est pas nécessaire, sauf cas particulier, d'appeler systématiquement les méthodes close() de chacune de ces classes - ResultSet, Statement, Connection. En effet, la méthode close() d'un objet Statement ferme automatiquement le jeu de résultats associé, donné par un ResultSet, si l'instruction dispose d'un jeu de résultat ouvert. De la même façon, la méthode close() de la classe Connection ferme toutes les instructions de la connexion. Ainsi dans la pratique, c'est cette dernière que nous devons clôturer.
Pour être sûr que la connexion soit impérativement libérée, quelque soit les péripéties (lancement d'une exception ou non), il est souhaitable de placer l'instruction close() à l'intérieur d'un bloc finally, en testant, bien entendu, si l'objet représentant la connexion existe vraiment. En reprenant l'exemple précédent, voilà comment il faudrait le réécrire pour tenir compte de la libération de la connexion :
package testbasedonnées; // Source du programme - lecture de la table < Personne > de la base de données < Gestion > import java.sql.*; public class Principale { public static void main(String[] args) { try { Class.forName("com.mysql.jdbc.Driver"); Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu"); Statement instruction = connexion.createStatement(); ResultSet résultat = instruction.executeQuery("SELECT * FROM personne"); while (résultat.next()) { System.out.println("---------------------------------"); System.out.println("Nom : "+ résultat.getString("Nom")); System.out.println("Prénom : "+ résultat.getString("Prenom")); System.out.println("Civilité : "+ résultat.getString("Civilite")); System.out.println("Age : "+ résultat.getInt("age")); } } catch (ClassNotFoundException ex) { System.err.println("Erreur Driver");} catch (SQLException ex) { System.err.println("Erreur Localisation BD");} finally { if (connexion!=null) connexion.close(); // libération de la connexion si elle existe } } }
Dans la suite de cette étude, je ne m'occuperai plus de la fermeture des connexions. Je ne désire pas alourdir les différents codes que je propose. Toutefois, il faut bien penser qu'il est préférable de libérer les connexions avec la base de données systématiquement.
Pour modifier le contenu d'une base de données, il convient d'utiliser la méthode executeUpdate() de Statement (ou de PreparedStatement). Grâce à cette méthode, les requêtes SQL : INSERT, UPDATE, DELETE (entre autres) permettent respectivement d'insérer, mettre à jour, ou supprimer un élément de cette base, et ceci directement à l'intérieur du programme Java. Pour réaliser ce genre de traitement, il suffit de spécifier la requête SQL au paramètre de cette méthode.
Vous avez ci-dessous un exemple qui permet d'insérer une nouvelle personne dans notre base de données.
package testbasedonnées; // Insertion d'une nouvelle personne dans la base de données
import java.sql.*;
public class Principale {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu");
Statement instruction = connexion.createStatement();
instruction.executeUpdate("INSERT INTO PERSONNE (Nom, Prenom, Civilite, age)"
+" VALUES ('Durand', 'Eric', 'Monsieur', 42)");
}
catch (ClassNotFoundException ex) { System.err.println("Erreur Driver");}
catch (SQLException ex) { System.err.println("Erreur Localisation BD");}
}
}
Après l'exécution de ce programme, voici le résultat obtenu sur la table Personne.
Avec SQL, les données qui décrivent une base de données ou l'une de ses parties sont appelées métadonnées (pour les distinguer des données elles-mêmes qui sont stockées dans la base de données). Vous pourrez rencontrer deux types de métadonnées :
La méthode getMetaData() d'une connexion (issue de java.sql.Connection) renvoie un objet dont la classe implémente java.sql.DatabaseMetaData. Les méthodes de cette interface permettent d'obtenir des informations complètes sur la base de données :
La plupart de ces informations sont renvoyées sous forme d'une instance de java.sql.ResultSet utilisée pour énumérer les réponses. Voici juste quelques méthodes qui me paraissent intéressantes :
Récupère la description de toutes les tables d'un catalogue qui correspond à un modèle de nom de table et de schéma , ainsi qu'à des critères de type. Un schéma décrit un groupe de tables associées et des droits d'accès. Un catalogue décrit un groupe de schémas associés. Ces concepts sont très importants pour structurer les grandes bases de données.
Les paramètres catalog et schéma peuvent être vide " " pour retrouver des tables sans catalogue et sans schéma, ou null pour renvoyer des tables indépendantes d'un catalogue ou d'un schéma.
Le tableau types contient les noms des types de tables à inclure. Les types les plus courants sont TABLE, VIEW, SYSTEM TABLE, GLOBAL TEMPORY, LOCAL TEMPORY, ALIAS, et SYNONYM. Si types vaut null, les tables de n'importe quel type peuvent être renvoyées.
L'ensemble des résultats possèdent cinq colonnes, qui sont toutes de type String, comme le montre le tableau ci-dessous.
Numéro 1 TABLE_CAT Catalogue de la table (peut être null) 2 TABLE_SCHEM Schéma de la table (peut être null) 3 TABLE_NAME Nom de la table 4 TABLE_TYPE Type de la table 5 REMARKS Commentaire sur la table
Renvoie le nom de l'ordinateur hôte ainsi que le nom de l'utilisateur.
Renvoie juste le type de table.
Renvoie l'ensemble des bases de données stockées dans le service. Vous pouvez gérer ainsi la totalité du service de base de données. A la connexion, il est préférable de ne spécifier que la localisation du serveur de base de données sans ajouter une base de données en particulier, mais rien ne l'empêche.
Class.forName("com.mysql.jdbc.Driver"); Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/", "root", "manu"); DatabaseMetaData bd = connexion.getMetaData(); ResultSet résultat = bd.getCatalogs(); while (résultat.next()) System.out.println(résultat.getString(1));Résultat du programme gestion mysql test
Il existe donc une deuxième classe de métadonnées, ResultSetMetaData, qui apporte des informations sur un ensemble de résultats. Lorsque vous obtenez un ensemble de résultats à partir d'une requête, vous pouvez demander ensuite, le nombre de colonne total, le nom de la colonne, le type du champ, le nombre d'éléments de chaque colonne, etc.
Bref, pas mal de méthodes permettent de retrouver des informations concernant la table :
Méthodes |
Résultat |
Type |
| getColumnCount( ) ; | Nombre de colonne constituant la table | int |
| getTableName( i ) ; | Nom de la table | String |
| getColumnName( i ) ; | Renvoie le nom de la colonne | String |
| getColumnLabel( i ) ; | Fournit le titre suggéré de la colonne | String |
| getColumnTypeName( i ) ; | Type de la colonne au sens base de données | String |
| getColumnDisplaySize( i ); | Taille de la colonne | int |
| isNullable( i ) ; | Si la colonne accèpte des valeurs nulles | int |
| isAutoIncrement( i ) ; | Si la colonne s'auto-incrémente | boolean |
Attention, contrairement aux indices de tableaux, les numéros de colonnes de base de données commencent à 1.
.
Voici un petit programme qui évalue les différentes méthodes issues de ResultSetMetaData au travers de la table Personne de la base de données Gestion.
package testbasedonnées; // Source du programme - Récupération des infos de la table < Personne > de la base de données < Gestion > import java.sql.*; public class Principale { public static void main(String[] args) { try { Class.forName("com.mysql.jdbc.Driver"); Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu"); Statement instruction = connexion.createStatement(); DatabaseMetaData meta = connexion.getMetaData(); ResultSet rs = meta.getTables(null, null, null, null); System.out.println("----------------------------------------"); while (rs.next()) { System.out.println("Catalogue de la table : " + rs.getString(1)); System.out.println("Schéma de la table : " + rs.getString(2)); System.out.println("Nom de la table : " + rs.getString(3)); System.out.println("type de table : " + rs.getString(4)); System.out.println("commentaire sur la table : " + rs.getString(5)); } System.out.println("----------------------------------------"); System.out.println("Nom utilisateur : "+ meta.getUserName()); rs = meta.getTableTypes(); while (rs.next()) System.out.println("Type de table : " + rs.getString(1)); System.out.println("----------------------------------------"); ResultSet table = instruction.executeQuery("select * from Personne"); ResultSetMetaData infoTable = table.getMetaData(); System.out.println("Nom de la table : "+infoTable.getTableName(1)); System.out.println("Nombre de colonnes : "+infoTable.getColumnCount()); for (int i=1; i<=infoTable.getColumnCount(); i++) { System.out.print("-------------------------- : "); System.out.println("Colonne n°"+i); System.out.println("Label : "+infoTable.getColumnLabel(i)); System.out.println("Nom : "+infoTable.getColumnName(i)); System.out.println("Nom de table : "+infoTable.getTableName(i)); System.out.println("Type : "+infoTable.getColumnTypeName(i)); System.out.println("Taille : "+infoTable.getColumnDisplaySize(i)); System.out.println("Null ? "+infoTable.isNullable(i)); System.out.println("Auto-incrément ? "+infoTable.isAutoIncrement(i)); } } catch (ClassNotFoundException ex) { System.err.println("Erreur Driver");} catch (SQLException ex) { System.err.println("Erreur Localisation BD");} } }
Résultat du programme
----------------------------------------
Catalogue de la table :
Schéma de la table : null
Nom de la table : personne
type de table : TABLE
commentaire sur la table :
----------------------------------------
Nom utilisateur : root@localhost
Type de table : TABLE
Type de table : LOCAL TEMPORARY
----------------------------------------
Nom de la table : Personne
Nombre de colonnes : 5
-------------------------- : Colonne n°1
Label : idPersonne
Nom : idPersonne
Nom de table : Personne
Type : INTEGER UNSIGNED
Taille : 10
Null ? 0
Auto-incrément ? true
-------------------------- : Colonne n°2
Label : Nom
Nom : Nom
Nom de table : Personne
Type : VARCHAR
Taille : 45
Null ? 0
Auto-incrément ? false
-------------------------- : Colonne n°3
Label : Prenom
Nom : Prenom
Nom de table : Personne
Type : VARCHAR
Taille : 45
Null ? 0
Auto-incrément ? false
-------------------------- : Colonne n°4
Label : Civilite
Nom : Civilite
Nom de table : Personne
Type : CHAR
Taille : 12
Null ? 0
Auto-incrément ? false
-------------------------- : Colonne n°5
Label : age
Nom : age
Nom de table : Personne
Type : INTEGER UNSIGNED
Taille : 10
Null ? 0
Auto-incrément ? false
Remarques : l'indice de la méthode getTableName() importe peu. Par ailleurs, que nous utilisions la méthode getColumnName() ou getColumnLabel(), le résultat pour cet exemple est identique. Toutefois, lorsque nous constituons une table, il est possible de faire la différence entre le label qui est juste un titre donné à la colonne (juste pour la visualisation), avec le nom véritable du champ.
Dans un programme, vous pouvez être ammené a proposer des requêtes relativement précises afin de retrouver un élément de l'ensemble de la base de données. Ainsi, nous pouvons rechercher, par exemple, toute la description d'une personne en spécifiant juste son nom. Voici l'exemple de requête à prévoir :
SELECT * FROM personne WHERE nom = 'LAGAFE'
Résultat de la recherche
---------------------------------
Nom : Lagafe
Prénom : Gaston
Civilité : Monsieur
Age : 33
---------------------------------
Si plus tard, vous devez avoir le même type de recherche, mais pour une autre personne, vous spécifierez alors la requête suivante :
SELECT * FROM personne WHERE nom = 'GUILLEMET'
Résultat de la recherche
---------------------------------
Nom : Guillemet
Prénom : Virgule
Civilité : Mademoiselle
Age : 2
---------------------------------
Plutôt que de générer une requête SQL à chaque besoin, nous pouvons préparer une seule requête paramétrée, et nous en servir à chaque fois, mais avec des valeurs de paramètre différentes.
Chaque paramètre d'une requête préparée est spécifié par un ?. En reprenant l'exemple précédent, nous pourrions prévoir une requête dont le nom servirait de paramètre. En voici la syntaxe :
SELECT * FROM personne WHERE nom = ?
Cette technique apporte une certaine amélioration au niveau des performances. Chaque fois que la base de données exécute une requête, elle commence par déterminer une stratégie lui permettant d'exécuter la requête de manière efficace. En préparant une requête et en l'utilisant par la suite, vous vous assurez que la tâche de répartition n'est faite qu'une seule fois.
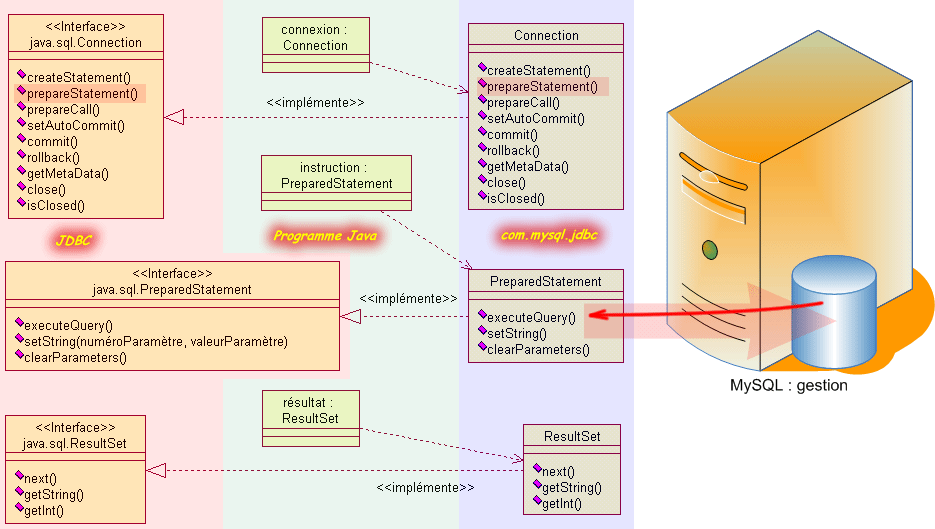
Pour mettre en oeuvre les instructions préparées, c'est-à-dire les requêtes paramétrées, vous devez cette fois-ci utilisée la classe qui implémente l'interface PreparedStatement en lieu et place de la classe Statement, et par la même occasion, utiliser la méthode prepareStatement de la classe Connection qui attend la requête paramétrée en argument. Voici le codage correspondant à la requête paramétrée ci-dessus :
Class.forName("com.mysql.jdbc.Driver"); Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu"); PreparedStatement instruction = connexion.prepareStatement("SELECT * FROM personne WHERE nom = ?");
Avant d'exécuter une instruction préparée, vous devez affecter les valeurs aux paramètres avec la méthode setXXX associée. Comme pour les méthodes getXXX de ResultSet, il existe une méthode setXXX pour plusieurs types de données.
Le premier argument correspond au numéro du paramètre que nous devons définir suivant son emplacement dans la requête paramétrée. La position 1 représente le premier ?. Le second argument est la valeur que nous désirons affecter au paramètre.
Si vous utilisez une requête préparée que vous avez déjà exécutée, et que cette requête possède plusieurs paramètres, tous ces paramètres restent inchangés tant qu'ils ne sont pas modifiés par une méthode setXXX. Cela signifie que vous avez uniquement besoin d'appeler la méthode setXXX pour les paramètres qui doivent être modifiés d'une requête à l'autre.
Une fois que tous les paramètres ont été définis, vous pouvez exécuter la requête grâce à la méthode executeQuery qui cette fois-ci n'a pas besoin d'arguments puisque la requête a déjà été mis en oeuvre par la méthode prepareStatement.
Class.forName("com.mysql.jdbc.Driver"); Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu"); PreparedStatement instruction = connexion.prepareStatement("SELECT * FROM personne WHERE nom = ?"); //........................................................ Recherche de renseignement sur 'LAGAFE' instruction.setString(1, "LAGAFE"); ResultSet résultat = instruction.executeQuery();
Une fois que nous avons un objet de type ResultSet, nous pouvons procéder comme à l'accoutumée, c'est-à-dire, naviguer sur l'ensemble des renseignements disponibles et afficher l'ensemble des résultats. Voici d'ailleurs le programme en entier avec une recherche successive avec une proposition de deux noms différents :
package testbasedonnées;
import java.sql.*;
public class Principale {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu");
PreparedStatement instruction = connexion.prepareStatement("SELECT * FROM personne WHERE nom = ?");
//........................................................ Recherche de renseignement sur 'LAGAFE'
instruction.setString(1, "LAGAFE");
ResultSet résultat = instruction.executeQuery();
while (résultat.next()) {
System.out.println("---------------------------------");
System.out.println("Nom : "+ résultat.getString("Nom"));
System.out.println("Prénom : "+ résultat.getString("Prenom"));
System.out.println("Civilité : "+ résultat.getString("Civilite"));
System.out.println("Age : "+ résultat.getInt("age"));
}
//...................................................... Recherche de renseignement sur 'GUILLEMET'
instruction.setString(1, "GUILLEMET");
résultat = instruction.executeQuery();
while (résultat.next()) {
System.out.println("---------------------------------");
System.out.println("Nom : "+ résultat.getString("Nom"));
System.out.println("Prénom : "+ résultat.getString("Prenom"));
System.out.println("Civilité : "+ résultat.getString("Civilite"));
System.out.println("Age : "+ résultat.getInt("age"));
}
}
catch (ClassNotFoundException ex) { System.err.println("Erreur Driver");}
catch (SQLException ex) { System.err.println("Erreur Localisation BD");}
}
}
En programation Java, il est très fréquent de manipuler des données représentées par des objets. Il peut alors être tentant de stocker l'ensemble de l'objet en une seule fois plutôt que de sauvegarder chacun des attributs en particulier, ce qui peut être fastidieux.
Les bases de données sont maintenant capable de manipuler des données directement en format binaire, c'est-à-dire sans connaître spécialement le format (ou la représentation) intrinsèque. Le type BLOB prévu par les bases de données représente un bloc de données de taille variable permettant de stocker des données binaires (images, données brutes, ...). Nous pouvons justement nous servir de ce type BLOB pour stocker des objets, la représentation binaire de ces objets dans la base de données nous importe peu.
En fait, en java, le stockage ou la restitution des données binaires dans la base se fait au travers d'un flux de type OutputStream ou InputStream, c'est-à-dire sous la forme d'une suite d'octets. Il est ensuite possible d'utiliser un flux de plus haut niveau, pour gérer les types primitives (DataOutputStream, DataInputStream)), les chaînes de caractères (PrintWriter, BufferedReader) ou les objets (ObjectOutputStream, ObjectInputStream).
Les premiers types (primitifs et chaînes de caractères) sont déjà prévus par les bases de données et ne nécessitent donc pas d'utiliser le système plus complexe des flux Java. Par contre, les derniers types de flux (ObjectOutputStream, ObjectInputStream) vont nous servir pour stocker des objets, la seule restriction étant alors de mettre en oeuvre des objets sérialisés comme nous l'avons déjà appris lors de l'étude spécifique des flux.
Pour illustrer ces propos, nous allons créer une nouvelle table "messagerie" dans la base de données "gestion".
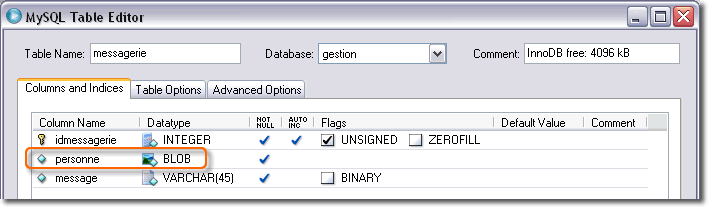
Cette table comporte 3 champs, dont l'un d'eux - personne - est du type BLOB. Ce champ représente un objet sérialisé de type Personne dont voici l'implémentation :
import java.io.Serializable;
/* Fichier : Personne.java
* Projet : TestBlob
* Créé le 29 juin 2005
* Par Emmanuel REMY
*/
/**
* Objet sérialisé à stocker dans la table
*/
public class Personne implements Serializable {
private String nom;
private String prénom;
private int age;
/**
* @param nom
* @param prenom
* @param age
*/
public Personne(String nom, String prénom, int age) {
this.nom = nom;
this.prénom = prénom;
this.age = age;
}
/**
* @return Renvoie age.
*/
public int getAge() {
return age;
}
/**
* @return Renvoie nom.
*/
public String getNom() {
return nom;
}
/**
* @return Renvoie prenom.
*/
public String getPrénom() {
return prénom;
}
}
Nous allons maintenant stocker un objet de type Personne dans la table messagerie qui se situe dans la base de données gestion :
/* Fichier : BaseDeDonnées.java
* Projet : TestBlob
* Créé le 29 juin 2005
* Par Emmanuel REMY
*/
import java.sql.*;
import java.io.*;
/**
* Test sur une base données avec stockage d'objets sérialisés
*/
public class BaseDeDonnées {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu");
//Création de l'objet et stockage dans la base de données
Personne personne = new Personne("REMY", "Emmanuel", 45);
String sql = "INSERT INTO messagerie (personne, message) VALUES (?,?)";
PreparedStatement statement = connexion.prepareStatement(sql);
//insertion de l'objet
statement.setObject(1, personne);
statement.setString(2, "Bienvenue à tous");
statement.executeUpdate();
}
catch (ClassNotFoundException e) {
System.err.println("Le driver n'a pas été chargé");
}
catch (SQLException e) {
System.err.println("La requête n'a pas aboutie");
}
}
}
L'enregistrement d'un objet dans la base de données ne pose aucun problème particulier, il suffit de faire appel à la méthode setObject au même titre que la méthode setString par exemple. Par contre le stockage dans la base de données s'effectue sous forme brut, c'est-à-dire sous forme d'une suite d'octets.
Nous allons maintenant récupérer les valeurs que nous venons de stocker dans la base de données :
/* Fichier : BaseDeDonnées.java
* Projet : TestBlob
* Créé le 29 juin 2005
* Par Emmanuel REMY
*/
import java.sql.*;
import java.io.*;
/**
* Test sur une base données avec stockage d'objets sérialisés
*/
public class BaseDeDonnées {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connexion = DriverManager.getConnection("jdbc:mysql://localhost/gestion", "root", "manu");
// Récupération de l'objet stocké dans la base de données
Statement instruction = connexion.createStatement();
ResultSet résultat = instruction.executeQuery("SELECT * FROM messagerie");
résultat.next();
InputStream stream = résultat.getBlob("personne").getBinaryStream();
ObjectInputStream objet = new ObjectInputStream(stream);
Personne personne = (Personne) objet.readObject();
System.out.println("Nom : "+ personne.getNom());
System.out.println("Prénom : "+ personne.getPrénom());
System.out.println("Age : "+ personne.getAge());
System.out.println("Message : "+ résultat.getString("message"));
}
catch (ClassNotFoundException e) {
System.err.println("Le driver n'a pas été chargé");
}
catch (SQLException e) {
System.err.println("La requête n'a pas aboutie");
}
catch (IOException e) {
System.err.println("Problème de flux");
}
}
}
Il semblerait logique d'utiliser la méthode getObject comme nous avons utilisé la méthode setObject. Toutefois, il ne faut pas oublier que le stockage dans la base de données de ce champ personne est tout simplement du stockage binaire, c'est-à-dire une suite d'octets, bref sans formattage particulier. Il faut pouvoir retrouver la structure de l'objet. Il est donc nécessaire de passer par l'architecture des flux. Dans un premier temps, nous faisons appel à la méthote getBlob qui récupère l'ensemble des informations binaire que nous formattons ensuite sous la forme d'une suite d'octets grâce à la méthode getBinaryStream. Pour le reste, nous connaissons toute la procédure, il suffit de créer un flux d'objet et de transtyper l'objet récupéré vers un objet de type Personne.
Chaque type SQL a son équivalent en tant que constante numérique dans la classe java.sql.Types. Tous les types SQL déclarés dans la classe java.sql.Types ne sont pas forcément pris en charge par toutes les bases de données.
Type SQL |
Description |
Type Java |
Constante java.sql.Types |
| INTEGER | Entier signé | int | Types.INTEGER |
| FLOAT | Nombre à virgule flottante | float | Types.FLOAT |
| DOUBLE | Nombre à virgule flottante en double précision | double | Types.DOUBLE |
| DECIMAL ( n, d ) | Nombre décimal de n chiffres et de d décimales | java.math.BigDecimal | Types.DECIMAL |
| CHAR ( n ) | Chaîne de caractères de n caractères | java.lang.String | Types.CHAR |
| VARCHAR ( n ) | Chaîne de caractères de longueur variable de n caractères au maximum | java.lang.String | Types.VARCHAR |
| DATE | Date | java.sql.Date | Types.DATE |
| TIME | Heure | java.sql.Time | Types.TIME |
| TIMESTAMP | Date et heure | java.sql.Timestamp | Types.TIMESTAMP |
| BLOB | Bloc de données de taille variable permettant de stocker des données binaires (images, données brutes...) | java.sql.Blob ÷ byte[ ] | Types.BLOB |