Servlets - techniques avancées
Servlets - techniques avancées
 A côté des JSP, que nous découvrirons dans les chapitres suivants, les servlets sont des composants J2EE très utilisé. Les servlets sont des applications côté serveur, tout comme les applets sont des applications côté client. Les JSP sont principalement constituées de code HTML avec des fragment de code Java. Les servlets, elles, contiennent essentiellement du code Java dans lequel sont insérés des fragments de code HTML (éventuellement).
A côté des JSP, que nous découvrirons dans les chapitres suivants, les servlets sont des composants J2EE très utilisé. Les servlets sont des applications côté serveur, tout comme les applets sont des applications côté client. Les JSP sont principalement constituées de code HTML avec des fragment de code Java. Les servlets, elles, contiennent essentiellement du code Java dans lequel sont insérés des fragments de code HTML (éventuellement).
Les servlets sont conçues comme des extensions de serveurs auxquels s'ajoutent des fonctionnalités. Notez que nous parlons de serveurs et non de serveurs Web. En effet, l'intension originelle était de créer des extensions pour tout types de serveurs, tels les serveurs FTP ou SMTP. Toutefois, seules les servlets HTTP sont aujourd'hui couramment employées.
Elles étendent les capacités des serveurs Web en permettant de créer des applications Web au comportement dynamique. Elles sont conçues pour recevoir une requête du client (généralement un navigateur Web), traiter cette requête et retourner une réponse. Bien que la totalité du traitement puisse être effectuée dans la servlet, celle-ci fait appel à des classes utilitaires (JavaBeans) ou à d'autres composants Web, tel les EJB (Entreprise JavaBeans), qui sont chagés d'implémenter la logique métier, laissant à la servlet le traitement des requêtes et des réponses.
Les servlets sont chronologiquement le deuxième élément J2EE apparu, après JDBC. Ayant été inventées avant les pages JSP, elles devaient prendre en charge l'affichage. Eviter le mélange de code Java et de code HTML qui en résultait a été la principale raison de la mise au point de la technologie JSP.
Bien que les servlets aient été conçues originellement pour travailler avec tous les types de serveurs, elles ne sont employées en pratique qu'avec les serveurs Web. Les applications J2EE n'utilisent donc que des servlets répondant à des requêtes HTTP. L'API Servlet contient une classe nommée HttpServlet conçue spécifiquement pour ce type de requêtes. Cette classe est spécialisée dans le traitement du protocole HTTP qui fut développé bien avant l'apparition des servlets et repose sur des fondations particulièrement stables.
Ce protocole définit la structure des requêtes qu'un client peut envoyer à un serveur Web, le format des paramètres pouvant accompagner ces requêtes et la façon dont le serveur doit y répondre. Les servlets HTTP emploient le même protocole pour gérer les requêtes de service et envoyer les réponses aux clients. Il est donc important de bien comprendre les éléments fondamentaux du protocole HTTP pour maîtriser l'utilisation de servlets.
Pour en savoir plus sur le protocole HTTP, revoyer le chapitre sur les pages Web dynamiques.
Lorsqu'un client (généralement, mais pas nécessairement un navigateur Web) envoie une requête au serveur Web et que celui-ci détermine que la requête est destinée à une servlet, il la passe au conteneur de servlets. Le conteneur de servlets est le programme responsable du chargement, de l'initialisation, de l'appel et de la destruction des instances de servlets.
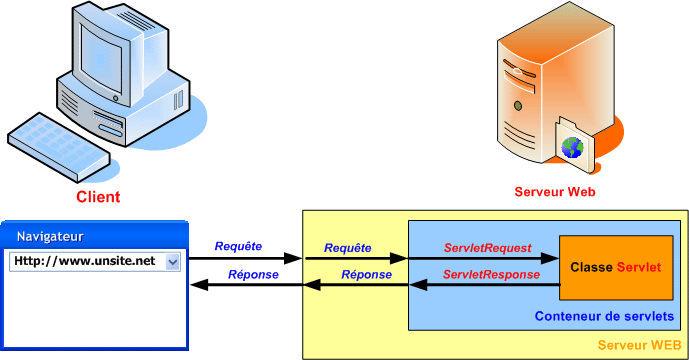
Lorsque le conteneur de servlets reçoit la requête, il en analyse l'URI, les entêtes et le corps et stocke toutes les données dans un objet implémentant l'interface javax.servlet.ServletRequest. Il crée également une instance d'un objet implémentant l'interface javax.servlet.ServletResponse. Cet objet encapsule la réponse qui sera envoyée au client. Le conteneur appelle ensuite une méthode de la classe de la servlet, en lui passant les objets requête et réponse.
La servlet traite la requête et renvoie la réponse au client.
Comme les programmes CGI, les servlets HTTP sont conçues pour répondre aux requêtes GET et POST ainsi qu'aux autres types de requêtes définies par la spécification HTTP. Dans la pratique, vous n'aurez jamais à vous préoccuper d'autres méthodes que GET et POST. Pour écrire une servlet, vous étendrez généralement la classe javax.servlet.http.HttpServlet. Il s'agit de la classe de base de l'API Servlet pour le traitement des requêtes HTTP.
Cette classe étend elle-même la classe javax.servlet.GenericServlet, qui fournit les fonctionnalités fondamentales. Enfin, javax.servlet.GenericServlet implémente l'interface principale de l'API, javax.servlet.Servlet. Elle implémente également une interface nommée ServletConfig qui offre un accès facile aux données de configuration des servlets.
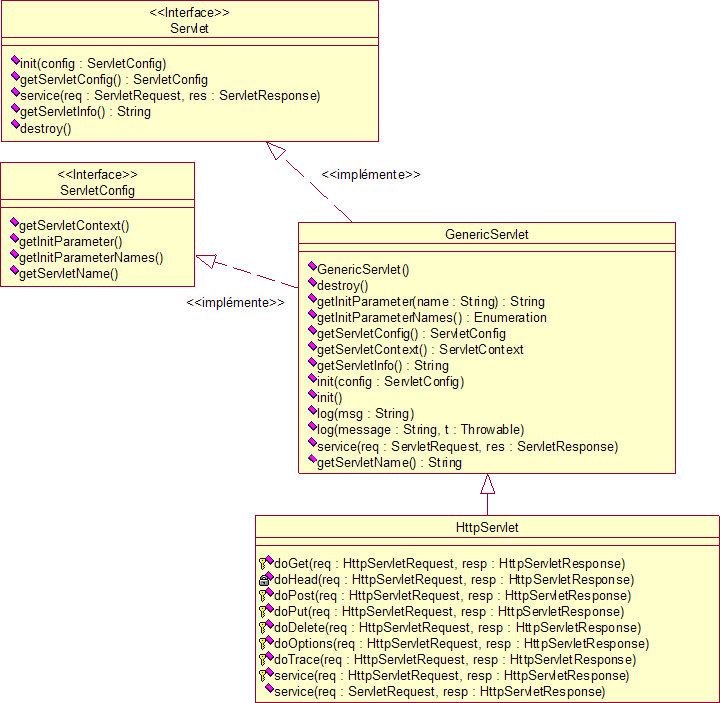
Dans l'interface Servlet, la seule méthode qui gère les requêtes est la méthode service(). Lorsqu'un conteneur reçoit une requête pour une servlet, il appelle systématiquement sa méthode service(). Comme pour toutes les interfaces, une servlet implémentant l'interface Servlet doit obligatoirement fournir une implémentation de toutes les méthodes déclarées, et à fortiori redéfinir la méthode service().
Les HttpServlet sont conçues pour réponde aux requêtes HTTP. Elles doivent donc traiter les requêtes GET, POST, HEAD, etc. La classe HttpServlet définit donc des méthodes supplémentaires. La méthode doGet() traite les requêtes GET et la méthode doPost() les requêtes POST. Il existe ainsi autant de méthode doXXX() qu'il y a de type de requêtes HTTP.
Dans cette classe HttpServlet, et donc par défaut, ces méthodes se contentent de retourner au client un message d'erreur indiquant que ce type de requêtes n'est pas supporté.
En tant que programmeur, votre rôle consiste à développer une nouvelle servlet adaptée à la situation qui hérite de la classe HttpServlet, et de redéfinir uniquement les méthodes dont vous avez besoin. Le plus souvent, il s'agira de doGet() et de doPost().
Certains développeurs étende la classe HttpServlet et redéfinisse uniquement la méthode service() pour traiter tous les types de requête HTTP. Cette solution est acceptable pour un problème simple, mais procéder ainsi peut poser des problèmes graves dans une application J2EE. HttpServlet implémente déjà la méthode service() qui aiguille la requête HTTP vers la méthode adaptée. Il est donc préférable de ne pas le faire et de redéfinir uniquement doGet() et doPost().
Lorsque le conteneur de servlets reçoit les requêtes HTTP, il associe chacune d'elles à une servlet. Il appelle ensuite la méthode service() de celle-ci. En supposant que la servlet étende HttpServlet et ne redéfinisse que les méthode doGet() et doPost(), l'appel à la méthode service() concerne donc celle définit dans la classe HttpServlet. Cette méthode détermine le type de la requête HTTP, puis appelle la méthode doXXX() correspondante. Si votre servlet redéfinit cette méthode, c'est cette implémentation qui sera exécutée. Cette méthode traite la requête, crée la réponse HTTP et la retourne au client.
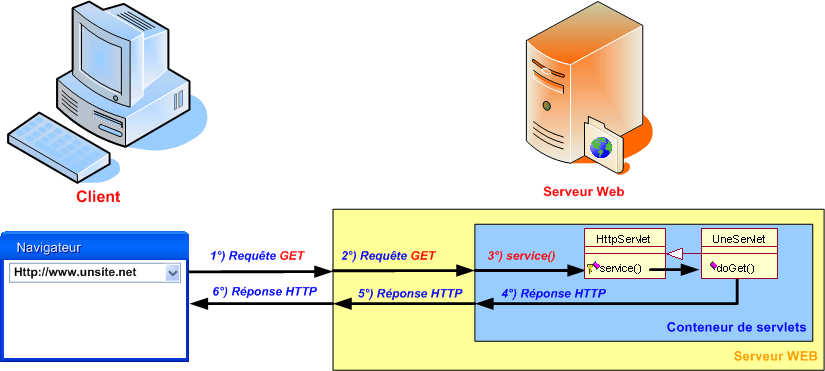
Sur cette figure, deux classes ont été représentées : HttpServlet et UneServlet. En fait, il s'agit d'un seul et même objet instance de UneServlet. Cette dernière récupère par héritage la méthode service() issue de HttpServlet.
La signature des méthodes doXXX( ) est la suivante :
public void doXXX(HttpServletRequest request, HttpServletResponse response)
Chaque méthode (doPost(), doGet(), etc.) prend deux paramètres. L'objet HttpServletRequest encapsule la requête envoyée au serveur. Il contient toutes les données de la requête, ainsi que certains en-têtes. Les méthodes de l'objet request permettent d'accéder à ces données. Les méthodes de l'objet HttpServletResponse encapsule la réponse au client.
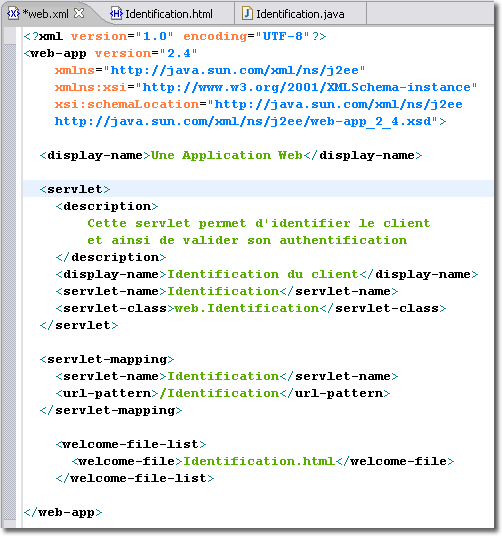
Maintenant que nous connaissons les objets fondamentaux, nous allons mettre en oeuvre une servlet simple qui va nous permettre d'étayer nos connaissances. Notre application Web doit d'abord authentifier le client désirant accéder à ses resources. Pour cela, il faut d'abord construire la page d'accueil Identification.html qui va permettre de saisir le nom de l'utilisateur ainsi que son mot de passe et ensuite créer une servlet web.Identification qui va permettre d'authentifier la personne désireuse d'accéder aux ressources de l'application Web.
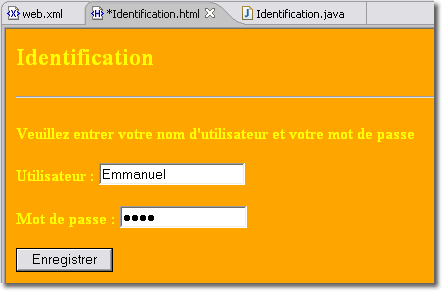
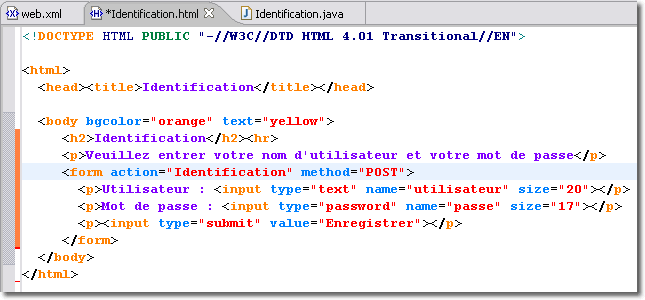
La servlet suivante est très rudimentaire puisqu'elle ne prend en compte que le premier paramètre et avertit le client sous la forme d'une page Web dynamique de la validation de son authentification.
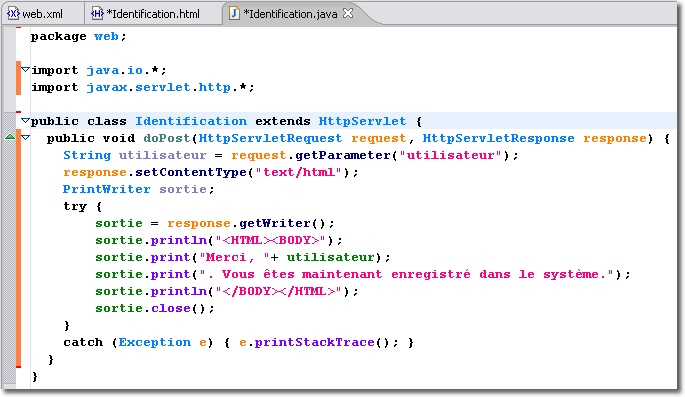
La servlet web.Identification illustre certains des points abordés jusqu'ici. Il s'agit d'une classe Java ordinaire. Sa particularité est qu'elle étend la classe HttpServlet. De ce fait, il lui suffit de redéfinir les méthodes de cette classe dont dépend son comportement spécifique, et d'ajouter des méthodes supplémentaires si nécessaire. Dans cet exemple, la classe web.Identification a juste besoin de redéfinir la méthode doPost.
Lorsque l'utilisateur clique sur le bouton "Enregistrer" de la page <Identification.html>, le navigateur envoie une requête POST au serveur. Les formulaires peuvent envoyer des requêtes GET ou POST. L'élément <form> possède un attribut method qui a ici pour valeur POST. Ainsi, le navigateur sait qu'il doit envoyer une requête POST à la ressource identifiée par l'attribut action qui correspond à la servlet désignée par l'URL suivante :
/Identification
Si l'attribut method est absent, une requête GET est envoyée par défaut.
.
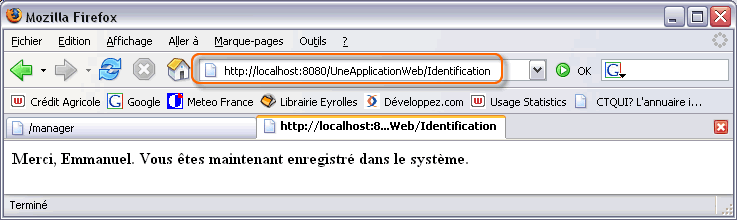
Finalement, dans cet exemple, l'URL envoyée au serveur est la suivante :
http://localhost:8080/UneApplicationWeb/Identification
Puisque la méthode POST a été choisie, la valeur des paramètres est encapsulée dans l'en-tête de la requête envoyée au serveur.
.
Lorsque le serveur reçoit la requête, il examine l'URL pour déterminer à qu'elle ressource il doit la transmettre. La partie /Identification, grâce au descripteur de déploiement, indique qu'il s'agit de la classe web.Identification. Le serveur crée une instance de cette classe et l'exécute dans le conteneur de servlets. Le serveur crée également une instance de HttpServletRequest ainsi qu'une instance de HttpServletResponse et appelle la méthode service(). La classe web.Identification ne possède pas une telle méthode par défaut, c'est celle héritée par la classe parente. Ainsi, la méthode service() de la classe HttpServlet détermine que la requête est du type POST et appelle la méthode correspondante doPost(). Celle-ci est justement redéfinie par la classe web.Identification. C'est donc cette implémentation qui est utilisée.
String utilisateur = request.getParameter("utilisateur") ;
La méthode doPost() lit les paramètres de la requête en appelant la méthode getParameter() de l'objet HttpServletRequest. Cette méthode retourne la valeur, sous la forme d'une chaîne de caractères, du paramètre indiqué comme argument. Si ce paramètre n'existe pas, la méthode retourne null. Le nom utilisé comme argument de la méthode getParameter() est le même que celui employé dans le formulaire.
<p>Utilisateur : <input type="text" name="utilisateur" size="20"></p>
La servlet utilise ensuite l'objet response pour envoyer la réponse au client. Elle commence par déterminer le type de contenu de la réponse en donnant à l'en-tête content-type la valeur "text/html" :
response.setContentType("text/html") ;
Attention : Le type de contenu doit être déterminé avant d'obtenir un flux de type OutputStream ou Writer de la réponse. En effet, le type est utilisé pour créer cet objet.
La servlet obtient ensuite un flux de caractères de type Writer de l'objet response et l'utilise pour envoyer au client les chaînes de caractères constituant la réponse. Il suffit alors de prévoir les chaînes de caractères en intégrant le codage HTML, de sorte que le client voit apparaître une nouvelle page Web dynamique adaptée à la saisie qu'il aura faite.
Dès que vous traitez les flux, vous devez vous occuper de la gestion d'exception. Ici le traitement est rudimentaire, puisque la servlet, en cas d'exception, affiche tout simplement la trace dans le serveur Web. Nous verrons ultérieurement une meilleure gestion de ce genre de problème.
Dans l'exemple précédent, la servlet obtenait des informations de l'objet request en appelant sa méthode getParameter() :
String utilisateur = request.getParameter("utilisateur") ;
L'interface ServletRequest définit plusieurs autres méthodes permettant de lire les données présentes dans la requête :
public Enumeration getParameterNames() ;
public String[] getParameterValues(String nom) ;
public Map getParameterMap() ;
La méthode getParameterValues( ) retourne les valeurs du paramètre dont le nom est passé en argument. Elle est utilisée lorsqu'un paramètre peut avoir plusieurs valeurs. Par exemple, si un formulaire HTML contient une liste <select> autorisant les sélections multiples. Avec un tel paramètre, la méthode getParameter( ) retourne uniquement la première des valeurs retournée par getParameterValues( ).
Si le paramètre indiqué n'existe pas, ces deux méthodes retournent la valeur null. N'oubliez pas que les navigateurs transmettent uniquement les valeurs non nulles. En d'autres termes, si un formulaire HTML contient une case à cocher non sélectionnée, le nom de cet élément n'est pas transmis avec la requête.
La méthode getParameterNames( ) retourne une énumération des noms des paramètres de la requête.
La méthode getParameterMap( ) retourne tous les paramètres stockés dans un objet de type Map. Chaque nom de paramètre est une clé. Les valeurs peuvent être des String ou des tableaux String[ ], selon que les paramètres ont une ou plusieurs valeurs.
Vous pouvez également obtenir des informations au sujet de la requête à l'aide des méthodes de ServletRequest. Voici quelque-unes des plus utiles :
Vous pouvez aussi accéder au flus de la requête, qui contient les paramètres sous forme brute. Il existe pour cela deux méthodes :
Pour une même requête, une seule de ces méthodes peut être employée. En effet, il n'est possible d'accéder au flux de la requête qu'une seule fois. Une deuxième tentative cause le lancement d'une exception. Notez également que si vous utilisez une de ces méthodes sur une requête comportant un corps, les méthodes getParameter() et getParameterValues() risquent de ne plus fonctionner.
Il est également possible, grâce à cet InputStream, de prévoir une couche de flux supplémentaire, comme un ObjectInputStream afin de recevoir directement un objet sur le réseau à l'aide de la sérialisation. Toutefois, cette technique impose d'avoir côté client une application ou une applet afin que ces dernières puissent envoyer cet objet récupéré par la servlet.
Revoyons le format d'un message HTTP :
Ligne de requête
En-têtes
<retour chariot / saut de ligne>
[corps du message]
L'interface HttpServletRequest offre plusieurs méthodes permettant de lire les en-têtes des messages HTTP :
long getDateHeater(String nom) ;
String getHeader(String nom) ;
Enumeration getHeaders(String nom) ;
Enumeration getHeadersNames ( ) ;
int getIntHeader(String nom) ;
Deux méthodes permettent d'obtenir la valeur d'un en-tête sous la forme d'une date ou d'un entier. Les en-têtes qui ne sont ni des dates ni des entiers peuvent être lus au moyen de la méthode générale getHeader(String). Cette méthode prend pour argument le nom de l'en-tête à lire.
En se servant du fragment de l'en-tête suivante :
Last-Modified: Mardi, 30 Août 2005 15:34:46 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 1024
Date: Mardi, 30 Août 2005 15:34:46 GMT
Server: Sun-Java-System/Application-Server-PE-8.0
Une servlet est en mesure de lire la valeur de l'en-tête Last-Modified en appelant la méthode getDateHeader("Last-Modified"). La longueur du contenu pourraît être obtenue à l'aide de la méthode getIntHeader("Content-Lenght"). Un en-tête tel que Server, qui n'est ni une date ni un entier, sera lu en appelant la méthode getHeader("Server").
Avec la méthode GET du protocole HTTP, les navigateurs ajoutent des paramètres à la fin de l'URL. La servlet les lit à l'aide de la méthode :
public String getQueryString() ;
Supposons que le serveur reçoive la requête suivante :
http://localhost:8080/UneApplicationWeb/Identification?utilisateur=Emmanuel
Dans ce cas, un appel à la méthode getQueryString( ) retournera : "utilisateur=Emmanuel".
Il est possible d'ajouter des informations sous forme d'une prolongation apparente du chemin d'accès à la ressource désignée par L'URL. Par exemple, dans votre page d'accueil, vous pouvez faire appel à la servlet Identification en ajoutant /extra/path/info.
<a href="/Identification/extra/path/info">Demande d'information</a>
Ainsi, la même page web peut proposer plusieurs liens vers la même servlet tout en proposant des prolongations d'URL différentes. Du coup, la même servlet proposera des traitements adaptée à la demande. Ces prolongations peuvent être obtenues à l'aide de la méthode suivante :
public String getPathInfo() ;
Ainsi, dans le cas de l'URL suivante :
http://localhost:8080/UneApplicationWeb/Identification/extra/path/info
getPathInfo( ) retournera "/extra/path/info"
Cette technique est intéressante pour la mise en oeuvre de l'architecture MVC et ainsi avoir une servlet qui sert de contrôleur.
.
Il est possible de récupérer l'adresse URL complète de l'endroit où se situe l'application Web grâce à la méthode suivante :
public String getContextPath() ;
Cette méthode nous permet de ne pas désigner explicitement l'adresse absolue et ainsi favorise le déploiement de l'application Web sur n'importe quel serveur. Pour faire référence à d'autres servlets, il est donc préférable d'utiliser cette méthode et de compléter ainsi la chaîne de caractère retournée par la méthode avec le nom url de la servlet :
request.getContextPath() + "/urlServlet"
Dans l'exemple précédent, nous avons employé deux méthodes de l'objet response :
response.setContentType("text/html") ;
PrintWriter writer = response.getWriter() ;
Crâce au Writer obtenu de la réponse, la servlet peut envoyer des données HTML au navigateur client. Un autre objet peut-être employé pour cela. Il s'agit d'un OutputStream qui peut être obtenu en appelant la méthode suivante :
public ServletOutputStream getOutputStream() ;
Bien que l'OutputStream puisse être utilisé pour du texte, sa principale fonction est d'envoyer des données binaires au client. Une servlet peut ainsi construire une image, la stocker dans un tableau de byte, puis sélectionner le type de contenu "image/jpeg", indiquer la longueur du contenu et envoyer les données à l'OutputStream. Il est également possible, grâce à cet OutputStream, de prévoir une couche de flux supplémentaire, comme un ObjectOuputStream afin d'envoyer un objet sur le réseau à l'aide de la sérialisation. Toutefois, cette technique impose d'avoir côté client une application ou une applet afin de pouvoir récupérer cet objet envoyé par la servlet.
L'interface HttpServletResponse ajoute un certain nombre de méthodes utiles pour le traitement des requêtes HTTP. Elles permettent d'ajouter des en-têtes à la réponse et de configurer leurs valeurs :
void addDateHeader(String nom, long date) ;
void addHeader(String nom, String valeur) ;
void addIntHeader(String nom, int valeur) ;
void setDateHeader(String nom, long date) ;
void setHeader(String nom, String valeur) ;
void setIntHeader(String nom, int valeur) ;
Dans l'exemple précédent, nous avons créé une simple servlet traitant les requêtes POST. Ce traitement ne constitue qu'une petite partie du cyle de vie d'une servlet (bien qu'il s'agisse de la part la plus importante du point de vue du client). La spécification définit quatre étapes dans le cycle de vie d'une servlet :
Ces quatres étapes sont illustrées ci-dessous, avec les méthodes permettant de passer d'une étape à une autre. Ce sont ces méthodes qui accomplissent le cycle de vie de la servlet.

A partir de quel moment la servlet est réellement créée et quel est l'événement qui fait qu'elle n'existe plus ? Ici, nous allons répondre à la première question.
Pour la phase de création, c'est au développeur de décider. Pour cela, il indique dans le descripteur de déploiement ce qu'il désire faire grâce à l'élément <load-on-start-up>.
<servlet> <load-on-start-up>5</load-on-start-up>
... </servlet>
L'élément <load-on-start-up> lorsqu'il est présent, contient un entier positif qui indique qu'il faut charger la servlet au démarrage du serveur. L'ordre de chargement des servlets est déterminé par cette valeur. Les servlets ayant la plus petite valeur sont chargées les premières. En cas de valeurs égales, l'ordre de chargement est arbitraire.
Si l'élément <load-on-start-up> est absent dans le descripteur de déploiement, la servlet est chargée lors de la première requêtes donnée par le client.
.
Au cours de cette étape, la classe de la servlet définie dans l'application Web est chargée et l'objet représentant la classe est créé. La méthode chargée de cette étape est comme pour tous les objets le constructeur de la servlet. Ce constructeur ne peut-être que le constructeur par défaut puisque c'est le conteneur de servlets qui doit lancer la création. Nous nous retrouvons dans la même situation que pour l'applet ou, dans une moindre mesure, à un JavaBean.
En effet, comme le conteneur de servlets charge et instancie les servlets de manière dynamique, il ne connaît pas les éventuels constructeurs que nous aurions pu créer et qui nécessiteraient des arguments. Il ne peut appeler qu'un constructeur sans arguments et il est donc inutile de définir un autre constructeur puisque Java le fournit automatiquement.
En toute rigueur, vous pouvez quand même, si vous le désirez, redéfinir le constructeur par défaut puisqu'il s'agit d'une classe comme une autre. Toutefois, il existe, comme vous allez le voir, une méthode init() qui réalise le même travail, autant donc travailler directement avec elle.
Comment le conteneur de servlets sait-il quelle servlet charger ? Tout simplement en lisant le descripteur de déploiement dont il connait l'emplacement. Chaque application Web possède son propre répertoire à l'intérieur duquel se situe le sous-répertoire <WEB-INF>. Ce sous-répertoire constitue la partie privée de l'application Web qui n'est donc accessible que par le conteneur de servlets. <WEB-INF> contient le fichier <web.xml> qui n'est autre que le descripteur de déploiement. Le conteneur de servlets lit ce fichier et charge les classes des servlets identifiées, puis, il fabrique l'objet de chaque servlets en appelant son constructeur par défaut.

Vu que nous ne redéfinissons pas le constructeur par défaut, il faut tout de même prévoir l'initialisation de la servlet lorsque cette dernière a été chargée et instanciée. Cette phase d'initialisation a lieu lorsque le conteneur appelle la méthode init(ServletConfig) - Nous remarquons le même type de processus que pour l'applet.
Si votre servlet n'a aucune initialisation particulière à effectuer, il n'est pas nécessaire d'implémenter cette méthode. Une implémentation est fournie grâce à l'héritage par la classe GenericServlet. Voilà pourquoi la servlet Identification définie plus haut ne possédait pas de méthode init ( ).
Cette méthode permet à la servlet de lire les paramètres d'initialisation ou les données de configuration, d'initialiser des ressources externes telles des connexions à une base de données ou d'effectuer diverses autres tâches qui seront accomplies une seule fois juste après la création de la servlet. La classe GenericServlet fournit deux formes de cette méthode :
public void init() throws ServletException
public void init(ServletConfig) throws ServletException
Le descripteur de déploiement peut définir des paramètres qui s'appliquent à la servlet au moyen de l'élément <init-param>. Le conteneur de servlets lit ces paramètres dans le fichier <web.xml> et les stocke sous forme de paires clé/valeur dans l'objet ServletConfig. L'interface Servlet ne définissant que init(ServletConfig), c'est cette méthode que le conteneur doit appeler. GenericServlet implémente cette méthode pour stocker la référence à ServletConfig puis appelle la méthode init( ) sans paramètres.
Aussi pour effectuer l'initialisation, nous avons seulement besoin de redéfinir init( ) sans paramètre. La référence à ServletConfig étant déjà mémorisée, la méthode init( ) a accès à tous les paramètres d'initialisation qui y sont stockées. Pour récupérer ces paramètres, il suffit d'utiliser la méthode getInitParameter(String).
public String GenericServlet.getInitParameter(String nomDuParamètre) ; // retourne la valeur du paramètre
L'intérêt des paramètres d'initialisation est de permettre de changer de configuration sans avoir besoin de recompiler la servlet. Par exemple, vous pouvez placer dans le descripteur de déploiement, le nom du pilote du serveur d'une base de données ainsi que sa localisation. Si plutard, vous devez changer de serveur, il suffit de modifier les valeurs directement dans la balise <init-param> du descripteur de déploiement (changement de texte) sans recompiler la servlet qui a déjà été mis en oeuvre. Ainsi notre servlet fonctionne quelque soit le serveur de base de données.
<init-param> est composé de deux sous-éléments qui correspondent respectivement au nom du paramètre suivi de sa valeur :
Voici un exemple de paramètres initiaux définissant le serveur de base de données MySql définies dans le descripteur de déploiement associés à la servlet FormulairePersonne :
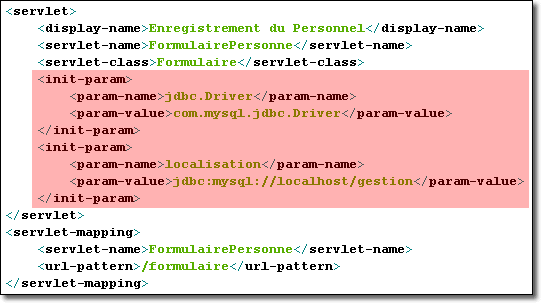
Récupération de ses paramètres initiaux dans la servlet FormulairePersonne :

Pour cet exemple, nous avons utilisé la méthode getInitParameter(String) à l'intérieur de la méthode init(). Il est possible de l'utiliser dans les autres méthodes de la servlet comme doGet() ou doPost(). Cela correspond à des paramètres moins spécifiques.
La spécification Servlet exige que la méthode soit terminée sans erreur pour traiter une requête. Si votre code rencontre un problème lors de l'exécution de la méthode init(), vous devez lancer une ServletException. Le conteneur saura ainsi que l'initialisation ne s'est pas déroulée correctement et qu'il ne doit pas utiliser cette servlet pour traiter des requêtes.

Une fois la servlet correctement initialisée, le conteneur peut l'utiliser pour traiter les requêtes.
Comme nous l'avons vu en début d chapitre, la principale méthode permettant de traiter les requêtes est service(). Chaque fois qu'une requête arrive, le conteneur appelle cette méthode. Toutefois, vos servlets étendrons pratiquement toujours la classe HttpServlet. Vous avez donc seulement besoin de redéfinir les méthodes doPost() et/ou doGet(). Voici les signatures de ces deux méthodes :
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException ;
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException ;
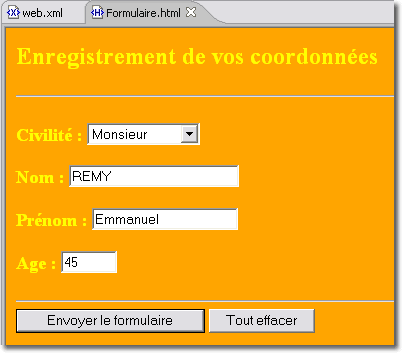
<Formulaire.html> delivrée au client par l'application Web
Traitement de la requête par la méthode doGet() de la servlet représentée par l'URL /formulaire

Comme la méthode init(), ces méthodes peuvent lancer une ServletException. Dans ce cas, le conteneur doit cesser de transmettre des requêtes à la servlet et terminer son cycle de vie. Si la servlet est effectivement détruite , le conteneur devra créer une nouvelle instance dans le cas où le client réclame de nouveau ses services.
Lorsque le conteneur doit supprimer une servlet, soit parce qu'il doit être arrêté ou lorsqu'une ServletException est lancée, il appelle sa méthode destroy(). Toutefois, il doit préalablement laisser le temps aux threads des requêtes en cours de terminer leur traitement. Une fois tous les threads terminés, il peut appeler la méthode destroy(). Notez que cette méthode ne détruit pas la servlet. Il s'agit simplement de donner à celle-ci l'opportunité de libérer les ressouces qu'elle utilise ou qu'elle a ouvertes. Une fois cette méthode appelée, le conteneur ne doit plus transmettre de requêtes à la servlet. La signature de la méthode destroy() est la suivante :
public void destroy() ;
La méthode destroy() permet donc à la servlet de libérer les ressources qu'elle utilise. Il peut s'agir de fermer une connexion à une base de données, ou de fermer des fichiers, de vider un flux ou de fermer les connexions réseaux.

Si une servlet n'a aucune tâche de ce type à accomplir, il est inutile de redéfinir cette méthode. Une fois la méthode destroy() terminée, le conteneur supprime toutes références à la servlet, qui peut alors être détruite par le ramasse-miette.
Bien que cette méthode soit publique, elle ne peut être appelée que par le conteneur de servlets. Vous ne devez pas l'appeler depuis la servlet elle-même, ni permettre à un autre composant de l'appeler.
Nous allons mettre en oeuvre un exemple qui permet d'utiliser toutes les méthodes de la servlet relatées dans la partie précédente. Nous en profitons pour voir comment, à partir de la servlet, se mettre en relation avec une base de données. Voici d'ailleurs la table Personne de la base de données Gestion.
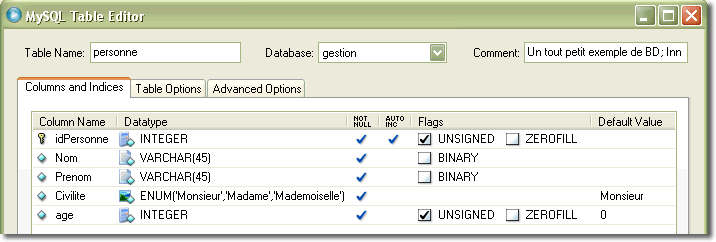
 Cet exemple permet d'enregistrer chaque personnel de l'entreprise dans la base de données au travers du navigateur. Il faut donc construire une application Web qui permet de mettre en oeuvre cet enregistrement. Normalement, cette application Web devrait permettre de réaliser bien d'autres opérations, mais nous nous contanterons juste de cet enregistrement. Cela nous permettra de valider les notions que nous venons d'apprendre.
Cet exemple permet d'enregistrer chaque personnel de l'entreprise dans la base de données au travers du navigateur. Il faut donc construire une application Web qui permet de mettre en oeuvre cet enregistrement. Normalement, cette application Web devrait permettre de réaliser bien d'autres opérations, mais nous nous contanterons juste de cet enregistrement. Cela nous permettra de valider les notions que nous venons d'apprendre.
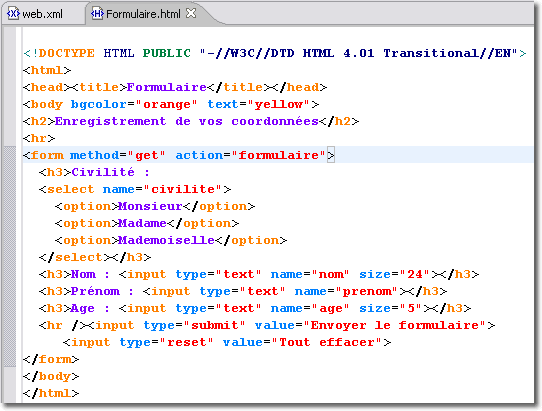
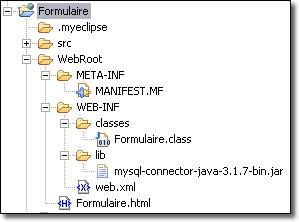
Notre application Web comporte la page d'accueil <Formulaire.hml> qui fait appel par la méthode GET à la servlet <Formulaire.class>. Cette dernière fait appel à la bibliothèque relative au pilote MySql qui doit donc être placé dans le répertoire <WEB-INF/lib>.
Si plusieurs applications Web utilisent le même pilote MySql, il peut sembler redondant que chaque application le stocke dans son propre répertoire <WEB-INF/lib>. Il serait alors préférable que le serveur lui-même dispose d'un seul pilote qui soit accessible par toutes les applications Web. En fait, chaque serveur dispose d'un répertoire particulier qui est prévu pour partager les ressources pour toutes les applications Web. Dans le cas de Tomcat, il s'agit du répertoire <Tomcat/shared> dans lequel sont placés deux sous-répertoires : <classes> et <lib>, qui sont prévues pour placer respectivement, les classes et les bibliothèques communes à toutes les applications Web.
Dans le cas où votre application Web doit être déployée sur un serveur non connu, alors il vaut mieux conserver votre pilote dans le répertoire <lib> de l'application (<WEB-INF/lib>), qui à avoir une certaine redondance.
Vu que notre page d'accueil ne s'appelle pas <index.html>, il est nécessaire de préciser son nom dans le descripteur de déploiement à l'aide de la balise <welcome-file-list>.
Dans le descripteur de déploiement, nous plaçons en paramètres de la servlet, respectivement, le nom du pilote du serveur de base de données ainsi que l'emplacement de ce dernier. Si nous décidons ultérieurement de changer de serveur de base de données, nous n'aurons pas besoin de recompiler la servlet, il suffira de changer les paramètres directement dans le descripteur de déploiement. Ainsi notre servlet s'adapte à n'importe quel serveur de base de données, et ceci quelque soit l'endroit où il se situe dans le réseau de l'entreprise. Les paramètres de servlet sont définis à l'aide de la balise <init-param>.
Puisqu'il s'agit d'un formulaire relativement réduit sans données sensibles, nous utilisons la méthode GET du protocole HTTP.

En imaginant que votre application Web dispose de plusieurs servlets qui font appel à la base de données, il peut être génant de placer les mêmes paramètres d'initialisation <init-param> du pilote JDBC pour chacune de ces servlets. En effet, l'élément <init-param> défini dans le descripteur de déploiement, est associé à une servlet en particulier. Il serait préférable d'utiliser plutôt les paramètres d'initialisation de l'application Web, appelé paramètres de contexte <context-param>, qui sont accessibles pour tous les composants Web constituant l'application Web.
<context-param>, comme pour <init-param> est composé de deux sous-éléments qui correspondent respectivement au nom du paramètre suivi de sa valeur :
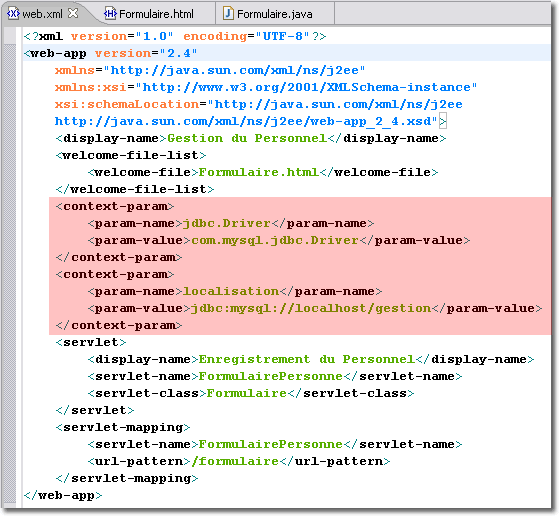
Pour que chacune des servlets récupèrent ces paramètres, il est nécessaire d'abord de solliciter l'objet correspondant au contexte de la servlet (plus précisément, au contexte de l'application Web) à l'aide de la méthode getServletContext(). Cet objet ensuite, peut délivrer les paramètres initiaux de l'application Web grâce à la méthode getInitParameter().

Vous avez remarqué dans les codes précedents l'utilisation de la méthode log(). Cette méthode est issue de la classe GenericServlet. Il existe en fait deux signatures possibles pour cette méthode :
public void log(String) ;
public void log(String, Throwable) ;
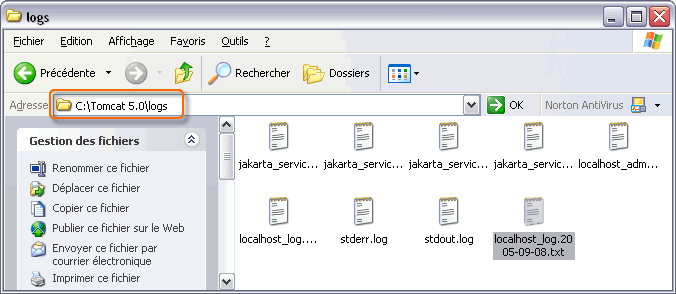
Il est difficile de donner un renseignement particulier à l'aide de l'affichage classique System.out.println(). Il faudrait, en effet, que l'administrateur soit présent au moment de l'affichage dans la console du serveur. Au lieu d'envoyer les données à System.out, ces méthodes log() permettent de les écrire dans le journal (log) des servlets. Un journal est un fichier où sont stockés tous les événements qui arrivent sur le serveur. Chaque jour un nouveau fichier log est créé. Grâce à ce système, l'administrateur peut consulter, à posteriori, tous les problèmes qui sont arrivées sur chacune des applications Web.
Dans le serveur Tomcat, il existe un répertoire qui stocke l'ensemble des journaux. Il s'agit tout simplement du répertoire <logs>.
En reprenant l'exemple précédent :
Et en imaginant que le serveur de base de données ne soit pas en fonctionnement, voilà ce que nous obtenons dans le journal :
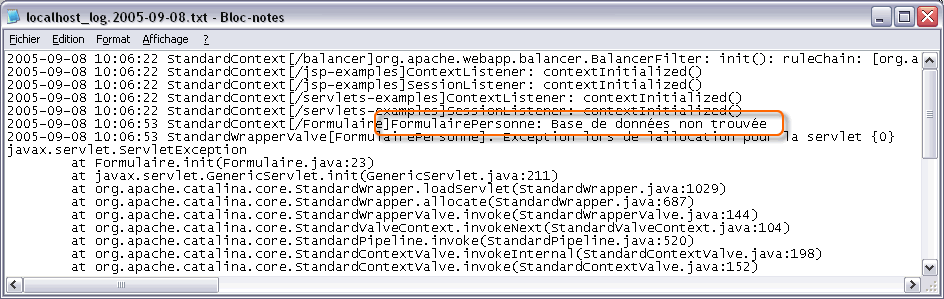
En fait, la journalisation peut servir à n'importe quel type d'information. Ainsi il peut être intéressant de connaître le client qui envoie la requête à la servlet. En voici un exemple ci-dessous :
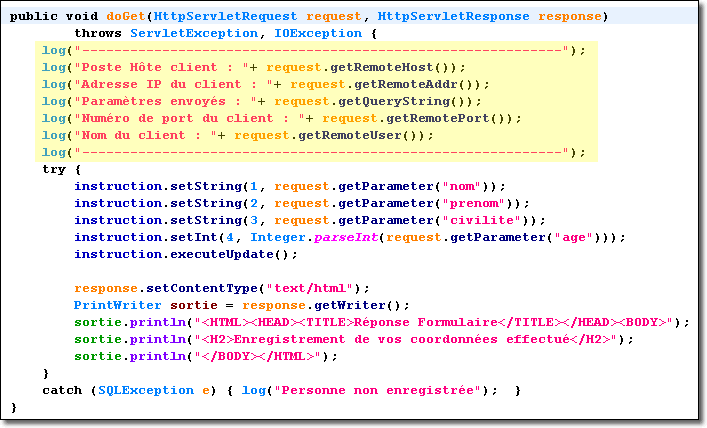

Les exemples de servlets proposés jusqu'à présent consistait uniquement à enregistrer la trace des exceptions dans un journal (comportement exceptionnel correspondant à un disfonctionnement de l'application Web). C'est bien pour l'administrateur, ça l'est beaucoup moins pour le client. Reprenons l'exemple précédent avec comme scenario, le serveur de base de données non opérationnel. Voilà ce que reçoit le client lorsqu'il remplit le formulaire et qu'il envoie la requête au serveur :
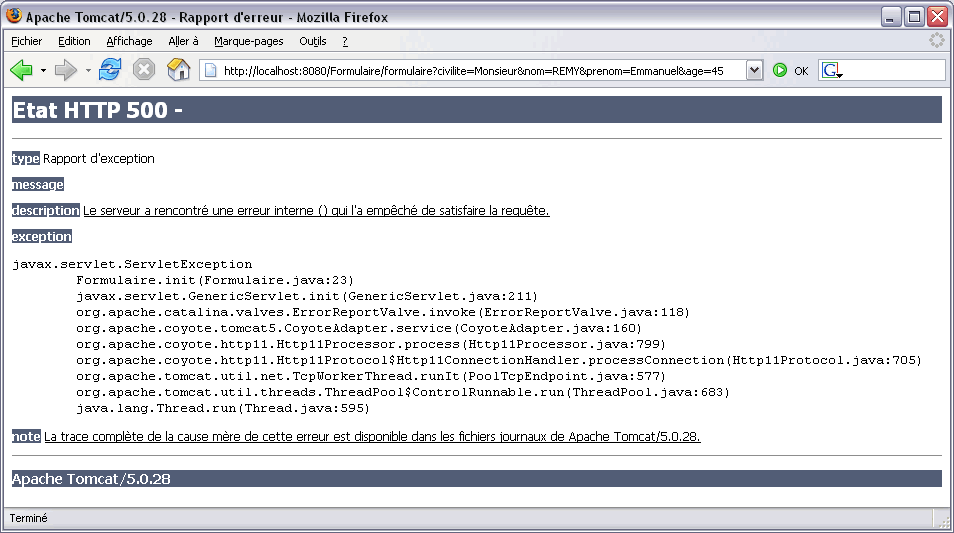
Suivant les serveurs, l'utilisateur voit s'afficher la trace de l'exception ou alors il n'obtient aucune réponse du serveur. Dans tous les cas, l'utilisateur a le sentiment que l'application est défectueuse, ce qui est le cas puisque pour l'instant, il n'y a pas de véritable gestion d'exception.
Autre exemple, que se passe-t-il lorsque l'utilisateur saisie une valeur non numérique dans le champ correspondant à l'âge ? Dans ce cas, le constructeur de la classe Integer lance une exception qui au niveau du client se traduit également par l'affichage de la trace de l'exception.
Cette situation n'est pas acceptable. Nous avertissons le client lorsque l'enregistrement c'est bien déroulé. Nous devons également l'avertir lorsqu'un problème s'est rencontré et lui proposer une solution éventuelle, notamment lors de la mauvaise saisie d'un champ. C'est la moindre des choses. Bref, nous devons gérer l'exception.
Règle de bonne conduite : A moins que l'exception soit une IOException (communication interrompue) survenant lors de l'écriture de la réponse, le client devrait toujours recevoir une réponse intelligible.
La solution au problème que nous venons d'évoquer pourrait être de ne placer un bloc try...catch qu'autour des instructions susceptibles de lancer des exceptions ou d'ajouter des instructions d'affichage dans le bloc catch pour retourner une réponse spécifique en cas d'erreur. C'est effectivement une solution plausible, mais le code de la servlet devient relativement surchargé. Il est préférable de séparer le code du fonctionnement normal de la servlet, avec le code relatif aux problèmes rencontrés, grâce à des pages spécialisées qui s'appellent des pages d'erreur.
Il est possible de définir des pages Web ou des pages JSP qui seront retournées au client suivant le type d'erreur survenu. Ainsi, le client sait toujours à quoi s'en tenir quelque soit le scenario rencontré. Chaque page correspond donc a un type d'erreur. Il faut que le développeur indique quel est la page qui doit être envoyée au client au regard de l'exception lancée. Il le définit, tout simplement, à l'aide du descripteur de déploiement.
Ainsi, lorsqu'un problème survient, le conteneur de servlets activera une page d'erreur d'une part, suivant l'exception qui est lancée, et d'autre part suivant ce que décrit le descripteur de déploiement au regard de cette exception.
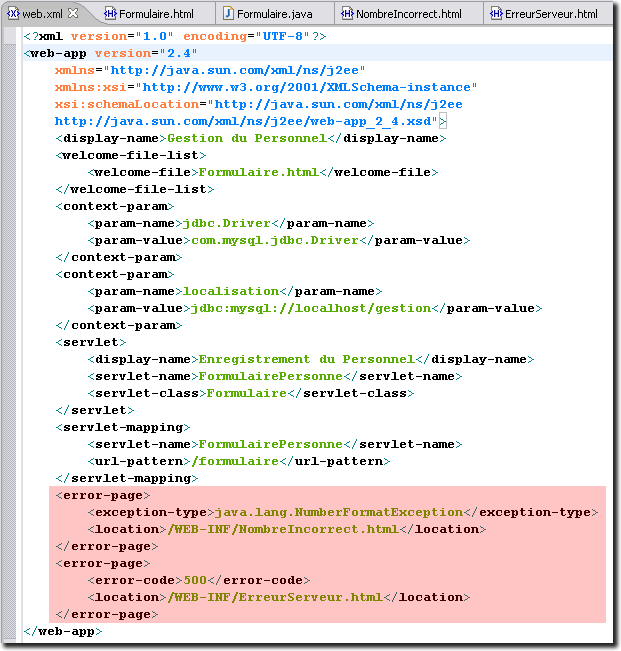
Dans le descripteur de déploiement, l'élément qui décrit les pages d'erreur est <error-page>.
Deux scenarii sont possibles. Soit nous indiquons le type d'erreur exacte, soit un code d'erreur délivré par le protocole HTTP (500 par exemple) qui correspond alors à une erreur plus générique. Le conteneur de servlets prend toujours, dans le descripteur de déploiement, en premier la page qui correspond pile à l'erreur. S'il ne la trouve pas, il se rabat alors sur le code d'erreur qui englobe un ensemble d'erreurs potentielles.
Nous avons donc deux écritures possibles dans le descripteur de déploiement qui correspondent au deux scenarii. C'est le choix des sous-éléments de <error-page> qui détermine le scenario choisi. Ainsi nous pouvons avoir les sous-éléments suivants :
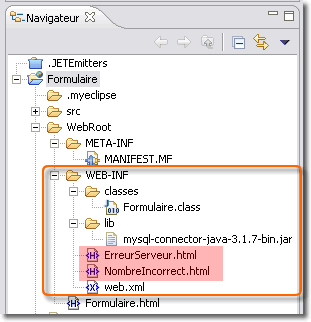
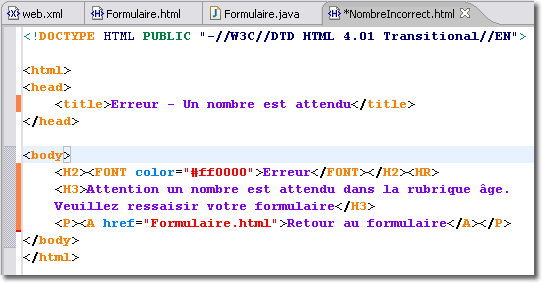
<error-page> <exception-type>java.lang.NumberFormatException</exception-type> <location>/WEB-INF/NombreIncorrect.html</location> </error-page>
ou/et les sous-éléments suivant :
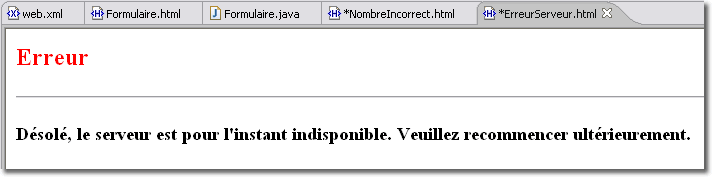
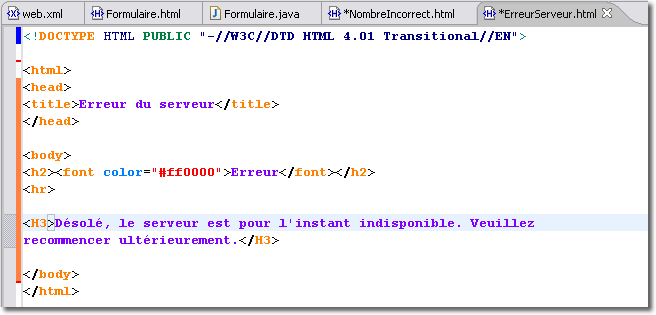
<error-page> <code-type>500</exception-type> <location>/WEB-INF/ErreurServeur.html</location> </error-page>
La première écriture indique que si une erreur de type numérique intervient, c'est la page <NombreIncorrect.html> qui va être envoyée au client. Dans le deuxième cas, c'est l'erreur 500 donnée par le protocole HTTP qui permet d'envoyer au client la page <ErreurServeur.html>.
L'erreur 500 devrait systématiquement être traitée de cette façon. Ce code indique une erreur interne du serveur que celui-ci ne peut traiter. Il peut s'agir d'un problème de compilation d'une JSP ou d'une exception dans une servlet.
En spécifiant une page d'erreur, vous vous assurez que le client recevra une page lisible et correctement mis en forme, plutôt qu'une trace cabalistique.
.
L'élément <location> permet de déterminer quelle est la page qui doit être affichée au client. C'est le serveur qui l'envoie. Ce n'est pas le client qui l'utilise directement. Les pages d'erreur doivent donc être inaccessible de l'extérieur et doivent du coup être placée dans la zone privée de l'application Web, c'est-à-dire dans le répertoire <WEB-INF>.

Un des problèmes les plus délicats à résoudre pour les applications Web utilisant le protocole HTTP est qu'il s'agit d'un protocole sans état. Chaque requête et chaque réponse est indépendant des requêtes et des réponses précédentes. Sans gestion de sessions, tout client envoyant une requête est considéré comme un nouveau client.
Par session, nous entendons que l'application Web peut maintenir l'information pour l'ensemble des servlets et des pages JSP au travers de plusieurs transactions au cours de la navigation de l'utilisateur, de sa première requête jusqu'à la fin de la conversation ainsi établie ; ce qu'il s'appelle aussi la persistance.
Assurer la continuité à travers une série de page Web est importante dans nombre d'application, comme par exemple la gestion de connexion ou le suivi des achats dans un caddie. Dans un sens, les données de la session prennent la place des données d'instance de votre objet de servlet. Cela permet de stocker les données entre les invocations de vos méthodes de service. Au delà de ça, nous permettons la communication dans le temps entre les différentes servlets (et pages JSP ou autres composants Web) faisant parties de la même application Web.
Toutes les données constituant une session sont concervées sur le serveur dans l'application Web correspondante. Comme plusieurs sessions peuvent exister, le serveur a donc besoin d'un moyen permettant d'associer une session particulière et la requête du client. Il existe deux techniques pour mettre en oeuvre ce principe :
Pour être sûr que mon application Web fonctionne, je prend systématiquement la technique de réécriture d'URL. Dans ce cas, la servlet doit efectuer une opération supplémentaire. Les URL contenues dans les pages Web envoyées au client doivent être personnalisées afin d'y ajouter l'identificateur de session grâce à la méthode suivante :
public void encodeURL(String urlProchaineServlet) ;
Cette méthode réécrit l'URL passée en argument si le client n'accepte pas les cookies. Si le client accepte les cookies, L'URL est retournée inchangée.
.
Deux méthodes de l'interface HttpServletRequest permettent de créer une session :
HttpSession getSession() ;
HttpSession getSession(boolean) ;
Si une session existe déjà, les méthodes getSession(), getSession(true) et getSession(false) renvoient la session existante. Dans le cas contraire, getSession() et getSession(true) créent une nouvelle session. Si vous souhaitez tester l'existence d'une session sans la créer, vous devez utiliser la version surchargée getSession(false). Elle ne crée pas automatiquement une nouvelle session et renvoie null s'il n'en n'existe pas.
public void invalidate() ;
Pour supprimer immédiatement une session, on peut utiliser la méthode invalidate(). Après avoir appelé invalidate() pour une session, il n'est plus possible d'y accéder.
Toute sorte de chose ! L'utilisation la plus évidente concerne la persistence des données entre l'interaction d'un client et l'application Web correspondante. L'interface HttpSession définie pour cela un certain nombre de méthodes.
Les méthodes les plus utilisées sont celles qui permettent de créer, de modifier ou de lire les attributs de la session. Un objet peut être placé dans une session au moyen de la méthode setAttribute(String, Object). Une session étant accessible à la totalité de l'application, tous les composants peuvent alors lire la valeur de l'attribut et la modifier. Les objets placés dans une session peuvent ensuite être obtenus au moyen de la méthode getAttribute(String).
public Object getAttribute(String nom) ;
public Enumeration getAttributeNames() ;
public void setAttribute(String nom, Object valeur) ;
public void removeAttribute(String nom) ;
Toutes sortes d'objets peuvent être placés dans une session. Il peut s'agir par exemple de texte décrivant les préférences de l'utilisateur. Une session peut également être employée pour stocker le contenu d'un caddie virtuel d'un client dans une application de commerce électronique.
Nous allons reprendre l'application Web précédente à laquelle nous allons rajouter la servlet supplémentaire Confirmation qui validera la saisie introduite dans le formulaire.

C'est cette servlet qui crée la session. Si l'utilisateur confirme ses choix, c'est alors la servlet Formulaire qui est ensuite appelée au moyen de la technique de la réécriture D'URL. La servlet Formulaire quant à elle, récupère les informations stockées dans la session et les envoient dans la base de données. Une fois que cette opération est réalisée, la servlet Formulaire met fin à la session et avertie l'utilisateur du bon déroulement des opérations.

Page Web issue de Formulaire.class
Remarquez l'identificateur de session jsessionid au cas où l'utilisateur bloque les cookies sur son navigateur.
.

Sur cette page Web statique, rien de bien nouveau par rapport à l'écriture précédente si ce n'est l'appel à la servlet Confirmation en lieu et place de la servlet Formulaire.
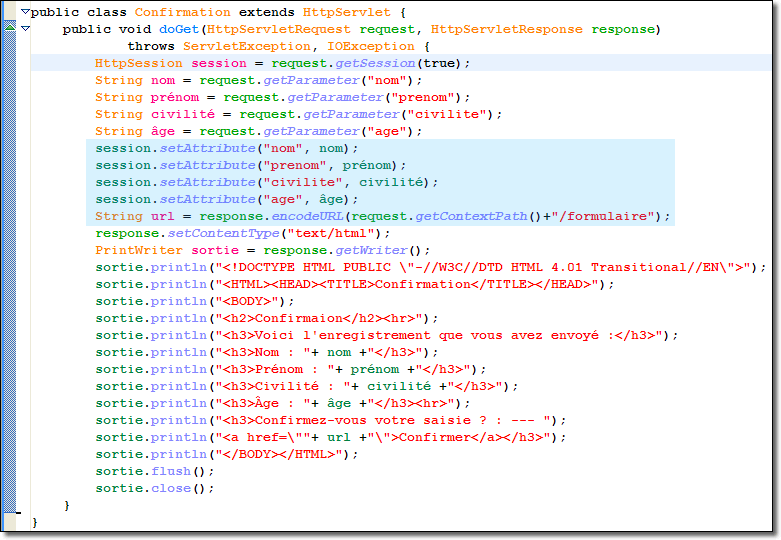
Notre nouvelle servlet Confirmation commence par essayer d'accéder à une session existante en appelant la méthode request.getSession(true). Avec cet argument, une nouvelle session est créée si aucune n'est trouvée.
Une fois que nous avons obtenu la session, nous y stockons le nom, le prénom, la civilité et l'âge de la personne saisie grâce à la méthode session.setAttribute(String attribut , Object valeur).
Après avoir stocker toutes les informations relative à la personne dans notre session, nous devons avertir le client s'il désire confirmer sa saisie. Mais avant cela, il est nécessaire de placer l'identificateur de session à la suite de l'URL d'appel de la prochaine servlet en réécrivant l'URL grâce à la méthode response.encodeURL(nomdeLaProchaineServlet).
url = response.encodeURL(request.getContextPath() + "/formulaire") ;
Remarquez que nous récupérons l'adresse de l'application Web grâce à la méthode getContextPath() de l'objet request. Cette méthode nous évite de préciser l'adresse absolue de l'application Web. Cela nous permet de placer éventuellement notre application Web sur un autre serveur sans qu'il soit nécessaire de tout réécrire et donc de tout recompiler.
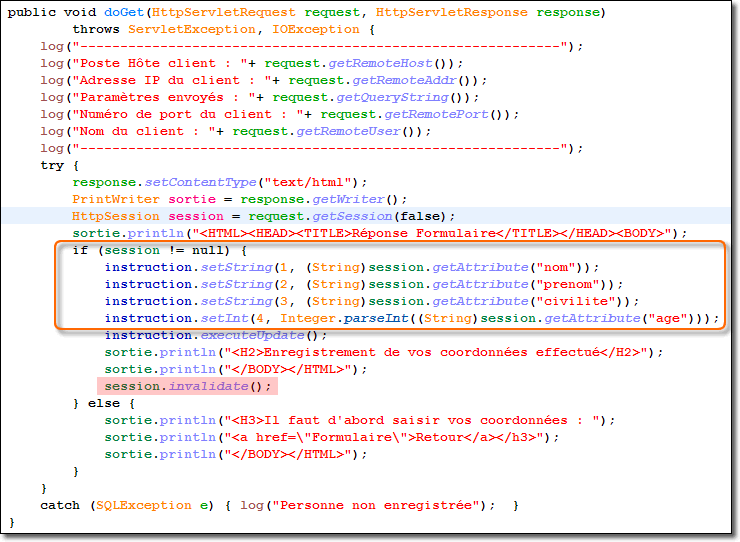
Cette servlet n'est active que si le client à confirmé l'enregistrement. Ainsi, il est nécessaire de récupérer maintenant les informations stockées dans la session grâce à la méthode session.getAttribute(String nomAttribut).
Au préalable, il est nécessaire de tester l'existence de la session au moyen de la méthode request.getSession(false). Cette méthode ne créée pas de session. Elle sert à connaître le nom de la session spécifié par l'identificateur de session qui est lui-même délivré par l'URL comme cela vous est montré ci-dessous.
Cette servlet doit rentrer en relation avec la base de données afin d'enregistrer effectivement les informations requises. A la suite de cela, Il est bon de prévenir l'utilisateur du bon déroulement de l'opération et, puisque le cycle est terminé, de clôturer la session au travers de la méthode session.invalidate().
Il peut être utile de récupérer ou d'avoir des informations sur l'identificateur de session. Voici quelques méthodes utiles pour cela :
String getRequestedSessionId() // Retourne l'identificateur affecté à la session.
boolean isRequestedSessionIdValid() // Retourne true si la requête contient un identificateur de session valide.
boolean isRequestedSessionIdFromCookie() // Retourne true si l'identificateur de session a été transmis dans un cookie.
boolean isRequestedSessionIdFromURL() // Retourne true si l'identificateur de session a été transmis au moyen de la réécriture D'URL.
Avec l'API Servlet 2.3, l'une des fonctionnalité les plus puissantes dans une application Web est la possibilité de définir des contraintes de sécurité déclarative. Par sécurité déclarative, on entend le fait qu'il suffit de décrire dans votre fichier web.xml les parties de votre application Web (accès à des documents, répertoires, servlets, etc.) qui sont protégés par mot de passe, le type d'utilisateurs autorisés à y accéder et la classe du protocole de sécurité nécessaire aux communications (crypté ou pas).
Pour implémenter ces procédures de sécurité de base, il n'est pas nécessaire d'ajouter du code à vos servlets.
.
Deux types d'entrées du fichier web.xml contrôlent la sécurité et l'authentification (avec toutefois un troisème pour la définition du rôle) :
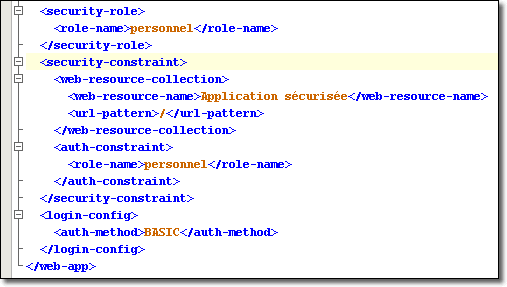
Revenons sur notre application Web Personnel. Je désire que cette application Web ne soit accessible que par login et mot de passe. L'extrait suivant du fichier web.xml définit une zone appelée Application sécurisée, à partir d'un modèle d'URL “/” et précise que seul les utilisateurs possédant le rôle personnel peuvent y accéder.
Il utilise la forme la plus simple du processus de connexion : le modèle d'identification BASIC, qui affiche dans le navigateur une simple boîte de dialogue nom d'utilisateur/mot de passe :
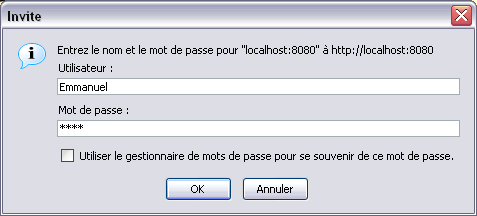
Ici, le modèle d'URL est “/”, ce qui signifie que toute l'application Web est sécurisée. Nous pourrions sécuriser qu'une seule partie de l'application Web, par exemple un répertoire de l'application qui ne sera accessible que par mot de passe.
Soit, par exemple, le répertoire secret qui devrait être sécurisé, il faudrait alors préciser le modèle d'URL suivant :
<url-pattern>/secret/</url-pattern>
L'entrée de contrainte de sécurité apparaît donc dans le fichier web.xml après toutes les entrées relatives à la servlet et au filtre. Chaque bloc <security-constraint> contient une section <web-ressource-collection> qui fournit une liste nommée de modèle d'URL d'accès à certaines zones de l'application Web, suivie d'une section <auth-contraint> listant les rôles utilisateur autorisés à accéder à ces zones, au moyen des balises successives <role-name>.
Toutefois, pour que la section <auth-contraint> soit efficace, il est préférable que ces rôles aient été préalablement définies, en dehors de la balise <security-contraint>, au moyen de la balise <security-role> à l'intérieur de laquelle se trouve également une suite de balises <role-name>.
<security-role> <role-name>personnel</role-name> </security-role> <security-constraint> ... <auth-constraint> <role-name>personnel</role-name> </auth-constraint> </security-constraint>
Attention : Avant que cela fonctionne, il reste toutefois une étape à franchir : créer le rôle utilisateur "personnel", ainsi qu'un véritable utilisateur "Emmanuel" possédant ce rôle dans votre serveur d'application.
Dans le serveur Tomcat, il est facile d'ajouter des utilisateurs et d'attribuer des rôles ; il suffit d'éditer le fichier conf/tomcat-users.xml. En voici un exemple ci-dessous avec l'ajout d'un seul utilisateur (N'oubliez pas de fabriquer le rôle).
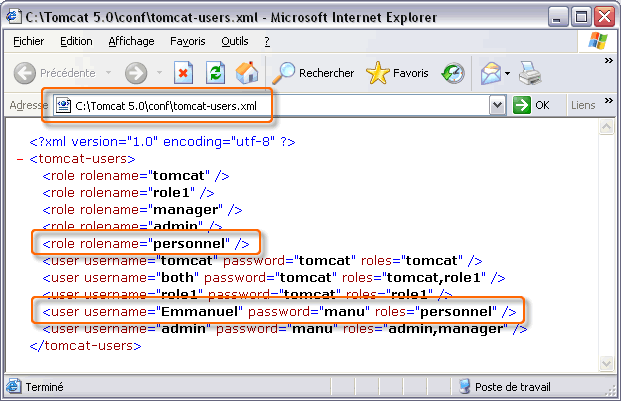
Le droit d'accès à des zones protégées est accordé à des rôles d'utilisateur et non pas à des utilisateurs individuels. Un rôle utilisateur représente en fait un groupe d'utilisateurs. Au lien d'allouer les droits à chaque utilisateur, par nom, on les alloue à des rôles, les utilisateurs se voyant attribuer un ou plusieurs rôles. C'est le cas notamment ci-dessus avec l'utilisateur admin qui peut aussi bien jouer le rôle de gestionnaire d'application Web (manager) que le rôle d'administrateur (admin) du serveur web Tomcat.
Lorsqu'un utilisateur essaie d'accéder à une zone protégée par mot de passe, le login est testé afin de vérifier s'il possède le rôle adéquat.
.
Pour que votre application Web soit parfaitement sécurisée, il faudrait également protéger les informations qui transitent sur le réseau. Il nous faut donc aborder un élément supplémentaire de la contrainte de sécurité : la garantie de transport. Chaque bloc <security-contraint> peut finir par une entrée <user-data-contraint>, qui indique lequel des trois niveaux de sécurité de transport est retenu pour le protocole utilisé lors du transfert de données de et vers la zone protégées.

Les trois niveaux de sécurité sont :
La section <login-config> détermine exactement comment un utilisateur s'authentifie à l'entrée de la zone protégée. La balise <auth-method> permet d'utiliser quatre types d'authentification :
La méthode FORM est la plus utilisée car elle permet de personnaliser la pagede connexion (nous vous recommandons l'usage de SSL afin de sécuriser le stream de données. Il est également possible de spécifier une page d'erreur en cas d'échec de l'authentification.

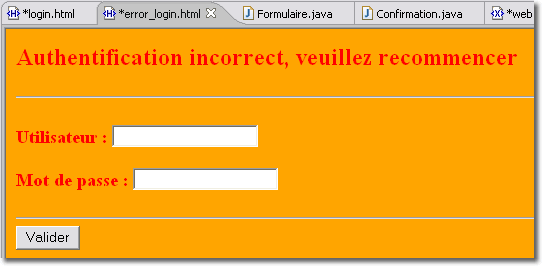
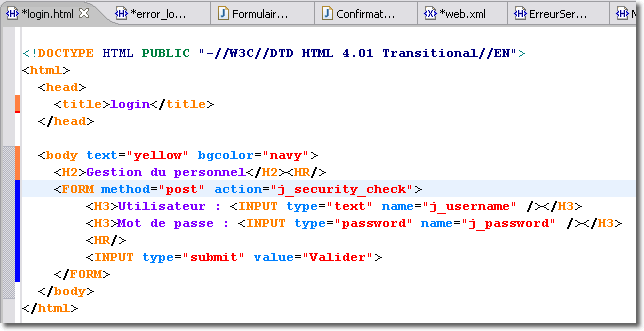
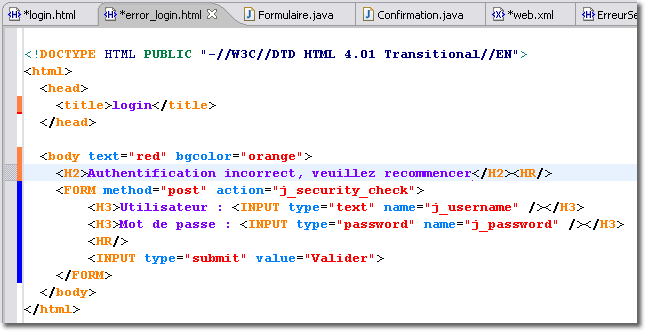
La servlet "Formulaire.java" que nous avons mis en oeuvre est relativement sophistiquée puisqu'elle intègre le stockage des informations, saisie par l'opérateur, dans la base de données. Cette servlet intègre également la journalisation des requêtes dans un fichier journal mémorisant toutes les tentatives d'accès. Pour cette journalisation, nous avons dû modifier la servlet en ce sens, la recompiler et la redéployer. C'est alors que l'on (votre patron, ou votre client) va vous demander de modifier l'application pour que le journal soit enregistré dans une base de données. Il vous faudra modifier de nouveau la servlet, la compiler, la déployer... C'est alors que l'on va vous demander ...
Bientôt, votre servlet sera remplie de code utile mais pas exactement en rapport avec sa fonction initiale : recevoir les requêtes et répondre aux clients. Nous avons besoin d'une solution plus efficace.
Les filtres sont un moyen permettant de donner à une application une structure modulaire. Ils permettent d'encapsuler différentes tâches annexes qui peuvent être indispensables pour traiter les requêtes. Ainsi, dans notre exemple, nous pouvons créer un filtre prévu uniquement pour la journalisation des événements, alors que la servlet principale s'occupe du traitement de la requête proprement dite. Grâce à cette modularité, il devient facile de modifier le comportement de l'application Web en modifiant uniquement son descripteur de déploiement.
La fonction principale d'une servlet consiste uniquement à recevoir des requêtes et répondre aux clients. Toute autre activité annexe est du ressort d'une autre classe. Aussi, lorsque que vous avez à implémenter une fonction particuliere, vous pouvez tirer profit des filtres et de la façon dont ils permettent d'encapsuler ces traitements spécifiques. Par ailleurs, leur modularité leur permet d'être utilisés avec plusieurs servlets différentes, ce qui facilite la maintenance en évitant la duplication du code.
Les filtres sont chaînés, ce qui signifie que lorsque nous appliquons plus d'un filtre, la requête du serveur est passée à travers chacun d'eux de manière séquentielle, chacun ayant l'opportunité d'agir dessus ou de la modifier (notion de filtre) avant de passer au prochain. De manière similaire, à l'exécution, le résultat de la servlet est repassée à travers la chaîne en sens inverse. Il est donc possible au travers des filtres de modifier également la réponse de la servlet, même si le cas le plus fréquent consiste plutôt à faire des traitements au niveau de la requête. L'ordre des filtres de la chaîne est spécifié dans le descripteur de déploiement.
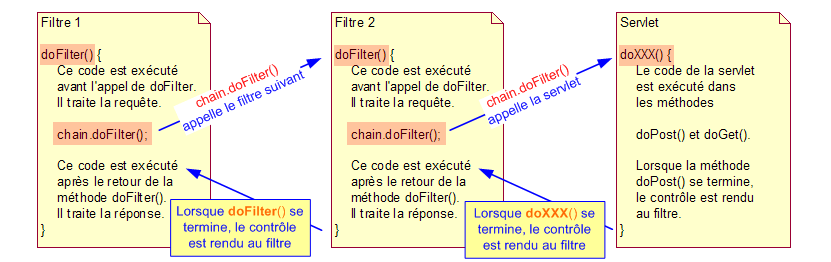
Lorsque la méthode doFilter() d'un filtre est appelée, un des arguments passés est une référence à un objet de type FilterChain. Lorsque le filtre appelle chain.doFilter(), le filtre suivant la chaîne est exécuté. Le code placé avant chain.doFilter() est exécuté avant le traitement de la servlet (ou d'un autre filtre). Toute modification que le filtre doit apporter à la requête doit donc être effectué avant cet appel. Le code placé après cet appel est exécuté après le traitement de la servlet. C'est donc là que doivent être effectuées toutes les modifications à apporter à la réponse. Si le filtre doit agir sur la requête et sur la réponse, il contiendra donc du code avant et après l'invocation de la méthode chain.doFilter().
Par ailleurs, si l'un des filtres doit interrompre le traitement (par exemple en cas d'échec de l'authentification d'un client implémenté dans le prmier filtre), il peut le faire simplement en n'appelant pas la méthode doFilter().
Les filtres de servlet peuvent opérer sur tout type de requêtes d'une application Web, pas seulement sur celles gérées par des servlets. Ils peuvent également être appliqués à du contenu statique. Finalement ils peuvent être utilisés pour tous les composants Web : Servlet, JSP, EJB et HTML.
Pour créer un filtre pour notre application Web, nous devons accomplir deux tâches. La première consiste à écrire une classe implémentant l'interface Filter, la seconde à modifier le descripteur de déploiement de l'application pour indiquer au conteneur qu'il doit utiliser le filtre.
L'API Filter comporte trois interfaces : Filter, FilterChain, et FilterConfig. javax.servlet.Filter est l'interface implémntée par les filtres. Elle déclare trois méthodes :
Vous pouvez constater que cette interface ressemble beaucoup à l'interface Servlet. Vous ne serez donc sûrement pas surpris d'apprendre que le cycle de vie des filtres ressemble également beaucoup à celui des servlets :
L'interface javax.servlet.FilterChain représente une chaîne de filtres. Elle déclare une méthode que chaque filtre peut invoquer pour appeler le filtre suivant dans la chaîne :
void doFilter(ServletRequest request, ServletResponse response) : Cette méthode entraine l'appel du filtre suivant dans la chaîne. Si le filtre appelant est le dernier de la chaîne, la ressource cible de la requête est appelée (par exemple une servlet).
Lorsque la méthode doFilter() d'un filtre est appelée, un des arguments passés est une référence à un objet de type FilterChain. Lorsque le filtre appelle chain.doFilter(), le filtre suivant la chaîne est exécuté.
Le descripteur de déploiement est utilisé pour indiquer au conteneur le ou les filtres qu'il doit appeler pour chaque servlet de l'application. Deux éléments sont utilisés pour décrire les filtres et indiquer à quelles servlets, ils doivent être appliqués.
Le premier est <filter>. Voici un exemple de <filter> contenant tous les sous-éléments possibles :
<filter> <icon>Chemin d'accès à une icône</icon> <filter-name>Le nom du filtre pour l'application Web</filter-name> <display-name>Le nom utilisé par le gestionnaire d'application Web</display-name> <description>Une description de l'application</description> <filter-class>Le nom qualifié de la classe filtre</filter-class> <init-param> <param-name>nom du paramètre</param-name> <param-value>valeur du paramètre</param-value> </init-param> </filter>
Seuls les sous-éléments <filter-name> et <filter-class> sont requis. Si un élément <init-param> est employé, les sous-éléments <param-name> et <param-value> doivent être présents. Ces paramètres sont accessibles grâce à l'interface FilterConfig.
Le second élément est filter-mapping. Il peut prendre une des deux formes suivantes :
<filter-mapping> <filter-name>Même nom que pour l'élément filter</filter-name> <url-pattern>Schéma d'URL auquel le filtre doit être appliqué</url-pattern> </filter-mapping>
ou
<filter-mapping> <filter-name>Même nom que pour l'élément filter</filter-name> <servlet-name>Nom de la servlet auquel le filtre doit être appliqué</servlet-name> </filter-mapping>
N'oubliez pas que l'ordre des éléments dans le descripteur de déploiement est important. Les éléments <filter> doivent être placés avant les éléments <filter-mapping> qui doivent se trouver avant les éléments <servlet>.
Si plusieurs filtres sont nécessaires, ils doivent être présentés par des éléments <filter-mapping> séparés. Les filtres sont appliqués dans l'ordre du descripteur de déploiment.
<filter-mapping> <filter-name>FiltreB</filter-name> <servlet-name>Formulaire</servlet-name> </filter-mapping> <filter-mapping> <filter-name>FiltreA<filter-name> <servlet-name>Formulaire</servlet-name> </filter-mapping>
Toute requête adressée à la servlet Formulaire est d'abord envoyée à FiltreB, car il est le premier dans le descripteur de déploiement. Lorsque FiltreB invoque la méthode chain.doFilter(), le FiltreA est appelé. Lorsque ce dernier invoque lui-même la méthode chain.doFilter(), la servlet Formulaire est enfin exécutée.
Nous allons reprendre l'application Web précédente, et nous allons modifier son comportement. En effet, souvenez-vous, dans la servlet Formulaire, nous avions placée la journalisation des événements - grâce à la méthode log(). Ce n'est pas du tout le but de cette servlet qui doit s'occuper avant tout de la sauvegarde des informations saisies par l'opérateur dans la base de données.
Nous allons donc mettre en oeuvre un filtre qui va s'occuper uniquement de cette journalisation. De plus, nous allons faire en sorte que cette journalisation, donc ce filtre, soit lancée pour tous les composants qui constitue notre application Web. Ainsi, il sera possible de contrôler précisément le parcours de l'opérateur.
L'exemple ci-dessous nous montre le passage de l'opérateur par la page d'accueil "Formulaire.html", la confirmation de sa saisie grâce à la servlet "Confirmation.java" ainsi que l'enregistrement définitif au moyen de la servlet "Formulaire.java".
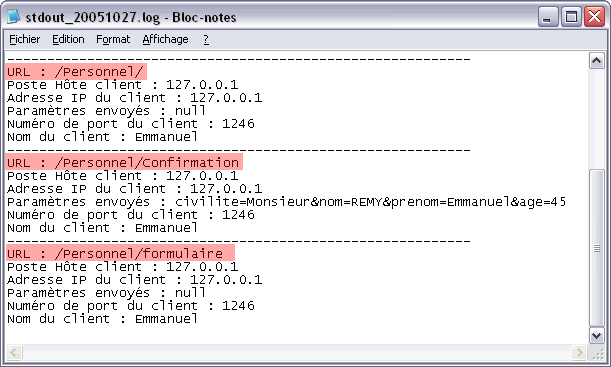
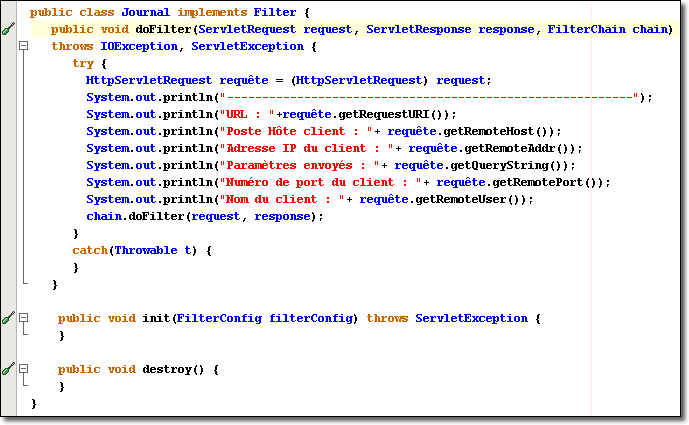
Nous enlevons toutes les commandes log() de la servlet "Formulaire.java" et nous les plaçons dans le filtre "Journal.java" implémenté ci-dessous :
Vous remarquez que les méthodes log() ont été supplantées par les méthodes println() sur la sortie standard. Le journal ainsi créé est représenté alors par le fichier stdout.log, comme vous l'avez vu d'ailleurs sur le journal d'exemple.
Voici ce que devient la servlet "Formulaire.java" sans les méthodes log() :
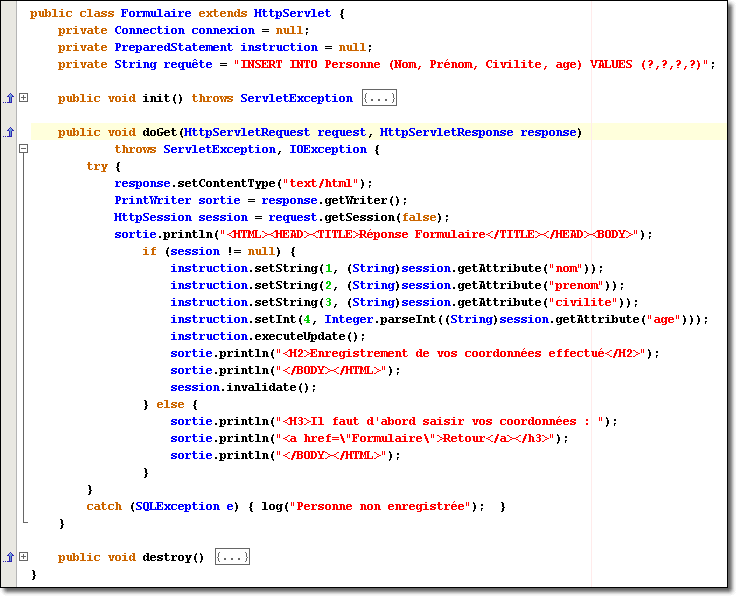
Attention, n'oubliez pas de compléter le descripteur de déploiement pour que ce filtre soit utilisé. Si vous désirez que tous les éléments de l'application Web activent le filtre avant d'être lancés, il suffit de prendre plutôt la balise <url-pattern> dans la mapping de filtre et de placer l'URL suivante : /* (le joker spécifie bien la prise en compte de tous les éléments).
