Les pages Web dynamiques
Les pages Web dynamiques
 Cette étude porte uniquement sur les principes généraux des pages Web dynamiques. Une fois que nous aurons bien maîtriser ces différents concepts, nous pourrons aborder les cas pratiques en se servant de la plateforme Java. Java met en oeuvre un certain nombre de technologies pour la mise en oeuvre de ces pages Web dynamiques, comme les servlets, les JSP, les EJB (Entreprise Java Bean). Ces différentes technologies seront présentées lors des études suivantes. Toutefois, avant de les traiter, je pense qu'il convient de connaître quelques éléments qui permettent de comprendre ce que sont les services et les applications Web.
Cette étude porte uniquement sur les principes généraux des pages Web dynamiques. Une fois que nous aurons bien maîtriser ces différents concepts, nous pourrons aborder les cas pratiques en se servant de la plateforme Java. Java met en oeuvre un certain nombre de technologies pour la mise en oeuvre de ces pages Web dynamiques, comme les servlets, les JSP, les EJB (Entreprise Java Bean). Ces différentes technologies seront présentées lors des études suivantes. Toutefois, avant de les traiter, je pense qu'il convient de connaître quelques éléments qui permettent de comprendre ce que sont les services et les applications Web.
Les sites Web dynamiques existent parce qu'Internet existe. La structure et le fonctionnement d'un site dynamique sont donc fortement liés au fonctionnement d'Internet et au mode de communication des ordinateurs. Les applications développées pour les sites Internet repose essentiellement sur le modèle client-serveur.
Le modèle client-serveur a été conçu bien avant Internet. Le concept a étté mis en place lorsque les ordinateurs ont pus être connectés pour former un réseau local et ainsi établir un dialogue entre eux. Pour bien comprendre le le principe, nous allons le décrire de façon imagée.
Les termes client et serveur ne sont pas anodins. Ils sont issus du monde réel. En effet, le fonctionnement client-serveur se rapproche tout naturellement des rapports existants entre le client et le serveur d'un restaurant.
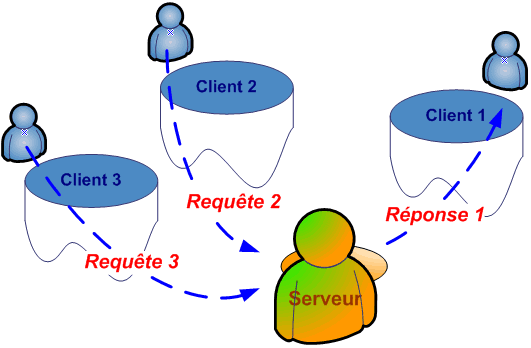
Lorsque vous allez au restaurant, vous êtes le client et vous souhaitez commander un menu. Pour cela, vous appelez le serveur (requête). Ce dernier doit gérer plusieurs tables (clients). Il répond au fur et à mesure, à la demande chaque client en fonction de ce qui est disponible. Il établit donc une relation entre les clients de la salle et les ressources disponibles en cuisine.
Transposé dans le monde informatique, le concept client-serveur est très proche de cette description. Le client est une application qui s'exécute qui s'exécute sur un ordinateur personnel. Le serveur est une autre application qui gère des ressources partagées, et qui est programmé pour rendre un service donné en réponse à une requête qui lui est adressé.
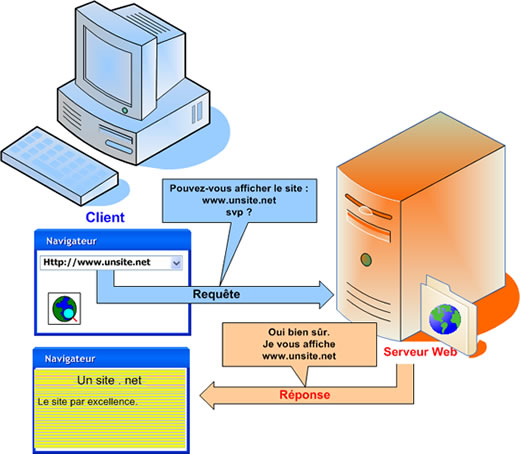
Le Web est un exemple tout choisi d'architecture client-serveur : les sites sont animés par des serveurs qui rendent toujours le même type de services aux clients que sont les navigateurs. Quel service au juste ? Le serveur Web attend qu'on lui demande des données (statiques ou résultant d'un traitement). En réponse à une requête, il envoie le contenu des données requises. Le navigateur de son côté est client du serveur auquel il a envoyé une requête HTTP. Le navigateur présente à l'utilisteur une réponse une fois les données téléchargées.
Un client est une application qui se connecte à un autre ordinateur pour obtenir ou modifier des informations à l'aide de requêtes. Un serveur est une application située sur un ordinateur très puissant capable de gérer un très grand nombre de requêtes simultanément. Un serveur est toujours en attente de requêtes. |
 |
Il existe différent types de serveurs : serveur de messagerie, serveur d'accès distant, serveurs de transfert de fichiers, serveurs de base de données. Parallèlement, il existe différentes applications clientes pour consulter ou modifier les ressources des serveurs. Pour que tous les clients et tous les serveurs arrivent à travailler ensemble, des règles de communication ont été définies.
Dans le modèle client-serveur, tout est construit autour de la communication entre le client et le serveur. Sans cette communication, il ne peut y avoir de requête ni de réponse. La communication s'établit en suivant un certain nombre de rêgles que l'on appelle protocoles de communications.
Ces protocoles sont en réalité des modèles qui décrivent l'organisation et la transmission des données numériques lors d'un échange entre le client et le serveur. Les rêgles qui en découlent sont respectées à la fois par les applications clientes et par les applications serveur. Elles ont fait l'objet d'une norme, de façon à ce que toute application orientée sur un service (messagerie électronique, Web, etc.) soit capable de comprendre un message provenant d'une autre application orientée sur le même service.
Nous venons de le voir, la clé de voute qui permet à une architecture client-serveur de fonctionner, sans d'ailleurs que ni le client ni le serveur ne sachent comment ils fonctionnent l'un l'autre, est l'utilisation d'un protocole commun. Un protocole établit la norme que doit respecter un client pour communiquer avec un serveur ;
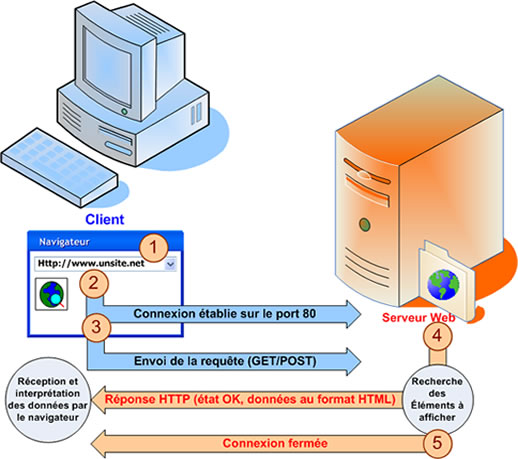
Le protocole le plus utilisé pour communiquer avec un serveur Web sur Internet est le protocole HTTP (Hyper Text Transfer Protocole). Il définit les règles de communication entre un client (navigateur) et un serveur Web.
Un serveur Internet est accessible par un nom de machine hôte (par exemple java.sun.com, www.google.fr). Chaque nom correspond à une adresse IP, qui est l'identifiant représentant la machine hôte où tourne un serveur (moi même, je possède un nom, et pour communiquer avec moi et recevoir des lettres, le facteur a besoin de connaître mon adresse). Ce nombre de 32 bits est généralement noté sous la forme d'une suite de 4 nombres de 8 bits chacun séparés par des points (par exemple 127.0.0.1). Chaque machine relié à Internet (client et serveur) est identifié une adresse IP qui la représente sur le réseau.
Pour distinguer les applications serveurs (les services) qui tournent simultanément sur une même machine hôte, un deuxième niveau d'identification est nécessaire, qui est donné par le numéro de port, codé sur 16 bits et donc compris entre 0 et 65535. Le fait de faire référence à un port indique quel est le service que nous désirons utiliser.
Pour éviter que ce soit l'anarchie, des numéros de port ont été normalisé par rapport au services que nous utilisons le plus couramment. Ainsi, le service Web (HTTP) utilise le numéro de port 80. Le service FTP utilise le numéro de port 21, etc. Ces numéros de port étant normalisés, ils constituent donc les valeurs par défaut, et du coup, lorsque nous utilisons le service associé, il n'est pas nécessaire de préciser le numéro. Implicitement, c'est le bon numéro de port qui est pris.
La requête la plus simple du protocole HTTP est formé de GET suivi d'une URL qui pointe sur des données (fichier statiques, traitement dynamique...). Elle est envoyée par un navigateur quand nous saisissons directement une URL dans le champ d'adresse du navigateur. Le serveur HTTP répond en renvoyant les données demandées.
Les méthodes POST ou GET déterminent la façon dont est envoyée la requête au serveur. En effet, il existe plusieurs façons de transmettre une requête, notamment lorsque celle-ci contient des valeurs (paramètres) qui permettront au serveur de faire des réponses différenciées (pages Web dynamiques).
Classiquement, la transmission des valeurs via le navigateur s'effectue par la mise en place d'une chaîne de données à la suite de l'URL. Ce type de transmission est utilisée par la méthode GET. Par exemple, L'URL :
http://www.unsite.net/rechercher?nom=Lagafe&prénom=Gaston
indique au serveur qu'il doit afficher la page associée aux paramètres nom et prénom qui ont pour valeur Lagafe et Gaston respectivement.
La syntaxe générale de l'URL correspondant à la méthode GET est la suivante :
Avec la méthode GET, les informations sont donc stockées dans l'URL. Ce mode de transmission est le plus simple de mise en oeuvre. Par contre, il présente l'inconvénient de rendre visibles les données sensibles telles qu'un mot de passe ou un code de carte banquaire. En outre, la longueur de la chaîne transférée est limitée.
Si le nombre de paramètres est important, ou si les valeurs sont confidentielles, il est conseillé d'utiliser la méthode POST. En effet, la méthode POST résout ces deux problèmes en envoyant les valeurs des paramètres dans le corps même de la requête et non via l'URL. De cette façon, aucune valeur n'apparaît dans l'URL. Cette dernière reste fixe quelles que soient les options choisies par l'internaute.
Par contre, la récupération des valeurs paraît un peu plus délicate puiqu'il faut scruter la requête elle-même. Ceci dit, nous verrons que dans Java, cela ne pose aucun problème puisque des objets sont spécialisés dans ce domaine. Il suffira d'appeler la méthode adéquate de l'objet concerné.
Ainsi, lorsque le serveur a traité une requête et envoyé sa réponse au client, la connexion entre le serveur et le client est clôturée. Le serveur pert la trace du client. Si ce dernier émet une nouvelle requête, le serveur la traite, ne sachant pas qu'il a déjà communiqué avec ce client.
La communication entre un client et un serveur n'est pas continue. On appelle ce mode de communication, le mode non connecté.
.
Cette façon de communiquer a des conséquences importantes sur le développement de sites commerciaux où le serveur doit enregistrer les achats du client. En effet, lorsque l'internaute achète sur Internet, il sélectionne chaque objet qu'il souhaite acheter l'un après l'autre. A chaque objet sélectionné correspond une requête distincte de la précédente (avec systématiquement une ouverture et une fermeture de la connexion).
Le serveur, ou plus exactement le programme exécuté sur le serveur, doit donc se souvenir du client afin de regrouper toutes les requêtes d'achat et de les identifier comme appartenant au même internaute.
Pour réaliser cette performance, il convient de mettre en place un suivi de session qui permet d'enregistrer toutes les requêtes d'un même client sous un numéro d'identification.
Une URL (Uniform Resource Locator) est une chaîne de caractères qui désigne une ressource sur un serveur. Elle est de la forme :
protocole://hote:port/chemin/vers/ressource
ou :
Une ressource représente une information ou un programme mis à disposition. Ce peut être un fichier, une image, une application, à vrai dire tout ce qui pourrait être utilisé d'une manière ou d'une autre.
Les numéros des ports des protocoles FTP et HTTP sont respectivement et implicitement les numéros 21 et 80 dans une URL s'ils ne sont pas mentionnés. Voici quelques exemples :
http://www.google.fr:80/ équivalent à http://www.google.fr/
http://magasin-en-ligne:80/jsp.informatique/Vitrine/index.jsp?page=cahier
http://www.autre.com/index.html
Dans ce chapitre, nous allons découvrir ce qu'est plus précisémment le protocole HTTP qui dans certain cas peut s'averer utile.
Le protocole HTTP (HyperText Transfer Protocol) est le protocole le plus utilisé sur Internet depuis 1990. La version 0.9 était uniquement destinée à transférer des données sur Internet (en particulier des pages Web écrites en HTML . La version 1.0 du protocole (la plus utilisée) permet désormais de transférer des messages avec des en-têtes décrivant le contenu du message en utilisant un codage de type MIME (voir plus loin).
Le but du protocole HTTP est de permettre un transfert de fichiers (essentiellement au format HTML) localisés grâce à URL entre un navigateur (le client) et un serveur Web.
Une requête HTTP est un ensemble de lignes de texte envoyé au serveur par le navigateur. Elle comprend :
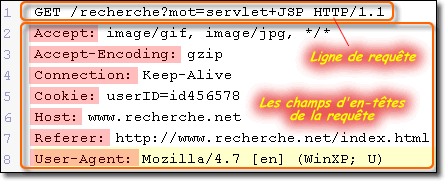
| Commande | Description |
| GET | La méthode GET permet d'envoyer les éléments du formulaire au travers de l'URL, en ajoutant l'ensemble des paires nom/valeur à l'URL, séparé de celui-ci par un point d'interrogation ?. Chaque paire nom/valeur est séparée de la suivante par l'opérateur &. Toutefois, la longueur de la chaîne URL étant limitée à 255 caractères, les informations situées au-delà de cette limite seront irrémédiablement perdues. De plus, cela crée une URL surchargée dans la barre d'adresse d'un navigateur et peut dévoiler des informations sensibles comme un mot de passe... |
| HEAD | Cette commande s'intéresse à la partie en-têtes du protocole HTTP. Les champs d'en-tête de la requête : il s'agit d'un ensemble de lignes facultatives permettant de donner des informations supplémentaires sur la requête et/ou le client (Navigateur, système d'exploitation, ...). Chacune de ces lignes est composée d'un nom qualifiant le type d'en-tête, suivi de deux points (:) et de la valeur de l'en-tête. |
| POST | la méthode POST est une bonne alternative à la méthode GET. Cette méthode code les informations de la même façon que la méthode GET (encodage URL et paires nom/valeur) mais elle envoie les données à la suite des en-têtes HTTP, dans un champ appelé corps de la requête. De cette façon la quantité de données envoyées n'est plus limitée, et est connue du serveur grâce à l' en-tête permettant de connaître la taille du corps de la requête. |
| PUT | La méthode PUT demande à ce que l'entité jointe soit enregistrée par le serveur sous l'URL visée. Si cette URL pointe vers une ressource déjà existante, l'entité jointe sera considérée comme une nouvelle version de celle jusqu'alors présente sur le serveur origine. Si l'URL visée pointe sur une ressource inexistante, et à la condition que cette URL puisse être définie en tant que nouvelle ressource du serveur, ce dernier créera une nouvelle ressource sous cette URL. La différence fondamentale entre les méthodes POST et PUT réside dans la signification donnée à l'URL visée. Celle-ci, pour une méthode POST désigne la ressource "active" à laquelle l'entité doit être confiée dans le but d'un traitement. Cette ressource peut être un programme, un routeur ou un autre protocole, ou encore une entité acceptant des annotations. Par contre, L'URL précisée dans une méthode PUT nomme l'entité incluse dans la requête - Le client sait parfaitement de quelle URL il s'agit et le serveur n'applique la méthode à aucune autre ressource. |
| DELETE | Suppression de la ressource située à l'URL spécifiée. |
| Nom de l'en-tête | Description |
| Accept | Type de contenu accepté par le navigateur (par exemple text/html ). Voir types MIME |
| Accept-Charset | Jeu de caractères attendu par le navigateur (par exemple ISO-8859-1). |
| Accept-Encoding | Codage de données accepté par le navigateur (par exemple gzip). S'il reçoit cette en-tête, le serveur est libre d'encoder en utilisant le format spécifié. |
| Accept-Language | Langage attendu par le navigateur (anglais par défaut) |
| Authorization | Identification du navigateur auprès du serveur. Cet en-tête est utilisé pour s'identifier lorsqu'ils accèdent à des pages Web protégées par mot de passe. |
| Content-Length | Longueur du corps de la requête applicable uniquement à des requêtes de type POST. Cet en-tête fournit la taille des données POST en octets. |
| Content-Type | Type de contenu du corps de la requête (par exemple text/html ). Voir types MIME |
| Date | Date de début de transfert des données. |
| From | Permet de spécifier l'adresse e-mail du client. |
| From | Permet de spécifier que le document doit être envoyé s'il a été modifié depuis une certaine date. |
| Host | Les navigateurs doivent spécifier cet en-tête, qui indique l'hôte et le port tel qu'ils sont fournis dans l'URL original. |
| Link | Relation entre deux URL. |
| Orig-URL | URL d'origine de la requête. |
| Range | Cet en-tête rarement utilisé permet à un client possédant une copie partielle d'un document de demander seulement les parties qui lui manque. |
| Referer | URL du lien à partir duquel la requête a été effectuée. |
| User-Agent | Chaîne donnant des informations sur le client, comme le nom et la version du navigateur, du système d'exploitation. |
Une réponse HTTP est un ensemble de lignes envoyées au navigateur par le serveur. Elle comprend:

| Nom de l'en-tête | Description |
| Content-Encoding | Type de codage du corps de la réponse. |
| Content-Language | Type de langage du corps de la réponse. |
| Content-Length | Longueur du corps de la réponse. |
| Content-Range | Ce nouvel en-tête de HTTP 1.1 est envoyé avec les réponses contenant des documents incomplets et spécifie la proportion du document envoyé. Par exemple, la valeur byte 500-900/2345 signifie que la réponse actuelle contient les octets 500 à 900 d'un document contenant au total 2345 octets. |
| Content-Type | Type de contenu du corps de la réponse (par exemple text/html ). Voir types MIME |
| Date | Date de début de transfert des données. |
| Expires | Date limite de consommation des données. |
| Forwarded | Utilisé par les machines intermédiaires entre le navigateur et le serveur. |
| Location | Redirection vers une nouvelle URL associée au document. |
| Server | Caractéristiques du serveur ayant envoyé la réponse. |
Ce sont les codes que vous voyez lorsque le navigateur n'arrive pas à vous fournir la page demandée. Le code de réponse est constitué de trois chiffres : le premier indique la classe de statut et les suivants la nature exacte de l'erreur.
| Code | Message | Description |
| 10x | Message d'information | Ces codes ne sont pas utilisés dans la version 1.0 du protocole |
| 20x | Réussite | Ces codes indiquent le bon déroulement de la transaction |
| 200 | OK | La requête a été accomplie correctement. |
| 201 | CREATED | Elle suit une commande POST, elle indique la réussite, le corps du reste du document est sensé indiquer l' URL à laquelle le document nouvellement créé devrait se trouver. |
| 202 | ACCEPTED | La requête a été acceptée, mais la procédure qui suit n'a pas été accomplie. |
| 203 | PARTIAL INFORMATION | Lorsque ce code est reçu en réponse à une commande GET, cela indique que la réponse n'est pas complète. |
| 204 | NO RESPONSE | Le serveur a reçu la requête mais il n'y a pas d'information à renvoyer. |
| 205 | RESET CONTENT | Le serveur indique au navigateur de supprimer le contenu des champs d'un formulaire. |
| 206 | PARTIAL CONTENT | Il s'agit d'une réponse à une requête comportant l'en-tête range. Le serveur doit indiquer l'en-tête content-Range. |
| 30x | Redirection | Ces codes indiquent que la ressource n'est plus à l'emplacement indiqué |
| 301 | MOVED | Les données demandées ont été transférées à une nouvelle adresse. |
| 302 | FOUND | Les données demandées sont à une nouvelle URL, mais ont cependant peut-être été déplacées depuis... |
| 303 | METHOD | Cela implique que le client doit essayer une nouvelle adresse, en essayant de préférence une autre méthode que GET. |
| 304 | NOT MODIFIED | Si le client a effectué une commande GET conditionnelle (en demandant si le document a été modifié depuis la dernière fois) et que le document n'a pas été modifié il renvoie ce code. |
| 40x | Erreur due au client | Ces codes indiquent que la requête est incorrecte |
| 400 | BAD REQUEST | La syntaxe de la requête est mal formulée ou est impossible à satisfaire. |
| 401 | UNAUTHORIZED | Le paramètre du message donne les spécifications des formes d'autorisation acceptables. Le client doit reformuler sa requête avec les bonnes données d'autorisation. |
| 402 | PAYMENT REQUIRED | Le client doit reformuler sa demande avec les bonnes données de paiement. |
| 403 | FORBIDDEN | L'accès à la ressource est tout simplement interdit. |
| 404 | NOT FOUND | Classique! Le serveur n'a rien trouvé à l'adresse spécifiée. Parti sans laisser d'adresse... :) |
| 50x | Erreur due au serveur | Ces codes indiquent qu'il y a eu une erreur interne du serveur |
| 500 | INTERNAL ERROR | Le serveur a rencontré une condition inattendue qui l'a empêché de donner suite à la demande (comme quoi il leur en arrive des trucs aux serveurs...) |
| 501 | NOT IMPLEMENTED | Le serveur ne supporte pas le service demandé (on ne peut pas tout savoir faire...) |
| 502 | BAD GATEWAY | Le serveur a reçu une réponse invalide de la part du serveur auquel il essayait d'accéder en agissant comme une passerelle ou un proxy. |
| 503 | SERVICE UNAVAILABLE | Le serveur ne peut pas vous répondre à l'instant présent, car le trafic est trop dense (toutes les lignes de votre correspondant sont occupées veuillez rappeler ultérieurement) |
| 504 | GATEWAY TIMEOUT | La réponse du serveur a été trop longue vis-à-vis du temps pendant lequel la passerelle était préparée à l'attendre (le temps qui vous était imparti est maintenant écoulé...) |
Le type MIME (Multipurpose Internet Mail Extensions) est un standard qui a été proposé par les laboratoires Bell Communications en 1991 afin d'étendre les possibilités du courrier électronique (mail), c'est-à-dire de permettre d'insérer des documents (images, sons, texte, ...) dans un courrier.
Depuis, le type MIME est utilisé d'une part pour typer les documents attachés à un courrier mais aussi pour typer les documents transférés par le protocole HTTP. Ainsi lors d'une transaction entre un serveur web et un navigateur internet, le serveur web envoie en premier lieu le type MIME du fichier envoyé au navigateur, afin que ce dernier puisse savoir de quelle manière afficher le document.
Un type MIME est constitué de la manière suivante :
Content-type: type_mime_principal/sous_type_mime
Une image GIF a par exemple le type MIME suivant :
Content-type: image/gif
| Type MIME | Type de fichier | Extension associée |
| application/acad | Fichiers AutoCAD | dwg |
| application/clariscad | Fichiers ClarisCAD | ccad |
| application/drafting | Fichiers MATRA Prelude drafting | drw |
| application/dxf | Fichiers AutoCAD | dxf |
| application/i-deas | Fichiers SDRC I-deas | unv |
| application/iges | Format d'échange CAO IGES | igs,iges |
| application/octet-stream | Fichiers binaires non interprétés | bin |
| application/oda | Fichiers ODA | oda |
| application/pdf | Fichiers Adobe Acrobat | |
| application/postscript | Fichiers PostScript | ai,eps,ps |
| application/pro_eng | Fichiers ProEngineer | prt |
| application/rtf | Format de texte enrichi | rtf |
| application/set | Fichiers CAO SET | set |
| application/sla | Fichiers stéréolithographie | stl |
| application/solids | Fichiers MATRA Solids | dwg |
| application/step | Fichiers de données STEP | step |
| application/vda | Fichiers de surface | vda |
| application/x-mif | Fichiers Framemaker | mif |
| application/x-csh | Script C-Shell (UNIX) | dwg |
| application/x-dvi | Fichiers texte dvi | dvi |
| application/hdf | Fichiers de données | hdf |
| application/x-latex | Fichiers LaTEX | latex |
| application/x-netcdf | Fichiers netCDF | nc,cdf |
| application/x-sh | Script Bourne Shell | dwg |
| application/x-tcl | Script Tcl | tcl |
| application/x-tex | fichiers Tex | tex |
| application/x-texinfo | Fichiers eMacs | texinfo,texi |
| application/x-troff | Fichiers Troff | t,tr,troff |
| application/x-troff-man | Fichiers Troff/macro man | man |
| application/x-troff-me | Fichiers Troff/macro ME | me |
| application/x-troff-ms | Fichiers Troff/macro MS | ms |
| application/x-wais-source | Source Wais | src |
| application/x-bcpio | CPIO binaire | bcpio |
| application/x-cpio | CPIO Posix | cpio |
| application/x-gtar | Tar GNU | gtar |
| application/x-shar | Archives Shell | shar |
| application/x-sv4cpio | CPIO SVR4n | sv4cpio |
| application/x-sv4crc | CPIO SVR4 avec CRC | sc4crc |
| application/x-tar | Fichiers compressés tar | tar |
| application/x-ustar | Fichiers compressés tar Posix | man |
| application/zip | Fichiers compressés ZIP | man |
| audio/basic | Fichiers audio basiques | au,snd |
| audio/x-aiff | Fichiers audio AIFF | aif,aiff,aifc |
| audio/x-wav | Fichiers audio Wave | wav |
| image/gif | Images gif | man |
| image/ief | Images exchange format | ief |
| image/jpeg | Images Jpeg | jpg,jpeg,jpe |
| image/tiff | Images Tiff | tiff,tif |
| image/x-cmu-raster | Raster cmu | cmu |
| image/x-portable-anymap | Fichiers Anymap PBM | pnm |
| image/x-portable-bitmap | Fichiers Bitmap PBM | pbm |
| image/x-portable-graymap | Fichiers Graymap PBM | pgm |
| image/x-portable-pixmap | Fichiers Pixmap PBM | ppm |
| image/x-rgb | Image RGB | rgb |
| image/x-xbitmap | Images Bitmap X | xbm |
| image/x-xpixmap | Images Pixmap X | xpm |
| image/x-xwindowdump | Images dump X Window | man |
| multipart/x-zip | Fichiers archive zip | zip |
| multipart/x-gzip | Fichiers archive GNU zip | gz,gzip |
| text/html | Fichiers HTML | htm,html |
| text/plain | Fichiers texte sans mise en forme | txt,g,h,c,cc,hh,m,f90 |
| text/richtext | Fichiers texte enrichis | rtx |
| text/tab-separated-value | Fichiers texte avec séparation des valeurs | tsv |
| text/x-setext | Fichiers texte Struct | etx |
| video/mpeg | Vidéos MPEG | mpeg,mpg,mpe |
| video/quicktime | Vidéos QuickTime | qt,mov |
| video/msvideo | Vidéos Microsoft Windows | avi |
| video/x-sgi-movie | Vidéos MoviePlayer | movie |
Les ressources accessibles par le protocole HTTP peuvent être des fichiers statiques (pages Web déjà constituées et placées sur le serveur Web) ou des programmes qui renvoie un contenu généré dynamiquement à la demande de l'utilisateur (page Web dynamique). Dans ce cas là, la page Web n'existe pas encore, elle est construite en retour d'une requête de l'utilisateur. Par ailleurs, le contenu de cette page n'est pas prédéterminé, il dépend de la demande de l'utilisateur. On interface ces programmes avec le serveur HTTP en utilisant le standard CGI.
Ce type de programme est utilisé dans de nombreux domaines :
Un CGI (Common Gateway Interface, traduisez interface de passerelle commune) est donc un programme exécuté du côté serveur, permettant de cette façon l'affichage de données traitées par le serveur (provenant d'une autre application, comme par exemple un système de gestion de base de données, d'où le nom de passerelle) en réponse à une demande l'utilisateur. C'est l'usage le plus courant des programmes CGI.
Un des grands intérêts de l'utilisation de CGI est la possibilité de fournir des pages dynamiques, c'est-à-dire des pages pouvant être différentes selon un choix ou une saisie de l'utilisateur. L'application la plus fréquente de cette technique repose sur l'utilisation de formulaires HTML permettant à l'utilisateur de choisir ou saisir des données, puis à cliquer sur un bouton de soumission du formulaire, envoyant alors les données du formulaire en paramètre du programme CGI.
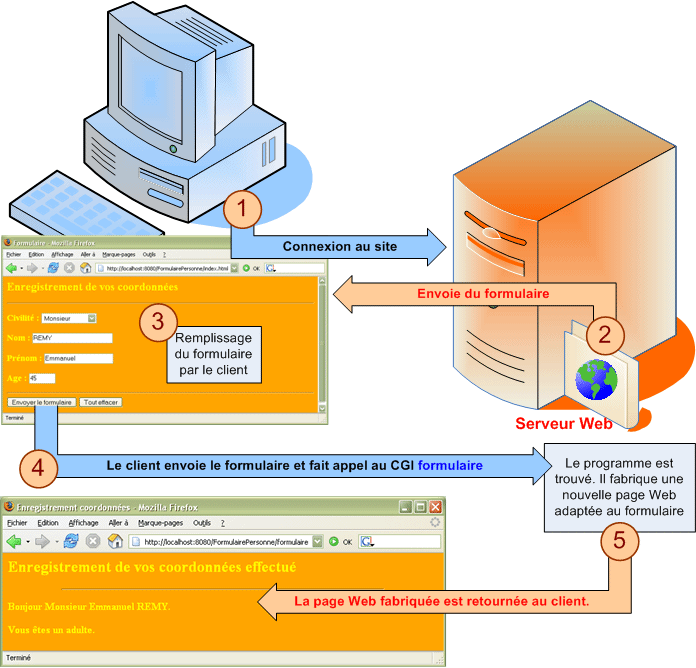
Un programme CGI peut être écrit dans n'importe quel langage ou du moins à peu près... pourvu que celui-ci soit:
Nous, nous utiliserons le langage Java. Dans ce cas là, deux techniques peuvent être utilisées, soit les servlets, soit les JSP.
.
Les scripts CGI ont donc pour but d'afficher des pages Web ayant été générées par un programme informatique, d'où la dénomination de pages web dynamiques pour les pages créées par ce moyen. Finalement, les scripts CGI sont tout simplement des sripts de page Web classiques composés des balises (tags) HTML valides. Toutefois, étant donné que le serveur renvoie telles quelles au navigateur les informations que lui fournit le script CGI, il est nécessaire d'ajouter aux données à afficher les en-têtes HTTP permettant au navigateur de comprendre qu'il s'agit d'une page web...
Le programme CGI doit créer lui-même les en-têtes HTTP.
.
En effet, lorsqu'un programme CGI renvoie un fichier, il doit commencer par envoyer un en-tête HTTP permettant de préciser le type de contenu envoyé au navigateur appelé type MIME, c'est-à-dire:
Vous vous demandez sûrement pourquoi le serveur ne pourrait pas ajouter tout seul les en-têtes HTTP, comme il le fait dans le cas des pages web statiques (fichiers .htm et .html). En fait, comme nous venons de le voir, un programme CGI peut renvoyer n'importe quel type de contenu, c'est-à-dire qu'il est capable de renvoyer une image octet par octet, qui sera intégrée dans un document HTML par exemple, pourvu que le CGI renvoie un en-tête correspondant au type de l'image. Une fois de plus, le serveur pourrait éventuellement être capable de reconnaître le type de données que le CGI renvoie et adapter les en-têtes HTTP en fonction. En réalité les en-têtes HTTP peuvent faire beaucoup plus que préciser le type de document envoyé, il est par exemple possible d'effectuer une redirection en renvoyant un en-tête de redirection. Une des applications peut par exemple consister à pointer vers un CGI, qui va enregistrer des informations sur le visiteur (une sorte de compteur de visites amélioré), puis le diriger vers un document...
Lorsque vous souhaitez acheter un billet d'avion sur un site Internet, vous devez fournir un certain nombre d'informations, comme les dates de voyage, le lieu de départ ainsi que la destination et enfin le numéro de la carte de paiement. Toutes ces données sont à transmettre au serveur afin d'être traitées et stockées.
Cette transmission s'effectue à l'aide des formulaires HTML ou au travers de scripts JSP.
.
Les formulaires interactifs permettent donc aux auteurs de pages Web de dialoguer avec leurs lecteurs, un peu comme les coupons-réponse que l'on trouve dans les magazines.
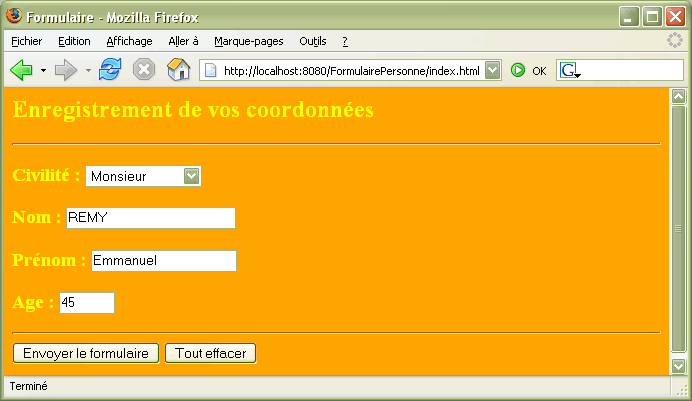
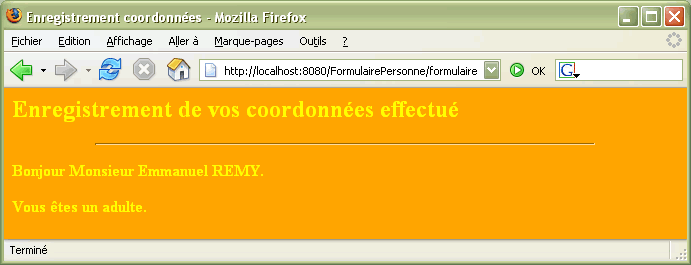
Le lecteur saisit des informations en remplissant des champs ou en cliquant sur des boutons, puis appuie sur un bouton de soumission (submit). Lorsque l'utilisateur valide sa saisie, l'ensemble du formulaire est envoyer au programme CGI qui traite ce type d'informations. Le site qui gère ce ou cet ensemble de programmes CGI est désigné par l'URL correspondante.
Les formulaires sont délimités par la balise <form> ... </form>, une balise qui permet de regrouper plusieurs éléments de formulaire (boutons, champs de saisie, ...) et qui possède les attributs suivants :
Vous avez ci-dessous l'exemple correspondant au formulaire présenté en tête de chapitre en utilisant la méthode POST.
C'est assez rare, mais si nous désirons envoyer le résultat d'un formulaire dans notre courrier électronique, voici ce que nous devons placer dans la balise <form>.
<form method="post" action="mailto:emmanuel.remy@wanadoo.fr" enctype="text/plain">
La balise <FORM> constitue en quelque sorte un conteneur permettant de regrouper des éléments qui vont permettre à l'utilisateur de choisir ou de saisir des données qui seront envoyées à l'URL indiqué dans l'attribut ACTION de la balise <FORM> par la méthode indiquée par l'attribut METHOD.
Il est possible d'insérer n'importe quel élément <HTML> de base dans une balise <FORM> (textes, boutons, tableaux, liens,...) mais il est surtout intéressant d'insérer des éléments interactifs. Ces éléments interactifs sont :
La balise <input> permet de proposer à l'internaute de saisir une information à travers différents types d'interfaces graphiques. Cette information peut être saisie sous la forme d'une ligne de texte, d'un nom de fichier ou encore de cases à cocher. La balise <INPUT> est la balise essentielle des formulaires, car elle permet de créer un bon nombre d'éléments "interactifs". La syntaxe de cette balise est la suivante :
<INPUT type="Nom du champ" value="Valeur par défaut" name="Nom de l'élément" maxlength="valeur maximale" size ="taille">
Attention : L'attribut name est essentiel car il permettra au script CGI de connaître le champ associé à la paire nom/valeur, c'est-à-dire que le nom du champ sera suivi du caractère "=" puis de la valeur entrée par l'utilisateur, ou dans le cas contraire de la valeur par défaut repéré par l'attribut value.
L'attribut type permet de préciser le type d'élément que représente la balise <INPUT>, voici les valeurs que ce champ peut prendre :





La balise <TEXTAREA> permet de définir une zone de saisie plus vaste par rapport à la simple ligne de saisie que propose la balise <INPUT>. <textarea>...</textarea> insère une zone de saisie de texte sur plusieurs lignes. Le texte par défaut est celui affiché entre les deux balises.
Cette balise possède les attributs suivants :

La balise <SELECT> permet de créer une liste déroulante d'éléments (précisés par des balises <OPTION> à l'intérieur de celle-ci). Les attributs de cette balise sont :