
![]() Chapitres traités
Chapitres traités
XML (eXtensible Markup Language) , est le standard soutenu par le W3C pour le balisage de documents. Il définit une syntaxe générique utilisée pour formater des données avec des balises simples et compréhensibles par l'homme. Ce format est suffisamment souple pour être adapté à des contextes aussi variés que les sites WEB, l'échange de données électroniques, les dessins vectoriels, les menus déroulants de logiciels, les descripteurs de déploiement, les procédures d appel à distance (XML-RPC), etc.
XML est un métalangage à balises pour les documents texte. Les données sont incluses dans un document XML sous forme de chaînes de caractères et elles sont délimitées par des marqueurs textuels (balises) qui les décrivent. En XML, l'unité de base de données et son marqueur est appelée élément. Les spécifications XML précisent la syntaxe exacte de ce marqueur :
A première vue, un marqueur dans un document XML ressemble de prêt à ceux d'un document HTML, mais des différences cruciales demeurent. Contrairement à HTML, XML n'est pas limité à un balisage prédéfini. Au sein d'un document XML, vous êtes libre de définir vos propres balises (eXtensible).
Rappelons qu'un document HTML est un document texte composé de paires « balise entrante / balise fermante » qui servent à la mise en forme (aspect visuel) du texte ou des images. Cette mise en forme se réalise effectivement au travers de balises prédéfinies comme mettre un texte en gras, en italique, etc.
Les marqueurs dans un document XML décrivent la structure du document. Ils vous laissent voir quels éléments sont associés aux autres. Dans un document XML, le document décrit également la sémantique du document. Par exemple, il indique qu'un élément est une date, une personne, ou un code barre. Dans une application XML, le marqueur n'apporte aucune information sur la façon dont le document doit être affiché. Il n'indique pas qu'un élément doit s'afficher en gras ou en italique. XML est un langage à balises structurel et sémantique et non un langage de présentation comme le HTML.
Un document XML contient du texte mais jamais de données binaires. Il peut donc être édité avec n'importe quel programme capable de lire un fichier texte. Fréquemment, un fichier représentant le document XML comporte l'extension « *.xml ».
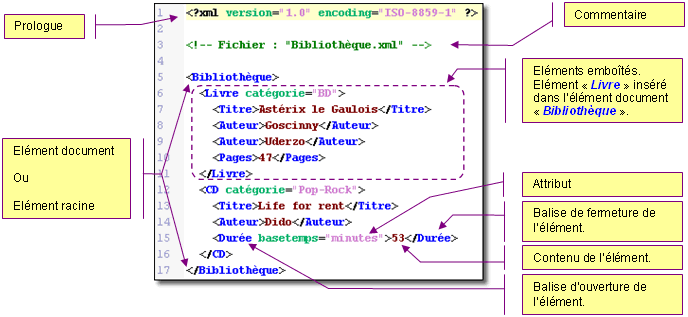
La première ligne d'un document XML s'appelle le prologue et contient, entre autre, la déclaration de la version XML employée pour la description des informations.
![]()

Les documents XML n'ont pas besoin d'avoir une déclaration XML. Cependant, si un document XML en possède une, alors elle se trouvera en premier dans le document. Elle ne doit pas être précédée de commentaires, de blancs ou d'instruction de traitement. La raison est que le parseur XML (programme annexe qui analyse la validité d'un document XML) emploie les cinq premiers caractères ( < ?xml ) pour déterminer l'encodage, afin de savoir si le document utilise un jeu de caractères mono ou multi-octets.
Le prologue permet également de spécifier le standard de codage des caractères employés dans le document. L'écriture des caractères XML se conforme à la norme UNICODE, norme développée afin de faciliter l'internationalisation des fichiers. A ce titre nous pouvons spécifier la norme ISO-8859-1 qui correspond au codage des caractères pour les langues d'Europe occidentale (Latin-1). Ce codage permet entre autre, d'utiliser la plupart des accentuations possibles.
![]()
Le prologue peut contenir également des liens vers des fichiers externes qui présentent des informations supplémentaires comme, par exemple, un fichier DTD qui s'intéresse à la validation du document XML en cours (ce sujet sera traité ultérieurement).
L'exemple ci-dessous présente un seul élément dont le type est personne . Cet élément est délimité par la balise de début <personne> et la balise de fin </personne>. Tout ce qui se trouve entre la balise de début et de fin de l'élément (de manière exclusive) est le contenu de l'élément. Le contenu de cet élément est la chaîne de caractères « Gaston Lagafe ».

<personne> et </personne> sont les balises. La chaîne de caractères « Gaston Lagafe » est une donnée textuelle.
Les balises XML ressemblent à peu près aux balises HTML. Les balises de début commence par un « < » et les balises de fin par un « </ ». Les deux sont suivies du nom de l'élément et terminées par un « > ». Toutefois, à la différence des balises HTML, vous avez la possibilité de créer toutes les nouvelles balises XML dont vous avez besoin. Les noms des balises reflètent le type de leur contenu, et non la façon dont le contenu devrait s'afficher.
Un élément vide désigne un élément dont la valeur n'est pas renseignée. La première syntaxe qui vient à l'esprit consiste, tout simplement, à utiliser une balise d'ouverture suivie immédiatement de la balise de fermeture, sans spécification de contenu entre les balises.
![]()
Il existe une syntaxe spéciale pour les éléments vides. Ces éléments peuvent être représentés par des balises qui commencent par « < » et qui se terminent par « /> ».
![]()
Nous pourrions nous poser la question de l'intérêt d'avoir des éléments vides. Ils sont souvent utiles en corrélations avec les attributs (voir plus loin dans le cours). Prenons l'exemple de l'élément IMG du standard HTML. Cet élément est effectivement vide. Tous les renseignement le concernant se situent aux niveaux des attributs. Voici justement un exemple en XML tiré de cette balise HTML :
![]()
Pour un élément donné, les noms présents dans la balise entrante et fermante doivent être identiques. La casse des noms doit être respectée. XML, à la différence du HTML, fait une différence entre les minuscules et les majuscules. Ainsi <personne>, <PERSONNE> et <Personne> sont en fait trois balises différentes sans aucuns rapport.
![]()
Les documents XML sont construits sous une forme arborescente, c'est-à-dire que les éléments sont emboîtés les uns dans les autres en respectant une structure hiérarchique. En voici un exemple :

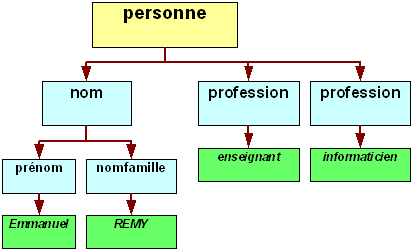
Ce document XML est composé d'un élément personne. Cette fois-ci, cet élément ne contient aucune donnée. Il contient trois sous-éléments : un élément nom et deux éléments profession. Pour sa part, l'élément nom possède également deux sous-éléments : prénom et nomfamille .
L'élément personne est appelé le parent de l'élément nom et des deux éléments profession. L'élément nom est le parent des éléments prénom et nomfamille. L'élément nom et les deux éléments profession sont appelés de même niveau les uns par rapport aux autres. Les éléments prénom et nomfamille sont également frères.
N'importe quel parent peut avoir de nombreux enfants. XML associe à chaque enfant un seul parent. Un élément enfant doit être complètement inclus (emboîté) dans un élément parent ; si une balise de début d'un élément est à l'intérieur du même élément, alors sa balise de fin doit être également à l'intérieur de cet élément.

Chaque document XML possède un élément racine (et un seul) sans parent. Cet élément racine correspond au document traité. Il est également quelque fois appelé « élément document ». C'est le premier élément du document qui contient tous les autres éléments.
Tout document bien formé possède une seule racine. Dès lors que les éléments ne se chevauchent pas et que tous les éléments, à l'exception de la racine, possèdent un parent, les documents XML représentent une structure de données sous forme d'un arbre.
Dans l'exemple précédent, les contenus des éléments prénom, nomfamille et profession sont des données textuelles : du texte qui ne contient aucune balise. Les contenus des éléments personne et nom sont uniquement des sous-élements.
Cette différence entre les éléments qui contiennent seulement des données textuelles et les éléments qui contiennent seulement des sous-éléments est fréquente dans les documents de données. Toutefois, XML peut être employé sous une forme plus libre, comme dans des documents narratifs, en intégrant dans un même élément, à la fois d'autres sous-éléments ainsi que des données textuelles.

L'élément définition contient à la fois des données textuelles et le sous-élément Nota. Cet élément possède un « contenu mixte ».
Les éléments XML peuvent avoir des attributs. Un attribut est une paire nom-valeur associée à la balise de début de l'élément. Les noms sont séparés des valeurs par un signe égal et d'éventuels blancs optionnels. Les valeurs sont entourées par des apostrophes ou des guillemets. Les paires nom-valeur sont séparées des autres par au moins un espace. L'ordre des attributs n'a aucune importance tant qu'ils sont bien saisis avant le signe « > ».
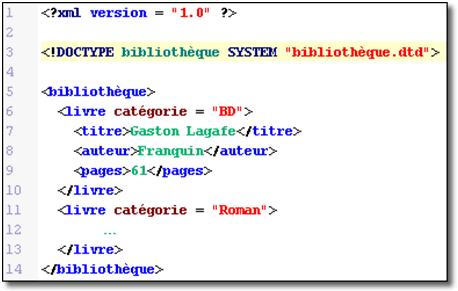
L'exemple ci-dessus montre l'attribut catégorie associé à l'élément livre, ce qui permet d'identifier le type de document stocker dans la bibliothèque, le premier livre étant une BD.


Les deux écritures proposées ci-dessus sont exactement identiques pour un parseur XML (programme annexe de validation d'un document XML). La deuxième écriture propose des apostrophes au lieu des guillemets et positionne des blancs supplémentaires autour du signe égal. Le blanc autour du signe égal est une contrainte purement esthétique et personnelle. On utilise fréquemment les guillemets pour entourer les valeurs des attributs, toutefois, les apostrophes peuvent être utiles dans le cas où la valeur de l'attribut contient elle-même des guillemets.

Cet exemple nous montre une autre structure et donc une autre possibilité de représentation du document personne avec une utilisation intensive des attributs.
Cet exemple soulève la question de savoir quand, et qui, doit utiliser des sous-éléments ou des attributs pour contenir l'information. Malheureusement, il n'existe aucune réponse simple, et différentes personnes peuvent avancer des arguments tout à fait valables en faveur de l'une ou de l'autre de ces deux options.
Dans l'exemple ci-dessus, l'utilisation systématique des attributs paraît être une démarche excessive, notamment pour l'élément profession où le choix du nom de l'attribut pose un problème. Puisque le nom de l'attribut est valeur, autant placer directement cette valeur à l'intérieur de l'élément profession.

Cette dernière version paraît être un bon compromis. Toutefois, c'est à vous de voir se qui vous semble le plus adapté à une situation donnée. Tout dépend du type de document à composer.
Les noms d'éléments et les autres noms XML peuvent contenir n'importe quel caractère alphanumérique. Ces caractères comprennent les lettres standard de A à Z et de a à z, aussi bien que les chiffres de 0 à 9. les noms XML peuvent également intégrer des lettres, chiffres et caractères non standard comme ?, ç, £, O. Ils peuvent également contenir ces trois caractères de ponctuation :
Les noms XML ne doivent pas contenir d'autres caractères de ponctuation, comme les points d'interrogation, les apostrophes, les signes dollar, les signes d'élévation à la puissance, les symboles de pourcentage et les points-virgules. Le caractère deux points est autorisé, mais il est réservé pour une utilisation avec les espaces de noms.

Les noms XML ne doivent pas comporter d'espace, de tabulation ni de retour à la ligne. Les noms XML doivent commencer seulement par des lettres, des symboles, ou le caractère souligné. Ils ne doivent pas débuter par un nombre, un trait d'union, ou un point. Il n'y a pas de limite pour la longueur du nom d'un élément ou de n'importe quel autre nom XML.
Un caractère utilisé dans un élément ne doit pas contenir de chevron ouvrant « < » non échappé. Ce caractère est toujours assimilé au début d'une balise. Si vous avez besoin d'utiliser ce caractère dans votre texte, vous pouvez l'échapper en utilisant l'appel d'entité. Quand un parseur lit le document, il remplace l'appel d'entité < ; par le caractère « < ». Toutefois, il ne confond pas < ; avec le début d'une balise.
Les données textuelles ne doivent pas non plus contenir de caractère & non échappé. Ce caractère est toujours interprété comme le début d'une référence d'entité ou la référence d'un caractère. Cependant, l'esperluette peut être échappée en utilisant l'appel d'entité & ;
XML définit exactement cinq types d'appels d'entité :
Seuls < ; et & ; doivent être employés en lieu et place des vrais caractères dans le contenu d'un élément. Les autres sont optionnels. " ; et &apos ; sont utiles dans les valeurs des attributs, où et pourrait être mal interprétés comme une fin de valeur d'un attribut.
Les sections CDATA (sections de caractères bruts) permettent de définir des zones qui contiennent uniquement des caractères bruts, et qui ne doivent donc pas être traitées comme du code XML. Ainsi, le caractère inférieur à n'indique plus le début d'une balise, et l'esperluette n'indique pas le début d'une référence d'entité. Dans ce contexte, il est possible d'inclure, dans ces sections, des portions de code XML ou HTML.

L'identificateur de début d'une section CDATA est :
<![CDATA[
L'identificateur de fin d'une portion CDATA est :
]]>
Tout ce qui est compris entre <![CDATA[ et ]]> est traité comme des données textuelles brutes sans interprétation particulière de la par du parseur XML.
Chaque document XML légitime, sans exception, doit être bien formé. Cela signifie qu'il respecte un certain nombre de règles (non exhaustive) comme :

