Tous les traitements possibles avec les chaînes
Tous les traitements possibles avec les chaînes
 Après avoir vu comment formater des nombres et des dates afin de produire des messages adaptés à pas mal de situations, nous allons passer cette fois-ci un peu plus de temps sur le texte et sur tous les autres types de traitements qui s'y rattachent. Effectivement, la plupart des programmes manipulent du texte d'une manière ou d'une autre, aussi la plate-forme Java définit-elle un certain nombre de classes importantes pour représenter, formater, et parcourir du texte.
Après avoir vu comment formater des nombres et des dates afin de produire des messages adaptés à pas mal de situations, nous allons passer cette fois-ci un peu plus de temps sur le texte et sur tous les autres types de traitements qui s'y rattachent. Effectivement, la plupart des programmes manipulent du texte d'une manière ou d'une autre, aussi la plate-forme Java définit-elle un certain nombre de classes importantes pour représenter, formater, et parcourir du texte.
La représentation du texte se fait principalement au travers de la classe String que nous connaissons déjà. Nous allons toutefois y revenir pour décrire bien plus précisément l'ensemble des méthodes qui la constitue.
Toujours au travers de cette classe String, le formatage va nous permettre d'associer des variables d'une autre nature (des entiers, en hexadécimal ou pas, des réels, en représentation flottante ou pas, etc. ) avec une chaîne de caractères qui sert de canevas. A ce sujet, nous travaillerons également avec la classe Scanner qui réalise du formatage automatique avec des chaînes de caractères. Nous profiterons également de revoir tous les problèmes de conversion entre les chaînes de caractères avec les types primitifs, avec donc un retour sur les classes enveloppes, comme Integer, Double, etc.
Pour terminer sur cette introduction, nous avons souvent besoin d'analyser des textes afin de contrôler si un certain motif est respecter dans la chaîne de caractères. Nous allons donc travailler sur ce que nous appelons les expressions régulières qui gèrent des motifs correspondant à des critères d'évaluation.
Les chaînes de caractères correspondent à un type de données fondamental et couramment utilisé. En java, cependant, les chaînes de caractères ne correspondent pas à un type primitif, à la différence de char, int ou double. En lieu et place, les chaînes de caractères sont représentées par la classe java.lang.String qui définit de nombreuses méthodes pour la manipulation des chaînes de caractères. Les objets String sont immuables : une fois qu'un objet String a été créé, il n'existe aucune possibilité de modifier la chaîne de caractères qu'il représente. Ainsi, chaque méthode qui agit sur une chaîne de caractères retourne généralement un nouvel objet String qui contient la chaîne de caractères modifiée.
Un certain nombre de méthodes manipulent des objets String et renvoient un nouvel objet String comme résultat. Même si cela est utile, vous devez savoir qu'en créant beaucoup de chaînes de caractères de cette manière, les performances de l'application peuvent être affectées. Si vous désirez que votre application soit plus performante en proposant beaucoup de manipulation sur la même chaîne de caractères, préférez plutôt la classe StringBuilder que nous traiterons dans le prochain chapitre.
| java.lang.String | ||
|---|---|---|
| Méthodes | Retour | Explication |
| charAt(int index) | char | Récupère un caractère particulier dans la chaîne dont la position est précisée en argument. |
| codePointAt(int index) | int | Renvoie le point de code qui démarre ou se termine à l'emplacement spécifié. |
| codePointCount(int début, int fin) | int | Renvoie le nombre de points de code entre début et fin-1. Les substitutions sans paires sont considérées comme des points de code. |
| compareTo(String autreChaîne) compareToIgnoreCase(String autreChaîne) |
int | Compare la chaîne avec une autre chaîne passée en argument. Possibilité de ne pas tenir compte de la casse des caractères avec la deuxième méthode. |
| concat(String autreChaîne) | String | Concatène la chaine avec une autre. |
| endWith(String suffixe) | boolean | Vérifie si la chaîne de caractère se termine par le suffixe précisé en argument. |
| equals(String autreChaîne) equalsIgnoreCase(String autreChaîne) |
Object | Compare la chaîne à une autre en ne tenant pas compte de la casse des caractères éventuellement. |
| format(String format, Object ... args) | String | Méthode statique qui permet de formater un texte, en relations avec les arguments proposés, dans un motif défini à la manière de la fonction printf() du C++. |
| indexOf(String sousChaîne) indexOf(int car) indexOf(String sousChaîne, int décalage) indexOf(int car, int décalage) |
int | Cherche la première occurence d'un caractère ou d'une partie de la chaîne. |
| intern() | String | Cherche et renvoie une instance unique de la chaîne dans l'ensemble des chaînes partagées. |
| lastIndexOf(String sousChaîne) lastIndexOf(int car) lastIndexOf(String sousChaîne, int index) lastIndexOf(int car, int index) |
int | Cherche la dernière occurence d'un caractère ou d'une sous-chaîne. |
| length() | int | Renvoie la longueur de la chaîne. |
| match(String motif) | boolean | Evalue que la chaîne de caractères correspond au critère spécifié par le motif proposé exprimé sous la forme d'expression régulière. |
| offsetByteCodePoints(int début, int pointCode) | int | Renvoie l'indice du point de code d'où pointe pointCode, depuis le point de code jusqu'à début. |
| replace(char ancien, char nouveau) | String | Remplace toutes les occurences d'un caractère dans une chaîne par un autre caractère. |
| replaceAll(String motif, String remplacement) replaceFirst(String motif, String remplacement) |
String | Remplace toutes les occurences ou la première partie de la chaîne de caractère avec la chaîne de remplacement spécifiée en argument à partir d'un motif défini par une expression régulière. |
| split(String motif) | String[] | Décompose la chaîne en un tableau de chaînes en utilisant comme séparateur un élément d'expression régulière. |
| startWith(String prefixe) | boolean | Vérifie si la chaîne débute par un prefixe. |
| subString(int début) subString(int début, int fin) |
String | Retourne une partie de la chaîne. Attention, le caractère indicé par début est pris en compte, alors que le caractère correspondant à fin ne l'est pas ; fin représente la limite supérieure exclusive. |
| toLowerCase() | String | Convertit la chaîne en minuscule. |
| toUpperCase() | String | Convertit la chaîne en majuscule. |
| trim() | String | Supprime les espaces blancs de début et de fin de chaîne. |
| valueOf(Type valeur) | String | Renvoie une chaîne de caractères correspondant à la valeur numérique passée en paramètre de la méthode. Type = int, long, double, float, Object, char[], char, boolean. |
Dans ce chapitre, nous allons nous consacrer uniquement sur les méthodes de bases. Nous verrons par la suite comment travailler avec les valeurs numériques, comment formater de telles valeurs, comment récupérer des valeurs quelconques à partir de la classe Scanner, et surtout comment travailler avec les expressions régulières, puisqu'il s'agit d'un sujet important. Tous ces autres points seront, bien entendus traités, mais dans les prochains chapitres.
Si vous désirez créer un objet String à partir d'un message spécifique, il suffit de placer ce dernier entre guillemets. Lorsque vous déclarez un objet de type String sans préciser de valeur, votre objet n'est pas initialisé. Il faudra le faire par la suite. Rappelez-vous d'ailleurs que comme tout autre objet, le nom de l'objet correspond en réalité à un pointeur vers l'objet réel où sont placées toutes ses valeurs internes. Pour terminer, un texte exprimé entre guillemets dans votre code est finalement considéré comme un objet de type String.
String message = "Mon texte personnel"; // déclaration et initialisation de l'objet message String texte; // déclaration de l'objet texte sans être initialisé System.out.println(texte); // erreur de compilation texte = "Autre message"; // initialisation de l'objet texte System.out.println(message); // affichage de message System.out.println(texte); // affichage de texte
Comme toujours, les tableaux Java étant de vrais objets qui connaissent leur propre taille, les objets String n'ont pas besoin de caractère de terminaison. Pour connaître la taille d'un objet String, utilisez pour cela sa méthode length().
String message = "Mon texte personnel"; int longueur = message.length(); // longueur = 19 longueur = "Autre message".length(); // longueur = 13
La chaîne de caractères représentées par le texte entre guillemets, comme nous l'avons dit plus haut, est considéré comme un objet de type String. A ce titre, vous avez donc le droit de solliciter toutes les méthodes que vous désirez à partir de ce texte, comme ici avec la méthode length().
Il est possible de juxtaposer plusieurs chaînes, les unes à la suite des autres, ce que nous appelons une concaténation de chaînes. Il existe la méthode concat() qui réalise ce type d'opération. Egalement, l'opérateur + a été redéfini pour concaténer deux objets String ou un objet String avec une valeur d'un autre type, produisant en sortie un nouvel objet String. Pour finir, nous pouvons également travailler avec l'opérateur += pour concaténer deux chaînes. Dans ce cas là, le contenu de la première chaîne est modifié.
public class Principal { public static void main(String[] args) { String message = " le moment"; String texte = "C'est".concat(message); String s = texte +" d'intégrer le nombre réel "+12.89; s += " dans ce message"; String autre = "C'est"+message.concat(" d'intégrer le nombre réel ")+12.89; System.out.println(s); System.out.println(autre); } }
C'est le moment d'intégrer le nombre réel 12.89 dans ce message
C'est le moment d'intégrer le nombre réel 12.89
Soyez conscient que chaque fois qu'une concaténation de chaînes de caractères est réalisée et que le résultat est enregistré dans une variable ou passé à une méthode, un nouvel objet String doit être créé. Dans certaines circonstances, cela peut s'avérer très peu efficace et dégrader les performances.
Les chaînes littérales (entre guillemets) ne peuvent occuper plusieurs lignes sur le code source, mais il est possible de les concaténer pour obtenir le même résultat :
String grandMessage = "Voici un grand message qui doit " + "s'écrire sur plusieurs lignes. Je suis obligé d'utiliser " + "l'opérateur + pour cela";
La méthode charAt() de la classe String permet de récupérer un seul caractère de la chaîne. Vous devez spécifier sa position dans la chaîne au travers du paramètre de la méthode :
S
a
l
u
t
public class Principal { public static void main(String[] args) { String bonjour = "Salut"; for (int i=0; i<bonjour.length(); i++) System.out.println(bonjour.charAt(i)); } }
La classe String propose plusieurs méthodes simples permettant de retrouver des parties de la chaîne. Les méthodes startsWith() et endsWith() comparent un argument avec le début et la fin de la chaîne. Il est possible de récupérer une partie de la chaîne à l'aide de la méthode substring(). Par contre, cette méthode réclame, d'une part où débute la sous-chaîne et d'autre part où elle se termine, ceci au travers d'indices numériques que vous spécifiez dans les arguments. A propos d'indice, il est possible également de délivrer l'emplacement d'un caractère ou d'une partie de la chaîne à partir de la méthode indexOf(). Cette méthode recherche la première occurence. Par contre, la méthode lastIndexOf() fait la même chose, mais à partir de la dernière occurence.
Nom du site : unsite
public class Principal { public static void main(String[] args) { String url = "http://www.unsite.fr/"; if (url.startsWith("http://") && url.endsWith("fr/")) { int début = url.indexOf('.')+1; int fin = url.lastIndexOf("."); String site = "Nom du site : "+ url.substring(début, fin); System.out.println(site); } } }
La méthode trim() est très utile pour supprimer tous les espaces blancs aux deux extrémités d'une chaîne de caractères (c'est-à-dire les caractères retour chariot, nouvelle ligne, tabulation et tout simplement les espaces). Par ailleurs, les méthodes toUpperCase() et toLowerCase() renvoient un nouvel objet String qui est, soit tout en majuscules, soit tout en minuscules.
En majuscules : BONJOUR À TOUT LE MONDE
En minuscules : bonjour à tout le monde
public class Principal { public static void main(String[] args) { String bienvenue = " Bonjour à tout le monde "; bienvenue = bienvenue.trim(); System.out.println("En majuscules : "+bienvenue.toUpperCase()); System.out.println("En minuscules : "+bienvenue.toLowerCase()); } }
Puisque les chaînes de caractères sont des objets plutôt que des valeurs primitives, elles ne peuvent généralement pas être comparées directement avec l'opérateur d'égalité ==. Si nous le faisons, == compare des références et peut déterminer si deux expressions pointent vers une même référence de chaîne de caractères. Par contre, cet opérateur d'égalité ne peut pas déterminer si deux chaînes de caractères distinctes contiennent le même texte.
Bonjour
false
import java.util.Scanner; public class Principal { public static void main(String[] args) { Scanner clavier = new Scanner(System.in); String message = "Bonjour"; String saisie = clavier.next(); System.out.println(message==saisie); } }
Pour tester l'égalité de deux chaînes de caractères, utilisez plutôt la méthode equals(). Il est possible également d'utiliser la méthode equalsIgnoreCase() en lieu et place de la méthode equals() si vous désirez ne pas tenir compte de la casse des caractères.
Bonjour
true
true
import java.util.Scanner; public class Principal { public static void main(String[] args) { Scanner clavier = new Scanner(System.in); String message = "Bonjour"; String saisie = clavier.next(); System.out.println(message.equals(saisie)); System.out.println("BONJOUR".equalsIgnoreCase(saisie)); } }
Bien que méconnue, intern() est une méthode importante de la classe String. Cette méthode retourne une nouvelle chaîne de caractères avec la garantie que la nouvelle chaîne possède le même contenu. En réalité, intern() retourne toujours une référence vers le même objet String. Autrement dit, si s et t sont deux objets String tels que s.equals(t), alors :
s.intern() == t.intern()
Cela signifie que la méthode intern() permet de réaliser des comparaisons de chaînes rapides en utilisant ==. Plus important encore, les littéraux chaînes sont toujours internés par la JVM Java de façon implicites, de sorte que si vous prévoyez de comparer une chaîne s avec un certain nombre de littéraux de chaînes, vous devriez interner s puis effectuer la comparaison avec ==.
Bonjour
true
true
true
false
import java.util.Scanner; public class Principal { public static void main(String[] args) { Scanner clavier = new Scanner(System.in); String message = "Bonjour"; String bienvenue = "Bonjour"; String saisie = clavier.next(); System.out.println(message==bienvenue); System.out.println("Bonjour"==bienvenue); System.out.println(message.equals(saisie)); System.out.println(saisie=="Bonjour"); } }
La méthode compareTo() permet de comparer la valeur lexicale d'un String à un autre String. Elle renvoie un entier strictement inférieur, égal ou strictement supérieur à 0. compareToIgnoreCase() fait la même chose, mais sans tenir compte de la casse des caractères.
true
true
true
public class Principal { public static void main(String[] args) { String abc = "abc"; String def = "def"; String num = "123"; System.out.println(abc.compareTo(def)<0); System.out.println(abc.compareTo("abc")==0); System.out.println(abc.compareTo(num)>0); } }
Les chaînes Java sont implémentées sous forme de suites de valeurs char. Comme nous l'avons vu, le type char est une unité de code permettant de représenter des points de code Unicode en codage UTF-16. Les caractères Unicode les plus souvent utilisés peuvent être représentés par une seule unité de code. Les caractères complémentaires exigent, quant à eux, une paire d'unité de code.
String chaîne = "Bonjour";
int longueur = chaîne.length(); // longueur vaut 7
int pointsCode = chaîne.codePointCount(0, chaîne.length());
char premier = chaîne.charAt(0); // le premier est 'B'
char dernier = chaîne.charAt(6); // le premier est 'r'
int index = chaîne.offsetByCodePoints(0, n);
int dernier = chaîne.codePointAt(index);
Etant donné que les objets String sont immuables, vous ne pouvez pas manipuler les caractères d'un objet String de manière directe. Si vous avez besoin d'objets modifiables, utilisez plutôt java.lang.StringBuilder.
| java.lang.StringBuilder | ||
|---|---|---|
| Méthodes | Retour | Explication |
| append(...) | StringBuilder | Ajoute à la chaîne déjà existante une autre chaîne, un caractère, une valeur numérique, un objet, etc. |
| charAt(int index) | char | Récupère un caractère particulier dans la chaîne dont la position est précisée en argument. |
| delete(int début, int fin) |
StringBuider | Enlève les caractères de la chaîne dans la limite spécifiée en argument. |
| deleteCharAt(int index) | StringBuilder | Enlève un seul caractère. |
| indexOf(String sousChaîne) indexOf(String sousChaîne, int décalage) |
int | Cherche la première occurence d'une partie de la chaîne. |
| insert(int index, ...) | StringBuilder | Insère à la chaîne déjà existante une autre chaîne, un caractère, une valeur numérique, un objet, etc. à l'emplacement spécifié par index. |
| lastIndexOf(String sousChaîne) lastIndexOf(String sousChaîne, int index) |
int | Cherche la dernière occurence d'une partie de la chaîne. |
| length() | int | Renvoie la longueur de la chaîne. |
| replace(int début, int fin, String nouvelle) | StringBuilder | Remplace une partie de la chaîne |
| reverse() |
StringBuilder | Inverse la chaîne. |
| setCharAt(int index, char ch) | Remplace dans la chaîne le caractère spécifié par rapport à l'indice proposé. | |
| setLenght(int taille) | Impose une nouvelle taille de la chaîne. | |
| subString(int début) subString(int début, int fin) |
String | Retourne une partie de la chaîne. Attention, le caractère indicé par début est pris en compte, alors que le caractère correspondant à fin ne l'est pas ; fin représente la limite supérieure exclusive. |
| toString() | String | Récupération de la chaîne de caractère en format String. |
public class Principal { public static void main(String[] args) { StringBuilder b = new StringBuilder("N'est"); // Création du tampon de chaîne avec la valeur "N'est" char car = b.charAt(0); // Retourne N b.setCharAt(0, 'C'); // changer un caractère : "C'est" : on ne peut pas faire cela avec un objet String b.append(' '); // ajoute un espace à la fin de la chaîne "C'est " b.append("Le moment."); // ajoute une chaine à la fin "C'est le moment." b.append(23); // ajoute un entier ou une valeur quelconque "C'est le moment.23" b.insert(6, "pas "); // insère une chaîne de caractère "C'est pas le moment.23" b.replace(2, 9, "est "); // remplace une partie de la chaîne "C'est le moment.23" b.delete(15, 18); // supprime une partie de la chaîne "C'est le moment" b.deleteCharAt(2); // supprime le troisème caractère "C'st le moment" b.setLength(5); // Tronque la chaîne pour aboutir à la taille désirée "C'st " b.reverse(); // Inverse les caractères " ts'C" String s = b.substring(1, 2); // extrait une partie de chaîne "t" s = b.toString(); // reconversion vers une chaîne immuable. System.out.println(s); System.out.println(b); // fait automatiquement appel à la méthode toString() de StringBuilder b.setLength(0); // écrase le tampon ; il est désormais prêt à être réutilisé } }
ts'C
ts'C
Comme vous le savez, les caractères individuels sont représentés en Java par le type primitif char. La plate-forme Java possède également une classe Character qui définit des méthodes de classe pour contrôler le type d'un caractère ou pour modifier la casse d'un caractère.
| java.lang.Character | ||
|---|---|---|
| Méthodes | Retour | Explication |
| static getNumericValue(char ch) | int | Retourne la valeur entière correspondante au chiffre exprimé dans le caractère. Prend donc en compte uniquement les caractères suivants : de '0' à '9'. |
| static isDigit(char ch) | boolean | Teste si le caractère représente un chiffre. |
| static isLetter(char ch) | boolean | Teste si le caractère représente une lettre. |
| static isLetterOrDigit(char ch) | boolean | Teste si le caractère représente une lettre ou un chiffre (pas de symbole de ponctuation). |
| static isLowerCase(char ch) | boolean | Teste si le caractère est en minuscule. |
| static isSpaceChar(char ch) | boolean | Teste si le caractère est le caractère espace. |
| static isUpperCase(char ch) | boolean | Teste si le caractère est en majuscule. |
| static isWhiteSpace(char ch) | String | Cherche et renvoie une instance unique de la chaîne dans l'ensemble des chaînes partagées. |
| static toLowerCase(char ch) | int | Renvoie le caractère en minuscule. |
| static toUpperCase(char ch) | int | Renvoie le caractère en majuscule. |
public class Principal { public static void main(String[] args) { char lettre = 'A'; char chiffre = '7'; char accent = 'é'; char espace = ' '; char blanc = '\n'; System.out.println(Character.getNumericValue(chiffre)); // 7 System.out.println(Character.isDigit(lettre)); // false System.out.println(Character.isDigit(chiffre)); // true System.out.println(Character.isLetter(lettre)); // true System.out.println(Character.isLetter(chiffre)); // false System.out.println(Character.isLetter(accent)); // true System.out.println(Character.isLetterOrDigit(chiffre)); // true System.out.println(Character.isLowerCase(lettre)); // false System.out.println(Character.isSpaceChar(lettre)); // false System.out.println(Character.isSpaceChar(espace)); // true System.out.println(Character.isUpperCase(lettre)); // true System.out.println(Character.isWhitespace(lettre)); // false System.out.println(Character.isWhitespace(blanc)); // true } }
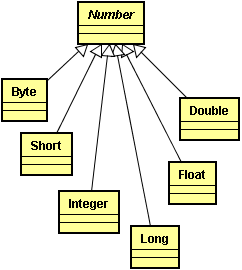 Il est parfois nécessaire de convertir un type primitif - comme int - en un objet. Tous les types primitifs ont une contrepartie sous forme de classe. Par exemple, il existe une classe Integer correspondant au type primitif int. Une classe de cette catégorie est généralement appelée classe enveloppe (object wrapper). Les classes enveloppes portent des noms correspondant aux types : Integer, Long, Float, Short, Byte, Character, Void et Boolean (les six premières héritent de la super classe Number). Les classes enveloppes sont inaltérables : vous ne pouvez pas modifier une valeur enveloppée, une fois l'enveloppe construite. Elles sont aussi final, vous ne pouvez donc pas en faire des sous-classes.
Il est parfois nécessaire de convertir un type primitif - comme int - en un objet. Tous les types primitifs ont une contrepartie sous forme de classe. Par exemple, il existe une classe Integer correspondant au type primitif int. Une classe de cette catégorie est généralement appelée classe enveloppe (object wrapper). Les classes enveloppes portent des noms correspondant aux types : Integer, Long, Float, Short, Byte, Character, Void et Boolean (les six premières héritent de la super classe Number). Les classes enveloppes sont inaltérables : vous ne pouvez pas modifier une valeur enveloppée, une fois l'enveloppe construite. Elles sont aussi final, vous ne pouvez donc pas en faire des sous-classes.
Supposons que nous voulions travailler sur une liste d'entiers. Nous pensons, tout de suite, utiliser la collection ArrayList<int>. Malheureusement, le paramètre de type entre les signes <> ne peut pas être un type primitif, c'est obligatoirement un objet. C'est à ce niveau là que la classe enveloppe devient intéressante. Vous pouvez ainsi déclarer une liste de tableau d'objet Integer :
ArrayList<Integer> liste = new ArrayList<Integer>() ;
Attention : un ArrayList<Integer> est bien moins efficace qu'un tableau int[] car chaque valeur est enveloppée séparément dans un objet. Vous ne devriez utiliser cette construction que pour les petites collections lorsque la commodité du programmeur est plus importante que l'efficacité.
Une autre innovation du JDK 5.0 facilite l'ajout et la récupération d'éléments de tableau. L'appel :
liste.add(3);
est automatiquement traduit en :
liste.add(new Integer(3));
Cette conversion est appelée autoboxing.
A l'inverse, lorsque vous attribuez un objet Integer à une valeur int, il est automatiquement déballé (unboxing). En fait, le compilateur traduit :
int n = liste.get(i) ;
en
int n = liste.get(i).intValue() ;
Les opérations d'autoboxing et d'unboxing fonctionne même avec les expressions arithmétiques. Vous pouvez, par exemple, appliquer l'opération d'incrémentation en une référence d'enveloppe :
Integer n = 3;
n++ ;
Le compilateur insère automatiquement des instructions pour déballer l'objet, augmenter la valeur du résultat et le remballer.
Dans la plupart des cas, vous avez l'illusion que les types primitifs et leurs enveloppes ne sont qu'un seul et même élément. Ils ne diffèrent considérablement qu'en un seul point : l'identité.
Vous verrez souvent les enveloppes de nombres pour une autre raison. Les concepteurs Java ont découvert que les enveloppes constituent un endroit pratique pour y stocker certaines méthodes de base, comme celles qui permettent de convertir des chaînes de chiffres en nombres.
Pour transformer une chaîne en entier, vous devez utiliser l'instruction suivante :
int x = Integer.parseInt(s) ;
Ceci n'a rien à voir avec les objets Integer ; parseInt() est une méthode statique. Mais la classe Integer constitue un bon endroit pour l'y placer. Pour transformer un entier en une chaîne représentant la suite des chiffres du nombre entier, utilisez la méthode toString() :
String chiffres = Integer.toString(324) ; // chiffres <-- "324"
Voici un exemple :
| Test.java |
|---|
package test; import java.util.Scanner; import static java.lang.System.*; public class Test { public static void main(String[] args) { Scanner clavier = new Scanner(in); out.print("Introduisez votre nombre entier : "); String chaîne = clavier.next(); Integer X = new Integer(chaîne) ; int x = X; // ou plus rapidement : int x = clavier.nextInt(); out.println("Valeur entière : "+x); out.println("Chaîne de caractère équivalente : "+X); // équivalent à Integer.toString(x); out.println("Valeur binaire correspondante : "+Integer.toBinaryString(x)); } } |
Vous avez ci-dessous, les tableaux montrant toutes les méthodes utiles sur les entiers et les réels dont les deux classes enveloppes Integer et Double sont les principales représentantes.
| java.lang.Integer | ||
|---|---|---|
| Attributs | ||
| static final int MAX_VALUE | Valeur maximale que peut représenter un nombre entier : 231-1. | |
| static final int MIN_VALUE | Valeur minimale que peut représenter un nombre entier : -231. | |
| Méthodes | ||
| Integer(int valeur) | Construit la classe enveloppe correspondante à partir de l'entier passé en argument. | |
| Integer(String valeur) | Construit la classe enveloppe correspondante à partir d'une chaîne de caractères représentant la suite des chiffres du nombre entier. | |
| static int bitcount(int valeur) | Retourne le nombre de bit à 1 dans la représentation binaire en complément à deux de la valeur entière spécifiée en argument de la méthode. | |
| int compareTo(Integer autre) | Compare la valeur numérique entre deux objets de type Integer. Si la valeur retournée est positive, cela signifie que la valeur numérique de l'objet est supérieur à la valeur numérique de l'objet passé en argument. Une valeur négative est retournée dans le cas contraire. Enfin, si les deux objets possèdent la même valeur numérique, c'est la valeur nulle qui est renvoyée. | |
| static Integer decode(String valeur) | Méthode statique qui renvoie un objet de type Integer qui enveloppe la valeur numérique représentée par la suite des chiffres spécifiés dans la chaîne de caractères. Cette méthode gère les représentations octale, décimale ou hexadécimale suivant le préfixe numérique de la chaîne de caractères. |
|
| static int highestOneBit(int valeur) | Méthode statique qui renvoie la valeur entière correspondante au bit 1 le plus à gauche, dans la représentation binaire du nombre entier passé en argument. | |
| static int lowestOneBit(int valeur) | Méthode statique qui renvoie la valeur entière correspondante au bit 1 le plus à droite, dans la représentation binaire du nombre entier passé en argument. | |
| static int numberOfLeadingZeros(int valeur) | Retourne le nombre de zéro, en partant de la gauche, dans la représentation binaire en complément à deux de la valeur entière spécifiée en argument. | |
| static int numberOfTrailingZeros(int valeur) | Retourne le nombre de zéro, en partant de la droite, dans la représentation binaire en complément à deux de la valeur entière spécifiée en argument. | |
| static int parseInt(String valeur) static int parseInt(String valeur, int base) |
Méthode statique qui retourne une valeur entière représentée par la suite des chiffres spécifiés dans la chaîne de caractères donnée en argument. Vous pouvez également précisez une autre base que la base 10. La valeur numérique retournée est en base 10. Elle est alors convertie à partir de la chaîne proposée, exprimée dans la base souhaitée. | |
| static int reverse(int valeur) | Méthode statique qui retourne une valeur entière dont l'ordre des bits est inversé par rapport à l'entier passé en argument. | |
| static int rotateLeft(int valeur, int nombre ) | Méthode statique qui retourne un entier qui a subit une rotation vers la gauche de l'entier valeur de nombre de position. | |
| static int rotateRight(int valeur, int nombre ) | Méthode statique qui retourne un entier qui a subit une rotation vers la droite de l'entier valeur de nombre de position. | |
| static int signum(int valeur) | Renvoie le signe de l'entier sous la forme -1, 0, 1. | |
| static String toBinaryString(int valeur) | Méthode statique qui retourne une chaîne de caractères qui représente une valeur entière en format binaire d'un nombre entier passé en argument. | |
| static String toHexString(int valeur) | Méthode statique qui retourne une chaîne de caractères qui représente une valeur entière en format hexadécimal d'un nombre entier passé en argument. | |
| static String toOctalString(int valeur) | Méthode statique qui retourne une chaîne de caractères qui représente une valeur entière en format octal d'un nombre entier passé en argument. | |
| String toString() | Méthode qui retourne une chaîne de caractère qui est une représentation du nombre entier de l'objet. | |
| static String toString(int valeur, int base) | Méthode statique qui retourne une chaîne de caractères qui représente une valeur entière dont la base est déterminé par base du nombre entier valeur passé en argument. | |
| static Integer valueOf(int valeur) | Méthode statique qui retourne un objet de type Integer correspondant à la valeur entière passée en argument. | |
| static Integer valueOf(String valeur) | Méthode statique qui retourne un objet de type Integer correspondant à la chaîne de caractères passée en argument qui représente une valeur entière. | |
| static Integer valueOf(String valeur, int base) | Même méthode que précédemment. Toutefois, le nombre est représenté dans une base quelconque qu'il s'agit de spécifier au moyen de l'argument base. | |
| java.lang.Double | ||
|---|---|---|
| Attributs | ||
| static final int MAX_VALUE | Valeur maximale que peut représenter un nombre réel : 1.7976931348623157 E308. | |
| static final int MIN_VALUE | Valeur minimale que peut représenter un nombre entier : 4.9 E-324. | |
| static final int NaN | Correspond à une valeur spéciale du type double ne représentant pas un nombre (Not a Number). | |
| static final int POSITIVE_INFINITY | Infini positif. | |
| static final int NEGATIVE_INFINITY | Infini négatif. | |
| Méthodes | ||
| Double(double valeur) | Construit la classe enveloppe correspondante à partir du réel passé en argument. | |
| Double(String valeur) | Construit la classe enveloppe correspondante à partir d'une chaîne de caractères représentant la suite des chiffres du nombre réel. | |
| static int compare(double un, double deux) | Compare la valeur numérique entre deux objets de type double. | |
| static boolean isInfinite(double valeur) | Détermine si la valeur réelle passée en argument est une valeur infinie. | |
| static double parseDouble(String valeur) | Méthode statique qui retourne une valeur réelle représentée par la suite des chiffres spécifiés dans la chaîne de caractères donnée en argument. | |
| static Double valueOf(double valeur) | Méthode statique qui retourne un objet de type Double correspondant à la valeur réelle passée en argument. | |
| static Double valueOf(String valeur) | Méthode statique qui retourne un objet de type Double correspondant à la chaîne de caractères passée en argument qui représente une valeur réelle. | |
public class Principal { public static void main(String[] args) { int nombre = 44; System.out.println("Représentation binaire : "+Integer.toBinaryString(nombre)); System.out.println("Nombre de bit à 1 : "+Integer.bitCount(nombre)); System.out.println("Valeur décimale du bit 1 le plus fort : "+Integer.highestOneBit(nombre)); System.out.println("Valeur décimale du bit 1 le plus faible : "+Integer.lowestOneBit(nombre)); System.out.println("Nombre de bit 0 en partant de la gauche : "+Integer.numberOfLeadingZeros(nombre)); System.out.println("Nombre de bit 0 en partant de la droite : "+Integer.numberOfTrailingZeros(nombre)); System.out.println("Symétrie horizontale du nombre binaire : "+Integer.toBinaryString(Integer.reverse(nombre))); System.out.println("Décalage vers la gauche de 2 unités : "+Integer.toBinaryString(Integer.rotateLeft(nombre, 2))); System.out.println("Représentation hexadécimale : "+Integer.toHexString(nombre)); System.out.println("Représentation octale : "+Integer.toOctalString(nombre)); System.out.println("Signe : "+Integer.signum(nombre)); System.out.println("Valeur décimale du nombre binaire 1101 : "+Integer.valueOf("1101", 2)); } }
Représentation binaire : 101100
Nombre de bit à 1 : 3
Valeur décimale du bit 1 le plus fort : 32
Valeur décimale du bit 1 le plus faible : 4
Nombre de bit 0 en partant de la gauche : 26
Nombre de bit 0 en partant de la droite : 2
Symétrie horizontale du nombre binaire : 110100000000000000000000000000
Décalage vers la gauche de 2 unités : 10110000
Représentation hexadécimale : 2c
Représentation octale : 54
Signe : 1
Valeur décimale du nombre binaire 1101 : 13
if (x == Double.NaN) // n'est jamais vrai
Toutes les valeurs "pas un nombre" sont considérées comme distinctes. Pour cela vous devez employer la méthode isNaN() de la classe enveloppe Double pour réaliser ce genre de test :
if (Double.isNaN(x)) // vérifier si x est "pas un nombre"
Attention : Les nombres à virgule flottante ne conviennent pas aux calculs financiers, dans lesquels les erreurs d'arrondi sont inadmissibles. La commande System.out.println(2.0-1.1) produit 0.899999999999999, et non 0.9 comme vous pourriez le penser. Ces erreurs d'arrondi proviennent u fait que les nombres à virgule flottante sont représentés dans un système de nombres binaires. Il n'existe pas de représentation binaire précise de la fraction 1/10, tout comme il n'existe pas de représentation précise de la fraction 1/3 dans un système décimal. Si vous voulez obtenir des calculs numériques précis sans erreurs d'arrondi, utilisez la classe BigDecimal.
Dans le développement d'applications, nous sommes souvent confrontés devant deux genres de situations classiques. Tout d'abord, nous avons besoin de récupérer une valeur numérique à partir d'une chaîne de caractères saisie au clavier ou venant d'un flux quelconque. Ainsi, une fois que nous avons récupérée la valeur, nous pouvons librement réaliser tous les traitements souhaitables. Ensuite, nous devons souvent afficher ce résultat numérique en association avec du texte.
Ce chapitre va nous aider à y voir plus clair sur ce sujet, sans être toutefois exhaustif puisque les chapitres suivants vont nous aider à aller encore plus loin dans ce domaine.
Comment un programme Java qui agit sur les nombres reçoit-t-il ses valeurs d'entrée ? Souvent, un tel programme lit une représentation textuelle d'un nombre et doit la convertir en une représentation numérique. Comme nous venons juste de la voir dans le chapitre précédent, les diverses sous-classes de Number : Integer, Double, Boolean, etc. définissent des méthodes de conversion très utiles :
public class Principal { public static void main(String[] args) { String s = "-42"; byte b = Byte.parseByte(s); // s sous forme d'octet short sh = Short.parseShort(s); // s sous forme de valeur int i = Integer.parseInt(s); // s sous forme de valeur long l = Long.parseLong(s); // s sous forme de valeur float f = Float.parseFloat(s); // s sous forme de valeur double d = Double.parseDouble(s); // s sous forme de valeur // les routines de conversion entière gère les nombres en diverses bases b = Byte.parseByte("1011", 2); // 1011 en binaire donne b=11 en base 10 sh = Short.parseShort("ff", 16); // ff en base 16 donne sh=255 en base 10 // la méthode valueOf() peut gérer les bases arbitraires i = Integer.valueOf("egg", 17); // Base 17 // la méthode decode() gère les représentation octale, décimale ou // hexadécimale suivant le préfixe numérique de la chaîne de caractères sh = Short.decode("0377"); // un 0 de tête signifie base 8 i = Integer.decode("0xff"); // un 0x de tête signifie base 16 l = Long.decode("255"); // Les autres nombres sont en base 10 } }
double valeur = Double.parseDouble("1 234,56"); // erreur lors de l'analyse du nombre exprimé dans la chaîne de caractères.
Si vous devez travailler avec ce type d'écriture, revoyez l'étude précédente qui nous a montré comment gérer les formats des nombres au niveau international, ou alors consultez les chapitres suivants.Toujours en se servant de ces classes enveloppes, vous avez la possibilité de passer cette fois-ci d'une valeur primitive vers la chaîne de caractères correspondante. Vous pouvez même envisager de contrôler la base du nombre et ainsi d'avoir une représentation très sophistiquée dans la chaîne de caractères :
int nombre = 42; String décimal = Integer.toString(nombre); String binaire = Integer.toBinaryString(nombre); String octal = Integer.toOctalString(nombre); String hexadécimal = Integer.toHexString(nombre); String base36 = Integer.toString(nombre, 36); hexadécimal = Integer.toHexString(nombre).toUpperCase();
Il est possible d'obtenir une représentation sous forme de chaîne de caractères de la plupart des types, grâce à la méthode statique valueOf() de la classe String. Plusieurs versions surchargées de cette méthode donnent des valeurs pour tous les types de base :
String un = String.valueOf(1); String deux = String.valueOf(2.384f); String pasVrai = String.valueOf(false);
Tous les objets Java possèdent une méthode toString() héritée de la classe Object. Pour des références de type classe, valueOf() appelle en réalité la méthode toString() de l'objet pour récupérer sa représentation sous forme de chaîne. Si la référence est égale à null, le résultat est une chaîne "null".
import java.util.Date; public class Principal { public static void main(String[] args) { String aujourdhui = String.valueOf(new Date()); System.out.println("La date d'aujourd'hui est "+aujourdhui); } }
La date d'aujourd'hui est Mon Mar 12 09:52:35 CET 2007
La représentation de la date n'est pas terrible. Encore une fois, reportez-vous sur l'étude précédente pour avoir un formatage de la date qui respecte vos désirs, ou alors consultez les chapîtres suivants.
import java.util.Date; public class Principal { public static void main(String[] args) { // récupérer la chaîne de caractères équivalente et afficher String un = ""+1; String deux = ""+2.384f; String aujourdhui = ""+new Date(); System.out.println(un); System.out.println(deux); System.out.println("La date d'aujourd'hui est "+aujourdhui); // alternatives beaucoup plus souvent utilisées -> Affichage direct System.out.println("Valeur entière : "+1); System.out.println("Valeur réelle : "+2.384f); System.out.println("La date d'aujourd'hui est "+new Date()); } }
1
2.384
La date d'aujourd'hui est Mon Mar 12 10:11:16 CET 2007
Valeur entière : 1
Valeur réelle : 2.384
La date d'aujourd'hui est Mon Mar 12 10:11:16 CET 2007
Une tâche courante lorsque nous travaillons avec du texte en sortie consiste à combiner les valeurs de divers types en un unique bloc de texte lisible par un être humain. Comme nous venons de le découvrir dans le chapitre précédent, une manière d'accomplir cette tâche se base sur les aptitudes de l'opérateur Java de concaténation de chaînes. Cela produit du code ressemblant à ceci :
String utilisateur = "Emmanuel REMY"; int essais = 15; Date date = new Date(); ... System.out.println(utilisateur+" connecté après "+essais+" essais. Dernière connexion le "+date);
Emmanuel REMY connecté après 15 essais. Dernière connexion le lun. mars 12 14:09:45 CET 2007
Depuis Java 5.0, il existe maintenant une alternative plus familière pour les programmeurs C : une méthode printf(). printf est l'abbrévation de print formatted, c'est-à-dire impression formatée, et combine des fonctions d'impression et de formatage en un seul appel. La méthode printf() a été rajoutée aux classes de flux de sortie PrintWriter et PrintStream. Il s'agit d'une méthode qui attend un nombre variable d'arguments. Le premier argument est la chaîne de formatage. Cette dernière spécifie le texte à afficher et inclut typiquement un ou plusieurs spécificateurs de format sous forme de séquences d'échappement commençant par le caractère %. Les arguments restants de printf() sont des valeurs à convertir en chaînes et à substituer aux spécificateurs de format dans la chaîne de formatage. Les spécificateurs de format influencent les types des arguments restants et spécifient de manière exacte comment ils doivent être convertis en chaînes.
La concaténation de chaînes illustrée ci-dessus peut être réécrite de la manière suivante :
String utilisateur = "Emmanuel REMY"; int essais = 15; Date date = new Date(); ... System.out.printf("%s connecté après %d essais. Dernière connexion le %tc%n", utilisateur, essais, date);
Au spécificateur de format %s se substitue simplement une chaîne de caractères. %d indique que l'argument doit être entier. %tc attend un objet Date, Calendar ou un nombre en millisecondes et convertit cette valeur en une représentation textuelle de la date et de l'heure. %n ne réalise aucune conversion : il produit simplement une terminaison de ligne spécifique à la plate-forme, tout comme la méthode println().
Les conversions réalisées par printf() sont toutes proprement localisées. Ainsi, les heures et les dates sont affichées avec une ponctuation adaptée aux paramètres de localisation. De même, si vous souhaitez qu'un nombre soit affiché avec un séparateur de milliers, la ponctuation sera également spécifique aux paramètres de localisation (un espace en France, une virgule aux USA, etc).
Outre la méthode printf() de base, les classes PrintWriter et PrintStream définissent aussi une méthode synonyme nommée format() : elle accepte exactement les mêmes arguments et se comporte de la même manière. La classe String possède également une méthode format(). Cette méthode statique String.format() se comporte comme la méthode PrintWriter.format(), à la différence près qu'elle retourne la chaîne de caractères plutôt que de l'envoyer dans un flux.
Chaque spécificateur de format commence donc par un signe pourcentage et se termine par un type de conversion d'un ou de deux caractères, lequel spécifie la plupart des détails relatifs à la conversion et à l'affichage. Entre ces deux éléments se trouvent les drapeaux facultatifs qui fournissent d'autres détails de formatage. La syntaxe générale d'un spécificateur de format est la suivante. Les parenthèses carrées indiquent les éléments facultatifs :
%[argument][drapeaux][largeur][.précision]type
Nous allons décrire chacun des éléments qui composent le spécificateur de format. Nous commençons tout d'abord par le type.
| type de Conversion | ||
|---|---|---|
| d | Formate l'argument sous forme d'entier en base 10. L'argument doit être d'un type entier compatible | 159 |
| x, X | Formate l'argument sous forme d'entier en base 16 (hexadécimal). Représentation en majuscule pour le type X. | 9F |
| o | Formate l'argument sous forme d'entier en base 8 (octal). | 237 |
| f | Formate l'argument sous forme de nombre à virgule flottante en base 10, sans utiliser la notation exponentielle. | 15.9 |
| e, E | Formate l'argument sous forme de nombre à virgule flottante en base 10, en utilisant la notation exponentielle. Représentation en majuscule pour le type E. | 1.59e+01 |
| g, G | Virgule flottante générale (le plus court entre e et f). Représentation en majuscule pour le type G. | |
| a | Formate l'argument en utilisant un format à virgule flottante hexadécimal. | 0x1.FCCDp3 |
| s, S | Chaîne de caractères (en majuscule pour S) | Salut |
| c, C | Caractère (en majuscule pour C) | S |
| b, B | Valeur booléenne ( en majuscule pour B) | true |
| t ou T | Date et heure (en majuscule pour T) - 2 lettres, la deuxième indique comment exécuter le formatage | (voir plus loin) |
| % | Symbole de pourcentage | % |
| n | Séparateur de ligne en fonction de la plateforme | |
Voici un exemple simple qui permet de découvrir le résultat suivant le type de conversion souhaité :
int entier = 30; double réel = 124.78; char lettre = 'a'; boolean test = false; String message = "bonjour"; String motif = "Entier : %d%nEntier : %X%nRéel : %f%nRéel : %e%nRéel : %g%nLettre : %C%nTest : %B%nMessage : %S"; System.out.printf(motif, entier, entier, réel, réel, réel, lettre, test, message);
Entier : 30 Entier : 1E Réel : 124,780000 Réel : 1.247800e+02 Réel : 124.780 Lettre : A Test : FALSE Message : BONJOUR
Tout spécificateur de format au sein d'une chaîne de formatage (à l'exception de %% et de %n) nécessite un argument contenant la valeur à formater. Ces arguments suivent la chaîne de formatage dans l'invocation de format() ou de printf(). Par défaut, un spécificateur de format utilise le prochain argument non utilisé. Ainsi, dans l'invocation de printf() suivante, les premier et deuxième spécificateurs de format %s formatent respectivement le deuxième et troisième argument de la méthode :
String nom = "Rémy"; String prénom = "Emmanuel"; System.out.printf("Nom : %s %s%n", prénom, nom); // Affichage -> Nom : Emmanuel Rémy
Si un spécificateur de format inclut le caractère < après le symbole %, il indique que l'argument du spécificateur de format précédent doit être réutilisé. Cela permet à un même élément d'être formaté à plusieurs reprises (cette technique sera généralement utilisée pour le formatage des dates).
En reprenant l'exemple ci-dessus, voici ce que nous pouvons faire :
String nom = "Rémy"; String prénom = "Emmanuel"; System.out.printf("Nom : %s %s. Bonjour Mr %<S%n", prénom, nom); // Affichage -> Nom : Emmanuel Rémy. Bonjour Mr RÉMY
En reprenant le mélange des différents types, voici comment changer le code pour que le nombre des arguments soit réellement plus faible :
int entier = 30; double réel = 124.78; char lettre = 'a'; boolean test = false; String message = "bonjour"; String motif = "Entier : %d%nEntier : %<X%nRéel : %f%nRéel : %<e%nRéel : %<g%nLettre : %C%nTest : %B%nMessage : %S"; System.out.printf(motif, entier, réel, lettre, test, message);
Entier : 30 Entier : 1E Réel : 124,780000 Réel : 1.247800e+02 Réel : 124.780 Lettre : A Test : FALSE Message : BONJOUR
La position des arguments peut aussi être spécifiée de façon absolue. Si le signe % est suivi par un ou plusieurs chiffres, puis par le signe $, ces chiffres spécifient une position d'argument. Par exemple, %1$d indique que le premier argument suivant la chaîne de formatage doit être formaté sous forme de nombre entier.
En reprenant encore une fois l'exemple du dessus, voici ce que nous pouvons faire :
String nom = "Rémy"; String prénom = "Emmanuel"; System.out.printf("Nom : %s %s. Bonjour Mr %1$S%n", nom, prénom); // Affichage -> Nom : Rémy Emmanuel. Bonjour Mr RÉMY
A la suite du spécificateur d'argument facultatif, un spécificateur de format peut inclure un ou plusieurs drapeaux.
| drapeaux | ||
|---|---|---|
| + |
Ce drapeau indique que les données de sortie numériques doivent toujours inclure un signe : une valeur non négative sera donc préfixée avec un +. | +3333.33 |
| espace | Un espace blanc représente un drapeau (un peu difficile à déceler, il est vrai) indique que les valeurs non négatives doivent être préfixées avec un espace. Ce drapeau s'avère particulièrement utile pour aligner nombres positifs et négatifs dans une colonne. | | 3333.33| |
| 0 | Le chiffre 0 utilisé sous forme de drapeau indique que les valeurs numériques doivent être remplies à gauche (après le signe, s'il y en a un) avec des zéros. Ce drapeau ne peut être utilisé que si une largeur est spécifiée, et jamais en conjonction avec le drapeau -. | 003333.33 |
| - | Un tiret indique que la valeur formatée doit être justifiée à gauche au sein de la largeur spécifiée. Lorsqu'une largeur est spécifiée sans ce drapeau, la chaîne formatée doit être remplie à gauche afin de produire une justification à droite. | |3333.33| |
| ( | Ce drapeau indique que les nombres négatifs doivent être produits entre parenthèses, comme c'est la norme avec les rapports financiers. | -(3333.33) |
| , | Ce drapeau indique que les nombres doivent être formatés en utilisant le séparateur spécifique aux paramètres de localisation. Par exemple, la France utilise l'espace comme séparateur de milliers, alors que les USA utilisent une virgule. | 3 333,33 |
| # (pour format f) | Inclut toujours une décimale. | 3,333 |
| # (pour format x ou o) | Ajoute le préfixe 0x ou 0. | 0xcafe |
L'exemple ci-dessous exploite quelques drapeaux :
int positif = 2345; int négatif = - 4567; double réel = 8; String motif = "% ,d%n% ,d%n%1$#x%n%#f"; System.out.printf(motif, positif, négatif, réel);
2 345 -4 567 0x929 8,000000
La largeur d'un spécificateur de format se compose d'une ou plusieurs positions spécifiant le nombre minimal de caractères à produire. Si la valeur formatée est moins large que la largeur spécifiée, elle est remplie à gauche avec des espaces blancs (par défaut), produisant ainsi une valeur justifiée à droite. Les drapeaux - et 0 peuvent être utilisés afin de spécifier une justification à gauche ou pour réaliser un remplissage de zéros.
Voici un exemple qui met en oeuvre la justification à droite avec la gestion de la largeur :
String nom = "Rémy"; String prénom = "Emmanuel"; int essais = 15; System.out.printf("Nom : %13s%nPrénom : %10s%nEssais : %10d", nom, prénom, essais);
Nom : Rémy Prénom : Emmanuel Essais : 15
La précision d'un spécificateur de format se compose d'une ou plusieurs positions suivant le point décimal. La signification de ce nombre dépend du type de formatage avec lequel elle est utilisée :
Voici un exemple qui permet de placer des réels sur une colonne avec une justification à droite, une notation typiquement française et pour finir avec 2 chiffres significatifs après la virgule :
for (double x : new double[] {34.6, 6745.7865, 0.3425, 12345}) System.out.printf("%,15.2f%n", x);
34,60
6 745,79
0,34
12 345,00
En reprenant un des exemples proposés plus haut, voici ce que nous pouvons faire en prenant en compte toutes les techniques que nous venons d'évoquer, savoir : les spécificateurs d'argument, les drapeaux, la largeur et la précision.
int positif = 2345; int négatif = - 4567; double réel = 84532; String motif = "%,10d%n%,10d%n%1$0#10x%n%,13.2f"; System.out.printf(motif, positif, négatif, réel);
2 345
-4 567
0x00000929
84 532,00
Après avoir recenser toutes les techniques de formatage de valeurs de différentes natures, nous allons nous consacrer uniquement au formatage des nombres. Ceci dit, la plupart des exemples proposés exploitent déjà largement ce type de valeur. Nous allons donc exploiter un petit exemple qui est souvent utile dans la représentation des nombres réels, comme la justification à droite et la prise en compte d'un certain nombre de chiffres après la virgule. Il s'agit de la conversion entre les €uros et les francs :
Valeur en €uro ? 169000 169 000,00 €uros 1 108 597,75 Francs
import java.text.ChoiceFormat; import static java.lang.System.*; import java.util.Scanner; public class Principal { public static void main(String[] args) { Scanner clavier = new Scanner(in); out.println("valeur en €uro ?"); double €uro = clavier.nextDouble(); affiche("€uro", €uro); affiche("Franc", €uro*6.55975); } public static void affiche(String monnaie, double valeur) { ChoiceFormat pluriel = new ChoiceFormat("0#|1#s"); out.printf("%,12.2f %s%s%n", valeur, monnaie, pluriel.format(valeur)); } }
Nous avons vu que la concaténation, ou l'appel à la méthode valueOf(), de la classe String permettent d'intégrer des objets dans une chaîne de caractères. Dans ce cas là, c'est la méthode toString() qui est automatiquement sollicitée. Toutefois, la méthode toString() de la classe Date produit bien une représentation textuelle d'une date et d'une heure, mais ne réalise aucune localisation et ne permet pas de personnaliser les champs (par exemple, jour, mois, année, heures et minutes) à afficher. Cette méthode toString() ne devrait être utilisée que pour produire une heure lisible par une machine, pas par une chaîne lisible par un être humain.
Tout comme les nombres, les dates et les heures peuvent être converties en chaînes de caractères en utilisant les méthodes format() ou printf() suivant le cas. Les chaînes de formatage pour l'affichage des dates et des heures se composent de séquences de deux caractères commençant par la lettre t. La seconde lettre de chaque séquence spécifie le ou les champs de la date et de l'heure à afficher. Ainsi, %tR affiche les champs heures et minutes en utilisant un format sur 24 heures, alors que %tD affiche les champs jour, mois et année séparés par des slashs. La méthode String.format() sait formater une date ou une heure spécifiée en tant que valeur long, Date ou Calendar.
| Date et heure | ||
|---|---|---|
| tc |
Date et heure complètes | ven. févr. 17 17:40:05 CET 2006 |
| tF | Date au format ISO 8601 | 2006-02-17 |
| tD | Date au format américain | 02/17/06 |
| tT | Heure sur 24 heures | 17:43:57 |
| tr | heure sur 12 heures | 05:44:37 PM |
| tR | Heure sur 24 heures sans secondes | 17:45 |
| tY | Année sur quatre chiffres (avec zéros préalables, le cas échéant) | 2006 |
| ty | Deux derniers chiffres de l'année (avec zéro préalable, le cas échéant) | 06 |
| tC | Deux premiers chiffres de l'année (avec zéro préalable, le cas échéant) | 20 |
| tB | Nom complet du mois | février |
| tb ou th | Nom du mois abrégé | févr. |
| tm | Mois sur deux chiffres (avec zéro préalable le cas échéant) | 02 |
| td | Jour sur deux chiffres (avec zéro préalable, le cas échéant) | 17 |
| te | Jour sur deux chiffres. | 9 |
| tA | Jour de la semaine complet | vendredi |
| ta | Jour de la semaine abrégé | ven. |
| tj | Jour de l'année sur trois chiffres (avec zéros préalables, le cas échéant), entre 001 et 366. | 048 |
| tH | Heure sur deux chiffres (avec zéro préalable, le cas échéant) , entre 00 et 23 | 21 |
| tk | Heure sur deux chiffres (sans zéro préalable, le cas échéant) entre 0 et 23 | 8 |
| tI | Heure sur deux chiffres (avec zéro préalable, le cas échéant) entre 01 et 12 | 09 |
| tl | Heure sur deux chiffres (sans zéro préalable) , entre 1 et 12 | 9 |
| tM | Minutes sur deux chiffres (avec zéro préalable, le cas échéant) | 06 |
| tS | Secondes sur deux chiffres (avec zéro préalable, le cas échéant) | 09 |
| tL | Millième de seconde, sur trois chiffres (avec zéros préalables, le cas échéant) | 921 |
| tN | Nanosecondes sur neuf chiffres (avec zéros préalables, le cas échéant) | 656000000 |
| tP | Indicateur du matin ou de l'après midi en majuscules | PM |
| tp | Indicateur du matin ou de l'après midi en minuscule | pm |
| tz | Décalage numérique RFC 822 du GMT | +0100 |
| tZ | Fuseau horaire | CET |
| ts | Secondes depuis le 1970-01-01 00:00:00 GMT | 1140209926 |
| tE | Millièmes de seconde depuis le 1970-01-01 00:00:00 GMT | 1140209926047 |
Voici un petit exemple qui donne des solutions pour l'affichage des dates et des heures :
import java.util.Date; public class Principal { public static void main(String[] args) { long maintenant = System.currentTimeMillis(); Date date = new Date(maintenant); System.out.printf("Heure : %tR%n", maintenant); System.out.printf("Date : %tD%n", date); // Attention, date au format américain System.out.printf("Aujourd'hui, nous sommes le %tA %<te %<tB %<tY", new Date()); } }
Heure : 15:09
Date : 03/13/07
Aujourd'hui, nous sommes le mardi 13 mars 2007
Vous remarquez dans cet exemple que l'affichage de la date au complet est un peu long. Par ailleurs, la localisation n'est pas gérée. Il peut être plus judicieux de prendre plutôt les formatages de date soit par la classe DateFormat, soit par la classe MessageFormat, sur lesquelles nous avons déjà travaillés dans l'étude précédente.
import java.text.*; import java.util.Date; public class Principal { public static void main(String[] args) { Date date = new Date(); // première solution System.out.println("Heure : "+DateFormat.getTimeInstance(DateFormat.SHORT).format(date)); System.out.println("Date : "+DateFormat.getDateInstance(DateFormat.SHORT).format(date)); System.out.println("Actuellement, nous sommes le "+DateFormat.getDateInstance(DateFormat.FULL).format(date)); // deuxième solution String motif = "Heure : {0, time, short}\nDate : {0, date, short}\nActuellement, nous sommes le {0, date, full}"; System.out.println(MessageFormat.format(motif, date)); } }
Heure : 15:29
Date : 13/03/07
Actuellement, nous sommes le mardi 13 mars 2007
Heure : 15:29
Date : 13/03/07
Actuellement, nous sommes le mardi 13 mars 2007
Une expression régulière décrit un motif dans le texte. Par motif, nous entendons tout élément que vous pouvez identifier dans le texte à partir de simples caractères qui ont un sens particulier dans l'interprétation qui en est faite. Ceci couvre des éléments comme les mots, les groupes de mots, les lignes de paragraphes, la ponctuation, la casse et plus généralement, les chaînes de caractères et les nombres structurés de manière particulière, comme les numéros de téléphone, les adresse mail, etc.
Avec les expressions régulières, vous pouvez chercher dans le dictionnaire tous les mots contenant un q sans son alter ego u juste à côté, ou les mots commençant et finissant par la même lettre. Une fois le motif construit, des outils simples permettent de chasser dans le texte ou de vérifier si une chaîne donnée lui correspond. Une expression régulière peut également vous aider à démembrer des parties spécifiques du texte, puis être utilisée comme texte de remplacement.
Lorsque vous construisez un motif, vous devez spécifier précisément la suite des caractères qui constituera une concordance autorisée. Il existe une syntaxe spéciale à utiliser pour décrire un motif.
Voici un exemple simple d'expression régulière :
[Jj]ava.+
L'expression régulière précédente correspond à n'importe quelle chaîne de caractères ayant la forme suivante :
Par exemple, la chaîne "javanais" correspond à cette expression, à la différence de la chaîne "le monde de Java".
La méthode la plus simple de la classe String acceptant un argument sous forme d'expression régulière s'appelle matches() ; elle retourne la valeur true si la chaîne de caractères correspond au motif défini par l'expression régulière spécifiée.
true
false
String motif = "[Jj]ava.+"; String premier = "javanais"; String deuxième = "le monde de Java"; System.out.println(premier.matches(motif)); System.out.println(deuxième.matches(motif));
Outre les mises en correspondance, nous pouvons utiliser les expressions régulières lors d'opérations de type chercher/remplacer. Les méthodes replaceFirst() et replaceAll() de la classe String cherche dans une chaîne de caractères respectivement la première occurence de la sous-chaîne recherchée, ou l'ensemble des sous-chaînes correspondant à un motif donné, avant de les remplacer par le texte alternatif spécifié, et de retourner enfin une nouvelle chaîne de caractères contenant les remplacements.
Javanais
le monde de JAVA
String motif = "[Jj]ava"; String premier = "javanais"; String deuxième = "le monde de Java"; System.out.println(premier.replaceAll(motif, "Java")); System.out.println(deuxième.replaceFirst(motif, "JAVA"));
L'autre méthode de la classe String utilisant les expressions régulières s'appelle split(). Elle retourne un tableau contenant les sous-chaînes d'une chaîne de caractères, séparées par des délimiteurs correspondant au motif spécifié.
Par exemple, pour obtenir un tableau contenant les mots d'une chaîne de caractères séparés par un nombre quelconque d'espaces ou de saut de lignes, utiliser le motif suivant [ \t\n\r] :
String phrase = "Voici une phrase\tavec une deuxième colonne\net une ligne en plus"; System.out.println(phrase); String[] mots = phrase.split("[ \t\n\r]"); for (String mot : mots) System.out.println(mot);
Voici une phrase avec une deuxième colonne et une ligne en plus Voici une phrase avec une deuxième colonne et une ligne en plus
Les méthodes matches(), replaceFirst(), replaceAll() et split() conviennent lorsque vous n'utilisez une expression régulière qu'une seule fois. Si vous souhaitez utiliser une expression régulière pour des mises en correspondance multiples, vous devez utiliser explicitement les classes Pattern et Matcher du paquetage java.util.regex.
En premier lieu, créez un objet Pattern représentant votre expression régulière à l'aide de la méthode statique compile(). A partir de là, vous devez créer un objet de type Matcher qui procure un certain nombre de méthodes équivalente à celles que nous avons découvert au travers de la classe String. Toutefois, cette classe Matcher offre la capacité supplémentaire de vous délivrer toutes les sous-chaînes correspondant au motif souhaité. Deux méthodes de Matcher me paraissent intéressantes pour répondre à ce critère particulier :
<gras>
</gras>
String phrase = "<gras>Agissez</gras>, au lieu de parler"; Matcher correspondance = Pattern.compile("</?.*?>").matcher(phrase); while (correspondance.find()) System.out.println(correspondance.group());
Nous avons décelé un petit peu l'utilité des expressions régulières. Il maintenant temps de voir la syntaxe à respecter pour optenir le résultat souhaité. Nous allons donc recenser, sans être toutefois exhaustif, la plupart des éléments qui constitue une expression régulière.
Notez que beaucoup d'éléments d'une expression régulière incluent le caractère antislash (\) qui permet ainsi de proposer une syntaxe raccourcie. Par exemple, \d indique qu'il s'agit d'un caractère représentant un chiffre compris entre 0 et 9. Toutefois, les chaînes de caractères Java utilisent également l'antislash pour exprimer ses propres caractères spéciaux, qui ont ainsi une influence particulière sur la gestion même de la chaîne, comme le font par exemple \n, \t, \r, etc. Pour éviter le conflit entre ces deux types d'interprétation, vous devez doubler les caractères antislashs sur les éléments qui correspondent à un motif particulier de l'expression régulière. En reprenant l'élément de l'expression régulière évoqué dans cette rubrique, voici donc ce que nous devons écrire : "\\d".
String code = "1234\t3456\t3214"; System.out.println(code); for (String valeur : code.split("\t")) if (valeur.matches("\\d{4}")) System.out.println(Integer.parseInt(valeur)); // résultats -------------------------------------------- 1234 3456 3214
1234
3456
3214
Le programme ci dessus permet de récupérer des nombres entiers qui sont constitués exactement de 4 chiffres.
.
Remarquez bien, que dans ce programme, \t (tabulation) agit tout simplement comme un caractère de contrôle dans une chaîne de caractères classique. Il est donc considéré comme un autre caractère puisqu'il agit également sur l'affichage, alors que \\d est un caractère spécifique interprété de façon particulière dans l'expression régulière. Pour résumer, dans un cas, vous devez utiliser qu'un seul antislah, dans l'autre cas vous en mettez deux, chacun ayant son propre rôle.
Il peut arriver, pour certains caractères qui ont normalement une interprétation particulière dans les expressions régulières, que vous souhaitiez les utiliser, cette fois-ci, de façon classique (de manière littérale). C'est le cas notamment pour les caractères ., *, +, les accolades {} et les parenthèses ( ) (leurs interprétations seront spécifiées par la suite). Pour que vous puissiez donc les utiliser de manière littérale, placez un antislash devant ce caractère. Ainsi, avec la séquence \., vous désirez tout simplement prendre en compte le point dans votre chaîne de caractères sans qu'il soit interprété par l'expression régulière.
La forme la plus simple d'une expression régulière est du texte plein, littéral, dont la signification correspond exactement à ce texte. Cela peut être un simple caractère ou plus. Généralement, ce type d'expression ne présente pas beaucoup d'intérêt, puisque dans ce cas de figure, il suffit de faire un test d'égalité entre deux chaînes sans passer par le système d'expression régulière.
Il existe quand même un cas où cela peut être intéressant, c'est lorsque nous utilisons la méthode split(). Effectivement, dans ce cas de figure, nous imposons souvent un séparateur bien spécifique :
String message = "Le monde de java est-il parfait ?"; for (String souschaine : message.split(" java ")) System.out.println(souschaine); Résultats -------------------------------------------------- Le monde de
est-il parfait ?
Le programme ci-dessus permet de récupérer un début et une fin de chaîne. Le début correspond à tout ce qui se trouve avant " java ", et la fin à tout, ce qui se trouve après.
Toutefois, la plupart du temps, nous avons besoin de plus de souplesse. Plutôt que de demander impérativement un caractère spécifique, vous pouvez solliciter un ensemble de caractères qui correspond à un critère. Dans ce cas là, nous mettons en oeuvre ce que nous appelons une classe de caractères. Nous avons la possiblité de définir nos propres classes de carcatères, toutefois un certain nombre de classessont déjà prédéfinies :
String phrase = "Une phrase\tavec une {deuxième} colonne\net une (ligne) en plus\tet des chiffres 453267"; System.out.println(phrase); String[] mots = phrase.split("\\s"); for (String mot : mots) { if (mot.matches(".*\\W.*")) System.out.println("Récupérer mot avec symboles : "+mot); if (mot.matches(".*\\d.*")) System.out.println("Récupérer nombres : "+mot); } Résultats ----------------------------------------------------------------------------------- Une phrase avec une {deuxième} colonne et une (ligne) en plus et des chiffres 453267 Récupérer mot avec symboles : {deuxième} Récupérer mot avec symboles : (ligne) Récupérer nombres : 453267
Vous pouvez définir vos propres classes de caractères. Une classe de caractères personnalisée est un jeu de caractères alternatifs, entourés de crochets. Voici quelques exemples qu'il est possible de réaliser :
String phrase = "Une phrase\tavec une {deuxième} colonne\net une (ligne) en plus\tet des chiffres 453267"; System.out.println(phrase); String[] mots = phrase.split("\\s"); for (String mot : mots) if (mot.matches("[a-z&&[^np]]*")) System.out.println(mot); Résultats ---------------------------------------- Une phrase avec une {deuxième} colonne et une (ligne) en plus et des chiffres 453267 avec et et des chiffres
Il existe des caractères de position qui vous permettent de préciser la position relative d'une correspondance. Cette démarche est intéressante lorsque nous avons plusieurs occurences possibles par rapport aux critères de recherche spécifiés. Ainsi le motif ".ose" trouve trois correspondances dans la phrase suivante :
La rose n'est pas de couleur rose. C'est quand même la question qu'on se pose.
Voici comment préciser une correspondance particulière :
String première = "Le monde de java est-il parfait ?"; String deuxième = "Le javanais est-elle une langue intéressante ?"; if(première.matches(".*\\bjava\\b.*")) System.out.println("Première valide"); if(deuxième.matches(".*\\bjava\\b.*")) System.out.println("Deuxième valide"); Résultats ---------------------------------- Première valide
L'exemple ci-dessus permet de connaître si une phrase possède le mot java. C'est la première chaîne de caractères qui correspond à ce critère.
.
Mettre en correspondance de simples motifs de caractères fixes ne nous mène généralement pas bien loin. Dans les exemples que je propose d'ailleurs, il n'y en a pas. Nous allons maintenant examiner les opérateurs permettant de compter le nombre d'occurence d'un caractère ou d'un motif.
String code = "1234 3456 3214 0045 0008"; System.out.println(code); for (String valeur : code.split("\\s")) if (valeur.matches("0+\\d+")) System.out.println(Integer.parseInt(valeur)); Résultats ---------------------------------------------- 1234 3456 3214 0045 0008
45
8
String code = "12/04 29-12 18 02 01?01 1008"; System.out.println(code); for (String valeur : code.split("\\s")) if (valeur.matches("\\d\\d/?\\d\\d")) System.out.println(valeur); Résultats ----------------------------------------- 12/04 29-12 18 02 01?01 1008
12/04
1008
String code = "12/04 29-12 18 02 01?01 1008"; System.out.println(code); for (String valeur : code.split("\\s")) if (valeur.matches("\\d{2}/?\\d{2}")) System.out.println(valeur); Résultats ----------------------------------------- 12/04 29-12 18 02 01?01 1008
12/04
1008
String phrase = "Voici une phrase\tavec une deuxième colonne\net une ligne en plus"; System.out.println(phrase); String[] mots = phrase.split("\\s"); for (String mot : mots) if (mot.matches("\\w{4,6}")) System.out.println(mot); Résultats ----------------------------------------- Voici une phrase avec une deuxième colonne et une ligne en plus Voici phrase avec ligne plus
String phrase = "Voici une phrase\tavec une deuxième colonne\net une ligne en plus"; System.out.println(phrase); String[] mots = phrase.split("\\s"); for (String mot : mots) if (mot.matches("\\w{4,}")) System.out.println(mot); Résultats ----------------------------------------- Voici une phrase avec une deuxième colonne et une ligne en plus Voici phrase avec colonne ligne plus
Comme dans des opérations logiques ou mathématiques, les parenthèses peuvent être utilisées dans les expressions régulières, pour créer des expressions secondaires ou pour fixer des limites à une exception. Cette possibilité permet d'étendre l'usage des opérateurs que nous venons de voir aux mots et autres expressions régulières. Le motif "(4\\d){2,}" permet de prendre en compte uniquement les nombres qui sont structurés systématiquement avec le chiffre 4 suivi d'un autre chiffre et ceci au moins deux fois dans le nombre concerné :
String phrase = "4345 3467 4940 453344 484341 4234"; System.out.println(phrase); String[] nombres = phrase.split(" "); for (String nombre : nombres) if (nombre.matches("(4\\d){2,}")) System.out.println(Integer.parseInt(nombre)); Résultats ----------------------------- 4345 3467 4940 3324 3841 4234
4345
4940 484341
Ici, nous appliquons {2,} (2 ou plus) sur le motif 4\\d, et non pas à un seul caractère.
.
En utilisant les regroupements, nous pouvons commencer à bâtir des expressions plus complexes. Par exemple, même si la plupart des adresses mail sont structurées en trois parties (par exemple, machin@bidule.fr), un nom de domaine peut comporter un nombre arbitraire d'éléments séparés par des points. Pour gérer ce phénomène correctement, nous pouvons utiliser une expression comme celle-ci :
\\w+@\\w+(\.\\w)+ // correspond à toute adresse mail
Cette expression correspond à un mot, suivi d'un symbole @, suivi d'un autre mot, puis d'un ou plusieurs mots séparés par des points, par exemple pat@pat.net, bob@truc.bidule.fr ou autre@truc.bidule.co.uk
En plus des opérations de regroupement de base, les parenthèses jouent un autre rôle important : le texte correspondant à chaque sous-expression peut être récupéré séparément. Ce qui veut dire que vous pouvez isoler le texte correspondant à chaque sous-expression. Il existe alors une syntaxe spéciale permettant, à l'intérieur de l'expression régulière, de se référer à chaque groupe de capture par un nombre. Cette fonctionnalité importante peut être utilisée dans deux cas.
Vous voyer le \\1 dans cette expression ? c'est une référence au premier groupe de capture de l'expression \\w. Les références à des groupes de capture sont de la forme \\n où n est le numéro du groupe de capture, en comptant de gauche à droite. Dans cet exemple, le premier groupe de capture correspond à un caractère en début de mot. Il est alors précisé que cette lettre peut être suivie par n'importe quel nombre de lettres jusqu'à la référence spéciale \\1 (également suivi par une borne de mot). Le \\1 signifie "la valeur doit correspondre au groupe de capture 1". Comme ces caractères doivent être les mêmes, ce motif identifie les mots commençant et finissant par la même lettre.
String phrase = "Les JavaBeans ainsi que JavaScript sont souvent utilisées"; String nouvelle = phrase.replaceAll("\\bJava([A-Z]\\w+)", "J$1"); System.out.println(phrase); System.out.println(nouvelle); Résultats ---------------------------------------------- Les JavaBeans ainsi que JavaScript sont souvent utiliséesL'exemple ci-dessus permet de chercher les mots comme JavaBean, JavaScript, JavaOs et JavaVM (mais pas Java ou Javanaise), et remplace ensuite le préfixe Java de ces mots par la lettre J sans altérer le suffixe (correspondant au groupe de capture). Vous remarquez dans ce cas là, que le signe dollar ($) sert de séparateur entre la lettre (ou le mot) à prendre en compte et l'indice du sous-groupe dans l'expression régulière.
Les JBeans ainsi que JScript sont souvent utilisées
Bien entendu, les groupes de capture peuvent contenir plus d'un caractère, et vous pouvez utiliser autant de groupes que vous voulez.
.
Les groupes de capture sont numérotés à partir de 1 et de gauche à droite, en comptant le nombre de parenthèses ouvrantes qui les précèdent. Le nombre spécial 0 fait toujours référence au résultat global de l'expression régulière. Considérons, par exemple, l'expression ci-dessous :
un ((deux) (trois (quatre)))
Elle fournit les résultats suivants :
Groupe 0 : un deux trois quatre
Groupe 1 : deux trois quatre
Groupe 2 : deux
Groupe 3 : trois quatre
Groupe 4 : quatre
Plus tôt dans ce chapitre, nous avons découvert la méthode group() de la classe Matcher, qui sans argument, propose la sous-chaîne correspondant à la recherche effectuée sur un motif sans prise en compte de groupe de capture. Il existe une deuxième méthode group() de cette classe Matcher, qui possède un agument entier. Cette méthode est alors capable de récupérer la sous-chaîne correspondant, cette fois-ci au groupe souhaité. Pour cela, votre motif doit mettre en oeuvre des groupes de captures, et lors de l'appel de la méthode, vous spécifiez le numéro du groupe qui vous intéresse. En voici un exemple :
Texte global : 10h53mn
Heures et minutes : 10h53
Heures uniquement : 10
Minutes uniquement : 53
String phrase = "10h53mn"; String motif = "(([1-2]?[0-9])h([0-5][0-9]))mn"; Matcher correspondance = Pattern.compile(motif).matcher(phrase); if (correspondance.find()) { System.out.println("Texte global : "+correspondance.group(0)); System.out.println("Heures et minutes : "+correspondance.group(1)); System.out.println("Heures uniquement : "+correspondance.group(2)); System.out.println("Minutes uniquement : "+correspondance.group(3)); }
La barre verticale (|) signale l'opérateur logique "ou", également appelé permutation ou choix. L'opérateur | n'agit pas sur les caractères individuels mais sur ce qui les entoure. Il décompose l'expression en deux. Par exemple, nous pourrions analyser une date comme suit :
\\w+, \\d{2} \\w+ \\d{4}|\\d{2}/\\d{2}/\\d{4}
Dans cette expression, la partie gauche correspond à des dates du type : (lundi, 19 mars 2007), et celle de droite à des dates de type (19/03/2007).
L'expression régulière suivante permet de trouver les adresses mail de trois domaines (net, edu, et gouv) :
\\w+@[\\w\.]*\.(net|edu|gouv)
Plusieurs options spéciales permettent de modifier le fonctionnement d'une expression régulière. Pour cela, il faut utiliser la syntaxe suivante (?x) où x est l'option que vous souhaitez activer. En général, ceci est fait en début d'expression régulière. Vous pouvez également désactiver des options en rajoutant un signe moins (?-x), ce qui vous permet de n'appliquer les options qu'à certaines parties de votre motif. Les options suivantes sont disponibles :
String phrase = "Les JavaBeans sont souvent utilisées, le javanais un peu moins."; for (String mot : phrase.split(" ")) if (mot.matches("(?i)java(\\w+)")) System.out.println(mot); Résultats ------------------------------------------ JavaBeans
javanais
Faisons une petite expérience. Supposons que nous voulions identifier toutes les balises XML pour, par exemple, les supprimer par la suite. Nous pourrions donc proposer le motif suivant :
</?.*> // cherche <, éventuellement /, et tous les caractères avant >
Faisons un petit programme qui permet de valider ce motif :
String phrase = "<gras>Agissez</gras>, au lieu de parler"; Matcher correspondance = Pattern.compile("</?.*>").matcher(phrase); while (correspondance.find()) System.out.println(correspondance.group()); Résultat ---------------------------------- <gras>Agissez</gras>
Malheureusement, le résultat ne correspond pas à notre attente. pour quelle raison ? Le problème est que l'opérateur .*, comme tous les opérateurs d'itération d'ailleurs, sont par défaut "gourmand", et ingurgitent tout ce qu'ils peuvent, jusqu'à ce qu'ils atteignent la dernière occurence du caractère de fin.
Pour résoudre ce problème, nous pouvons prendre un opérateur réluctant. En effet, chaque opérateur d'itération peut être utilisé sous une forme alternative, plus économe et qui se contente du minimum de caractères possible, tout en continuant à examiner les caractères qui suivent. Les opérateurs réluctants sont identiques à l'opérateur standard suivi d'un (?), comme *?, +?, {x}?, {x,}?, {x,y}?.
En reprenant notre exemple, voici ce que nous pourrions faire :
</?.*?> // cherche <, éventuellement /, le minimum de caractères, puis >
Testons le :
String phrase = "<gras>Agissez</gras>, au lieu de parler"; Matcher correspondance = Pattern.compile("</?.*?>").matcher(phrase); while (correspondance.find()) System.out.println(correspondance.group()); Résultats ---------------------------------- <gras> </gras>
Dans de toutes petites applications, il est quelque fois utile de prévoir un simple fichier qui sert de base de données rudimentaire. Dans ce cas là, il est nécessaire de prévoir des délimitations particulières pour stocker les informations prévues. Ces délimitations sont bien utiles pour permettre par la suite de reconnaître chacune des données élémentaires.
Si nous faisons une petite application qui doit consulter ce type de fichier, nous obtenons pour chaque ligne de texte, une longue chaîne de caractères qu'il va falloir découper en sous-chaînes distinctes afin de récupérer chacun des champs utiles. Cela implique de repérer les délimiteurs (|) puis de procéder au découpage en séquences de caractères allant jusqu'aux délimiteurs suivants (ces éléments ainsi obtenus sont appelés des tokens).
StringTokenizer découpe = new StringTokenizer(ligne, "|");
Il est également possible de spécifier plusieurs délimiteurs dans la chaîne, par exemple :
StringTokenizer découpe = new StringTokenizer(ligne, "|,;");
Ainsi, tout caractère de chaîne peut servir de délimiteur.
Si vous ne spécifiez pas de jeu de délimiteurs, le paramètre par défaut est " \t\n\r", à savoir tous les caractères d'espace vide (espace, tabulation, nouvelle ligne et retour chariot).
Une fois l'analyseur lexical construit, ses méthodes vont permettre d'extraire efficacement les portions de la chaîne. La méthode nextTocken() renvoie la portion suivante se trouvant encore dans la chaîne. La méthode hasMoreTokens() renvoie true s'il reste encore des portions de chaîne. Enfin la méthode countTockens() renvoie le nombre de portions de chaîne présentes encore dans la chaîne globale.
package délimiteurs; import java.util.*; public class Délimiteurs { public static void main(String[] args) { Scanner clavier = new Scanner(System.in); System.out.println("Insérer votre chaîne avec délimiteur | pour en récupérer les portions"); System.out.println(); String chaîne = clavier.nextLine(); System.out.println(); StringTokenizer analyseur = new StringTokenizer(chaîne, "|"); System.out.println("Nombre de parties : "+analyseur.countTokens()); while (analyseur.hasMoreTokens()) System.out.println(analyseur.nextToken()); } }
Insérer votre chaîne avec délimiteur | pour en récupérer les portions
Voici mon texte|avec un certain|nombre de délimiteurs|à bientôt
Nombre de parties : 4
Voici mon texte
avec un certain
nombre de délimiteurs
à bientôt
Nous avons déjà largement utilisé la classe Scanner, notamment dans la gestion des flux d'entrée de texte. Nous l'avons également utilisée pour récupérer toutes les saisies issues du clavier. En réalité, la classe Scanner est une classe beaucoup plus polyvalente. Elle tire profit des expressions régulières que nous venons d'étudier. Avant tout, sa spécialité, c'est la décomposition de texte. Certe, cette classe Scanner peut prendre en entrée des textes venant d'un fichier ou d'un flux quelconque, mais également et tout simplement des chaînes de caractères, et c'est là que ça devient intéressant.
Un objet Scanner peut décomposer le texte qu'il reçoit en entrée en occurences séparées par un espace blanc ou par tout autre caractère de délimitation ou expression régulière. Scanner définit aussi une variété de méthodes utilitaires pour analyser les occurences sous forme de valeur booléenne, entières ou à virgule flottante, avec une analyse syntaxique des nombres prenant en compte les paramètres de localisation. Elle possède des méthodes skip() pour éviter les occurences correspondant à un motif spécifié, ainsi que des méthodes permettant de chercher vers l'avant des occurences correspondante à un motif spécifié.
La classe Scanner n'analyse pas seulement des littéraux entiers ou réels. Elle sait aussi reconnaître les séparateurs de milliers ainsi que le séparateur de la partie décimale conformément au pays concerné. Dans le cas de la France, nous pouvons donc avoir en entrée la valeur suivante : 1 234,45.
| java.util.Scanner | ||
|---|---|---|
| Méthodes | Retour | Explication |
| Scanner(InputStream flux) | Construit un objet Scanner à partir du flux d'entrée. Le flux est alors interprété sous forme de flux de texte. Toutefois, cette classe est capable de décomposer du texte en élément. Ces éléments peuvent être de différentes natures. Ainsi par exemple, il est possible de récupérer une suite de caractères représentant une valeur entière directement transformée dans le type int. | |
| Scanner(String text) | Construit un objet Scanner à partir cette fois-ci d'une chaîne de caractères qui sera alors possible de décomposer en éléments de nature différente. | |
| findInLine(String motif) findInLine(Pattern motif) |
String | Cherche, dans la ligne courante, du texte semblable à l'expression régulière spécifiée. Si une correspondance est trouvée, le Scanner avance jusqu'au texte et le retourne. |
| hasNext() | boolean | Retourne true si un mot est présent dans la ligne courante. En réalité, Scanner découpe la chaîne de caractères d'entrée en plusieurs morceaux. Une série d'espaces blancs constitue le délimiteur par défaut. Nous pouvons spécifer un autre délimiteur au travers de la méthode useDelimiteur(). |
| hasNext(String motif) hasNext(Pattern motif) |
boolean | Cette méthode est similaire à la précédente. Ici, la méthode accepte une expression régulière en argument et retourne true si les données en entrée sont semblables à cette expression. |
| hasNextBoolean() hasNextByte() hasNextByte(int base) hasNextDouble() hasNextFloat() hasNextInt() hasNextInt(int base) hasNextLong() hasNextLong(int base) hasNextShort() hasNextShort(int base) |
boolean | Contrôle si la prochaine valeur en entrée (suite de caractères) peut se transformer dans la valeur correspondant au type spécifié dans le nom de la méthode. Pour les types entiers, ces méthodes sont mêmes capables de déterminer si la suite de caractères proposée respecte la base spécifiée en argument. |
| hasNextLine() |
boolean | Contrôle si une ligne est présente. Cette fois-ci, il s'agit d'une chaîne de caractères qui se termine par une fin de ligne. |
| next() next(String motif) next(Pattern motif) |
String | Découpe les données en entrée en une série d'occurence String, séparés par des espaces blancs ou par le délimiteur spécifié par la méthode useDelimiter(). Chaque appel à next(), par défaut, retourne le mot pointé par le curseur courant. Il est également possible de travailler avec les expressions régulières pour récupérer la valeur correspond au motif établi. |
| nextBoolean() nextByte() nextByte(int base) nextDouble() nextFloat() nextInt() nextInt(int base) nextLong() nextLong(int base) nextShort() nextShort(int base) |
boolean byte byte double float int int long long short short |
Interprète la chaîne de caractère présente dans la ligne courante et la tranforme dans le type correspondant à la méthode choisie. Si la tranformation se déroule correctement la méthode renvoie la valeur. Pour les types entiers, il est possible de travailler avec des valeurs numériques de base quelconque. La méthode retourne alors la valeur décimale équivalente. |
| nextLine() | String | Retourne toute la chaîne jusqu'à la fin de ligne. |
| skip(String motif) skip(Pattern motif) |
Scanner | Cette méthode ignore les délimiteurs et saute le texte correspondant à l'expression régulière spécifiée. |
| useDelimiter(String motif) useDelimiter(Pattern motif) |
Scanner | Cette méthode spécifie une expression régulière qui représente le délimiteur d'occurence. Une série d'espace blancs constitue le délimiteur par défaut. |
| useLocale(Locale pays) |
Scanner | Spécifie le pays pour analyser les nombres. Cela peut influencer des éléments tels que les caractères utilisés pour le point décimal ou comme le séparateur de milliers. |
| useRadix(int base) | Scanner | Spécifie la base sur laquelle les nombres devraient être analysés. Toutes les valeurs entre 2 et 36 sont autorisées. |
Nous allons mettre au point un premier programme qui utilise la classe Scanner dont le but est de traiter une chaîne de caractères issue du clavier. Cette chaîne correspond à un numéro de compte qui possède une structure particulière. Normalement, ce numéro est composé de trois parties. Il doit comporter d'abord trois lettres en majuscules suivi de 5 chiffres binaires et enfin de trois chifres décimaux. Les différentes parties sont séparées par un espace. Voici l'exemple d'un numéro valide : DUF 10110 342.
import java.util.Scanner; public class Principal { public static void main(String[] args) { Scanner clavier = new Scanner(System.in); System.out.println("Récupérer un numéro de compte avec des espaces de séparation"); System.out.println("Votre numéro de compte : "); String compte = clavier.nextLine(); Scanner saisie = new Scanner(compte); if (saisie.hasNext("[A-Z]{3}")) System.out.println("Référence de base : "+saisie.next()); else System.err.println("Le 1er groupe doit posséder 3 lettres"); if (saisie.hasNext("[0-1]{5}")) System.out.println("Valeur décimale du premier nombre : "+saisie.nextInt(2)); else System.err.println("Le 2ème groupe doit être une valeur binaire sur 5 chiffres"); if (saisie.hasNext("\\d{3}")) System.out.println("Deuxième nombre : "+saisie.nextInt()); else System.err.println("Le 3ème groupe doit posséder 3 chiffres"); } }
Votre numéro de compte :
DUF 10110 342
Référence de base : DUF
Valeur décimale du premier nombre : 22
Deuxième nombre : 342
---------------------------------------------------
Votre numéro de compte :
DUF10110342
Le 1er groupe doit posséder 3 lettres
Le 2ème groupe doit être une valeur binaire sur 5 chiffres
Le 3ème groupe doit posséder 3 chiffres
---------------------------------------------------
Votre numéro de compte :
DUF 10110 34U
Référence de base : DUF
Valeur décimale du premier nombre : 22
Le 3ème groupe doit posséder 3 chiffres
Nous allons reprendre le même type d'exercice. Cette fois-ci, par contre, le numéro de compte ne possède pas d'espace séparateur. Voici un numéro de compte valide : DUF10110342.
import java.util.Scanner; public class Principal { public static void main(String[] args) { Scanner clavier = new Scanner(System.in); System.out.println("Récupérer un numéro de compte avec des espaces de séparation"); System.out.println("Votre numéro de compte : "); String compte = clavier.nextLine(); if (compte.matches("[A-Z]{3}[0-1]{5}\\d{3}")) { Scanner saisie = new Scanner(compte); System.out.println("Référence de base : "+saisie.findInLine("[A-Z]{3}")); System.out.println("Valeur décimale du premier nombre : "+Integer.parseInt(saisie.findInLine("[0-1]{5}"), 2)); System.out.println("Deuxième nombre : "+Integer.parseInt(saisie.findInLine("\\d{3}"))); } else System.err.println("Votre numéro n'est pas bon"); } }
Votre numéro de compte :
DUF10110342
Référence de base : DUF
Valeur décimale du premier nombre : 22
Deuxième nombre : 342
En reprenant le même exemple, voici comment utiliser les méthodes useDelimiter() et skip(). Cette fois-ci, le nombre binaire est évalué après :
import java.util.Scanner; public class Principal { public static void main(String[] args) { Scanner clavier = new Scanner(System.in); System.out.println("Récupérer un numéro de compte avec des espaces de séparation"); System.out.println("Votre numéro de compte : "); String compte = clavier.nextLine(); if (compte.matches("[A-Z]{3}[0-1]{5}\\d{3}")) { Scanner saisie = new Scanner(compte); saisie.useDelimiter("\\d"); System.out.println("Référence de base : "+saisie.next()); saisie.useDelimiter("\\s"); System.out.println("Deuxième nombre : "+saisie.skip("[0-1]{5}").nextInt()); System.out.println("Valeur décimale du premier nombre : "+new Scanner(compte.substring(3,8)).nextInt(2)); } else System.err.println("Votre numéro n'est pas bon"); } }
Votre numéro de compte :
DUF10110347
Référence de base : DUF
Deuxième nombre : 347
Valeur décimale du premier nombre : 22