Les collections
Les collections
 Nous allons ici faire l'étude du regroupement mémoire d'éléments de même type que nous appelons collections. Nous en profiterons pour revoir les tableaux classiques pour mieux cerner l'intérêt de proposer d'autres alternatives.
Nous allons ici faire l'étude du regroupement mémoire d'éléments de même type que nous appelons collections. Nous en profiterons pour revoir les tableaux classiques pour mieux cerner l'intérêt de proposer d'autres alternatives.
Les collections que vous choisirez peut engendrer une grande différence, à la fois au moment de l'implémentation des méthodes et en termes de performances. Faut-il rechercher rapidement parmi des miliers (voire des millions) d'éléments triés ? Devez-vous rapidement insérer et supprimer des éléments au milieu d'une suite triée ? Devez-vous établir des associations entre clés et valeurs ?
Cette étude met en évidence la façon dont la bibliothèque Java peut vous aider à trouver une structure de données adaptée à une programmation sérieuse, et par là, choisir la collection équivalente.
Attention : afin de bien maîtriser les différents concepts mis en oeuvre sur ces collections, il est important de connaître la généricité qui est expliquée dans l'étude précédente.
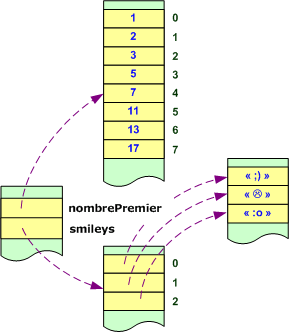
Un tableau java est un objet qui mémorise un ensemble de valeurs contiguës en mémoire, auxquelles on accède grâce à un indice entier compris entre 0 et le nombre d'éléments moins un.
Un tableau qui contient des valeurs de type primitif, comme le tableau nombrePremier, stocke directement ses valeurs les unes à la suite des autres, tandis que celui qui contient des objets, comme le tableau smileys, stocke les références sur ses objets.
Java laisse la liberté de placer les crochets [] avant ou après l'identificateur de tableau :
int t[] ; ou bien int[] t ;
La création d'un tableau de type objet ne génère pas d'objet pour chaque élément, mais uniquement des références initialisées à null par défaut.
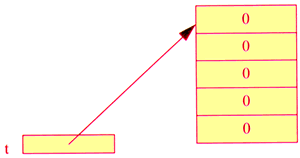
On crée un tableau comme on crée un objet, c'est à dire en utilisant l'opérateur new. On précise à la fois le type des éléments, ainsi que leur nombre (dimension du tableau).
t = new int[5]; // t fait référence à un tableau de 5 entiers
Cette instruction alloue l'emplacement nécessaire à un tableau de 5 éléments de type int et place la référence dans t. Les 5 éléments sont initialisés par défaut (comme tous les champs d'un objet) à une valeur nulle (0 pour int).
float[] tabNombres = new float[5];
String[] textes;
...
int taille = 10;
textes = new String[taille];
int[] nombrePremiers = {1, 2, 5, 7, 11, 13};
String[] smileys = {";)", ":(", ":o"};
Un tableau (array en anglais) est le type d'objet le plus simple à programmer pour gérer un ensemble d'éléments :
Les tableaux permettent donc de regrouper une suite de variables de même type. Chaque élément du tableau est une variable que vous pouvez utiliser comme n'importe quelle variable de ce type. Il est possible de définir des tableaux pour les types primaires ou les classes. Cependant, tous les éléments doivent être du même type. En Java, les tableaux sont des objets.
Pour pouvoir utiliser un tableau, vous devez respecter les trois étapes suivantes :
Effectivement, comme un tableau est un objet, la création d'un tableau commence par la mise en place de sa référence afin de pointer ultérieurement vers l'objet tableau lui-même. Voici comment se déclare une telle référence t de type tableau d'entiers :
int t[];
Elle précise que t est destiné à contenir la référence à un tableau d'entiers. Vous constatez qu'aucune dimension ne figure dans cette déclaration et, pour l'instant, aucune valeur n'a été attribuée à t. Comme toute référence, une référence de type tableau peut être égale à null ou désigner un objet tableau.
Voici quelques exemples de déclarations :
int t[]; // peut s'écrire int[] t ; int [] t1, t2; // t1 et t2 sont des références à des tableaux d'entiers int t3[], t4[]; // écritures équivalentes int t5[], n, t6[]; // t5 et t6 sont des tableaux d'entiers, n est entier Point tp[]; // tp est une référence à un tableau d'objets de type Point Point a, tp[]; // a est une référence à un objet de type Point, tp est une référence à un tableau d'objets de type Point int tab[5]; // erreur : nous ne pouvons pas indiquer de dimension ici.
Nous pouvons effectuer la création et l'initialisation d'un tableau de trois façons différentes :
Création par l'opérateur new
Après avoir déclaré la variable tableau, il faut allouer les éléments de ce tableau. On utilise pour ce faire l'opérateur new. Vous avez déjà mis en oeuvre cet opérateur pour créer des objets. A ce niveau, il est obligatoire de préciser le nombre d'éléments du tableau. Ces derniers sont initialisés automatiquement en fonction du type de tableau (0 pour les numériques, '\0' pour les caractères, false pour les boolean et null pour les éléments de type objet).
package test; import java.awt.*; public class Main { public static void main(String[] args) { int[] tabEntier = new int[30]; // tableau de 30 entiers de valeur nulle String[] semaine = new String[7]; /* tableau de 7 références vers des objets * de type String. Par la suite, il sera nécessaire * pour chaque élément du tableau de * créer un objet de type String */ } }
Utilisation d'un initialiseur
Lors de la déclaration d'une référence, il est possible de fournir la valeur à chacune des cases du tableau. Il suffit de donner la liste entre accolades sans utiliser l'opérateur new. Java se sert du nombre de valeurs figurant dans l'initialiseur pour en déduire la taille du tableau à créer.
int[] t = {1, 3, 5, 7}; /* création d'un tableau de 4 entiers de * valeurs respectives 1, 3, 5, 7 et place * la référence dans t. Elle remplace les * instructions suivantes : */ int t[]; t = new int[4]; t[0]=1; t[1]=3; t[2]=5; t[3]=7;
tableau anonyme
A tout moment en utilisant l'opérateur new et une liste entre accolades de valeurs. Cette notation est très pratique pour passer un tableau en paramètres à une méthode sans qu'il faille créer une variable locale pour ce tableau. En imaginant la déclaration de la méthode suivante :
afficheSemaine(String[] joursSemaine);
Voici un exemple de tableau anonyme que nous pouvons passer en argument de la méthode :
afficheSemaine(new String[] {"Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche"});
Cette écriture est à la fois un raccourci et évite d'utiliser une variable intermédiaire :
String[] jours = {"Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche"} ;
afficheSemaine(jours);
Nous pouvons manipuler un élément de tableau comme nous le ferions avec n'importe quelle variable ou n'importe quel objet de ses éléments. On désigne un élément particulier en plaçant entre crochets, à la suite du nom du tableau, une expression entière nommée indice indiquant sa position. Le premier élément correspond à l'indice 0 (et non 1).
int t[] = new int[5], a; t[0] = 15; // place la valeur 15 dans le premier élément du tableau t[2]++; // incrémente de 1 le troisième élément de t a = t[4]+23; // utilisation dans un calcul t[1] = t[0]+5; // initialisation d'un élément à partir d'un autre t[a-20] = -85; // calcul sur l'indice
La classe java.util.Arrays contient un ensemble de méthodes de classe qui permettent d'effectuer des traitements sur les tableaux de type primitif ou de type d'objet :
toString(type[] tableau) : renvoie une chaîne de caractères avec les éléments de tableau, entre parenthèses et délimités par des virgules.
deepToString(type[] tableau) : renvoie une chaîne de caractères avec les éléments de tableau dont la structure est par nature multidimensionnel.
equals() : compage les éléments de deux tableaux ;
fill() : remplit tout ou partie d'un tableau avec une valeur donnée ;
sort() : trie les éléments d'un tableau dans l'ordre ascendant ;
binarySearch() : renvoie l'indice du premier élément égal à une valeur dans un tableau trié.
import java.util.Arrays; public class Main { public static void main(String[] args) { String[] liste = {"Salut", "Bonjour"}; String[] copie = new String[2]; System.arraycopy(liste, 0, copie, 0, 2); Arrays.sort(liste); boolean test = Arrays.equals(copie, liste); } }
Le JDK 5.0 a introduit une construction de boucle performante qui vous permet de parcourir chaque élément d'un tableau (ainsi que d'autres collections d'éléments) sans avoir à vous préoccuper des valeurs d'indice.
La boucle for améliorée :
for (variable : collection) instruction
définit la variable donnée sur chaque élément de la collection, puis exécute l'instruction (qui, bien sûr, peut être un bloc). L'expression collection doit être un tableau ou un objet d'une classe qui implémente l'interface Iterable, comme ArrayList. Par exemple :
int[] tableau = new int[10];
for (int élément : tableau)
System.out.println(élément); // affiche chaque élément du tableau sur une ligne séparée.
Il est conseillé de lire cette boucle sous la forme "pour chaque élément dans tableau".
Bien entendu, vous pourriez obtenir le même effet avec la boucle for traditionnelle :
int[] tableau = new int[10];
for (int élément=0; élément<10; élément++) System.out.println(tableau[élément]);
Toutefois, la boucle "for each" est plus concise et moins sujette à erreur (vous n'avez pas à vous inquiéter des valeurs d'indice de début et de fin, qui sont souvent pénibles).
La variable loop de la boucle "for each" parcourt les éléments d'un tableau, et non les valeurs d'indice.
La boucle "for each" est une amélioration agréable de la boucle traditionnelle si vous devez traiter tous les éléments d'une collection. Il y a toutefois de nombreuses opportunités d'utiliser la boucle for traditionnelle. Vous ne voudrez pas, par exemple, parcourir la totalité de la collection ou pourriez avoir besoin de la valeur d'indice à l'intérieur de la boucle.
Java permet aussi de manipuler globalement des tableaux, par le biais d'affectations de leurs références.

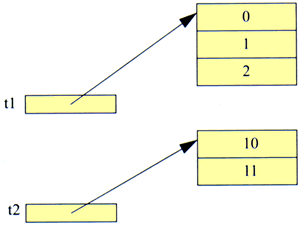
Exécutons maintenant l'affectation :
t1 = t2; // la référence contenue dans t2 est recopiée dans t1
Nous aboutissons à la situation présentée ci-dessous. Dorénavant, t1 et t2 désigne le même tableau.
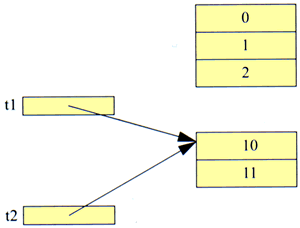
Ainsi, avec :
t1[1] = 5;
System.out.println (t2[1]);
on obtiendra l'affichage de la valeur 5, et non 11.
Si l'objet que constitue le tableau de trois entiers anciennement désigné par t1 n'est plus référencé par ailleurs, il deviendra candidat au ramasse-miettes.
Il est très important de noter que l'affectation de références de tableaux n'entraine aucune recopie des valeurs des éléments du tableau. On retrouve exactement le même phénomène que pour l'affectation d'objets.
Pour connaître le nombre d'éléments d'un tableau, vous pouvez utiliser l'attribut public length. Cet attribut peut être utilisé pour tous les types de tableaux. Considérez le code suivant :
int tab[] = new int [10];
int taille = tab.length; // taille est égal à 10
Après avoir déclaré un tableau, utilisez length pour récupérer le nombre d'éléments du tableau (ici 10).
Le mot length désigne en quelque sorte un attribut du tableau, attribut que l'on peut d'ailleurs uniquement lire ; ce n'est pas un attribut au même titre que les attributs d'une classe. Remarquons qu'il n'y a pas d'autre attribut pour une variable de type tableau.
Attention : Pour définir un tableau d'objets, il faut commencer par définir un tableau de références, puis, pour chaque référence, créer l'objet associé. Un tableau d'objets est en fait un tableau de références, et chaque référence pointe vers l'objet associé.
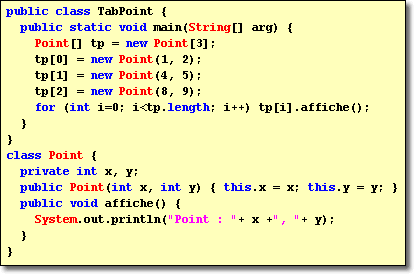
Le résultat est le suivant :
Point : 1, 2
Point : 4, 5
Point : 8, 9
Il est possible d'avoir une écriture plus concise de la classe TabPoint en utilisant l'initialiseur de tableau.

Il existe une méthode très très simple pour afficher toutes les valeurs d'un tableau dans la sortie standard, et ce grâce à la méthode toString() de la classe Arrays. L'appel Arrays.toString(tableau) renvoie une chaîne de caractères contenant les éléments du tableau, insérés entre crochets et séparés par des virgules :
System.out.println(Arrays.toString(tableau)); // affichepar exemple à l'écran "[2, 3, 5, 7, 11, 13]"
Il est possible de copier une variable tableau dans une autre, mais attention, comme nous l'avons vu plus haut, les deux variables feront alors référence au même tableau :
int[ ] suite = {17, 19, 23, 29, 31, 37};
int[ ] entier = suite;
entier[3] = 12; // suite[3] vaut maintenant 12
int[ ] suite = {17, 19, 23, 29, 31, 37};
int[ ] entier = Arrays.copyOf(suite, suite.length);
int[ ] suite = {17, 19, 23, 29, 31, 37};
suite = Arrays.copyOf(suite, 2 * suite.length);
Les autres éléments sont remplis de 0 si le tableau contient des nombres, false si le tableau contient des valeurs booléennes. A l'inverse, si la longueur est inférieure à celle du tableau initial, seules les valeurs initiales sont copiées.
Si vous voulez trier un tableau de nombres, utilisez une des méthodes sort() de la classe Arrays :
int[ ] nombre = new int[100];
...
Arrays.sort(nombre);
Cette méthode utilise une version adaptée de l'algorithme QuickSort qui se révèle très efficace sur la plupart des ensembles de données.
§
Une boucle "for each" ne traverse pas automatiquement toutes les entrées d'un tableau multidimensionnel. Elle parcourt plutôt les lignes, qui sont elles-mêmes des tableaux à une dimension. Pour visiter tous les éléments d'un tableau bidimensionnel, imbriquer deux boucles :
int[ ][ ] tableau = { {16, 3, 2, 13}, {5, 10, 11, 8}, {9, 6, 7, 12}, {4, 15, 14, 1} }; ... for (int[ ] ligne : tableau) for (int élément : ligne) // faire quelque chose avec élément
System.out.println(Arrays.deepToString(tableau));
[[16, 3, 2, 13], [5, 10, 11, 8], [9, 6, 7, 12], [4, 15, 14, 1]]
Les tableaux sont inadéquats pour gérer une quantité importante d'informations du même type quand leur nombre n'est pas connu à l'avance. Par exemple, le nombre de messages postés dans un forum n'étant pas limité, il existe des solutions plus simples que des tableaux pour stocker ces messages. Le paquetage java.util contient plusieurs classes de collection utilisées pour gérer un ensemble d'éléments de type d'objet et résoudre les limitations inhérentes aux tableaux, ce que nous allons aborder dans les chapitres qui suivent.
Comme pour la plupart des bibliothèques de données récentes, la bibliothèque de collections Java fait la distinction entre les interfaces et les implémentations. Intéressons-nous à cette distinction avec une structure de données familière, la queue de données.
Une interface de queue indique que vous pouvez :
Les queues sont utilisées si vous devez enregistrer des objets et les récupérer selon la règle "premier entré, premier sortie" (FIFO - First In First Out)
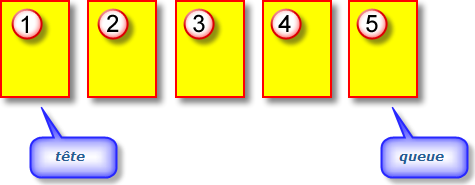
Une forme minimaliste d'interface pour les queues pourrait ressembler à ceci :
interface Queue<E> { void add(E élément); E remove(); int size(); }
L'interface n'indique en aucune manière la façon dont la queue est implémentée.
§
En réalité, il existe deux implémentations courantes de queues :
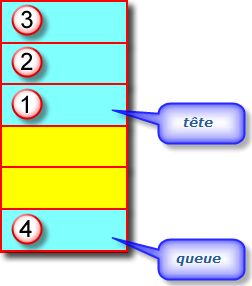
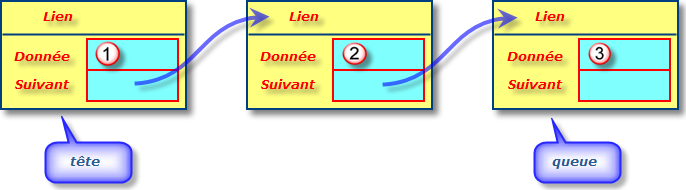
Queue<String> textes = new ArrayDeque<String>(); textes.add("Premier texte");Avec cette approche, si vous changez de point de vue, vous pouvez facilement utiliser une implémentation différente. Vous n'avez besoin de modifier votre programme qu'à un seul endroit : le constructeur. Si vous décidez qu'après tout, une LinkedList constitue un meilleurs choix, votre programme devient :
Queue<String> textes = new LinkedList<String>(); textes.add("Premier texte");
Pourquoi choisir une implémentation plutôt qu'une autre ? Une interface ne fournit aucun détail quant à l'efficacité de son implémentation. De manière générale, un tableau circulaire est plus efficace qu'une liste chaînée, et il est donc préférable à cette dernière. Toutefois, comme d'habitude, il y a un prix à payer. Les tableaux circulaires font partie d'une collection bornée, qui a une capacité déterminée. Si vous ne connaissez pas la limite maximale du nombre d'objets stockés par votre programme, vous préférerez probablement une implémentation en liste chaînée.
En étudiant la documentation de l'API, vous découvrirez un autre jeu de classes dont le nom commence par Abstract, comme AbstractQueue. Ces classes sont destinées aux implémentations de bibliothèque. Pour implémenter votre propre classe de queue, il sera plus facile d'étendre AbstractQueue que d'implémenter toutes les méthodes de l'interface Queue.
En réalité, l'interface fondamentale des classes de collection de la bibliothèque Java est l'interface Collection.
public interface Collection<E> { boolean add(E élément); Iterator<E> iterator(); ... }
Par exemple, si vous essayez d'ajouter un objet dans un ensemble et que cet objet en fasse déjà partie, la requête add() est sans effet parce que les ensembles de données ne peuvent pas accepter deux fois la même donnée.
Les itérateurs permettent de parcourir la collection d'un début vers une fin en ne passant qu'une seule fois sur chacun des éléments. Associé à une collection donnée, l'itérateur possède les propriétés suivantes :
public interface Iterator<E> { E next(); boolean hasNext(); void remove(); }
Comme nous l'avons évoqué plus haut, en appelant plusieurs fois la méthode next(), vous pouvez parcourir tous les éléments d'une collection un par un. Lorsque la fin de la collection est atteinte, la méthode next() déclenche une exception NuSuchElementException. Par conséquent, il convient d'appeler la méthode hasNext() avant la méthode next(). Cette méthode renvoie true si l'objet de l'itération possède encore au moins un élément.
Collection<String> textes = ...; Iterator<String> it = textes.iterator(); while (it.hasNext()) { String élément = it.next(); // utilisation de élément }
Collection<String> textes = ...; for (String élément : textes) { // utilisation de élément }
Le compilateur se contente de traduire la boucle "for each" en boucle avec un itérateur.
§
La boucle "for each" fonctionne comme tout objet qui implémente l'interface Iterable, une interface avec une seule méthode, la méthode iterator() :
public interface Iterable<E> { Iterator<E> iterator(); }
L'interface Collection étend l'interface Iterable. Vous pouvez donc utiliser la boucle "for each" avec n'importe quelle collection de la bibliothèque standard.
§
L'ordre de visite des éléments dépend du type de la collection. Si vous parcourez un ArrayList, l'itérateur démarre à l'indice 0 et l'incrémente à chaque pas. Toutefois, si vous visitez les éléments dans un HashSet, vous les rencontrerez dans un ordre aléatoire.
Vous pouvez être sûr de rencontrer tous les éléments d'un collection lors de l'itération, mais vous ne pouvez pas savoir dans quel ordre. Cela ne pose généralement pas de problème car l'ordre importe peu pour des calculs comme les totaux ou les concordances.
L'interface Iterator prévoit la méthode remove() qui supprime de la collection le dernier objet envoyé par la méthode next(). Dans de nombreux cas, cette méthode est pratique si vous avez besoin d'examiner chaque élément avant de savoir si vous devez le supprimer ou non. Mais, si vous souhaitez effacer un élément en fonction de sa position, il faut malgré tout le dépasser.
Par exemple, voici comment supprimer le premier élément d'une collection de chaînes :
Iterator<String> it = textes.iterator(); it.next(); it.remove();
Bien que l'itérateur soit placé en début de collection, il n'existe encore aucun élément courant car aucun objet n'a encore été renvoyé par la méthode next(). Ainsi, pour supprimer le premier objet de la collection, il faut d'abord l'avoir lu.
Donc, si vous désirez supprimer deux éléments successifs, vous n'avez pas le droit d'appeler :
it.remove(); it.remove(); // erreur
Il faut appeler next() pour passer au-dessus de l'élément à supprimer :
it.remove(); it.next(); it.remove(); // Ok
On notrera bien que l'interface Iterator ne comporte pas de méthode d'ajout d'un élément à une position déterminée (c'est-à-dire en général entre deux éléments). En effet, un tel ajout n'est réalisable que sur des collections disposant d'informations permettant de localiser, non seulement l'élément suivant, mais aussi l'élément précédent d'un élément donné. Ce ne sera le cas que de certaines collections seulement, disposant précisément d'itérateurs bidirectionnels.
En revanche, nous verrons que toute collection disposera d'une méthode d'ajout d'un élément à un emplacement (souvent sa fin) indépendant de la valeur d'un quelconque itérateur. C'est d'ailleurs cette démarche qui sera le plus souvent utilisée pour créer effectivement une collection.
Certaines collections (listes chaînées, vecteurs dynamiques) peuvent, par nature, être parcourues dans les deux sens. Elles disposent d'une méthode nommée listIterator() qui fournit un itérateur bidirectionnel. Il s'agit, cette fois, d'un objet d'un type implémentant l'interface ListIterator<E> (qui dérive de l'interface Iterator<E>). Il dispose bien sûr des méthodes next(), hasnext() et remove() héritées de Iterator. Mais il dispose d'autres méthodes permettant d'exploiter son caractère bidirectionnel, à savoir :
Nous pouvons obtenir l'élément précédent la position courante à l'aide de la méthode previous() de l'iterateur, laquelle, en outre, recule l'itérateur sur la position précédente. Ainsi, deux appels successifs de previous() fournissent deux objets différents.
La méthode hasPrevious() de l'itérateur permet de savoir si nous sommes ou non en début de collection, c'est-à-dire si la position courante dispose ou non d'une position précédente.
LinkedList<String> textes = ...; ListIterator<String> it = textes.listIterator(texte.size()); while (it.hasPrevious()) { String élément = it.previous(); // utilisation de élément }
Un appel à la méthode previous() annule, en quelque sorte, l'action réalisée sur le pointeur de déplacement, par un précédent appel à la méthode next().
L'interface ListIterator prévoir une méthode add() qui ajoute un élément à la position courante de l'itérateur. Si ce dernier est en fin de collection, l'ajout se fait tout naturellement en fin de collection (y compris si la collection est vide). Si l'itérateur désigne le premier élément, l'ajout se fera avant ce premier élément. Par exemple, si textes est une collection disposant d'un itérateur bidirectionnel, les instructions suivantes ajouterons l'élément avant le deuxième élément (en supposant qu'il existe) :
LinkedList<String> textes = ...; ListIterator<String> it = textes.listIterator(texte.size()); it.next(); it.next(); it.add(élément);
Nous noterons bien ici, quelle que soit la position courante, l'ajout par add() est toujours possible. De plus, contrairement à remove(), cet ajout ne nécessite pas que l'élément courant soit défini (il n'est pas nécessaire qu'un quelconque élément ait déjà été renvoyé par next() ou previous()).
Par ailleurs, add() déplace la position courante après l'élément que nous venons d'ajouter. Plusieurs appels consécutifs de add() sans intervention explicite sur l'itérateur introduisent donc des éléments consécutifs.
L'appel à la méthode set(élément) remplace l'élément courant, c'est-à-dire le dernier renvoyé par next() et previous(), à condition que la collection n'ait pas été modifiée entre temps (par exemple par add() ou remove()). N'oubliez pas que les éléments ne sont que de simples références ; la modification opérée par set() n'est donc qu'une simple modification de référence (les objets concernés n'étant pas modifiés).
La position courante de l'itérateur n'est pas modifiée (plusieurs appels successifs de set(), sans action sur l'itérateur, reviennent à ne retenir que la dernière modification).
N'oubliez pas que set(), comme remove(), s'applique à un élément courant (et non comme add() à une position courante).
§
Comme les interfaces Iterator et Collection sont générales, il est possible d'écrire des méthodes pratiques pouvant travailler sur n'importe quel type de collection.
Par exemple, voici une méthode générale qui teste si une collection arbitraire contient un élément donné :
public static<E> boolean contains(Collection<E> collection, Object objet) for (E élément : collection) if (élément.eguals(objet)) return true; return false; }
Les concepteurs de la bibliothèque Java ont décidé que certaines de ces méthodes générales étaient tellement pratiques qu'elles devaient faire partie de la bibliothèque. De cette façon, les utilisateurs n'ont pas besoin de réinventer la roue en permanence. La méthode contains() en constitue un bon exemple.
public abstract class AbstractCollection<E> implements Collection<E> { ... public abstract Iterator<E> iterator(); ... public static<E> boolean contains(Collection<E> collection, Object objet) for (E élément : collection) if (élément.eguals(objet)) return true; return false; }
Une classe de collection concrète peut maintenant étendre la classe AbstractCollection. C'est donc à la classe de collection concrète de fournir une méthode iterator(), mais la méthode contains() est gérée par la super-classe AbstractCollection. De plus, si la sous-classe propose une meilleure implémentation de la méthode contains(), elle est libre de l'utiliser.
Il s'agit là d'une bonne architecture pour un ensemble de classes. Les utilisateurs des classes de collection disposent ainsi d'un ensemble de méthodes très complet disponible au travers de l'interface générale et les programmeurs chargés des structures de données n'ont pas besoin de se préoccuper de toutes les méthodes.
Maintenant que nous avons pris connaissance avec les interfaces principales pour gérer les collections et plutôt que de voir en détail chaque interface, il est plus utile dès lors de commencer par aborder les structures de données concrètes implémentées dans la bibliothèque Java. Une fois que nous aurons correctement décrit les classes que nous pouvons utiliser, nous reviendrons à des considérations abstraites et nous verrons comment la structure des collections organise toutes ces classes.
Le tableau ci-dessous présente les collections de la bibliothèque Java et décrit brièvement l'objectif de chaque classe de collection (pour des raisons de simplicité, nous ne parlerons pas des collections compatibles avec les Threads qui seront traitées dans une autre étude).
Pour en savoir plus sur les collections compatibles avec les threads.
§
Toutes les classes du tableau implémente l'interface Collection, à l'exception de celles dont le nom se termine par Map. Celles-ci implémentent plutôt l'interface Map (nous la traiterons un peu plus loin).
| Type de collection | Description |
|---|---|
| ArrayList | Une séquence indexée qui grandit et se réduit de manière dynamique. |
| LinkedList | Une séquence ordonnée qui permet des insertions et des retraits effectifs à n'importe quel endroit. |
| ArrayDeQue | Une queue à deux extrémités implémentée sous forme de tableau circulaire. |
| HashSet | Un ensemble de valeur non ordonnée qui refuse les réplications (comme dans la théorie des ensembles). |
| TreeSet | Un ensemble trié. |
| EnumSet | Un ensemble de valeur de type énuméré. |
| LinkedHashSet | Un ensemble qui se souvient de l'ordre d'insertion des éléments. |
| PriorityQueue | Une collection qui permet un retrait effectif de l'élément le plus petit. |
| HashMap | Une structure de données qui stocke les associations clé/valeur. |
| TreeMap | Une concordance dans laquelle les clés sont triées. |
| EnumMap | Une concordance dans laquelle les clés appartiennent à un type énuméré. |
| LinkedHashMap | Une concordance qui se souvient de l'ordre d'ajout des entrées. |
| WeakHashMap | Une concordance avec des valeurs pouvant être réclamées par le ramasse-miettes si elles ne sont pas utilisées ailleurs. |
| IdentityHashMap | Une concordance avec des clés comparées par ==, et non par equals() |
Nous avons déjà abordé les tableaux et, dans de nombreux exemples, leur cousin dynamique, la classe ArrayList (qui sera abordée dans le chapitre suivant). Voici recensés ci-dessous les différents critères relatifs à leur structure :
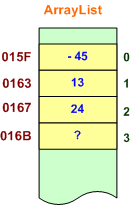 En fait, en interne, la classe ArrayList mémorise ses éléments dans un tableau Java. Si ce tableau interne est trop petit lors de l'ajout d'un nouvel élément à la collection, il est automatiquement remplacé par un nouveau tableau, plus grand, initialisé avec les références de l'ancien tableau.
En fait, en interne, la classe ArrayList mémorise ses éléments dans un tableau Java. Si ce tableau interne est trop petit lors de l'ajout d'un nouvel élément à la collection, il est automatiquement remplacé par un nouveau tableau, plus grand, initialisé avec les références de l'ancien tableau.
La classe ArrayList est très séduisante. Il s'agit ni plus ni moins d'un tableau dynamique. Elle est totalement adaptée lorsque nous devons ajouter ou supprimer des éléments en fin de tableau.
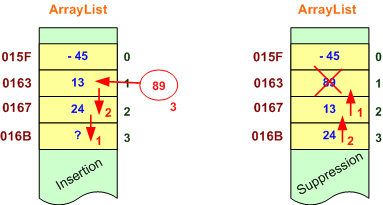 Mais ces deux structures possèdent un inconvénient majeur. La suppression d'un élément au milieu d'un tableau nécessite beaucoup de temps machine, car tous les éléments situés après l'élément supprimé doivent être décalés d'une case. Le même problème se pose pour insérer des éléments au milieu d'un tableau.
Mais ces deux structures possèdent un inconvénient majeur. La suppression d'un élément au milieu d'un tableau nécessite beaucoup de temps machine, car tous les éléments situés après l'élément supprimé doivent être décalés d'une case. Le même problème se pose pour insérer des éléments au milieu d'un tableau.
Il existe une autre structure de données très répandue, la liste chaînée, qui permet de résoudre ces problèmes. Alors que les objets d'un tableau occupent des emplacements mémoires successifs, une liste chaînée stocke chaque objet avec un lien qui y fait référence. Chaque lien possède également une référence vers le lien suivant de la liste. Avec Java, chaque élément d'une liste chaînée possède en fait deux liens, c'est-à-dire que chaque élément est aussi relié à l'élément précédent. La bibliothèque Java possède la classe LinkedList prète à l'emploi et qui implémente donc la liste "doublement chaînée".
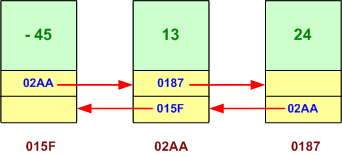
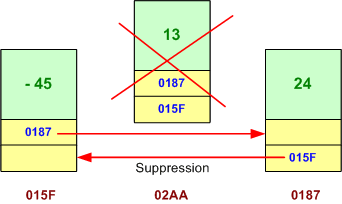
La classe LinkedList mémorise ses éléments avec une liste doublement chaînée, ce qui permet d'insérer plus rapidement un élément dans la collection, mais par contre, ralentit l'accès à un élément par son indice.
Par exemple, le type de données "set" que nous aborderons dans un prochain chapitre n'impose aucun ordre à ses éléments. C'est pourquoi il n'existe aucune méthode add() dans l'interface Iterator. Pour compenser, la bibliothèque de collections fournit une sous-interface de Iterator, que nous avons déjà découvert, qui se nomme ListIterator et qui possède effectivement la méthode add().
Contrairement à la méthode add() de Collection, cette méthode add() de ListIterator ne renvoie par un boolean, c'est-à-dire que l'opération add() est censée toujours modifier la liste.
La classe LinkedList permet ainsi de manipuler des listes doublement chaînées. A chaque élément de la collection, on associe (de façon totalement transparente pour le programmeur) deux informations supplémentaires qui ne sont autres que les références à l'élément précédent et au suivant. Une telle collection peut être ainsi parcourue à l'aide d'un itérateur bidirectionnel de type ListIterator.
Il existe une méthode listIterator() de la classe LinkedList qui renvoie un objet itérateur qui implémente l'interface ListIterator :LinkedList<String> textes = ...; ListIterator<String> it = textes.listIterator();
List<String> prénoms = new LinkedList<String>(); prénoms.add("Claire"); prénoms.add("Laurent"); prénoms.add("Adrien"); ListIterator<String> itérateur = prénoms.listIterator(); itérateur.next(); // ignorer le premier élément itérateur.add("Juliette");
Si vous appelez la méthode add() de ListIterator plusieurs fois, les éléments sont simplement ajoutés dans l'ordre dans lequel vous les passez. Ils sont tous ajoutés avant la position courante de l'itérateur.
Comme pour toutes les classes concrètes, la classe LinkedList implémente une interface particulière (ou plusieurs), ici List, qui correspond à la fonctionnalité globale d'une liste. L'intérêt de déclarer une interface plutôt que la classe elle-même, je le rappelle, c'est qu'il est plus facile de changer ensuite le type de collection si le choix initial ne s'avère pas des plus judicieux à terme. Par exemple, si nous nous rendons compte que dans notre application, nous faisons très peu d'insertion ou de suppression d'éléments dans la liste, nous pourrions tout à fait prendre la classe ArrayList à la place de LinkedList puisque toutes les deux implémentent l'interface List.
|ABC A|BC AB|C ABC|
Faites attention à l'analogie avec un curseur de texte. L'opération remove() de ListIterator ne fonctionne pas exactement comme la touche Retour-arrière. Juste après un appel à la méthode next(), la méthode remove() supprime en fait l'élément à gauche de l'itérateur, exactement comme la touche Retour-arrière. Cependant, si vous venez d'appler la méthode previous(), l'élément situé à droite de l'itérateur sera supprimé. De plus, il n'est pas possible d'appeler la méthode remove() deux fois de suite.
Contrairement à la méthode add(), qui ne dépend que de la position de l'itérateur, la méthode remove() dépend de l'état de l'itérateur.
List<String> prénoms = new LinkedList<String>(); ListIterator<String> itérateur = prénoms.listIterator(); String ancienneValeur = itérateur.next(); itérateur.set("Justine"); // affecte une nouvelle valeur au premier élément
List<String> prénoms = new LinkedList<String>(); ListIterator<String> itérateur1 = prénoms.listIterator(); ListIterator<String> itérateur2 = prénoms.listIterator(); itérateur1.next(); itérateur1.remove(); itérateur2.next(); // déclenche une exception de type ConcurrentModificationException
Afin d'éviter ce type d'exception, il suffit de suivre une règle simple : vous pouvez attacher autant d'itérateurs à une collection que vous le souhaitez, tant qu'ils effectuent uniquement des lectures dans la liste. Sinon, vous pouvez attacher un seul itérateur qui peut à la fois lire et écrire.
Le déclenchement de ce type d'exception observe aussi une règle simple. La collection garde une trace du nombre d'opérations de transformations (comme l'ajout ou la suppression d'un élément). Chaque itérateur compte le nombre de transformations dont il est responsable. Au début de chaque méthode d'itérateur, ce dernier vérifie que son nombre de transformations est bien égal à celui de la collection. Dans le cas contraire, il déclenche l'exception ConcurrentModificationException.
Il existe une curieuse exception à la règle permettant de détecter une modification simultanée. La liste chaînée garde uniquement la trace des modifications structurelles de la liste, comme l'ajout et la suppression de liens. La méthode set() n'est pas comptée comme une modification structurelle. Vous pouvez attacher plusieurs itérateurs à une liste chaînée, et ils peuvent tous appeler set() pour modifier le contenu des liens existants. Cette capacité est en fait nécessaire pour un certain nombre d'algorithmes de la classe Collections que nous aborderons plus loin dans cette étude.
Vous connaissez désormais les méthodes fondamentales de la classe LinkedList. Vous pouvez vous servir d'un ListIterator pour parcourir les éléments d'une liste chaînée dans n'importe quelle direction et pour ajouter ou supprimer des éléments.
Comme nous l'avons vu dans la section précédente, plusieurs autres méthodes pratiques manipulent les listes chaînées, qui sont déclarées dans l'interface Collection. Ces méthodes, pour la plupart, sont implémentées dans la superclasse AbstractCollection de la classe LinkedList.
Les listes chaînées ne permettent pas d'accéder rapidement à n'importe quel élément. Si vous voulez connaître le n-ième élément d'une liste chaînée, il faut commencer par le début de la liste et sauter les n-1 premiers éléments. Il n'existe aucun moyen plus rapide. Pour cette raison, les programmeurs n'utilisent généralement pas les listes chaînées dans des situations où les éléments doivent être référencés par un index entier.
List<String> prénoms = new LinkedList<String>(); String valeur = prénoms.get(n);
Bien sûr, cette technique n'est pas très efficace. Si vous vous rendez compte que vous l'utilisez, c'est probablement que vous utilisez une structure de données qui n'est pas adaptée à votre problème.
List<String> prénoms = new LinkedList<String>(); for (int i=0; i < prénoms.size(); i++) utilisation de prénoms.get(i);
Chaque fois que vous recherchez un élément, vous parcourez à nouveau la liste depuis le début. L'objet LinkedList ne fait aucun effort pour se rappeler la position courante du dernier élément lu.
Ces méthodes sont assez efficaces, car l'itérateur garde en mémoire sa position courante.
§
L'obtention de cet itérateur reste assez peu efficace.
§
Si l'une de vos listes chaînées ne possède que quelques éléments, vous n'avez pas trop de soucis à vous faire à propos de l'efficacité des méthode get() et set(). Mais dans ce cas, quel est l'avantage d'une liste chaînée ? La seule motivation permettant de choisir une liste chaînée consiste à minimiser le coût d'une insertion ou d'une suppression d'un élément en plein milieu de la liste. Si vous n'avez que quelques éléments à traiter, il vaut mieux utiliser une ArrayList.
Nous conseillons d'ailleurs d'éviter toutes les méthodes qui utilisent un indice d'entier permettant de noter la position dans une liste chaînée. Pour obtenir un accès direct dans une collection, mieux vaut utiliser un tableau ou encore un ArrayList.
A titre d'exemple, je vous propose de créer une application qui permet de gérer (surtout de visualiser) une liste de prénoms. Je profite de cette application pour voir comment effectuer les différents cas d'utilisations : ajout, suppression, changement de prénom, se déplacer dans la liste et tout effacer.
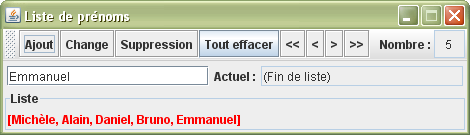
package listes; import java.awt.*; import java.awt.event.ActionEvent; import javax.swing.*; import java.util.*; public class Prénoms extends JFrame { private JTextField nouveauPrénom = new JTextField(, 18); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField prénomActuel = new JTextField(,18); private JTextField nombre = new JTextField(); private LinkedList<String> prénoms = new LinkedList<String>(); private ListIterator<String> itérateur = prénoms.listIterator(); public Prénoms() { super(); prénomActuel.setEditable(false); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { itérateur.add(nouveauPrénom.getText()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (itérateur.hasNext()) itérateur.set(nouveauPrénom.getText()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (itérateur.hasNext()) itérateur.remove(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.clear(); itérateur = prénoms.listIterator(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { itérateur = prénoms.listIterator(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (itérateur.hasPrevious()) itérateur.previous(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { if (itérateur.hasNext()) itérateur.next(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { itérateur = prénoms.listIterator(prénoms.size()); analysePrénoms(); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); panneau.add(nouveauPrénom); panneau.add(new JLabel()); panneau.add(prénomActuel); add(panneau); add(liste, BorderLayout.SOUTH); setSize(470, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analysePrénoms() { liste.repaint(); if (prénoms.isEmpty()) prénomActuel.setText(); else if (itérateur.hasNext()) { prénomActuel.setText(itérateur.next()); itérateur.previous(); } else prénomActuel.setText(); nombre.setText(+prénoms.size()); } public static void main(String[] args) { new Prénoms(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(prénoms.toString()); super.paint(g); } } }
Dans la section précédente, nous avons abordé l'interface List et la classe LinkedList qui l'implémente. L'interface List décrit une collection classée dans laquelle la position des éléments a une importance.
Il existe deux protocoles pour parcourir ces éléments : avec un itérateur ou avec les méthodes d'accès direct get() et set(). Ces deux méthodes ne sont pas vraiment adaptées à une structure de liste chaînée, mais get() et set() prennent toute leur importance avec les tableaux.
La bibliothèque de collections fournit une classe ArrayList qui implémente aussi l'interface List. Une ArrayList encapsule un tableau dynamique relogeable d'objets.
En définitive, les vecteurs (tableaux dynamiques) seront bien adaptés à l'accès direct à condition que les insertions et les suppressions restent limitées.
Il n'existe pas de méthodes réellement spécifiques à la classe ArrayList. Tout ce que nous connaissons déjà peut donc être pris en compte. Finalement, il suffit juste de connaître l'efficacité des méthodes utilisées. Suivant le cas, il peut être judicieux de choisir entre la classe ArrayList et la classe LinkedList.
A titre d'exemple, je vous propose de reprendre l'application précédente et d'implémenter la classe ArrayList à la place de la classe LinkedList. Cette fois-ci, je passerai par un indice plutôt que de passer par un itérateur.
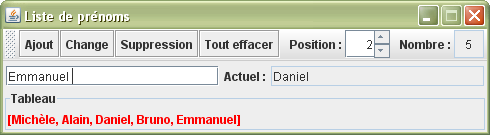
package listes; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import javax.swing.*; import java.util.*; import javax.swing.event.*; public class Prénoms extends JFrame { private JTextField nouveauPrénom = new JTextField(, 19); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField prénomActuel = new JTextField(,19); private JTextField nombre = new JTextField(); private JSpinner position = new JSpinner(); private ArrayList<String> prénoms = new ArrayList<String>(); private int indice; public Prénoms() { super(); prénomActuel.setEditable(false); position.setPreferredSize(new Dimension(45, 22)); position.addChangeListener(new ChangeListener() { public void stateChanged(ChangeEvent e) { int index = (Integer)position.getValue(); if (index>=0 && index<prénoms.size()) indice = index; else position.setValue(indice); analysePrénoms(); } }); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); AbstractAction ajout = new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.add(nouveauPrénom.getText()); analysePrénoms(); } }; barre.add(ajout); nouveauPrénom.addActionListener(ajout); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.set(indice, nouveauPrénom.getText()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.remove(indice--); position.setValue(indice); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.clear(); position.setValue(indice = 0); analysePrénoms(); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(position); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); panneau.add(nouveauPrénom); panneau.add(new JLabel()); panneau.add(prénomActuel); add(panneau); add(liste, BorderLayout.SOUTH); setSize(490, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analysePrénoms() { liste.repaint(); if (prénoms.isEmpty()) prénomActuel.setText(); else prénomActuel.setText(prénoms.get(indice)); nombre.setText(+prénoms.size()); } public static void main(String[] args) { new Prénoms(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(prénoms.toString()); super.paint(g); } } }
Lorsque nous consultons ce code en regard du même exemple traité par une liste chaînée, nous remarquons tout de suite que nous travaillons plus directement avec le tableau dynamique (ArrayList) sans passer systématiquement par un itérateur, ce qui etait très souvent le cas avec la classe LinkedList. Je préfère très nettement cette approche puiqu'elle me paraît plus intuitive.
Ci-dessous se trouve un exemple où nous prenons comme collection un tableau dynamique ArrayList. Les méthodes utilisées sont les méthodes communes aux deux types de collection. Remplacez, d'ailleurs, la classe ArrayList par LinkedList, vous remarquerez que votre programme vous donnera le même résultat. Le choix entre les deux types de collection doit correspondre uniquement au critère de performance. Si vous devez insérer ou supprimer des éléments n'importe où dans la collection, il faut alors choisir LinkerList. Si vous n'avez pas ce genre de contrainte et que vous voulez juste remplacer un tableau statique par un tableau dynamique, n'hésitez pas à prendre le conteneur ArrayList.
init:
deps-jar:
Compiling 1 source file to L:\BTS IRIS\TP Java\ListArray\build\classes
compile:
run:
Tableau vide ? true
Taille du tableau : 3
tableau[0] = -45
tableau[1] = 13
tableau[2] = 24
Taille du tableau : 4
tableau[0] = -45
tableau[1] = 89
tableau[2] = 13
tableau[3] = 24
Taille du tableau : 4
tableau[0] = -45
tableau[1] = 3
tableau[2] = 13
tableau[3] = 24
Taille du tableau : 3
tableau[0] = -45
tableau[1] = 3
tableau[2] = 24
tableau[] = { -45 3 24 -45 }
Position de la valeur -45 : 0
Position de la valeur -45 : 3
Taille du tableau : 0
BUILD SUCCESSFUL (total time: 0 seconds)
import java.util.*; import static java.lang.System.*; public class TableauDynamique { public static void main(String[] args) { // tableau d'entier par la classe enveloppe Integer ArrayList<Integer> tableau = new ArrayList<Integer>(); out.println("Tableau vide ? "+tableau.isEmpty()); tableau.add(-45); tableau.add(13); tableau.add(24); afficheTableau(tableau); // ajout de la valeur 89 à la position 1 tableau.add(1, 89); afficheTableau(tableau); // remplacer la valeur 89 par la valeur 3 tableau.set(1, 3); afficheTableau(tableau); // enlève la valeur 13 if (tableau.contains(13)) tableau.remove((Integer)13); afficheTableau(tableau); //ajout d'une nouvelle valeur et affichage en ligne tableau.add(-45); out.print("tableau[] = { "); for(Integer valeur : tableau) out.print(valeur+" "); out.println("}"); // position de la valeur -45 out.println("Position de la valeur -45 : "+tableau.indexOf(-45)); out.println("Position de la valeur -45 : "+tableau.lastIndexOf(-45)); // effacer le tableau en entier tableau.clear(); out.println("Taille du tableau : "+tableau.size()); } public static void afficheTableau(ArrayList<Integer> tableau) { out.println("Taille du tableau : "+tableau.size()); for (int i=0; i<tableau.size(); i++) out.println("tableau["+i+"] = "+tableau.get(i)); } }
Les listes chaînées et les tableaux vous permettent de spécifier l'ordre dans lequel vous voulez organiser vos éléments. Cependant, si vous recherchez un élément particulier et que vous ne vous rappeliez pas sa position, vous aurez besoin de parcourir tous les éléments jusqu'à ce que vous trouviez l'élément recherché. Cela requiert beaucoup de temps, surtout lorsque la collection contient pas mal d'éléments. Si l'ordre des éléments n'a pas d'importance, il existe des structures de données qui vous permettent de retrouver un élement très rapidement. L'inconvénient est que ces structures de données ne vous permettent pas de contrôler l'ordre des éléments. En effet, elles les organisent plutôt selon l'ordre qui leur permet de les retrouver facilement. Ces structures de données correspondent tout-à-fait à la théorie des ensembles.
Trois classes implémentent la notion d'ensemble : HashSet, TreeSet et EnumSet. Rappelons que, théoriquement, un ensemble est une collection non ordonnée d'éléments, aucun élément ne pouvant apparaître plusieurs fois dans un même ensemble. Chaque fois que nous introduisons un nouvel élément dans une collection de ce type, il est donc nécessaire de s'assurer qu'il n'y figure pas déjà, autrement dit que l'ensemble ne contient pas un autre élément qui lui soit égal.
Attention : Dès que nous nous écartons des types String, File ou classe enveloppe de type primitif, il est généralement nécessaire de se préoccuper des méthodes equals() ou compareTo() (ou d'un comparateur - voir plus loin) ; si nous ne le faisons pas, il faut alors accepter que deux objets de références différentes ne soient jamais identiques, quelles que soit leurs valeurs !
Par ailleurs, bien qu'en théorie un ensemble ne soit pas ordonné, des raisons évidentes d'efficacité de méthodes de test d'appartenance nécessite une certaine organisation de l'information. Dans le cas contraire, un tel test d'appartenance ne pourrait se faire qu'en examinant un à un les éléments de l'ensemble (ce qui conduirait à une efficacité moyenne).
Quatre démarches différentes ont été employées par les concepteurs des collections, d'où l'existence de quatre classes différentes :
En définitive, dans tous les cas, les éléments sont ordonnées même si cet ordre est moins facile à appréhender ; avec TreeSet, il s'agit de l'ordre induit par compareTo() ou un éventuel comparateur personnalisé.
Comme toute collection, un ensemble peut être construit vide ou à partir d'une autre collection :
La classe EnumSet ne possède pas de constructeurs publics. Utilisez une méthode de fabrique statique (qui génère une instance appropriée) pour construire l'ensemble désiré.
Ces ensembles disposent tous de méthodes communes puisque, comme pour les autres collections, elles implémentent l'interface Collection. Je rappelle, ci-dessous les méthodes bien utiles
HashSet<Interger> loto = ...; // TreeSet<Integer> loto = ...; Iterator<Integer> it = loto.iterator(); while (it.hasNext()) { int élément = it.next(); // utilisation de élément }
D'ailleurs, comme au niveau de leur implémentation, les ensembles sont organisés en fonction des valeurs de leurs éléments, l'opération ne serait pas réalisable.
La seule façon d'ajouter un élément à un ensemble est d'utiliser la méthode add() prévue par l'interface Collection. Elle assure en effet que l'élément en question n'existe pas déjà :HashSet<Interger> loto = ...; // TreeSet<Integer> loto = ...; ... boolean existe = loto.add(23); if (existe) System.out.println(23 + " existe déjà"); else System.out.println(23 + " a été ajouté");
Nous ne pouvons pas dire que add() ajoute l'élément en "fin d'ensemble" (comme dans le cas des collections étudiées précédemment). En effet, comme nous l'avons déjà évoqué, les ensembles sont organisés au niveau de leur implémentation, de sorte que l'élément devra quand même être ajouté à un endroit bien précis de l'ensemble (endroit qui se concrétisera lorsque nous utiliserons un itérateur). Pour l'instant, nous le devinons déjà, cet endroit sera imposé par l'ordre induit par compareTo() (ou par un comparateur personnalisé) dans le cas de TreeSet ; en ce qui concerne HashSet, nous verrons bientôt comment l'emplacement est déterminé.
TreeSet<Personnel> employés = ...; ... boolean trouvé = employés.remove(employé); if (trouvé) System.out.println(employé + " a été supprimé"); else System.out.println(employé + " n'existe pas");Par ailleurs, la méthode remove() de l'itérateur monodirectionnel permet de supprimer l'élément courant (le dernier renvoyé par next()) le cas échéant :
HashSet<Interger> loto = ...; Iterator<Integer> it = loto.iterator(); it.next(); it.next(); it.remove(); // supprime le deuxième élément }
La classe HashSet représente un ensemble d'éléments non ordonnés. De ce fait, elle offre une solution de recherche extrêmement efficace. Cette efficacité est dû à sa structure interne et à sa méthode d'enregistrement des données. La structure de données classique pour retrouver simplement un élément est "la table de hachage".
| Chaîne | Code de hachage |
|---|---|
| "Emmanuel" | 1162033930 |
| "emmanuel" | 1097389802 |
| "manu" | 3343963 |
int hashCode() { int hash = 0; for (int i=0; i<length(); i++) hash = 31 * hash + charAt(i); return hash; }
Jusqu'ici, nous n'avons considéré que des ensembles dont les éléments étaient d'un type String ou de classes enveloppes (comme Integer, Double, etc.) pour lesquels, nous n'avions pas à nous préoccuper des détails d'implémentation. Dès que nous cherchons à utiliser des éléments d'un autre type d'objet, il est nécessaire de connaître quelques conséquences de la manière dont les ensembles sont effectivement implémentés. Plus précisément, dans le cas de HashSet, vous devrez définir convenablement :
- la méthode equals() : c'est toujours elle qui sert à définir l'appartenance d'un élément à l'ensemble. si a.equals(b), a et b doivent avoir le même code de hachage.
- la méthode hashCode() dont nous allons voir comment elle est exploitée pour ordonnancer les éléments d'un ensemble.
Les codes de hachage peuvent être calculés très rapidement et ce calcul ne dépend que de l'état de l'objet à hacher, et non des autres objets de la table de hachage.
String s = "Ok"; StringBuilder sb = new StringBuilder(s); System.out.println(s.hashCode() + " " + sb.hashCode()); String t = new String("Ok"); StringBuilder tb = new StringBuilder(t); System.out.println(t.hashCode() + " " + tb.hashCode());
| Chaîne | Code de hachage |
|---|---|
| s | 2556 |
| sb | 20526976 |
| t | 2556 |
| tb | 20527144 |
Sachez que les chaînes s et t présentent le même code de hachage car, pour les chaînes, ces codes sont dérivés de leur contenu. Par contre, les constructeurs de chaînes sb et tb disposent de code de hachage différents car aucune méthode hashCode() n'a pas été redéfinie pour la classe StringBuilder et la méthode hashCode() de la classe Object dérive le code de hachage de l'adresse mémoire de l'objet.
Si vous redéfinissez la méthode equals(), vous devrez aussi redéfinir la méthode hashCode() pour les objets que l'utilisateur pourraient insérer dans une table de hachage afin qu'il soit facile par la suite de les retrouver rapidement et surtout que deux objets de valeurs identiques puissent produire le même code de hachage, ce que ne fait pas la méthode hashCode() de Object.
La méthode hashCode() doit renvoyer un entier. Associez simplement les codes de hachage des attributs de l'objet, de sorte que les codes des différents objets soient plus largement répartis.
seau = codeHachage % NombreDeSeaux
Par exemple, si un objet possède un code de hachage de 76268 et qu'il existe 128 seaux, l'objet sera placé dans le seau 108 (car le reste de la division entière 76268/128 est 108). Avec un peu de chance, il n'existe aucun autre élément dans ce seau. Il suffit alors d'insérer l'élément dans le seau. Naturellement, il est inévitable de trouver parfois un seau déjà utilisé. Cela s'appelle une collision de hachage. Dans ce cas, vous comparez le nouvel objet avec tous les autres objet du seau pour déterminer s'il en fait déjà partie. S'il existe effectivement des éléments dans le seau, le nouvel élément est ajouté à la fin de la liste chaînée correspondante.
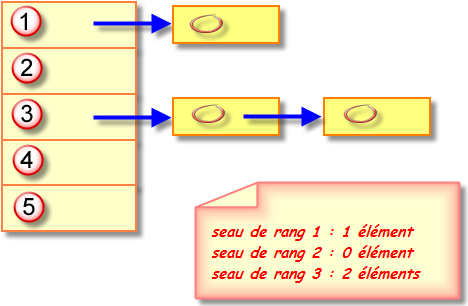
En se fondant sur le fait que les codes de hachage sont distribués aléatoirements et que le nombre de seaux est suffisament grand, il suffit généralement d'effectuer que quelques petites comparaisons.
Si vous désirez contrôler plus finement les performances d'une table de hachage, il est possible de spécifier le nombre initial de seaux. Si trop d'éléments sont insérés dans la table de hachage, le nombre de collisions augmente et les performances de recherche baissent. Comme nous pouvons nous y attendre, le choix du nombre initial de seaux sera fait en fonction du nombre d'éléments prévus pour la collection. On nomme "facteur de charge" le rapport entre le nombre d'éléments de la collection et le nombre de seaux. Plus ce facteur est grand, moins statistiquement, nous obtenons des seaux contenant plusieurs éléments ; par contre, plus il est grand, plus le tableau de références des seaux occupe de l'espace. Généralement, nous choisissons un facteur de charge de l'ordre de 75%. Bien entendu, la méthode de hachage joue également un rôle important dans la bonne répartition des codes des éléments dans les différents seaux.
Pour retrouver un élément de la collection (ou pour savoir s'il est présent), on détermine d'abord son code de hachage. Ensuite la formule seau = codeHachage % NombreDeSeaux donne la valeur du seau dans lequel l'élément est succeptible de se trouver. Il ne reste plus qu'à parcourir les différents éléments du seau pour vérifier si la valeur donnée s'y trouve (à l'aide de la méthode equals()). Notez que nous utilisons cette méthode equals() que pour les seuls éléments qui sont dans le même seau.
Avec Java, les tables de hachage sont automatiquement agrandies dès que leur facteur de charge devient trop grand (supérieur à 75%). Elles sont automatiquement réorganisées avec le double de seaux.
La bibliothèque de collections Java fournit une classe HashSet qui implémente un Set à partir d'une table de hachage. Les éléments sont ajoutés avec la méthode add(). La méthode contains(), que nous connaissons déjà, est redéfinie pour effectuer une recherche rapide et vérifier si un des éléments fait déjà partie du Set. Elle ne vérifie les éléments que d'un seul seau et non tous les éléments de la collection.
L'itérateur d'un Set parcourt tous les seaux un par un. Comme les éléments d'une table de hachage sont dispersés dans toute la table, les seaux sont parcourus dans un ordre pseudo aléatoire. C'est pourquoi, il ne faut utiliser un HashSet que si l'ordre des éléments dans la collection n'a aucune importance.
Après toutes ces considérations techniques, il est temps de prendre un exemple. Je vais reprendre l'application précédente et placer une collection de type HashSet à la place de ArrayList et prévoir ainsi les fonctionnalités justes nécessaires à la gestion de l'ensemble des prénoms. Cette fois-ci, dans cette nouvelle application, un prénom doit être exclusif.
Remarquez
bien que les prénoms se place à priori de façon tout à fait aléatoirement dans la collection.
§
Vu que nous utilisons comme éléments de collection des chaînes de caractères, il n'est pas nécessaire de se préoccuper des méthodes equals() et hashCode().
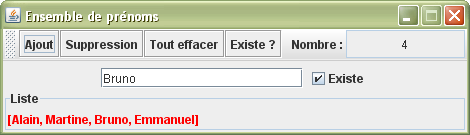
package ensemble; import java.awt.*; import java.awt.event.ActionEvent; import javax.swing.*; import java.util.*; public class Prénoms extends JFrame { private JTextField nouveauPrénom = new JTextField(, 18); private JCheckBox existe = new JCheckBox(); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField nombre = new JTextField(); private HashSet<String> prénoms = new HashSet<String>(); public Prénoms() { super(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.add(nouveauPrénom.getText()); analysePrénoms(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.remove(nouveauPrénom.getText()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.clear(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); nouveauPrénom.addActionListener(ajouter); panneau.add(nouveauPrénom); panneau.add(existe); add(panneau); add(liste, BorderLayout.SOUTH); setSize(470, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analysePrénoms() { liste.repaint(); nombre.setText(+prénoms.size()); existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } public static void main(String[] args) { new Prénoms(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(prénoms.toString()); super.paint(g); } } }
Si nous souhaitons pouvoir définir une égalité des éléments basée sur leur valeur effective, il va donc falloir redéfinir dans la classe correspondante la méthode hashCode(). Elle doit effectivement fournir le code de hachage correspondant à la valeur intrinsèque de l'objet et non plus de son adresse.
Dans la définition de cette méthode hashCode(), il ne faudra pas oublier que le code de hachage doit être compatible avec equals(). Deux objets égaux pour equals() doivent absolument fournir le même code, sinon ils risquent d'aller dans des seaux différents ; dans ce cas, il n'apparaîtrons plus comme égaux (puisque le système recourt à la méthode equals() qu'à l'intérieur d'un même seau). De même, nous ne pouvons nous permettre de redéfinir seulement equals() sans redéfinir la méthode hashCode().
Cette fois-ci, nous allons mettre en oeuvre une nouvelle application qui stocke un ensemble de coordonnées. Ici aussi chaque point doit être exclusif. Je décris une nouvelle classe Coordonnées qui enregistre la valeur de x et de y de la position d'un point.
Remarquez
bien également que les coordonnées du point se placent à priori de façon tout à fait aléatoirement dans la collection.
§
Cette fois-ci, vu que je crée une nouvelle classe, cette dernière doit redéfinir respectivement les méthodes equals(), hashCode() et toString().
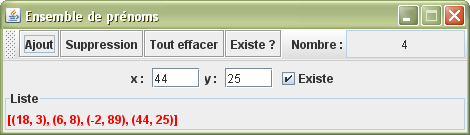
package ensemble; import java.awt.*; import java.awt.event.ActionEvent; import javax.swing.*; import java.util.*; public class EnsemblePoints extends JFrame { private JFormattedTextField abscisse = new JFormattedTextField(0); private JFormattedTextField ordonnée = new JFormattedTextField(0); private JCheckBox existe = new JCheckBox(); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JFormattedTextField nombre = new JFormattedTextField(0); private HashSet<Coordonnées> ensemble = new HashSet<Coordonnées>(); public EnsemblePoints() { super(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { ensemble.add(new Coordonnées((Integer)abscisse.getValue(), (Integer)ordonnée.getValue())); analyse(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { ensemble.remove(new Coordonnées((Integer)abscisse.getValue(), (Integer)ordonnée.getValue())); analyse(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { ensemble.clear(); analyse(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { existe.setSelected(ensemble.contains(new Coordonnées((Integer)abscisse.getValue(), (Integer)ordonnée.getValue()))); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); panneau.add(new JLabel()); abscisse.setColumns(4); panneau.add(abscisse); panneau.add(new JLabel()); ordonnée.addActionListener(ajouter); ordonnée.setColumns(4); panneau.add(ordonnée); panneau.add(existe); add(panneau); add(liste, BorderLayout.SOUTH); setSize(470, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analyse() { liste.repaint(); nombre.setValue(ensemble.size()); existe.setSelected(ensemble.contains(new Coordonnées((Integer)abscisse.getValue(), (Integer)ordonnée.getValue()))); } public static void main(String[] args) { new EnsemblePoints(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(ensemble.toString()); super.paint(g); } } private class Coordonnées { private int x, y; public Coordonnées(int x, int y) { this.x = x; this.y = y; } @Override public boolean equals(Object obj) { Coordonnées c = (Coordonnées) obj; return x==c.x && y==c.y; } @Override public int hashCode() { return x*10001+y; } @Override public String toString() { return +x++y+; } } }
Nous venons de voir comment les ensembles HashSet organisent leurs éléments en table de hachage, en vue de les retrouver rapidement. La classe TreeSet propose une autre organisation utilisant un arbre binaire, lequel permet d'ordonner totalement les éléments. Nous utilisons, cette fois-ci, la relation d'ordre ususelle induite par la méthode compareTo() ou par un comparateur personnalisé.
Dans ces conditions, la recherche dans cet arbre d'un élément particulier est généralement moins rapide que dans la table de hachage mais tout de même plus rapide qu'une recherche séquentielle, comme avecun ArrayList ou avec un LinkedList. Par ailleurs, l'utilisation d'un arbre binaire permet de disposer en permanence d'un ensemble totalement ordonné (trié).
Nous noterons d'ailleurs que la classe TreeSet dispose de deux méthodes spécifiques : first() et last() fournissant respectivement le premier et le dernier élément de l'ensemble.
Nous noterons bien que, dans un ensemble TreeSet, la méthode equals() n'intervient ni dans l'organisation de l'ensemble, ni dans le test d'appartenance d'un élément. L'égalité est définie uniquement à l'aide de la méthode compareTo() (ou d'un comparateur personnalisé). Dans un ensemble HashSet, la méthode equals() intervenait (mais uniquement pour des éléments de même numéro de seau).
La classe TreeSet ressemble beaucoup à la classe HashSet, avec une amélioration supplémentaire. Les arbres de hachage représentent des collections triées. Vous pouvez insérer des éléments dans la collection dans n'importe quel ordre, et lorsque vous parcourez ces éléments, ils sont automatiquement présentés selon un ordre croissant. Comme le nom de la classe le laisse entendre, le tri est accompli par une structure de données en arbre.
Reprenons tout de suite l'exemple sur la gestion des prénoms. Cette fois-ci, notre ensemble de prénoms sera ordonné dans la collection. Pour aboutir à ce résultat, il suffit tout simplement de remplacer la classe HashSet par la classe TreeSet lors de la déclaration de la collection. Pour le reste, nous pouvons conserver la même gestion.
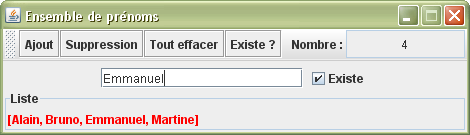
package ensemble; import java.awt.*; import java.awt.event.ActionEvent; import javax.swing.*; import java.util.*; public class Prénoms extends JFrame { private JTextField nouveauPrénom = new JTextField(, 18); private JCheckBox existe = new JCheckBox(); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField nombre = new JTextField(); private TreeSet<String> prénoms = new TreeSet<String>(); public Prénoms() { super(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.add(nouveauPrénom.getText()); analysePrénoms(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.remove(nouveauPrénom.getText()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.clear(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); nouveauPrénom.addActionListener(ajouter); panneau.add(nouveauPrénom); panneau.add(existe); add(panneau); add(liste, BorderLayout.SOUTH); setSize(470, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analysePrénoms() { liste.repaint(); nombre.setText(+prénoms.size()); existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } public static void main(String[] args) { new Prénoms(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(prénoms.toString()); super.paint(g); } } }
Depuis Java SE 6, les ensembles TreeSet implémentent en outre l'interface NavigableSet qui prévoit des méthodes exploitant l'ordre total induit par l'organisation de l'ensemble (en un arbre binaire). Ces méthodes peuvent retrouver et, éventuellement, de supprimer l'élément le plus petit ou le plus grand au sens de cet ordre, ou encore de trouver l'élément le plus proche (avant ou après) d'une valeur donnée. Il est possible de parcourir les éléments dans l'ordre inverse de l'ordre naturel. Enfin, certaines méthodes permettent d'obtenir une vue (cette notion sera présentée ultérieurement) d'une partie de l'ensemble, formée des éléments de valeur supérieure ou inférieure à une valeur donnée.
Comment TreeSet (ou TreeMap dans le chapitre suivant) sait-il dans quel ordre trier les éléments ? Par défaut, cette structure de données part de l'hypothèse que vous insérez des éléments qui implémentent l'interface Comparable, ce qui est d'ailleurs le cas des classes que nous avons déjà utilisé comme la classe Integer ou la classe String.
import java.util.*; import static java.lang.System.*; public class Liste { public static void main(String[] args) { Personne schmidt, lagafe; TreeSet<Personne> ensemble = new TreeSet<Personne>(); out.println("ensemble vide ? "+ensemble.isEmpty()); ensemble.add(lagafe = new Personne("LAGAFE", "Gaston", 23)); ensemble.add(new Personne("GUILLEMET", "Virgule", 13)); ensemble.add(schmidt = new Personne("SCHMIDT", "Jules", 30)); ensemble.add(new Personne("GUILLEMET", "Virgule", 13)); ensemble.add(new Personne("TALON", "Achille", 13)); afficheEnsemble(ensemble); if (ensemble.contains(schmidt)) ensemble.remove(schmidt); afficheEnsemble(ensemble); ensemble.add(lagafe); afficheEnsemble(ensemble); ensemble.clear(); out.println("Taille de ensemble : "+ensemble.size()); } public static void afficheEnsemble(TreeSet<Personne> ensemble) { out.print("ensemble = { "); for(Personne valeur : ensemble) out.println(valeur+" "); out.println("} : nombre = "+ensemble.size()); } } class Personne { private String nom, prénom; private int âge; public Personne(String nom, String prénom, int âge) { this.nom = nom; this.prénom = prénom; this.âge = âge; } public String getNom() { return nom; } public String getPrénom() { return prénom; } public int getÂge() { return âge; } }
Compare cet objet avec un autre objet et renvoie une valeur négative si this est inférieur à autre, nulle si les deux objets sont identiques au sens de l'ordre de tri et positive si this est supérieur à autre.
L'appel a.compareTo(b) doit renvoyer 0 si a et b sont égaux, un nombre entier négatif si a est inférieur à b (selon l'ordre de tri choisi), et un nombre entier positif si a est supérieur à b. La valeur exacte renvoyée par cette méthode n'a pas grande importance. Seul son signe (>0, 0 ou <0) a une signification. Plusieurs classes de la plate-forme standard implémentent l'interface Comparable. La classe String en est un bon exemple. Sa méthode compareTo() compare les chaînes selon l'ordre du dictionnaire (aussi appelé lexicographique).
Si vous insérez vos propres objets, il vous faut définir un ordre de tri en implémentant l'interface Comparable. Il n'existe aucune implémentation par défaut de compareTo() dans la classe Object.
init:
deps-jar:
Compiling 1 source file to C:\netbeans-5.0\travail\Liste\build\classes
compile:
run:
ensemble vide ? true
ensemble {
...GUILLEMET Virgule : 13
...LAGAFE Gaston : 23
...SCHMIDT Jules : 30
...TALON Achille : 13
} : nombre = 4
ensemble {
...GUILLEMET Virgule : 13
...LAGAFE Gaston : 23
...TALON Achille : 13
} : nombre = 3
ensemble {
...GUILLEMET Virgule : 13
...LAGAFE Gaston : 23
...TALON Achille : 13
} : nombre = 3
Taille de ensemble : 0
BUILD SUCCESSFUL (total time: 0 seconds)
import java.util.*; import static java.lang.System.*; public class Liste { public static void main(String[] args) { Personne schmidt, lagafe; TreeSet<Personne> ensemble = new TreeSet<Personne>(); out.println("ensemble vide ? "+ensemble.isEmpty()); ensemble.add(lagafe = new Personne("LAGAFE", "Gaston", 23)); ensemble.add(new Personne("GUILLEMET", "Virgule", 13)); ensemble.add(schmidt = new Personne("SCHMIDT", "Jules", 30)); ensemble.add(new Personne("GUILLEMET", "Virgule", 13)); ensemble.add(new Personne("TALON", "Achille", 13)); afficheEnsemble(ensemble); if (ensemble.contains(schmidt)) ensemble.remove(schmidt); afficheEnsemble(ensemble); ensemble.add(lagafe); afficheEnsemble(ensemble); ensemble.clear(); out.println("Taille de ensemble : "+ensemble.size()); } public static void afficheEnsemble(TreeSet<Personne> ensemble) { out.println("ensemble { "); for(Personne p : ensemble) out.println("..."+p.getNom()+" "+p.getPrénom()+" : "+p.getÂge()); out.println("} : nombre = "+ensemble.size()); } } class Personne implements Comparable<Personne> { private String nom, prénom; private int âge; public Personne(String nom, String prénom, int âge) { this.nom = nom; this.prénom = prénom; this.âge = âge; } public String getNom() { return nom; } public String getPrénom() { return prénom; } public int getÂge() { return âge; } public int compareTo(Personne p) { if (!nom.equalsIgnoreCase(p.nom)) return nom.compareToIgnoreCase(p.nom); if (!prénom.equalsIgnoreCase(p.prénom)) return prénom.compareToIgnoreCase(p.prénom); return âge - p.âge; } }
Il est bien évident que l'utilisation de l'interface Comparable pour définir un ordre de tri possède certaines limitations. Cette interface ne peut être implémentée qu'une seule fois. Mais que peut-on faire pour trier un ensemble d'articles selon leur numéro de code dans une collection, et en fonction de leur description dans une autre ? De plus que pouvez-vous faire pour trier des objets d'une classe dont le concepteur n'a pas pris le soin d'implémenter l'interface Comparable ?
Dans ces situations, il faut demander à la collection de recourir à une autre méthode de comparaison, en passant un objet qui implémente l'interface Comparator dans le constructeur TreeSet (ou MapSet). L'interface Comparator déclare une méthode compare().
Compare deux objets et renvoie une valeur négative si a est inférieur à b, nulle si les deux objets sont identiques au sens de l'ordre de tri et positive si a est supérieur à b.
Comme la méthode compareTo(), la méthode compare() renvoie une valeur entière négative si a et inférieure à b, nulle si a et b sont identiques, et positive dans le dernier cas.
Reprenons le même exemple et remplaçons l'interface Comparable par l'interface Comparator :
init:
deps-jar:
Compiling 1 source file to C:\netbeans-5.0\travail\Liste\build\classes
compile:
run:
ensemble vide ? true
ensemble {
...GUILLEMET Virgule : 13
...LAGAFE Gaston : 23
...SCHMIDT Jules : 30
...TALON Achille : 13
} : nombre = 4
ensemble {
...GUILLEMET Virgule : 13
...LAGAFE Gaston : 23
...TALON Achille : 13
} : nombre = 3
ensemble {
...GUILLEMET Virgule : 13
...LAGAFE Gaston : 23
...TALON Achille : 13
} : nombre = 3
Taille de ensemble : 0
BUILD SUCCESSFUL (total time: 0 seconds)
import java.util.*; import static java.lang.System.*; public class Liste { public static void main(String[] args) { Personne schmidt, lagafe; TreeSet<Personne> ensemble = new TreeSet<Personne>(new TrierPersonne()); out.println("ensemble vide ? "+ensemble.isEmpty()); ensemble.add(lagafe = new Personne("LAGAFE", "Gaston", 23)); ensemble.add(new Personne("GUILLEMET", "Virgule", 13)); ensemble.add(schmidt = new Personne("SCHMIDT", "Jules", 30)); ensemble.add(new Personne("GUILLEMET", "Virgule", 13)); ensemble.add(new Personne("TALON", "Achille", 13)); afficheEnsemble(ensemble); if (ensemble.contains(schmidt)) ensemble.remove(schmidt); afficheEnsemble(ensemble); ensemble.add(lagafe); afficheEnsemble(ensemble); ensemble.clear(); out.println("Taille de ensemble : "+ensemble.size()); } public static void afficheEnsemble(TreeSet<Personne> ensemble) { out.println("ensemble { "); for(Personne p : ensemble) out.println("..."+p.getNom()+" "+p.getPrénom()+" : "+p.getÂge()); out.println("} : nombre = "+ensemble.size()); } } class Personne { private String nom, prénom; private int âge; public Personne(String nom, String prénom, int âge) { this.nom = nom; this.prénom = prénom; this.âge = âge; } public String getNom() { return nom; } public String getPrénom() { return prénom; } public int getÂge() { return âge; } } class TrierPersonne implements Comparator<Personne> { public int compare(Personne p1, Personne p2) { if (!p1.getNom().equalsIgnoreCase(p2.getNom())) return p1.getNom().compareToIgnoreCase(p2.getNom()); if (!p1.getPrénom().equalsIgnoreCase(p2.getPrénom())) return p1.getPrénom().compareToIgnoreCase(p2.getPrénom()); return p1.getÂge() - p2.getÂge(); } }
Remarquons au passage que l'objet qui représente l'implémentation de Comparator est passé au constructeur de l'arbre. Si vous construisez un arbre avec un comparateur, il se sert de cet objet même s'il doit comparer deux éléments.
EnumSet est une implémentation efficace d'un ensemble, dont les éléments appartiennent à un type énuméré. Un type énuméré ayant un nombre fini d'instances, EnumSet est implémenté en interne sous la forme d'une suite de bits. Un bit est activé si la valeur correspondante est présente dans l'ensemble.
enum Semaine {LUNDI, MARDI, MERCREDI, JEUDI, VENDREDI, SAMEDI, DIMANCHE}; EnumSet<Semaine> touslesjours = EnumSet.allOf(Semaine.class); EnumSet<Semaine> aucunjours = EnumSet.noneOf(Semaine.class); EnumSet<Semaine> jourstravail = EnumSet.range(Semaine.LUNDI, Semaine.VENDREDI); EnumSet<Semaine> weekend = EnumSet.of(Semaine.SAMEDI, Semaine.DIMANCHE);
Pour modifier un EnumSet, vous pouvez utiliser les méthodes habituelles de l'interface Set.
§
Pour en savoir plus sur les énumérations.
§
A titre d'exemple, nous allons mettre en oeuvre un ensemble qui stoque les jours de la semaine.
package ensemble; import java.awt.*; import java.awt.event.ActionEvent; import javax.swing.*; import java.util.*; public class Semaine extends JFrame { private JCheckBox existe = new JCheckBox(); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField nombre = new JTextField(); private enum Jours {Lundi, Mardi, Mercredi, Jeudi, Vendredi, Samedi, Dimanche}; private JComboBox nouveauJour = new JComboBox(Jours.values()); private EnumSet<Jours> jours = EnumSet.noneOf(Jours.class); public Semaine() { super(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { jours.add((Jours) nouveauJour.getSelectedItem()); analyseJours(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { jours.remove((Jours) nouveauJour.getSelectedItem()); analyseJours(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { jours.clear(); analyseJours(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { existe.setSelected(jours.contains((Jours) nouveauJour.getSelectedItem())); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); nouveauJour.addActionListener(ajouter); panneau.add(nouveauJour); panneau.add(existe); add(panneau); add(liste, BorderLayout.SOUTH); setSize(400, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analyseJours() { liste.repaint(); nombre.setText(+jours.size()); existe.setSelected(jours.contains((Jours) nouveauJour.getSelectedItem())); } public static void main(String[] args) { new Semaine(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(jours.toString()); super.paint(g); } } }
Il reste un dernier ensemble, un peu particulier, qui se souvient de l'ordre d'insertion des éléments. De cette manière, vous évitez l'ordre assez aléatoire des éléments dans la table de hachage. A mesure que des entrées sont insérées dans la table, elles sont simplement reliées ensemble dans une liste doublement chaînée. Cet ensemble est implémenté par la classe LinkedHashSet.
Nous allons tout de suite prendre un exemple puisque cette collection ne présente rien de bien nouveau si ce n'est sa petite particularité. Je vais reprendre l'application précédente sur la gestion des prénoms et placer une collection de type LinkedHashSet à la place de HashSet. Comme toujours, dans les ensembles, un prénom doit être exclusif.
Remarquez
bien que cette fois-ci les prénoms se place dans la collection suivant l'ordre d'insertion.
§
package ensemble; import java.awt.*; import java.awt.event.ActionEvent; import javax.swing.*; import java.util.*; public class Prénoms extends JFrame { private JTextField nouveauPrénom = new JTextField(, 18); private JCheckBox existe = new JCheckBox(); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField nombre = new JTextField(); private LinkedHashSet<String> prénoms = new LinkedHashSet<String>(); public Prénoms() { super(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.add(nouveauPrénom.getText()); analysePrénoms(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.remove(nouveauPrénom.getText()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.clear(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); nouveauPrénom.addActionListener(ajouter); panneau.add(nouveauPrénom); panneau.add(existe); add(panneau); add(liste, BorderLayout.SOUTH); setSize(470, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analysePrénoms() { liste.repaint(); nombre.setText(+prénoms.size()); existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } public static void main(String[] args) { new Prénoms(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(prénoms.toString()); super.paint(g); } } }
Les queues implémentent les files d'attente.
Les queues sont utilisées si vous devez enregistrer des objets et les récupérer selon la règle "premier entré, premier sortie" (FIFO - First In First Out)
Il en existe de plusieurs sortes :
Comme nous l'avons déjà découvert au tout début de l'étude des collections, il existe une interface Queue, dérivée de l'interface Collection, destinée à la gestion des files d'attente (ou queues). Il s'agit d'une structure dans laquelle nous pouvons :
Il est impossible d'ajouter ou de supprimer des éléments au milieu de la file d'attente.
§
Une queue à deux extrémités permet d'ajouter ou de supprimer efficacement des éléments en début et à la fin. Java 6 a introduit une nouvelle interface Deque, dérivée de Queue, destinée à gérer les files d'attente à double entrée, c'est-à-dire dans lesquelles nous pouvons réaliser l'une des opérations suivantes à l'une des extrémités de la queue :
Il est impossible d'ajouter ou de supprimer des éléments au milieu de la file d'attente.
§
Pour chacune de ces possibilités (3 actions, 2 extrémités), il existe deux méthodes :
A noter que les méthodes de l'interface Queue restent utilisables, sachant que celles d'ajout agissent sur la queue, tandis que celles d'examen ou de suppression agissent sur la tête.
Il existe trois classes qui sont capables d'implémenter l'une de ces interface :
Cette classe LinkedList a été modifiée par le Java 5, pour y intégrer les nouvelles méthodes de l'interface Queue. Depuis Java 6, cette classe implémente également l'interface Deque disposant de méthodes d'action à la fois sur le début et la fin de la liste.
Comme son non l'indique, la classe ArrayDeque implément l'interface Deque. Il s'agit donc d'une implémentation d'une queue à double entrée sous forme d'un tableau (éléments contigus en mémoire) redimensionnable à volonté (comme l'est l'ArrayList). On notera bien que, malgré son nom, cette classe n'est pas destinée à concurencer ArrayList, car elle ne dispose pas d'opérateur d'accès direct à un élément. Il s'agit simplement d'une impémentation plus efficace que LinkedList pour une queue à double entrée.
Pourquoi choisir une implémentation plutôt qu'une autre ? Une interface ne fournit aucun détail quant à l'efficacité de son implémentation. De manière générale, un tableau circulaire est plus efficace qu'une liste chaînée, et il est donc préférable à cette dernière. Toutefois, comme d'habitude, il y a un prix à payer. Les tableaux circulaires font partie d'une collection bornée, qui a une capacité déterminée. Si vous ne connaissez pas la limite maximale du nombre d'objets stockés par votre programme, vous préférerez probablement une implémentation en liste chaînée.
En étudiant la documentation de l'API, vous découvrirez un autre jeu de classes dont le nom commence par Abstract, comme AbstractQueue. Ces classes sont destinées aux implémentations de bibliothèque. Pour implémenter votre propre classe de queue, il sera plus facile d'étendre AbstractQueue que d'implémenter toutes les méthodes de l'interface Queue.
Pour éviter de mettre en oeuvre une nouvelle application, je reprends l'application précédente pour gérer une simple queue de prénoms. La file d'attente est implémentée par la classe ArrayDeque mais je ne me sert que d'une queue à simple entrée. Cette fois-ci, lorsque que nous supprimons un prénom de la queue, elle s'affiche dans la zone d'édition.
Remarquez
bien que les prénoms se place dans la collection suivant l'ordre d'insertion. La suppression se fait uniquement sur les premiers entrés
§
... public class Prénoms extends JFrame { private JTextField nouveauPrénom = new JTextField(, 18); private JCheckBox existe = new JCheckBox(); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField nombre = new JTextField(); private ArrayDeque<String> prénoms = new ArrayDeque<String>(); public Prénoms() { super(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.offer(nouveauPrénom.getText()); analysePrénoms(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { nouveauPrénom.setText(prénoms.poll()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.clear(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } }); ... }
Une queue de priorité récupère des éléments triés, après qu'ils ont été insérés dans un ordre arbitraire. Ainsi, dès que vous appelez la méthode remove(), vous obtenez le plus petit élément se trouvant dans la queue. Celle-ci ne trie toutefois pas tous ses éléments. Si vous parcourez les éléments, ils ne sont pas nécessairement triés. La queue de priorité fait usage d'une structure de données efficace et élégante, appelée un tas. Il s'agit d'une arborescence binaire dans laquelle les opérations add() et remove() amènent l'élément le plus petit à graviter autour de la racine, sans perdre de temps à trier tous les éléments.
A l'instar d'un TreeSet, une queue de priorité peut contenir soit les éléments d'une classe qui implémente l'interface Comparable, soit un objet Comparator que vous fournissez dans le constructeur.
Ces queues servent généralement à planifier les tâches. Chaque tâche se voit attribuer une priorité et elles sont ajoutées dans un ordre aléatoire. Dès le démarrage possible d'une nouvelle tâche, celle ayant la plus haute priorité est supprimée de la queue (la priorité 1 étant généralement la plus forte, l'opération de suppression concerne le plus petit élément).
Je reprends de nouveau l'application sur la file d'attente des prénoms. Cette fois-ci toutefois, la file d'attente est implémentée par la classe PriorityQueue. Ainsi, lorsque que nous supprimons un prénom de la queue, il s'agit toujours de celui qui est le premier dans l'ordre alphabétique.
Au moment de l'insertion, tous les prénoms ne sont pas spécialement dans l'ordre alphabétique, sauf pour le premier. Lorsque nous commençons à supprimer des éléments, un arrangement s'effectue pour être sûr que le suivant soit bien le nouveau premier dans l'ordre alphabétique.
... public class Prénoms extends JFrame { private JTextField nouveauPrénom = new JTextField(, 18); private JCheckBox existe = new JCheckBox(); private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField nombre = new JTextField(); private PriorityQueue<String> prénoms = new PriorityQueue<String>(); public Prénoms() { super(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.offer(nouveauPrénom.getText()); analysePrénoms(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { nouveauPrénom.setText(prénoms.poll()); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { prénoms.clear(); analysePrénoms(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { existe.setSelected(prénoms.contains(nouveauPrénom.getText())); } }); ... }
Un Set (ensemble) est une collection qui vous permet de retrouver rapidement un élément. Pour cela, il faut le connaître exactement, ce qui n'est pas souvent le cas. En fait, nous disposons généralement de certaines informations importantes sur l'élément à rechercher, et il faut le retrouver à partir de ces informations.
On notera que les ensembles (Set) déjà étudiés sont des cas particuliers de telles tables, dans lesquels la valeur serait vide.
§
La bibliothèque Java propose deux implémentations générales des cartes : HashMap et TreeMap (Une HashMap répartit les clés dans plusieurs catégories, alors que la TreeMap se sert d'un ordre total pour organiser les clés dans un arbre de recherche). Ces deux classes gèrent des collections d'éléments accessibles par une clé correspondant (map en anglais) à un élément. Ces classes mémorisent en fait un ensemble d'entrées (entries) associant une clé et son élément (key-value). L'accès par clé dans une collection est comparable à l'accès par indice dans un tableau.
Comme les clés peuvent être des chaînes de caractères, des instances des classes d'emballage ou d'autres classes, les classes HashMap et TreeMap permettent d'accéder à ces ensembles d'éléments de manière plus élaborée qu'avec un indice entier.
Attention, les clés doivent être uniques. Il n'est également pas permis d'associer deux valeurs à une même clé. Ainsi, par exemple, il n'est pas possible d'avoir plusieurs numéros de téléphone pour une même personne. Il existe toutefois des solutions pour résoudre cet apparente difficulté.
Comme pour les ensembles, l'intérêt des tables associatives est de pouvoir retrouver rapidement une clé donnée pour en obtenir l'information associée. Java dispose de plusieurs classes, avec les deux que nous venons de découvrir, qui implémentent ces différents dictionnaires, chacune ayant sa propre particularité. Dans tous les cas, seule la clé sera utilisée pour ordonnancer les informations.
La classe HashMap mémorise ses entrées dans un ordre quelconque, tandis que la classe TreeMap mémorise ses entrées dans l'ordre ascendant avec un arbre, pour maintenir plus rapidement le tri des éléments stockées. Vous avez ci-dessous d'autres classes qui implémentent également l'interface Map.
Les fonctions de hachage ou de comparaison ne sont appliquées qu'aux clés. Les valeurs associées ne sont ni comparées ni réparties.
§
Construit une carte en arbre et se sert du comparateur pour trier ses clés.
Construit une carte en arbre et y ajoute toutes les entrées de la carte spécifiée.
Construit un arbre, ajoute toutes les entrées de la carte triée et se sert du même comparateur d'éléments que la carte triée.
Renvoie le comparateur servant à trier les clés ou null si les clés sont comparées à l'aide de la méthode compareTo() de l'interface Comparable.
Renvoie la plus petite ou la plus grande clé de la carte.
enum Semaine {LUNDI, MARDI, MERCREDI, JEUDI, VENDREDI, SAMEDI, DIMANCHE}; EnumMap<Semaine, String> alertes = new EnumMap<Semaine, String>(Semaine.class);
Construit une carte vide dont les clés ont le type spécifié.
L'ordre d'accès est utile pour implémenter le système de "la dernière utilisée" pour un cache. Par exemple, vous voulez conserver les entrées fréquemment lues en mémoire et lire des objets lus moins souvent à partir d'une base de données. Lorsqu'une entrée d'une table est introuvable et que la table est déjà assez pleine, vous pouvez obtenir un itérateur dans la table, puis supprimer les premiers éléments qu'elle énumère. Ces entrées étaient les dernières utilisées.
Map<Key, Value> cache = new LinkedHashMap<Key, Value>(64, 0.75F, true) { protected boolean removeEdestEntry(Map.Entry<Key, Value> ancien) { return size() > 100; } }
Vous pouvez également envisager de prendre en compte l'élément ancien pour décider si vous devez le supprimer. Par exemple, vous devrez peut-être vérifier une indication de la date et de l'heure stockée avec l'entrée.
La classe WeakHashMap a été conçue dans le but de résoudre un problème intéressant. Que se passe-t-il avec une valeur lorsque sa clé n'est plus utilisée nulle part dans le programme ? Supposons que la dernière référence à une clé ait disparu. Il n'y a alors plus aucune manière de se référer à l'objet de la valeur. Toutefois, étant donné qu'aucune partie du programme ne possède plus la clé, la paire clé/valeur ne peut être supprimée de la carte. Pourquoi alors le ramasse-miettes ne peut-t-il pas la supprimer ? Ce serait en effet son rôle de supprimer les objets inutilisés.
Malheureusement, la situation n'est pas aussi simple. Le ramasse-miettes suit les objets vivants. Tant que l'objet de carte est vivant, tous les seaux qu'il contient sont également vivants et ils ne seront pas réclamés. Ainsi, votre programme doit supprimer les valeurs inutilisées des cartes vivantes. Vous pouvez également utiliser à la place WeakHashMap. Cette structure de données coopère avec le ramasse-miettes pour supprimer les paires clé/valeur lorsque la seule référence à la clé est la référence de l'entrée de la table de hachage.
Voici en fait le fonctionnement interne de ce mécanisme. WeakHashMap utilise des références faibles pour conserver les clés. Un objet WeakReference contient une référence à un autre objet, dans notre cas, une clé de table de hachage. Les objets de ce type sont considérés de manière particulière par le ramasse-miettes. Normalement, s'il découvre qu'un objet particulier ne possède pas de références vers lui, il réclame simplement l'objet. Toutefois, si l'objet peut être atteint uniquement par un WeakReference, le ramasse-miettes réclame toujours l'objet, mais place la référence faible qui y menait dans une queue. Les opérations du WeakHashMap vérifient périodiquement cette queue pour y retrouver des références faibles nouvellement arrivées. L'arrivée d'une référence faible dans la queue signifie que la clé n'est plus utilisée par personne et qu'elle a été collectée. WeakHashMap supprime alors l'entrée associée.
Java 1.4 a ajouté une autre classe IdentyHashMap pour un autre objectif assez spécialisé, où les valeurs de hachage pour les clés ne doivent pas être calculées par la méthode hashCode() mais par la méthode System.identityHashCode(). C'est la méthode utilisée par Object.hashCode() pour calculer le code de hachage à partir de l'adresse mémoire de l'objet. De même, pour la comparaison des objets, IdentityHashMap utilise ==, et non equals().
En d'autres termes, différents objets de clé sont considérés comme distincts, même s'ils ont un contenu égal. Cette classe est utile pour implémenter des algorithmes object transversal (comme la sérialisation des objets), dans lesquels vous souhaitez effectuer le suivi des objets auxquels on a déjà appliqué traversed.
Toutes les classes que nous venons de décourvrir implémentent l'interface Map qui proposent des fonctionnalités communes et que nous allons maintenant étudier.
Map<String, String> téléphones = new TreeMap<String, String>(); téléphones.put("Virgule GUILLEMET", "08-71-63-18-08");
Les clés doivent être uniques. Il n'est pas permis d'associer deux valeurs à la même clé. Si vous appelez la méthode put() deux fois avec la même clé, la seconde valeur remplace la première. En fait, put() renvoie la dernière valeur correspondant à la clé fournie.
Notez que, comme pour les autres collections, les clés et les valeurs doivent être des objets. Il n'est théoriquement pas nécessaire que toutes les clés soient du même type, pas plus que les éléments. En pratique, ce sera presque toujours le cas pour des questions évidentes de facilité d'exploitation de la table.
String nom = "Virgule GUILLEMET";
String téléphone = téléphones.get(nom); il (téléphone == null) System.out.println("Aucun numéro de téléphone"); else System.out.println("Le numéro de "+nom+" est "+téléphone);
Si aucune information n'est stockée dans la carte pour une clé spécifiée, get() renvoie null.
§
La méthode containsKey() permet de savoir si une clé est présente dans la carte. De la même façon, il est possible de contrôler si une valeur existe dans la carte au moyen de la méthode containsValue().
String ancienNuméro = téléphones.remove(nom); il (ancienNuméro == null) System.out.println("Ce nom "+nom+" n'existe pas"); else System.out.println("Le numéro de "+ancienNuméro+" est supprimé");
Renvoie une vue des objets Map.Entry, contenant les paires clé / valeur de la carte. Vous pouvez supprimer des éléments de cette vue (ils sont alors éliminés de la carte), mais vous ne pouvez pas en ajouter de nouveaux.
Renvoie une vue de toutes les clés de la carte. Lorsque vous supprimez des éléments de cet ensemble, la clé et la valeur associée sont supprimées de la carte. En revanche, vous ne pouvez pas ajouter de nouveaux éléments.
Renvoie une vue de toutes les valeurs de la carte. Vous pouvez supprimer des éléments de cet ensemble (la clé et la valeur associée sont supprimées de la carte), mais vous n'avez pas le droit d'y ajouter de nouveaux éléments.
Il est souvent plus confortable de déclarer la structure de données cartes au travers de l'interface Map<K, V> plutôt que d'utiliser directement les classes HashMap, TreeMap, etc. Effectivement, au travers de cette procédure, il est plus facile ensuite de récupérer chaque entrée séparément.
Les cartes ne sont pas vraiment considérées comme des collections. Effectivement, les classes qui implémentent les cartes ne disposent pas d'itérateurs. Il reste néanmoins possible d'obtenir une vue d'une carte, c'est-à-dire un objet qui implémente l'interface Collection ou l'une de ses sous-interfaces.
Il existe trois vues différentes :
Notons que la méthode keySet() ne délivre pas un HashSet ou un TreeSet, mais il s'agit d'un objet d'une autre classe qui implémente l'interface Set, laquelle étend l'interface Collection. Vous pouvez donc utiliser le résultat de cette méthode comme n'importe quelle autre collection.
L'ensemble des clés et des paires clé / valeur forme un Set parce qu'il ne peut exister qu'un seul exemplaire d'une clé dans une carte. Les éléments de la troisième méthode font partie de la classe interne statique Map.Entry.
A l'aide de la méthode entrySet(), nous pouvons donc facilement voir une carte comme un ensemble de "paire", une paire n'étant rien d'autre qu'un élément de type Map.Entry réunissant deux objets (de types a priori quelconques). Les méthodes getKey() et getValue() de Map.Entry permettent d'extraire respectivement la clé et la valeur d'une paire.
Notez que l'ensemble fourni par la méthode entrySet() n'est pas une copie des informations figurant dans la carte. Il s'agit de ce que nous nommons une "vue". Si nous opérons des modifications dans la carte, elles seront directement perceptibles sur la vue associée. De plus si nous appliquons la méthode remove() à un élément courant (paire) de la vue, nous supprimons du même coup l'élément de la carte. En revanche, il n'est pas permis d'ajouter directement des éléments dans la vue elle-même.
Depuis Java 6, les tables de TreeMap implémentent également l'interface NavigableMap qui prévoit des méthodes exploitant l'ordre total induit sur les clés, par l'organisation en arbre binaire.
Ces méthodes permettent de retrouver et, éventuellement, de supprimer des éléments correspondant à la plus petite ou la plus grande des clés, ou encore de trouver un élément ayant la clé la plus proche (avant ou après) d'une valeur donnée. Il est possible de parcourir les éléments dans l'ordre inverse de l'ordre naturel des clés. Enfin, nous pouvons obtenir une vue d'une partie du map, en se fondant sur la valeur d'une clé qui sert en quelque sorte de "délimiteur".
A titre d'exemple, je vous propose de mettre en oeuvre un répertoire téléphonique dans l'ordre alphabétique. Pour cela j'utilise la classe TreeMap.
Cette classe TreeMap est intéressante à plus d'un titre puisque je peux utiliser toutes ses compétences de navigations à l'aide des méthodes redéfinies issues de l'interface NavigableMap.
package carte; import java.awt.*; import java.awt.event.ActionEvent; import java.text.ParseException; import javax.swing.*; import java.util.*; import javax.swing.text.MaskFormatter; public class Répertoire extends JFrame { private JTextField nom = new JTextField(, 18); private JFormattedTextField téléphone; private Résultat liste = new Résultat(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JTextField nombre = new JTextField(); private TreeMap<String, String> répertoire = new TreeMap<String, String>(); private JComboBox déjàIntroduit = new JComboBox(répertoire.entrySet().toArray()); public Répertoire() throws ParseException { super(); téléphone = new JFormattedTextField(new MaskFormatter()); téléphone.setValue(); nombre.setEditable(false); nombre.setHorizontalAlignment(JLabel.CENTER); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { répertoire.put(nom.getText(),(String) téléphone.getValue()); déjàIntroduit.addItem(répertoire.floorEntry(nom.getText())); analyseCarte(); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { téléphone.setValue(répertoire.get(nom.getText())); analyseCarte(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { déjàIntroduit.removeItem(répertoire.ceilingEntry(nom.getText())); répertoire.remove(nom.getText()); analyseCarte(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { répertoire.clear(); déjàIntroduit.removeAllItems(); analyseCarte(); } }); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); téléphone.addActionListener(ajouter); panneau.add(new JLabel()); panneau.add(nom); panneau.add(new JLabel()); panneau.add(téléphone); panneau.add(new JLabel()); panneau.add(déjàIntroduit); add(panneau); add(liste, BorderLayout.SOUTH); setSize(470, 170); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void analyseCarte() { liste.repaint(); nombre.setText(+répertoire.size()); } public static void main(String[] args) throws ParseException { new Répertoire(); } private class Résultat extends JLabel { public Résultat() { setForeground(Color.RED); setBorder(BorderFactory.createTitledBorder()); } @Override public void paint(Graphics g) { setText(répertoire.toString()); super.paint(g); } } }
Nous allons reprendre le répertoire téléphonique dans l'ordre alphabétique, mais cette fois-ci, il sera possible d'associer plusieurs numéros pour la même personne.
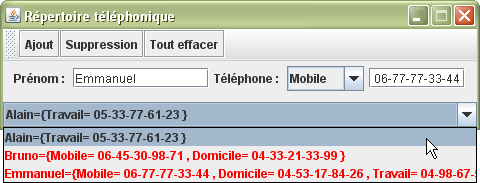
package carte; import java.awt.*; import java.awt.event.ActionEvent; import java.text.ParseException; import javax.swing.*; import java.util.*; import javax.swing.text.MaskFormatter; public class Répertoire extends JFrame { private JTextField prénom = new JTextField(, 12); private JFormattedTextField téléphone; private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JComboBox liste = new JComboBox(); private enum TypeTéléphone {Mobile, Domicile, Travail}; private TreeMap<String, EnumMap<TypeTéléphone, String>> répertoire = new TreeMap<String, EnumMap<TypeTéléphone, String>>(); private JComboBox type = new JComboBox(TypeTéléphone.values()); public Répertoire() throws ParseException { super(); téléphone = new JFormattedTextField(new MaskFormatter()); téléphone.setValue(); liste.setForeground(Color.RED); Action ajouter = new AbstractAction() { public void actionPerformed(ActionEvent e) { EnumMap<TypeTéléphone, String> téléphones; if (répertoire.containsKey(prénom.getText())) { téléphones = répertoire.get(prénom.getText()); téléphones.put((TypeTéléphone)type.getSelectedItem(),(String)téléphone.getValue()); } else { téléphones = new EnumMap<TypeTéléphone, String>(TypeTéléphone.class); répertoire.put(prénom.getText(), téléphones); } téléphones.put((TypeTéléphone)type.getSelectedItem(),(String)téléphone.getValue()); liste.removeAllItems(); for (Map.Entry<String, EnumMap<TypeTéléphone, String>> carte : répertoire.entrySet()) liste.addItem(carte); } }; barre.add(ajouter); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { liste.removeItem(répertoire.ceilingEntry(prénom.getText())); répertoire.remove(prénom.getText()); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { répertoire.clear(); type.removeAllItems(); } }); barre.addSeparator(); add(barre, BorderLayout.NORTH); téléphone.addActionListener(ajouter); panneau.add(new JLabel()); panneau.add(prénom); panneau.add(new JLabel()); panneau.add(type); panneau.add(téléphone); add(panneau); add(liste, BorderLayout.SOUTH); setSize(480, 130); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) throws ParseException { new Répertoire(); } }
Les classes sont regroupées dans une structure appelée cadre (ou framework), qui constitue la base commune pour créer des fonctionnalités avancées. Un cadre contient des superclasses renfermant des fonctionnalités pratiques, des méthodes et des mécanismes. L'utilisateur d'un cadre crée des sous-classes pour étendre les fonctionnalités sans devoir réinventer les mécanismes de base. Par exemple, Swing est un cadre pour les interfaces utilisateurs.
La bibliothèque de collection Java forme un cadre pour les classes de collection. Ce cadre définit un certain nombre d'interfaces et de classes abstraites pour des implémentations de collections et il propose certains mécanismes, comme un protocole d'itération.
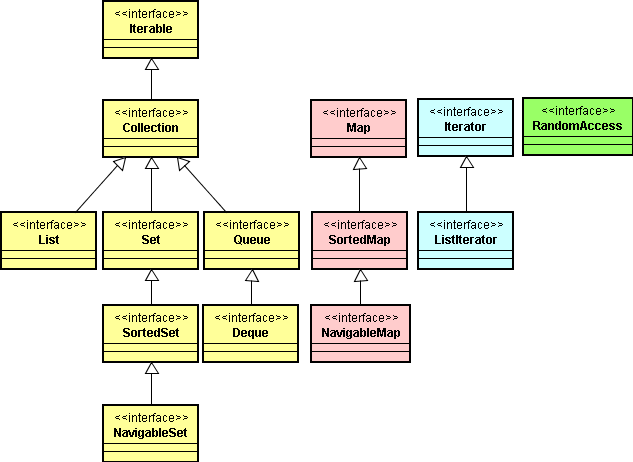
Vous pouvez vous servir des classes de collection sans connaître grand-chose au cadre. C'est exactement ce que nous avons fait dans les chapitres précédents. En revanche, si vous souhaitez implémenter des algorithmes généraux qui fonctionnent sur plusieurs types de collection ou si vous voulez créer un nouveau type de collection, il vaut mieux comprendre le fonctionnement du cadre.
Il existe deux interfaces fondamentales pour les collections : Collection et Map. Suivant le type de collection, nous pouvons :
if (c instanceof RandomAccess) { utiliser un algorithme d'accès direct (aléatoire) } else { utiliser un alogorithme d'accès séquentiel }
Les classes ArrayList et Vector implémentent l'interface RandomAccess. Les élément de ces deux classes sont justement contigües en mémoire et permettent d'avoir ainsi un accès direct aléatoire) efficace.
Pourquoi définir une interface séparée si les signatures des méthodes sont les mêmes ? Conceptuellement, toutes les collections ne sont pas des ensembles. La définition d'une interface Set permet aux programmeurs d'écrire des méthodes qui n'acceptent que des ensembles.
Passons maintenant des interfaces aux classes qui les implémentent. Nous avons déjà vu que les interfaces de collections possèdent quelques méthodes qui peuvent être implémentées très simplement à partir d'un nombre plus important de méthodes fondamentales. Les classes abstraites fournissent certaines implémentations de ces routines :
Si vous implémentez votre propre classe de collection, vous voudrez probablement étendre l'une de ces classes pour récupérer les implémentation de ces opérations.
En tout cas, la bibliothèque Java fournit des classes concrètes associées :
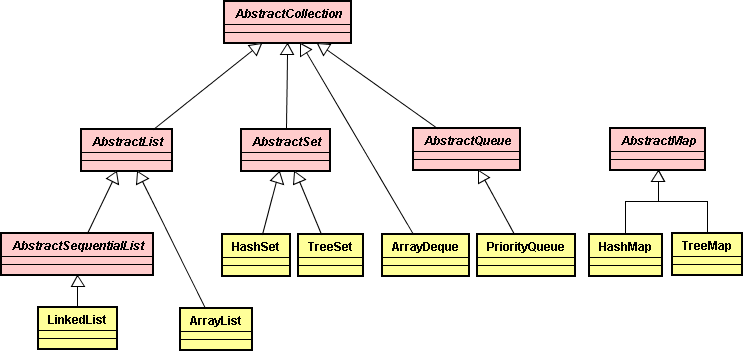
Lorsque nous regardons les deux diagrammes de classes précédents, vous trouverez peut-être qu'il est exagéré d'avoir de nombreuses interfaces et classes abstraites pour implémenter un nombre modeste de collections concrètes. Mais ces diagrammes n'expliquent pas tout. En ayant recours à des vues, vous pouvez obtenir d'autres objets qui implémentent les interfaces Collection ou Map. Nous avons vu un exemple dans le chapitre précédent au moyen de la méthode keySet() des classes de cartes.
Au premier abord, il apparaît que la méthode crée un nouvel ensemble, le remplit avec toutes les clés de la carte, puis renvoie l'ensemble. Mais ce n'est pas exactement ce qui se passe. En fait, la méthode keySet() renvoie un objet d'une classe qui implémente l'interface Set et dont les méthodes permettent de manipuler la carte d'origine. Ce type de collection est appelée une vue.
La technique des vues possède un certain nombre d'applications pratiques dans le cadre des collections. Nous verrons ces applications dans les sections suivantes.
String[] prénoms = new String[52];
List<String> listePrénoms = Arrays.asList(prénoms);
L'objet renvoyé n'est pas un ArrayList, c'est un objet vue avec des méthodes get() et set() qui accèdent au tableau sous-jacent. Toutes les méthodes capables de modifier la taille du tableau (comme add() et la méthode remove() de l'itérateur associé) déclenchent une UnsupportedOperationException.
List<String> listePrénoms = Arrays.asList("Bruno", "Alain", "Emmanuel");
List<String> réglages = Collections.nCopies(100, "Défaut");
Le stockage se révèle peu coûteux, l'objet n'est stocké qu'une fois. C'est une bonne application de la technique d'affichage.
§
La classe Collections contient un certain nombre de méthodes commodes dont les paramètres ou les valeurs renvoyées constituent des collections. Attention à ne pas les confondre avec l'interface Collection.
Les méthodes singletonList() et singletonMap() se comportent de la même manière.
§
Vous pouvez créer des vues de sous-ensembles pour un certain nombre de collection :
List<String> listePrénoms = ...;
List<String> quelques = listePrénoms.subList(10, 20);
Le premier indice est inclusif et le second exclusif, exactement comme les paramètres de la méthode substring() de la classe String.
§
List<String> listePrénoms = ...;
List<String> quelques = listePrénoms.subList(10, 20);
quelques.clear();
Ainsi, les éléments sont automatiquement effacés de la liste listePrénoms et quelques devient vide.
§
Celles-ci renvoient les sous-ensembles de tous les éléments supérieurs ou égaux à l'argument de et strictement inférieur à to.
§
La classe Collections possède des méthodes qui produisent des vues non modifiables de collections. Ces vues ajoutent à une collection existante une vérification se produisant en cours d'exécution. Si une tentative de modification de la collection est détectée, une exception est déclenchée et la collection demeure inchangée.
Les vues non modifiables s'obtiennent au travers de six méthodes :
Chaque méthode est défini de manière à fonctionner sur une interface. Collections.unmodifiableList(), par exemple, fonctionne avec un ArrayList, un LinkedList ou toute autre classe qui implémente l'interface List.
List<String> listePrénoms = new ArrayList<String>();
...
List<String> vue = new Collections.unmodifiableList(listPrénoms);
La méthode Collections.unmodifiableList() renvoie un objet d'une classe implémentant l'interface List. Sa méthode d'accès recherche des valeurs de la collection listePrénoms. Naturellement, la vue peut appeler toutes les méthodes de l'interface List et pas seulement les méthodes d'accès. Mais toutes les méthodes de modification (comme add()) sont redéfinies pour lancer une UnsupportedOperationException au lieu de propager l'appel à la collection sous-jacente.
La vue non modifiable ne rend pas la collection inaltérable. Vous pouvez toujours la modifier via sa référence initiale (listePrénoms dans notre cas). Vous pouvez toujours appeler des méthodes de modification sur les éléments de la collection.
Puisque les vues enveloppent l'interface et non l'objet de collection réel, vous n'avez accès qu'aux méthodes définies dans l'interface. Ainsi, la classe LinkedList possède des méthodes, addFirst() et addLast(), qui ne font pas parties de l'interface List. Ces méthodes ne sont pas accessibles par la vue non modifiable.
Si vous accédez à une collection depuis plusieurs threads, il est très important que la collection ne soit pas accidentellement endommagée. Par exemple, il serait désastreux qu'un thread tente d'ajouter un élément dans une table de hachage alors qu'un autre thread essaierait d'en réorganiser les éléments.
Map<String, String> téléphones = Collections.synchronisedMap(new TreeMap<String, String>());
Vous pourrez dorénavant accéder à l'objet téléphones depuis plusieurs threads. Les méthodes comme get() et put() sont synchronisées, c'est-à-dire que chaque appel à l'une d'elles doit être entièrement terminé avant qu'un autre thread puisse appeler une autre méthode.
Jusqu'à maintenant, la plupart de nos exemples se servaient d'un itérateur pour parcourir un par un les éléments d'une collection. Mais, il est possible d'éviter de parcourir tous ces éléments en ayant recours à l'une des opérations de masse (ou bulk operation) de la bibliothèque.
Set<String> résultat = new HashSet<String>(premier);
résultat.retainAll(deuxième);
Nous utilisons ici le fait que toutes les collections possèdent un constructeur dont les paramètres sont une autre collection renfermant des valeurs d'initialisation. Cette méthode retainAll() conserve tous les éléments qui sont aussi dans deuxième. Nous venons de déterminer l'intersection sans programmer de boucle.
Map<String, String> téléphones = ...;
Set<String> suppressions = ...;
téléphones.keySet().removeAll(suppressions);
Comme l'ensemble de clés constitue une vue de la carte, les clés (prénoms) et les numéros de téléphone associés sont automatiquement supprimés de la carte.
récupération.addAll(ensemble.subList(0, 10));
Le sous-ensemble peut aussi être la cible d'une opération de mutation :ensemble.subList(0, 10).clear();
Comme une grande partie de l'API de la plate-forme Java a été conçue avant l'introduction du cadre des collections, vous aurez parfois besoin d'adapter les anciens tableaux en collections plus récentes.
String[ ] tableau = ...;
HashSet<String> collection = new HashSet<String>(Arrays.asList(tableau));
Object[ ] tableau = collection.toArray();
Malheureusement, cette méthode donne un tableau d'objets. Même si vous savez que votre collection contient des objets d'un type spécifique, vous ne pouvez pas recourir à une conversion de type :String[ ] tableau = (String[ ]) collection.toArray(); // erreur
Le tableau renvoyé par la méthode toArray() a été créé comme un tableau Object[], et son type ne peut être modifié. Pour contourner ce problème, vous utilisez une variante de la méthode toArray(). Passez-lui un tableau de longueur nulle et du type qui vous intéresse.
Le tableau créé est du même type que le type spécifié :String[ ] tableau = collection.toArray(new String[0]);
Si vous le souhaitez, vous pouvez construire le tableau, de sorte qu'il ait la bonne taille. Dans ce cas, aucun nouveau tableau n'est créé :collection.toArray(new String[collection.size()]);
La classe Collections fournit, sous formes statiques, des méthodes utilitaires générales applicables aux collections, notamment :
Ces méthodes disposent d'arguments d'un type interface Collection ou List. Dans le premier cas, l'argument effectif pourra être une collection quelconque. Dans le second cas, il devra s'agir obligatoirement d'une liste chaînée (LinkedList) ou d'un vecteur dynamique (ArrayList).
La classe Collections contient plusieurs algorithmes simples, mais très utiles. Nous retrouvons notamment parmi ces algorithmes la recherche de la valeur minimale ou maximale d'une collection. Les autres algorithmes convrent des sujets aussi variés que la copie des éléments d'une liste dans une autre liste, le remplissage d'un conteneur avec une valeur constante, ou l'inversion d'une liste.
Pourquoi fournir des algorithmes aussi simples dans une bibliothèque standard ? Il est probable que la plupart des programmeurs pourraient les implémenter facilement avec des boucles simples. Nous aimons bien ces algorithmes, car ils simplifient la vie des programmeurs et surtout parce ce qu'ils augmentent la lisibilté des programmes. Lorsque vous lisez une boucle qui a été implémentée par un autre programmeur, vous devez commencer par décrypter les intensions de ce programmeur. Alors que si vous voyez un appel à une méthode max() de la classe Collections, vous devinez immédiatement ce que réalise cette instruction.
La classe Collections dispose de méthodes sort() qui réalisent des algorithmes de tri des éléments d'une collection qui doit, cette fois, implémenter l'interface List. Ses éléments sont réorganisés de façon à respecter l'ordre induit soit par compareTo(), soit par un comparateur personnalisé.
List<String> prénoms = new LinkedList<String>();
...
Collections.sort(prénoms);
Cette méthode sort() part de l'hypothèse que les éléments de la liste implémentent l'interface Comparable. Si vous voulez trier une liste d'une autre manière, vous pouvez spécifier un objet Comparator en second argument.
Nous avons déjà abordé les comparateurs dans la section traitant des ensembles triés.
§
List<String> prénoms = new LinkedList<String>();
...
Collections.sort(prénoms, Collections.reverseOrder());
Cette partie de code trie les prénoms par ordre décroissant, selon l'ordre fourni par la méthode compareTo() du type de l'élément, ici la classe String.
§
List<String> prénoms = new LinkedList<String>();
...
Collections.shuffle(prénoms);
Si vous fournissez une liste qui n'implémente pas l'interface RandomAccess, la méthode shuffle() copie les éléments dans un tableau, mélange le tableau et recopie les éléments mélangés dans la liste.
En principe, pour trouver un objet dans un tableau, il faut parcourir tous ses éléments jusqu'à trouver celui que vous cherchez. Cependant, lorsqu'un tableau est trié, vous pouvez commencer par examiner la valeur de l'élément situé au milieu du tableau et vérifier si cette valeur est supérieure à celle de l'objet que vous cherchez. Dans ce cas, il vous suffit de chercher l'objet dans la première moitié du tableau. Sinon, l'élément cherché se trouve dans la seconde moitié du tableau. Cette opération divise le problème en deux. Vous pouvez alors continuer à chercher l'objet en utilisant la même technique.
Ainsi, si le tableau comprend 1024 éléments, vous trouverez n'importe lequel de ces éléments en 10 étapes au maximum, alors qu'une recherche séquentielle aurait nécessité en moyenne 512 étapes si l'élément cherché fait bien partie du tableau, et il aurait fallu 1024 étapes pour confirmer l'absence d'un élément dans ce tableau.
List<String> prénoms = new ArrayList<String>();
...
int indice = Collections.binarySearch(prénoms, "Emmanuel");
ou
int indice = Collections.binarySearch(prénoms, "Emmanuel", comparateur);
...
String prénom = prénoms.get(indice);
Si la valeur renvoyée par la recherche binaire est supérieure ou égale à zéro, cette valeur correspond à l'indice de l'élément trouvé. C'est-à-dire que collection.get(indice) est égal à l'élément au sens du comparateur. Si la valeur est négative, cela signifie que l'élément n'a pas pu être trouvé dans la collection.
List<String> prénoms = new ArrayList<String>();
...
int indice = Collections.binarySearch(prénoms, "Emmanuel");
...
if (indice<0) prénoms.add(-indice-1, "Emmanuel");
Pour rester valable, une recherche binaire doit bénéficier d'un accès aléatoire aux données de la collection. Si vous devez parcourir tous les éléments jusqu'à la moitié du tableau pour trouver l'élément du milieu, l'avantage principal de la recherche binaire est perdu. Par conséquent, l'algorithme implémenté par la méthode binarySearch() se transforme en recherche linéaire si vous lui fournissez une liste chaînée.
A titre d'exemple, je vous porpose de mettre en oeuvre une application qui permet de recenser l'ensemble des notes à prendre en compte pour calculer une moyenne, ansi que de connaître automatiquement, la note la plus haute, la plus basse, etc.
package listes; import java.awt.*; import java.awt.event.*; import java.text.*; import javax.swing.*; import java.util.*; public class Notes extends JFrame { private JFormattedTextField nouvelleNote = new JFormattedTextField(NumberFormat.getNumberInstance()); private JCheckBox ordre = new JCheckBox(); private JCheckBox présente = new JCheckBox(); private JLabel liste = new JLabel(); private JPanel panneau = new JPanel(); private JToolBar barre = new JToolBar(); private JLabel nombre = new JLabel(); private ArrayList<Double> notes = new ArrayList<Double>(); public Notes() { super(); liste.setForeground(Color.RED); liste.setBorder(BorderFactory.createTitledBorder()); nombre.setForeground(Color.RED); nombre.setHorizontalAlignment(JLabel.CENTER); AbstractAction ajout = new AbstractAction() { public void actionPerformed(ActionEvent e) { notes.add(valeurNote()); analyseNotes(); } }; barre.add(ajout); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { notes.remove(valeurNote()); analyseNotes(); } }); barre.add(new AbstractAction() { public void actionPerformed(ActionEvent e) { Collections.sort(notes); présente.setSelected(Collections.binarySearch(notes, valeurNote())>=0); } }); nouvelleNote.setColumns(5); nouvelleNote.addActionListener(ajout); barre.addSeparator(); barre.add(new JLabel()); barre.add(nombre); add(barre, BorderLayout.NORTH); panneau.add(new JLabel()); panneau.add(nouvelleNote); panneau.add(ordre); panneau.add(présente); présente.setEnabled(false); ordre.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { if (ordre.isSelected()) Collections.sort(notes); else Collections.shuffle(notes); analyseNotes(); } }); add(panneau); add(liste, BorderLayout.SOUTH); setSize(480, 135); setLocationRelativeTo(null); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public double valeurNote() { Number valeur = (Number) nouvelleNote.getValue(); return valeur.doubleValue(); } public void analyseNotes() { double plusBasse = Collections.min(notes); double plusHaute = Collections.max(notes); double somme = 0.0; for (double note : notes) somme+=note; double moyenne = notes.size()!=0 ? somme/notes.size() : 0.0; nombre.setText(MessageFormat.format(, notes.size(), plusBasse, plusHaute)); liste.setText(MessageFormat.format(, notes.toString(), moyenne)); } public static void main(String[] args) { new Notes(); } }