
La notion de paquetage correspond à un regroupement logique sous un identificateur commun d'un ensemble de classes. Elle est proche de la notion de bibliothèque que l'on rencontre dans d'autres langages. Elle facilite le développement et la cohabitation de logiciels conséquents en permettant de répartir les classes correspondantes dans différents paquetages. Le risque de créer deux classes de même nom se trouve alors limité aux seules classes d'un même paquetage.
Un paquetage est caractérisé par un nom qui est soit un simple identificateur, soit une suite d'identificateurs séparés par des points, comme dans :
MesClasses
Utilitaires.Mathematigues
Utilitaires.Tris
L'attribution d'un nom de paquetage se fait au niveau du fichier source ; toutes les classes d'un même fichier source appartiendront donc toujours à un même paquetage. Pour ce faire, on place, en début de fichier, une instruction de la forme :
package xxxxxx ; // xxxxxx représente le nom du paquetage.
Cette instruction est suffisante, même lorsque le fichier concerné est le premier auquel on attribue le nom de paquetage en question. En effet, la notion de paquetage est une notion "logique", n'ayant qu'un rapport partiel avec la localisation effective des classes ou des fchiers au sein de répertoires (Il est vrai que bien souvent un paquetage correspond à un répertoire).
En l'absence d'instruction package dans un fichier source, le compilateur considère que les classes correspondantes appartiennent au paquetage par défaut (java.lang). Bien entendu, celui-ci est unique pour une implémentation donnée.
Lorsque, dans un programme, vous faites référence à une classe, le compilateur la recherche dans le paquetage par défaut. Pour utiliser une classe appartenant à un autre paquetage, il est nécessaire de fournir l'information correspondante au compilateur. Pour ce faire, vous pouvez :
En citant le nom de la classe
Si vous avez attribué à la classe Point le nom de paquetage MesClasses par exemple, vous pourrez l'utiliser simplement en la nommant MesClasses.Point. Par exemple :
MesClasses.Point p = new MesClasses.Point(2, 5) ;
...
p.affiche() ; // ici, le nom de paquetage n'est pas requis
Evidemment, cette démarche devient fastidieuse dès que de nombreuses classes sont concernées.
En important une classe
L'instruction import vous permet de citer le nom (complet) d'une ou plusieurs classes, par exemple :
import MesClasses.Point, MesClasses.Cercle;
A partir de là, vous pourrez utiliser les classes Point et Cercle sans avoir à mentionner leur nom de paquetage, comme si elles appartenaient au paquetage par défaut.
En important un paquetage
La démarche précédente s'avère elle aussi fastidieuse dès qu'un certain nombre de classes d'un même paquetage sont concernées. Avec :
import MesClasses.* ;
vous pourrez ensuite utiliser toutes les classes du paquetage MesClasses en omettant le nom du paquetage correspondant.
Précautions
L'instruction :
import MesClasses ;
ne concerne que les classes du paquetage MesClasses. Si, par exemple, vous avez créé un paquetage nommé MesClasses.Projet1, ses classes ne seront nullement concernées.
Remarques
Les nombreuses classes standard avec lesquelles Java est fourni sont structurées en paquetages. Nous aurons l'occasion d'utiliser certains d'entre eux par la suite, par exemple java.awt, java.awt.event, javax.swing...
Par ailleurs, il existe un paquetage particulier nommé java.lang qui est automatiquement importé par le compilateur. C'est ce qui vous permet d'utiliser des classes standard telles que Math, System, Float ou Integer, sans avoir à introduire d'instruction import.
Pour vous permettre de commencer à écrire de petits programmes, nous vous avons déjà signalé qu'un fichier source pouvait contenir plusieurs classes, mais qu'une seule pouvait avoir l'attribut public. C'est d'ailleurs ainsi que nous avons procédé dans bon nombre d'exemples.
D'une manière générale, chaque classe dispose de ce qu'on nomme un droit d'accès (on dit aussi un modificateur d'accès). Il permet de décider quelles sont les autres classes qui peuvent l'utiliser. I1 est simplement défini par la présence ou l'absence du mot clé public :
Tant que l'on travaille avec le paquetage par défaut, l'absence du mot public n'a guère d'importance (il faut toutefois que la classe contenant main soit publique pour que la machine virtuelle y ait accès).
Nous avons déjà vu qu'on pouvait utiliser pour un membre (champ ou méthode) l'un des attributs public ou private. Avec public, le membre est accessible depuis l'extérieur de la classe ; avec private, il n'est accessible qu'aux méthodes de la classe. En fait, il existe une troisième possibilité, à savoir l'absence de mot clé (private ou public). Dans ce cas, l'accès au membre est limité aux classes du même paquetage (on parle d'accès de paquetage). Voyez cet exemple :


Les classes internes sont concernées par ce droit d'accès, mais sa signification est différente, compte tenu de l'imbrication de leur définition dans celle d'une autre classe :
Il est fastidieux de modifier le style // lorsque vous souhaitez ajouter des lignes à un commentaire multiligne. Nous vous conseillons de ne l'employer que si vous êtes certain que la taille du commentaire n'augmentera pas.
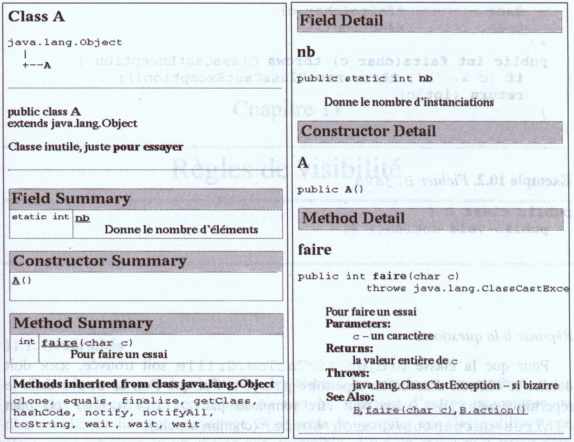
Il existe un troisième type de commentaire utilisable pour la génération automatique de documentation. Ce type de commentaire commence par /** et se termine par */. Nous en reparlerons ultérieurement, mais voici un exemple :
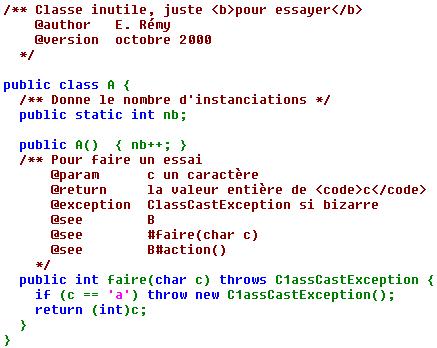
Fichier "A.java" --> la page "A.html"
Attention :
Les commentaires /* */ ne peuvent pas être imbriqués en Java. Autrement dit, pour désactiver un bloc de code, il ne suffit pas de l'enfermer entre un /* et un */, car ce bloc peut luimême contenir un délimiteur */ .
Les opérateurs binaires sont utilisés pour manipuler les bits des valeurs entières. ces opérateurs sont dérivés des opérateurs du C et C++. Ils permettent de réaliser des opérations sur des champs de bits. Utiliser ces opérateurs pour une variable numérique signifie que vous travaillez bit à bit au lieu de travailler sur la valeur numérique complète.
Opérateur Signification Exemple &
|
^
~
<<
>>
>>>Et binaire
Ou binaire
Ou exclusif bit à bit
Complément à un
Décalage de n bits vers la gauche
Décalage de n bits vers la droite (poids fort avec bit de signe)
Décalage de n bits vers la droite (poids fort à zéro)
y = x | 3
y = x ^ 3
y = ~x
y = x << 3
y = x >> 3
y = x >>> 3
Ces opérateurs travaillent sur des groupes de bits. Par exemple, si bof est une variable entière, alors la déclaration :
![]()
renvoie 1 si le quatrième bit à partir de la droite est à 1 dans la représentation binaire de bof, et zéro dans le cas contraire. L'emploi de & avec la puissance de 2 appropriée permet de masquer tous les bits sauf un. Les opérateurs >> et << permettent de déclarer un groupe de bits vers la droite ou vers la gauche. Ces opérateurs se révèlent pratiques lorsqu'on veut construire des masques :
![]()
Rien ne vous oblige à employer ces opérateurs pour diviser ou multiplier par une puissance de deux. Les compilateurs Java sont eux-mêmes assez performants pour utiliser des opérateurs de décalage lorsqu'ils rencontrent une multiplication par une puissance deux dans un bloc de code. Signalons enfin qu'il existe également un opérateur >>> permettant de remplir les bits de poids fort avec des zéros (décalage non signé), alors que >> conserve le bit de signature. Il n'y a pas d'opérateur <<<.
Instruction Valeur binaire Résultat byte octet = 0x97;
octet = ~octet;
byte bits = 1;
bits = bits << 1; (bits <<= 1)
bits <<= 2;
bits >>= 3;
byte résultat;
byte b1 = 0x65;
byte b2 = 0xAF;
résultat = b1 & b2;
résultat = b1 | b2;
résultat = b1 ^ b2;
pour => byte test = ~((0xA3^0x75)<<2);
1°) 0xA3^0x75
2°) 0xD6 << 2
3°) ~(0x58)
01101000
00000001
00000010
00001000
00000001
01100101
10101111
00100101
11101111
11001010
11010110
01011000
10100111-105 (151 - 256)
104
1 = 0x01
2 = 0x02
8 = 0x08
1 = 0x01
101
(175 - 256) = -81
0x25 = 37
0xEF = -17
0xCA = -54
0xD6
0x58
0xA7
Explication de la ligne : (10010111)2 => (1x27 + 0x26 + 0x25 + 1x24 + 0x23 + 1x22 + 1x21 + 1x20)10 => (27 + 24 + 22 + 21 +20)10 => (128 + 16 + 4 + 2 + 1)10 => (151)10 . Attention! pour un byte, l'ensemble de définition est : -128 à 127, donc 151 est trop grand, en fait si nous prenons le bit de signe, nous nous rendons compte qu'il est négatif, et donc pour retrouver la valeur réelle du nombre, il faut faire 151-256 (byte : 256 valeurs possibles). Normalement, nous n'avons pas à nous soucier de la valeur décimale, puisque nous travaillons avec le binaire. Eventuellement, le système numérique intéressant est l'hexadécimal puisqu'il est une image du binaire.
Comme dans tous les langages de programmation, il est préférable d'employer des parenthèses pour indiquer l'ordre dans lequel les opérations doivent être accomplies. La hiérarchie normale des opérations en java est présentée dans le tableau suivant :
Opérateurs Associativité [ ] . ( ) (appel de méthode)
! ~ ++ -- + (unaire) - (unaire) ( ) (transtypage) new
* / %
+ -
<< >> >>>
< <= > >= instanceof
== !=
&
^
|
&&
||
?:
= += -= *= /= %= &= |= ^= <<= >>= >>>=
De la droite vers la gauche
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la gauche vers la droite
De la droite vers la gauche
Si les parenthèses ne sont pas employées, les opérations sont accomplies dans l'ordre hiérarchique indiqué. Les opérateurs de même niveau sont traités selon l'associativité spécifiée dans le tableau.
Les mots clés break et continue possèdent tous deux une étiquette optionnelle qui indique à Java à quel endroit il doit reprendre l'exécution du programme. Quand aucune étiquette n'est utilisée, le mot clé break passe à la boucle de niveau immédiatement supérieur dans le cas d'une boucle imbriquée, ou à l'instruction située juste après la boucle s'il n'y a pas d'imbrication. Le mot clé continue fait redémarrer la boucle dont il fait partie. L'utilisation des mots clés break et continue avec des étiquettes permet d'utiliser le mot clé break pour atteindre un point situé à l'extérieur d'une boucle imbriquée, ou le mot clé continue pour atteindre une boucle située à l'extérieur de la boucle en cours.
Pour utiliser une boucle à étiquette, ajoutez l'étiquette avant le début de la boucle, et ajoutez aussi deux points (:) entre l'étiquette et la boucle. Ensuite, au moment d'utiliser le mot clé break ou continue, ajoutez le nom de l'étiquette après le mot clé lui-même, comme dans l'exemple suivant :
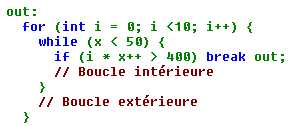 Dans
ce fragment de code, l'étiquette out désigne
la boucle extérieure. Dans chacune des boucles for et while, quand une condition
donnée est remplie, une instruction break fait
sortir le programme des deux boucles. S'il n'y avait pas d'étiquette out,
l'instruction break indiquerait au programme
de quitter la boucle intérieure et de reprendre l'exécution du programme au
niveau de la boucle extérieure.
Dans
ce fragment de code, l'étiquette out désigne
la boucle extérieure. Dans chacune des boucles for et while, quand une condition
donnée est remplie, une instruction break fait
sortir le programme des deux boucles. S'il n'y avait pas d'étiquette out,
l'instruction break indiquerait au programme
de quitter la boucle intérieure et de reprendre l'exécution du programme au
niveau de la boucle extérieure.
En Java, on peut définir des champs qui, au lieu d'exister dans chacune des instances de la classe, n'existent qu'en un seul exemplaire pour toutes les instances d'une même classe. I1 s'agit en quelque sorte de données globales partagées par toutes les instances d'une même classe. On parle alors de champs de classe ou de champs statiques. De même, on peut définir des méthodes de classe (ou statiques) qui peuvent être appelées indépendamment de tout objet de la classe (c'est le cas de la méthode main).
Considérons la définition (simpliste) de classe ci-contre (nous ne nous préoccuperons pas des droits d'accès aux champs n et y) :

Chaque objet de type A possède ses propres champs n et x. Par exemple, avec cette déclaration :
A a1 = new A() , a2 = new A () ;
on aboutit à une situation qu'on peut schématiser ainsi :
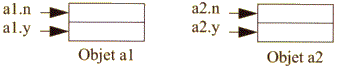
Mais Java permet de définir ce qu'on nomme des champs de classe (ou statiques) qui n'existent qu'en un seul exemplaire, quel que soit le nombre d'objets de la classe. Il suffit pour cela de les déclarer avec l'attribut static. Par exemple, si nous définissons :
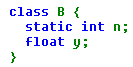
B a1 = new B () , a2 = new B () ;
nous aboutissons à cette situation :

Les notations al.n et a2.n désignent donc le même champ. En fait, ce champ existe indépendamment de tout objet de sa classe. Il est possible (et même préférable) de s'y référer en le nommant simplement :
B.n // champ (statique) n de la classe B
Notez que depuis une méthode de la classe B, on accédera à ce champ on le nommant comme d'habitude n (le préfixe B. n'est pas nécessaire, mais il reste utilisable).
Nous venons de voir comment définir des champs de classe, lesquels n'existent qu'en un seul exemplaire, indépendamment de tout objet de la classe. De manière analogue, on peut imaginer que certaines méthodes d'une classe aient un rôle indépendant d'un quelconque objet. Ce serait notamment le cas d'une méthode se contentant d'agir sur des champs de classe ou de les utiliser.
Là encore, Java vous permet de définir une méthode de classe en la déclarant avec le mot clé static. L'appel d'une telle méthode ne nécessite plus que le nom de la classe correspondante.
Bien entendu, une méthode de classe ne pourra en aucun cas agir sur des champs usuels (non statiques) puisque, par nature, elle n'est liée à aucun objet en particulier. Voyez cet exemple :

A a ;
A.f() ; // appelle la méthode de classe f de la classe
A
a.f() ; // autre solution moins lisible, nous ne nous
rendons pas compte qu'il s'agit d'une méthode de classe
On pourrait introduire dans une des classes Point déjà rencontrées deux champs de classe destinés à contenir les coordonnées d'une origine partagée par tous les points. Mais les méthodes de classe peuvent également fournir des services n'ayant de signification que pour la classe même. Ce serait par exemple le cas d'une méthode fournissant l'identification d'une classe (nom de classe, numéro d'identification, nom de l'auteur...).
Enfin, on peut utiliser des méthodes de classe pour regrouper au sein d'une classe des fonctionnalités ayant un point commun et n'étant pas liées à un quelconque objet. C'est le cas de la classe Math qui contient des fonctions de classe telles que sqrt, sin, cos.
double x=0.0;
double y = Math.sin(x);
double z = Math.sqrt(x+2.5);
Ces méthodes n'ont d'ailleurs qu'un très lointain rapport avec la notion de classe. En fait, ce regroupement est le seul moyen dont on dispose en Java pour retrouver (artificiellement) la notion de fonction indépendante qu'on trouve dans les langages usuels (objet ou non).
Nous avons vu comment les champs usuels se trouvent initialisés : d'abord à une valeur fournie (éventuellement) lors de leur déclaration, sinon à une valeur par défaut , enfin par le constructeur.
Ces possibilités vont s'appliquer aux champs statiques avec cependant une exception concernant le constructeur. En effet, alors que l'initialisation d'un champ usuel est faite à la création d'un objet de la classe, celle d'un objet statique doit être faite avant la première utilisation de la classe. Cet instant peut bien sûr coïncider avec la création d'un objet, mais il peut aussi la précéder (il peut même n'y avoir aucune création d'objets). C'est pourquoi l'initialisation d'un champ statique se limite à :
 l'initialisation par défaut,
l'initialisation par défaut, Considérez la classe ci-contre :
Une simple déclaration telle que la suivante entraînera l'initialisation des champs statiques de A :
A a ; // aucun objet de type A n'est encore
créé, les champs statiques
// de A sont intialisés : p (implicitement) à 0, n (explicitement) à 10
Il en ira de même en cas d'appel d'une méthode statique de cette classe, même si aucun objet n'a encore été créé :
A.f() ; // initialisation des statiques de A, si pas déjà fait
Notez cependant qu'un constructeur, comme d'ailleurs toute méthode, peut très bien modifier la valeur d'un champ statique ; mais il ne s'agit plus d'une initialisation, c'est-à-dire d'une opération accompagnant la création du champ.
Enfin, un champ de classe peut être déclaré final. I1 doit alors obligatoirement recevoir une valeur initiale, au moment de sa déclaration. En effet, comme tout champ déclaré final, il ne peut pas être initialisé implicitement. De plus, comme il s'agit d'un champ de classe, il ne peut plus être initialisé par un constructeur.
Java permet d'introduire dans la définition d'une classe un ou plusieurs blocs d'instructions précédés du mot static. Dans ce cas, leurs instructions n'ont accès qu'aux champs statiques de la classe.
Les blocs d'initialisation statiques présentent un intérêt lorsque l'initialisation des champs statiques ne peut être faite par une simple expression. En effet, il n'est plus possible de se reposer sur le constructeur, non concerné par l'initialisation des champs statiques. En voici un exemple qui fait appel à la notion de tableau que nous avons déjà étudié :

En Java, la transmission d'un argument à une méthode et celle de son résultat ont toujours lieu par valeur. Comme pour l'affectation, les conséquences en seront totalement différentes, selon que l'on a affaire à une valeur d'un type primitif ou d'un type classe.
Dans les différents langages de programmation, on rencontre principalement deux façons d'effectuer le transfert d'information requis par la correspondance entre argument :
Java emploie systématiquement le premier mode. Mais lorsqu'on manipule une variable de type objet, son nom représente en fait sa référence de sorte que la méthode reçoit bien une copie ; mais il s'agit d'une copie de la référence. La méthode peut donc modifier l'objet concerné qui, quant à lui, n'a pas été recopié. En définitive, tout se passe comme si on avait affaire à une transmission par valeur pour les types primitifs et à une transmission par référence pour les objets. Les mêmes remarques s'appliquent à la valeur de retour d'une méthode.
La notion de classe interne a été introduite par la version 1.1 de Java, essentiellement dans le but de simplifier l'écriture du code de la programmation événementielle (qui sera traitée lors de la programmation graphique). Nous pouvons utiliser les classes internes en dehors de la programmation événementielle.
Une classe est dite interne lorsque sa définition est située à l'intérieur de la définition d'une autre classe. Malgré certaines ressemblances avec la notion d'objet membre étudiée ci-dessus, elle ne doit surtout pas être confondue avec elle, même s'il est possible de l'utiliser dans ce contexte. La notion de classe interne correspond à cette situation :
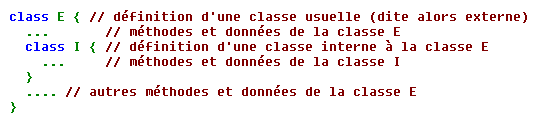
Il est très important de savoir que la définition de la classe I n'introduit pas d'office de membre de type I dans E. En fait, la définition de 1 est utilisable au sein de la définition de E, pour instancier quand on le souhaite un ou plusieurs objets de ce type. Par exemple, on pourra rencontrer cette situation :

On voit qu'ici un objet de classe E ne contient aucun membre de type I. Simplement, une de ses méthodes (fe) utilise le type I pour instancier un objet de ce type. Mais bien entendu, on peut aussi trouver une ou plusieurs références à des objets de type I au sein de la classe E, comme dans ce schéma :
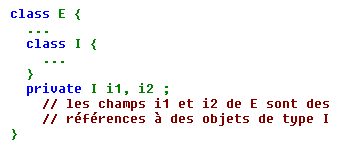
Ici, un objet de classe E contient deux membres de type I. Nous n'avons pas précisé comment les objets correspondants seront instanciés (par le constructeur de E, par une méthode de E...).
On peut se demander en quoi les situations précédentes diffèrent d'une définition de I qui serait externe à celle de E. En fait, les objets correspondant à cette situation de classe interne jouissent de trois propriétés particulières.
Si le point 1 n'apporte rien de nouveau par rapport à la situation d'objets membres, il n'en va pas de même pour les points 2 et 3, qui permettent d'établir une communication privilégiée entre objet externe et objet interne.
Exemple 1 : Voici un premier exemple utilisant le premier cas de figure et illustrant les points 1 et 2 :
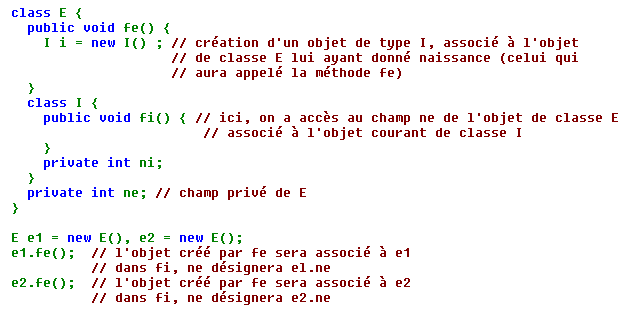
Exemple 2 : Voici un second exemple utilisant le second cas de figure et illustrant les points 1 et 3 :
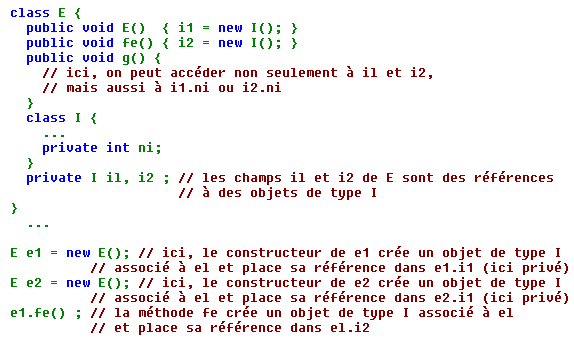
Au bout du compte, on a créé ici deux objets de type I, associés à el ; il se trouve que (après appel de fe seulement), leurs références figurent dans el.i1 et el.i2. La situation ressemble à celle d'objets membres (avec cependant des différences de droits d'accès). En revanche, on n'a créé qu'un seul objet de type I associé à e2.
Remarques
Exemple complet :
Au paragraphe précédent, nous avons commenté un exemple de classe Cercle utilisant un objet membre de type Point. Nous vous proposons ici, à simple titre d'exercice, de créer une telle classe en utilisant une classe nommée Centre, interne à Cercle :
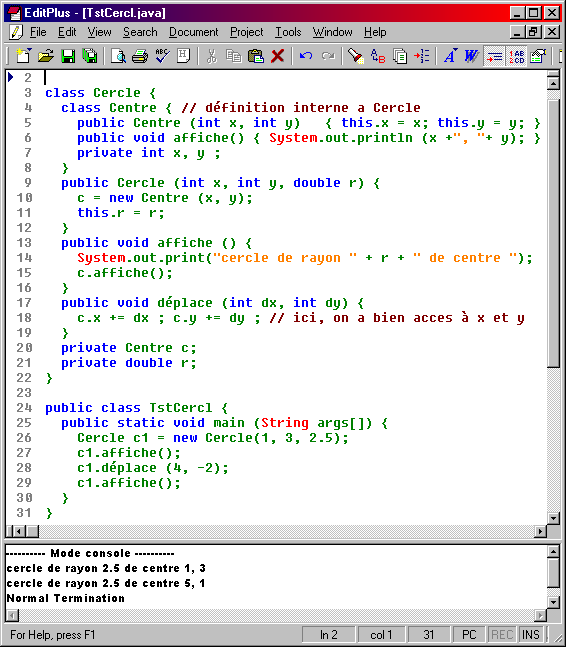
Ici, la classe Centre a été dotée d'une méthode affiche, réutilisée par la méthode affiche de la classe Cercle. La situation de classe interne ne se distingue guère de celle d'objet membre. En revanche, bien que la classe Centre ne dispose ni de fonctions d'accès et d'altération, ni de méthode déplace, la méthode déplace de la classe Cercle a bien pu accéder aux champs privés x et y de l'objet de type Centre associé.
Nous avons vu comment déclarer et instancier un objet d'une classe interne depuis une classe englobante, ce qui constitue la démarche la plus naturelle. En théorie, Java permet d'utiliser une classe interne depuis une classe indépendante (non englobante). Mais, il faut quand même rattacher un objet d'une classe interne à un objet de sa classe englobante, moyennant l'utilisation d'une syntaxe particulière de new. Supposons que l'on ait :
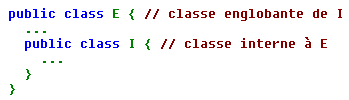
En dehors de E, vous pouvez toujours déclarer une référence i à un objet de type I, de cette manière :
E.I i ; // i : référence à un objet de type I (interne à E)
Mais la création d'un objet de type I ne peut se faire qu'en le rattachant à un objet de sa classe englobante. Par exemple, si l'on dispose d'un objet e créé ainsi :
E e = new E() ;
on pourra affecter à i la référence à un objet de type I, rattaché à e, en utilisant new comme suit :
i = new e.I() ; // création d'un objet de
type I, rattaché à l'objet e
// et affectation de sa référence à i
Vous pouvez définir une classe interne I dans une méthode f d'une classe E. Dans ce cas, l'instanciation d'objets de type I ne peut se faire que dans f. En plus des accès déjà décrits, un objet de type I a alors accès aux variables locales finales de f.

Les objets des classes internes dont nous avons parlé jusqu'ici étaient toujours associés à un objet d'une classe englobante. On peut créer des classes internes "autonomes" en employant l'attribut static :

Depuis l'extérieur de E, on peut instancier un objet de classe I de cette façon :
E.I i = new E.I() ;
L'objet i n'est associé à aucun objet de type E. Bien entendu, la classe I n'a plus accès aux membres de E, sauf s'il s'agit de membres statiques.