EJB3.1 - ORM - Object-Relational Mapping
EJB3.1 - ORM - Object-Relational Mapping
 Durant cette étude, nous passerons en revue les bases des ORM (Object-Relational Mapping), qui consistent essentiellement à faire correspondre des entités à des tables et des attributs à des colonnes. Nous nous intéresserons ensuite à des associations plus complexes comme les relations, la composition et l'héritage.
Durant cette étude, nous passerons en revue les bases des ORM (Object-Relational Mapping), qui consistent essentiellement à faire correspondre des entités à des tables et des attributs à des colonnes. Nous nous intéresserons ensuite à des associations plus complexes comme les relations, la composition et l'héritage.
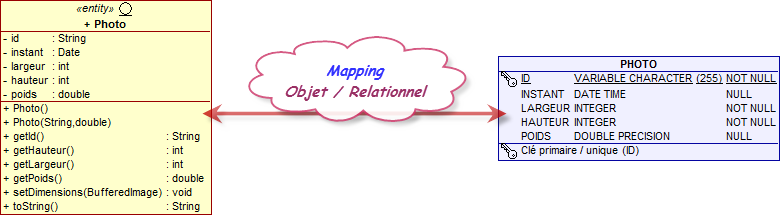
Un modèle objet est composé d'objets interagissant ensemble ; or les objets et les bases de données utilisent des moyens différents pour stocker les informations sur ces relations (via des pointeurs ou des clés étrangères). Les bases de données relationnelles ne disposent pas naturellement du concept d'héritage et cette association entre objets et bases n'est par conséquent pas évidente.
Nous irons donc dans les détails et présenterons des exemples qui montrerons comment les attributs, les relations et l'héritage peuvent être traduits d'un modèle objet vers une base de données.
Comme premier exemple, commençons par l'association la plus simple possible que nous avons élaboré lors de l'étude précédente. Dans le modèle de persistance de JPA, une entité est un objet Java classique (POJO) :
Ceci signifie qu'une entité est déclarée, instanciée et utilisée comme n'importe qu'elle autre classe Java. Une entité possède des attributs (son état) qui peuvent être manipulés au moyen de getters et de setters (notion de propriétés). Dans la base de données relationnelle, chaque attribut est stockée dans une colonne d'une table
package entité; import java.awt.image.BufferedImage; import java.util.Date; import javax.persistence.*; @Entity @NamedQuery(name=, query=) public class Photo { // implements java.io.Serializable { @Id private String id; @Temporal(TemporalType.TIMESTAMP) private Date instant; private int largeur; private int hauteur; private long poids; public String getId() { return id; } public int getHauteur() { return hauteur; } public Date getInstant() { return instant; } public int getLargeur() { return largeur; } public long getPoids() { return poids; } public Photo() { } public Photo(String nom, long poids) { id = nom; instant = new Date(); this.poids = poids; } public void setDimensions(BufferedImage image) { largeur = image.getWidth(); hauteur = image.getHeight(); } @Override public String toString() { return id++largeur++hauteur+; } }
Comme vous pouvez le constater, à part les annotations, cette entité ressemble exactement à n'importe quelle classe Java : elle possède plusieurs attributs (id, instant, largeur, hauteur et poids) de différents types (String, Date, int et long), plusieurs constructeurs dont celui par défaut, des getters pour chaque attribut avec un seul setter. Dans cette exemple là, l'état de l'objet est rapidement renseigné à l'aide du deuxième constructeur et de la méthode setDimensions().
Les annotations permettent d'associer très simplement cette entité à une table dans une base de données.
Notez que cette entité Photo est une classe qui actuellement n'implémente aucune interface et qui n'hérite d'aucune classe. En fait, pour être une entité, une classe doit impérativement respecter les règles suivantes :
L'entité Photo respectant ces règles simples, le fournisseur de persistance peut synchroniser les données entre les attributs de l'entité et les colonnes de la table PHOTO. Par conséquent, si l'attribut largeur est modifié par l'application, la colonne LARGEUR le sera également (si l'entité est gérée, si le contexte de transaction est actif, etc.).
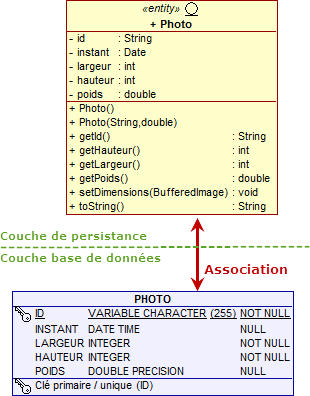 L'entité Photo est stockée dans une table PHOTO dont chaque colonne porte le nom de l'attribut correspondant de la classe (l'attribut largeur de type int est associée à une colonne LARGEUR de type INTEGER). Ces règles d'associations par défaut sont un aspect important du principe appelé "convention plutôt que configuration" (ou "configuration par exception").
L'entité Photo est stockée dans une table PHOTO dont chaque colonne porte le nom de l'attribut correspondant de la classe (l'attribut largeur de type int est associée à une colonne LARGEUR de type INTEGER). Ces règles d'associations par défaut sont un aspect important du principe appelé "convention plutôt que configuration" (ou "configuration par exception").
Java EE 5 a introduit l'idée de configuration par exception. Ceci signifie que, sauf mention contraire, le conteneur ou le fournisseur doivent appliquer les règles par défaut. En d'autres termes, fournir une configuration est une exception à la règle. Cette politique permet donc de configurer une application avec un minimum d'effort.
Ce type de décision caractérise bien la politique de configuration par exception : les annotations ne sont pas nécessaires dans le cas général ; elles ne sont utilisées que pour outrepasser une convention. Ceci signifie donc que tous les autres attributs de notre classe (sauf instant) seront associés selon les règles par défaut :
Ces règles par défaut peuvent éventuellement varier en fonction du SGBDR : un String est associé avec un VARCHAR avec Derby, mais à un VARCHAR2 avec Oracle ; de la même façon, un Integer est associé à un INTEGER avec Derby, mais à un NUMBER avec Oracle.
La plupart des fournisseurs de persistance, dont EclipseLink, permettent de produire automatiquement la base de données directement à partir des entités. Cette fonctionnalité est tout spécialement pratique lorsque nous sommes en phase de développement car, avec uniquement les règles par défaut, nous pouvons associer très simplement les données en se contentant des annotations @Entity et @Id.
Indépendamment de notre application d'entreprise, il peut arriver que nous souhaitions nous connecter au SGBDR de façon classique, à l'aide notamment de requête SQL. Dans ce cas de figure, pour que les développeurs de base de données classiques puissent s'y retrouver, JPA définit un nombre important d'annotations qui vont permettrent de personnaliser chaque partie de l'association (les noms des tables et des colonnes, les clés primaires, la taille des colonnes, les colonnes NULL ou NOT NULL, etc. ).
D'importantes différences existent entre la gestion des données par Java et par un SGBDR. En Java, nous utilisons des classes pour décrire à la fois les attributs qui contiennent les données et les méthodes qui accèdent et manipulent ces données. Lorsqu'une classe est définie, nous pouvons créer autant d'instances que nécessaire. Dans un SGBDR, en revanche, seules les données sont stockées, pas les comportements (exception faite des triggers et des procédures stockées). La procédure de stockage est également totalement différente de la structure des objets puisqu'elle utilise une décomposition en ligne et colonnes.
L'association d'objets Java à une base de données sous-jacente peut donc être simple et se contenter des règles par défaut ; parfois, ces règles peuvent ne pas convenir aux besoin, auquel cas nous sommes obligés de les outrepasser.
Les annotations des associations élémentaires permettent ainsi de remplacer les règles par défaut pour la table, les clés primaires et les colonnes, et de modifier certaines conventions de nommage ou de contenu de colonnes (valeurs non nulle, longueur, etc.).
La convention établit que les noms de l'entité et de la table sont identiques (une entité Photo est associée à une table PHOTO, une entité Livre, à une table LIVRE, etc.). Toutefois, si vous le souhaitez, vous pouvez associer vos attributs à une table différente, voire associer une même entité à plusieurs tables.
L'annotation @javax.persistence.Table permet de modifier les règles par défaut pour les tables. Vous pouvez, par exemple, indiquer le nom de la table dans laquelle vous voulez stocker vos attributs, le catalogue et le schéma de la base.
Cette annotation possède différents attributs :
@Entity @Table(name=) public class Photo implements java.io.Serializable { @Id private String id; @Temporal(TemporalType.TIMESTAMP) private Date instant; private int largeur; private int hauteur; private long poids; ... }
Dans l'annotation @Table, le nom de la table est en minuscule (t_photo). Par défaut, la plupart des SGBDR lui feront correspondre un nom en majuscules (c'est notamment le cas de Derby), sauf si vous les configurez pour qu'ils respectent la casse.
Jusqu'à maintenant, nous avons toujours supposé qu'une entité n'était associée qu'à une seule table, également appelée table primaire. Si nous possédons déjà un modèle de données, en revanche, nous voudrons peut-être disséminer les attributs sur plusieurs tables, ou tables secondaires. Cette annotation permet de mettre en place cette configuration.
@SecondaryTable permet d'associer une table secondaire à une entité, alors que @SecondaryTables (avec un "s") en associe plusieurs. Vous pouvez ainsi distribuer les données d'une entité entre les colonnes de la table primaire et celles des tables secondaires en définissant simplement les tables secondaires avec des annotations, puis en précisant pour chaque attribut la table dans laquelle il devra être stocké (à l'aide de l'annotation @Column, que nous décrirons ultérieurement).
@Entity @SecondaryTables({ @SecondaryTable(name=), @SecondaryTable(name=) }) public class Adresse implements java.io.Serializable { @Id @GeneratedValue private long id; private String rue1; private String rue2; @Column(table=) private String ville; @Column(table=) private String département; @Column(table=) private int codepostal; @Column(table=) private String pays; ... }
Par défaut, les attributs de l'entité Adresse seraient associés à la table primaire ADRESSE. L'annotation @SecondaryTables précise qu'il existe deux tables secondaires supplémentaires : VILLE et PAYS. Vous devez ensuite respectivement indiquer dans quelle table secondaire stocker chaque attribut - à l'aide de l'annotation @Column(table=) ou @Column(table=).
Le résultat d'une telle écriture est ainsi la création de trois tables distinctes se partageant les différents attributs d'une même entité, en ayant toutefois la même clé primaire (afin, bien entendu, de pouvoir les joindre).
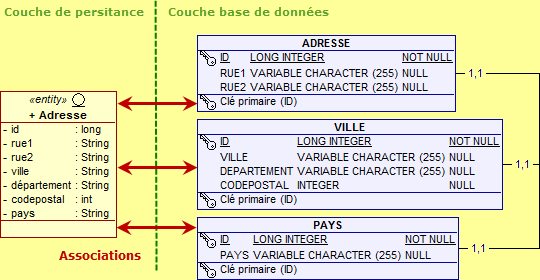
Comme vous l'avez sûrement compris, la même entité peut contenir plusieurs annotations. Ainsi, si vous désirez renommer la table primaire, vous pouvez donc ajouter une annotation @Table à celles déjà existantes :
@Entity @Table(name=) @SecondaryTables({ @SecondaryTable(name=), @SecondaryTable(name=) }) public class Adresse implements java.io.Serializable { @Id @GeneratedValue private long id; private String rue1; private String rue2; @Column(table=) private String ville; @Column(table=) private String département; @Column(table=) private int codepostal; @Column(table=) private String pays; ... }
Vous devez être concient de l'impact des tables secondaires sur les performances car, à chaque fois que vous accéder à une entité, le fournisseur de persistance devra accéder à plusieurs tables et les joindre. En revanche, les tables secondaires peuvent être intéressantes si vous avez des attributs de grande taille, comme les BLOB (Binary Large Objects), car vous pourrez les isoler dans une table à part.
Dans les bases de données relationnelles, une clé primaire identifie chaque ligne d'une table. Cette clé peut être une simple colonne ou un ensemble de colonnes. Les clés primaires doivent évidemment être uniques (et la valeur NULL n'est pas autorisée). Des exemples de clés primaires classiques sont un numéro de compte client, un numéro de téléphone, un numéro de commande et un ISBN.
JPA exige que les entités aient un identifiant associé à une clé primaire qui suivra également les mêmes règles ; identifier de façon unique une entité à l'aide d'un simple attribut ou d'un ensemble d'attributs (clé composée). Une fois affectée, la valeur de la clé primaire d'une entité ne peut plus être modifiée.
A retenir : Un bean entité doit impérativement posséder un attribut dont la valeur est unique, dit identificateur unique ou clé primaire. Ce champ permet de différencier chaque objet entité des autres. Cette clé primaire doit être définie une seule fois dans toute la hiérarchie du bean entité.
Une clé primaire simple (non composée) doit correspondre à un seul attribut de la classe de l'entité. L'annotation @Id que nous avons déjà rencontrée sert à indiquer une clé simple. L'attribut qui servira de clé doit être de l'un des types suivants :
Remarque : en général, les décimaux (nombre à virgule) ne sont pas utilisés en tant que clé primaire. Les entités utilisant ce type pour la clé primaire risquent de ne pas être portables.
@Id @GeneratedValue(strategy = GenerationType.IDENTITY) private int id;
@Entity @SequenceGenerator(name = "SEQ_USER", sequenceName = "SEQ_USER") public class Utilisateur implements Serializable { @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "SEQ_USER") public int id;
Ce type de génération est utile lorsque la base de données offre un système natif de séquence et qu'il est conseillé de l'utiliser par le fournisseur de celle-ci.
Derby, par exemple, crée une table SEQUENCE de deux colonnes : une pour le nom de la séquence (qui est arbitraire) et l'autre pour la valeur (un entier incrémenté automatiquement par Derby).
De façon annecdotique, nous pouvons pousser plus loin notre investigation en proposant l'annotation @TableGenerator qui permet de préciser les paramètres de création de la table annexe de génération dont les attributs sont les suivants :@Entity @TableGenerator( name="C0NTACT_GEN", table="GENERATEUR_TABLE", pkColumnName="clé", valueColumnName="haut", pkColumnValue="id", allocationSize=25 ) public class Utilisateur implements Serializable { @Id @GeneratedValue(strategy = GenerationType.TABLE, generator = "CONTACT_GEN") public int id;
Ainsi, ce type indique au fournisseur de persistance d'utiliser la meilleure stratégie (entre ENTITY, TABLE, SEQUENCE) suivant la base de données utilisée. Le générateur AUTO est le type préféré pour avoir une application portable.
Même si l'incrémentation automatique de la clé primaire soulage le développeur, elle doit être utilisée avec parcimonie. En effet, il est préférable d'utiliser un attribut de l'entité plutôt que d'en rajouter un, spécialement pour la clé primaire. Par exemple, l'entité Compte peut contenir une propriété numéroCompte qui se veut unique par la logique bancaire. Cette propriété est alors la meilleure candidate pour la clé primaire.
En l'absence de @GeneratedValue, l'application est responsable de la production des identifiants à l'aide d'un algorithme qui devra renvoyer une valeur unique.
Le code source suivant montre comment obtenir automatiquement un identifiant :
@Entity public class Livre implements java.io.Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private long id; private String titre; private double prix; private String description; private String isbn; private int nombreDePages; private boolean illustrations; ... }
GenerationType.AUTO étant la valeur par défaut de l'annotation, nous aurions pu omettre l'élément strategy. Notez également dans tous nos exemples que l'attribut id est annoté deux fois : avec @Id et avec @GeneratedValue.
Lorsque nous associons des entités, il est conseillé dans la mesure du possible de dédier une seule colonne à la clé primaire. Dans certains cas, toutefois, nous sommes obligés de passer par une clé primaire composée.
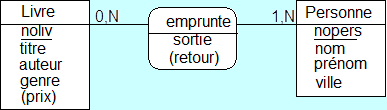
CREATE TABLE emprunte ( nopers integer not null, noliv integer not null, sortie date default current_date, retour date, primary key (noliv, nopers, sortie), foreign key (noliv) references Livre(noliv), foreign key (nopers) references Personne(nopers) );
En réalité, dans la technologie relative à la couche de persistance, la plupart du temps, nous n'avons pas besoin de créer explicitement des entités représentant les tables de jointures. Celles-ci sont fabriquées automatiquement à partir des beans entités représentant les deux tables principales comme ici Livre et Personne. Nous le verrons utltérieurement, c'est au moment de la mise en relation de type @ManyToMany entre l'entité Livre et l'entité Personne que la table de jointure se génère automatiquement.
Toutefois, dans cet exemple précis, cette table de jointure dispose de deux champs importants que sont la date d'emprunt et la date de retour. Ainsi, cette table de jointure, en même temps qu'elle sert de jonction entre les livres et les personnes, sert également à enregistrer des informations importantes. Du coup, il est finalement nécessaire de créer une entité relative afin de bien prendre en compte ces dates de stockage et de restitution. Nous étudierons cette possibilité au travers d'un projet complet de gestion de bibliothèque.
Dans ce type de situation, dans la couche de persistance, nous devons créer spécialement une classe de clé primaire pour représenter la clé primaire composée. Pour cela, nous disposons de deux annotations spécifiques pour cette classe, en fonction de la façon dont nous envisageons de structurer l'entité : @EmbeddedId et @IdClass. Comme nous le découvrirons, le résultat final sera le même. Nous aboutirons au même schéma de base de données, mais cela modifiera légèrement la façon d'interroger l'entité.
Imaginons un projet d'entreprise dans lequel le système prévoit de poster fréquemment des articles sur une page d'accueil pour signaler de nouveaux livres, des titres musicaux ou des artistes. Ces articles doivent possèder un contenu, un titre et, comme ils sont écrits dans des langues différentes, un code langue (EN pour l'anglais, FR pour le français, etc.) La clé primaire des articles pourrait donc être composée du titre et du code de la langue car un article peut être traduit en plusieurs langues tout en gardant son titre initial.
La classe de la clé primaire sera composée des attributs de type String titre et langue. Afin de permettre la gestion des requêtes et des collections internes, les classes des clés primaires doivent :
Comme nous le verrons plus loin, JPA utilise différentes sortes d'objets intégrés (embedded). Pour faire court, un objet intégré n'a pas d'identité propre (il n'a donc pas de clé primaire) et ses attributs sont stockés dans des colonnes de la table associée à l'entité qui le contient.
Le code source suivant présente la classe NewsId comme une classe intégrable (embeddable). Il s'agit simplement d'un objet intégré (annoté @Embeddable) composé de deux attributs (titre et langue). Cette classe doit avoir un constructeur par défaut, des getters() et redéfinir la méthode equals() et hashCode(). Vous remarquez que la classe n'a pas d'identité par elle-même (aucune annotation @Id : c'est ce qui caractérise un objet intégrable.
package entité; import java.io.Serializable; import javax.persistence.Embeddable; @Embeddable public class NewsId implements Serializable { private String titre; private String langue; public NewsId() { } public NewsId(String titre, String langue) { this.titre = titre; this.langue = langue; } public String getLangue() { return langue; } public String getTitre() { return titre; } @Override public boolean equals(Object obj) { // généré automatiquement par NetBeans if (obj == null) { return false; } if (getClass() != obj.getClass()) { return false; } final NewsId other = (NewsId) obj; if ((this.titre == null) ? (other.titre != null) : !this.titre.equals(other.titre)) { return false; } if ((this.langue == null) ? (other.langue != null) : !this.langue.equals(other.langue)) { return false; } return true; } @Override public int hashCode() { // généré automatiquement par NetBeans int hash = 7; hash = 89 * hash + (this.titre != null ? this.titre.hashCode() : 0); hash = 89 * hash + (this.langue != null ? this.langue.hashCode() : 0); return hash; } }
L'entité News, présentée dans le code source qui suit, doit maintenant intégrer la classe de clé primaire NewsId à l'aide de l'annotation @EmbeddedId. Toutes les annotations @EmbeddedId doivent désigner une classe intégrable annotée par @Embeddable.
package entité; import java.io.Serializable; import javax.persistence.*; @Entity public class News implements Serializable { @EmbeddedId private NewsId id; private String contenu; public News() { } public News(String titre, String langue, String contenu) { id = new NewsId(titre, langue); this.contenu = contenu; } public NewsId getId() { return id; } public String getContenu() { return contenu; } }
Lors d'une prochaine étude, nous verrons plus précisément comment retrouver les entités à l'aide de leur clé primaire, mais l'exemple ci-dessous présente le principe général : La clé primaire étant une classe avec un constructeur, vous devez d'abord l'instancier avec les valeurs qui forment la clé, puis passer cet objet au gestionnaire d'entités :
package session; import entité.*; import javax.ejb.*; import javax.persistence.*; @Stateless @LocalBean public class Gestion { @PersistenceContext private EntityManager persistance; public News recherche(String titre, String langue) { return persistance.find(News.class, new NewsId(titre, langue)); } ... }
L'autre méthode pour déclarer une clé primaire compsée consiste à utiliser l'annotation @IdClass. Cette approche est différente de la précédente car, ici, chaque attribut de la classe de la clé primaire doit également être déclaré dans la classe entité et annoté avec @Id.
package entité; import java.io.Serializable; import javax.persistence.Embeddable; public class NewsId implements Serializable { // la classe de la clé primaire n'est pas annotée private String titre; private String langue; public NewsId() { } public NewsId(String titre, String langue) { this.titre = titre; this.langue = langue; } public String getLangue() { return langue; } public String getTitre() { return titre; } @Override public boolean equals(Object obj) { // généré automatiquement par NetBeans if (obj == null) { return false; } if (getClass() != obj.getClass()) { return false; } final NewsId other = (NewsId) obj; if ((this.titre == null) ? (other.titre != null) : !this.titre.equals(other.titre)) { return false; } if ((this.langue == null) ? (other.langue != null) : !this.langue.equals(other.langue)) { return false; } return true; } @Override public int hashCode() { // généré automatiquement par NetBeans int hash = 7; hash = 89 * hash + (this.titre != null ? this.titre.hashCode() : 0); hash = 89 * hash + (this.langue != null ? this.langue.hashCode() : 0); return hash; } }
L'entité News doit simplement définir la classe de la clé primaire à l'aide de l'annotation @IdClass et annoter chaque attribut de la clé avec @Id. Pour stocker l'entité News, vous devrez maintenant donner une valeur aux attributs titre et langue.
package entité; import java.io.Serializable; import javax.persistence.*; @Entity @IdClass(NewsId.class) public class News implements Serializable { @Id private String titre; @Id private String langue; private String contenu; public News() { } public News(String titre, String langue, String contenu) { this.titre = titre; this.langue = langue; this.contenu = contenu; } public NewsId getId() { return id; } public String getContenu() { return contenu; } }
Les deux approches, @EmbeddedId et @IdClass, donneront la même structure de table. Les attributs de l'entité et de la clé primaire se retrouveront bien dans la même table et la clé primaire sera formée des attributs de la classe clé primaire (titre et langue).
CREATE TABLE emprunte ( CONTENU varchar(255), TITRE varchar(255) not null, LANGUE varchar(255) not null, primary key (TITRE, LANGUE) );
L'approche par @IdClass est plus sujette aux erreurs car vous devez définir chaque attribut de la clé primaire à la fois dans la classe de clé primaire et dans l'entité, en vous assurant d'utiliser les mêmes noms et les mêmes types.
La seule différence visible est la façon dont vous ferez référence à l'entité dans JQPL.
@IdClass : SELECT n.titre FROM News n @EmbeddedId : SELECT n.newsId.titre FROM News n
Une entité doit posséder une clé primaire (simple ou composée) pour être identifiable dans une base de données relationnelle. Elle dispose également de toutes sortes d'attributs qui forment son état, qui doit également être associé à la table. Cet état peut contenir quasiment tous les types Java que vous pourriez vouloir associer :
Bien sûr, une entité peut également avoir des attributs entités, collections d'entités ou d'instances de classes intégrables. Ceci implique d'introduire des relations entre les entités (que nous étudierons en détail ultérieurement).
Comme nous l'avons vu, en vertu de la configuration par exception, les attributs sont associés selon des règles par défaut. Parfois, cependant, vous aurez besoin d'adapter certaines parties de cette association ; c'est là que les annotations JPA entrent une nouvelle fois en jeu.
La politique de l'API de persistance est de considérer toute propriété comme un champ persistant. Cela signifie qu'il n'est pas nécessaire d'annoter les propriétés pour les désigner persistantes. Le conteneur considère par défaut que la propriété est annotée avec @Basic avec les valeurs par défaut des attributs suivants :
Pour spécifier qu'un attribut ne doit pas être persistant, vous devez l'annoter avec @Transient.
.
public class Piste { @Id private long id; private String titre; private double durée; @Lob @Basic(fetch = FetchType.LAZY) private byte[] wav; @Basic(optional = true) private String description; ... }
Notez que l'attribut wav de type byte[] est également annoté @Lob afin que sa valeur soit stockée comme un LOB (Large Object) - les colonnes pouvant stocker ces types de gros objets nécessitent des appels JDBC spéciaux pour être accessibles à partir de Java. Pour en informer le fournisseur, il faut donc ajouter une annotation @Lob à l'association de base.
Ainsi, l'annotation @Lob s'avère utile lorsque vous souhaitez stocker des tableaux de bytes (byte[] ou Byte[]) pour représenter le contenu d'un fichier par exemple :
@Lob @Basic(fetch=FetchType.LAZY) public byte[] fichierImage;
L'annotation @Lob s'applique également sur des propriétés de type java.sql.Clob (Character Large Object) ou java.sql.Blob (Binary Large Object). Nous avons volontairement ajouté le mode paressseux. Effectivement, le contenu de cette propriété risque d'être de grande taille.
L'annotation @javax.persistence.Column définit toutes les propriétés possibles d'une colonne dans la table. Grâce à elle, nous pouvons modifier le nom de la colonne (qui, par défaut, est le même que celui de l'attribut), la taille du champ correspondant, et de nombreuses autres caractéristiques à utiliser pour une propriété persistante, comme notamment si la valeur dans la colonne peut être nulle ou pas.
Voici une description des attributs, tous optionnels, de l'annotation @Column :
Les nombreux paramètres par défaut de l'API de persistance offrent un avantage certain au développeur. Celui-ci peut rapidement tester ses entités. Toutefois, il ne doit pas en rester là, mais utiliser les possiblités exposées ici pour optimiser le mapping entre ses entités et les tables de la base de données.
@Entity public class Livre implements java.io.Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private long id; @Column(name = "titre_livre", nullable = false, updatable = false) private String titre; @Column(precision = 5, scale = 2) private double prix; @Column(length = 2000) private String description; private String isbn; @Column(name = "nombre_pages", nullable = false) private int nombreDePages; private boolean illustrations; ... }
CREATE TABLE LIVRE ( ID BIGINT not null, TITRE_LIVRE VARCHAR(255) not null, PRIX DOUBLE(5, 2), DESCRIPTION VARCHAR(2000), ISBN VARCHAR(255), NOMBRE_PAGES INTEGER not null, ILLUSTRATION SMALLINT, primary key (ID) );
Notez que ceci n'implique pas que l'entité ne pourra être modifiée en mémoire - elle pourra l'être mais, en ce cas, elle ne sera plus synchronisée avec la base car l'instruction SQL qui sera produite (INSERT ou UPDATE) ne portera pas sur ces colonnes.
De la même manière, les types java.util.Date ou java.util.Calendar utilisés pour définir des propriétés dites temporelles peuvent être paramétrées pour spécifier le format le plus adéquat à sa mise en persistance, en faisant le choix entre la date, l'heure ou des millisecondes. Ceci peut être précisé grâce à l'annotation @javax.persistence.Temporal qui prend en paramètre en TemporalType (énumération) dont les valeurs sont les suivantes :
@Temporal(TemporalType.DATE) private Calendar dateDeNaissance;
@Entity public class Photo implements java.io.Serializable { @Id private String id; @Temporal(TemporalType.TIMESTAMP) private Date instant; private int largeur; private int hauteur; private long poids; ... }
CREATE TABLE PHOTO ( ID VARCHAR(255) not null, INSTANT TIMESTAMP, LARGEUR INTEGER, HAUTEUR INTEGER, POIDS BIGINT, primary key (ID) );
Avec JPA, tous les attributs d'une classe annotée par @Entity sont sont automatiquement associés à une table. Si vous ne souhaitez pas associer un attribut particulier, utilisez l'annotation @javax.persistence.Transient.
@Entity public class Personnel implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private String téléphone; @Temporal(TemporalType.DATE) private Date naissance; @Transient private int âge; // cet attribut n'aura pas de colonne AGE associée ... }
CREATE TABLE PERSONNEL ( ID BIGINT not null, NOM VARCHAR(255), PRENOM VARCHAR(255), EMAIL VARCHAR(255), TELEPHONE VARCHAR(255), NAISSANCE DATE, primary key (ID) );
Depuis J2SE 5.0, le langage Java apporte un nouveau type de données : les énumérations. Ce type existe depuis plusieurs années au sein des bases de données. Il est enfin possible de les utiliser dans les beans entités. L'énumération permet de spécifier un ensemble de valeurs possibles pour une propriété. Par exemple, le sexe d'un utilisateur ne peut prendre que deux valeurs possibles : Masculin ou Féminin. La solution idéale dans cette situation est bien entendu l'utilisation de l'énumération. La valeur d'une énumération peut être enregistrée soit via une chaîne de caractères soit via un entier. L'annotation @Enumerated prend en paramètre un objet EnumType qui définit la façon de stocker cette valeur. Les valeurs EnumType.STRING ou EnumType.ORDINAL sont utilisées respectivement pour l'enregistrement dans une chaîne de caractères ou dans un entier.
@Entity public class Utilisateur implements Serializable { public enum Sexe {Masculin, Féminin}; @Enumerated(value=EnumType.STRING) public Sexe sexe; ... }
public enum TypeCarteCrédit { Visa, MasterCard, AmericanExpress }
Les numéros affectés lors de la compilation aux valeurs de ce type énuméré seront respectivement :
Par défaut, les fournisseurs de persistance associerons ce type énuméré à la base de données en supposant que la colonne est de type INTEGER. Le code source suivant montre l'entité CarteCrédit qui utilise l'énumération précédente avec une association par défaut :
@Entity public class CarteCrédit { @Id private String numéro; private String dateExpiration; private int numéroControl; private TypeCarteCrédit typeCarte; ... }
Les règles par défaut feront que l'énumération sera associée à une colonne de type entier et tout ira bien. Imaginons maintenant que nous ajoutions une nouvelle constante au début de l'énumération. L'affectation des numéros dépendant de l'ordre d'apparition des constantes, les valeurs déjà stockées dans la base de données ne correspondront plus à l'énumération.
Une meilleure solution consiste donc à stocker le nom de la constante à la place de son numéro d'ordre. C'est ce que nous proposons avec l'annotation @Enumerated avec la valeur STRING (sa valeur par défaut est ORDINAL).
@Entity public class CarteCrédit { @Id private String numéro; private String dateExpiration; private int numéroControl; @Enumerated(value=EnumType.STRING) private TypeCarteCrédit typeCarte; ... }
Désormais, la colonne TYPECARTE de la table sera de type VARCHAR et une carte Visa sera stockée sous la forme "Visa".
Les collections sont très utilisées en Java. Lors de cette étude, nous aurons l'occasion d'étudier les relations entre entités (qui peuvent être des collections d'entités) : essentiellement, ceci signifie qu'une entité contient une collection d'autres entités ou d'objets intégrables. En terme d'association, chaque entité est associée à sa propre table et nous créons alors des références entre les clés primaires et les clés étrangères.
Dans de nombreux cas, il n'est pas toujours nécessaire de créer plusieurs entités alors qu'une seule peut suffire. Comme vous le savez, une entité est une classe Java avec une identité et de nombreux attributs : mais la question qui se pose c'est comment faire pour stocker dans une base de données un attribut qui représente une simple collection de types Java comme les String et/ou des Integer ?
Depuis JPA 2.0, intégré dans Java EE6, il n'est plus nécessaire de créer spécifiquement une classe distincte pour encapsuler ces collections, car nous disposons de nouvelles annotations @ElementCollection et @CollectionTable.
@Entity public class Personnel implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private ArrayList<String> téléphones = new ArrayList<String>(); @Temporal(TemporalType.DATE) private Date naissance; @Transient private int âge; ... }
La première démarche consiste à ne placer aucune annotation sur l'attribut téléphones. La base de données considère alors, vu qu'il s'agit d'une collection et qu'il peut y avoir un nombre conséquent de valeurs, qu'il est préférable de prendre le type BLOB au niveau de la colonne représentant ces informations.
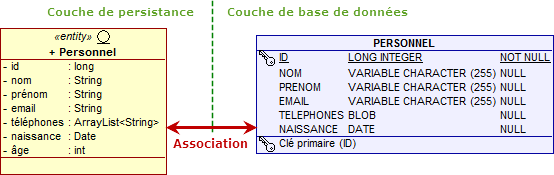
En effet, java.util.ArrayList implémente l'interface Serializable et JPA sait associer automatiquement des objets sérializables à des BLOB. En revanche, si vous utilisez une collection java.util.List, vous obtiendrez alors une exception car List n'implémente justement pas Serializable.
Cela fonctionne parfaitement. Le problème de ce choix toutefois, c'est qu'il est alors très difficile de consulter au niveau de la table le contenu d'une telle colonne.
@Entity public class Personnel implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @ElementCollection private ArrayList<String> téléphones = new ArrayList<String>(); @Temporal(TemporalType.DATE) private Date naissance; @Transient private int âge; ... }
L'annotation @ElementCollection informe le fournisseur de persistance que l'attribut téléphones est une liste de chaînes qui devra être enregistrée dans une table séparée dont le nom est par défaut PERSONNEL_TELEPHONES avec deux colonnes, d'une part PERSONNEL_ID qui représente la clé primaire de la table PERSONNEL et TELEPHONES qui stocke l'ensemble des numéros.
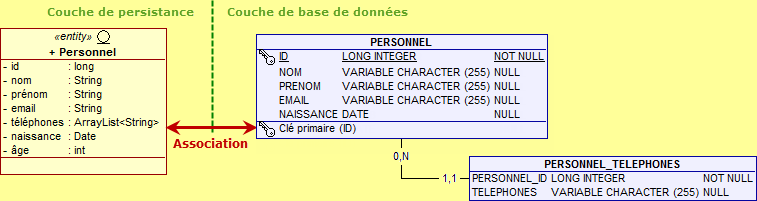
L'annotation @ElementCollection est un moyen plus élégant et plus pratique de stocker les types primitifs puisque cette fois-ci nous visualisons parfaitement chacun des numéros de téléphone alors que le stockage sous un format binaire opaque aux requêtes les rends inaccessibles.
@Entity public class Personnel implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @ElementCollection(fetch = FetchType.EAGER) private ArrayList<String> téléphones = new ArrayList<String>(); @Temporal(TemporalType.DATE) private Date naissance; @Transient private int âge; ... }
Attention, les collections sont gérées de façon paresseuse au niveau de la base de données. Si vous voulez être sûr que vos numéros soient immédiatement enregistrés, il serait alors préférable de stipuler la valeur FetchType.EAGER sur l'attribut fetch de @ElementCollection.
@Entity public class Personnel implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @ElementCollection(fetch = FetchType.EAGER) @CollectionTable(name = "Téléphones") @Column(name = "Numéro") private ArrayList<String> téléphones = new ArrayList<String>(); @Temporal(TemporalType.DATE) private Date naissance; @Transient private int âge; ... }
En l'absence de @CollectionTable, nous l'avons vu, le nom de la table est PERSONNEL_TELEPHONES. Grâce à cette annotation, il est tout-à-fait possible de choisir explicitement le nom de la table représentant la collection juste en spécifiant l'attribut name. Vous remarquez que j'ai ajouté une annotation @Column supplémentaire afin de renommer également la colonne en Numéro au lieu de Téléphones.
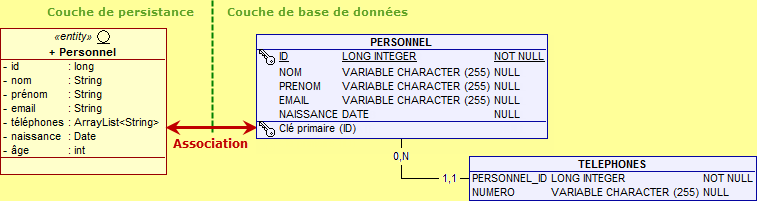
Voici le résultat obtenu en tenant compte de ces modifications. Personnellement, je trouve que les noms proposés par défaut sont assez évocateurs et j'utilise assez rarement cette annotation @CollectionTable.
Comme les collections, les tables de hachage, communément appelées les cartes, sont très utiles pour le stockage des données. Avec JPA 1.0, nous pouvions pas en faire grand chose en terme d'ORM. Désormais, les cartes peuvent utiliser n'importe quelle combinaison de types de base, d'objets intégrables et d'entités comme clés ou comme valeurs : ceci apporte beaucoup de souplesse. Pour l'instant, nous nous intéressons uniquement aux cartes qui utilisent les types de base.
Lorsqu'une carte emploie des types de base, vous pouvez vous servir des annotations @ElementCollection et @CollectionTable exactement comme nous venons de le voir pour les collections. En ce cas, les données relatives aux cartes sont également stockées dans une table spécifique, la table de collection.
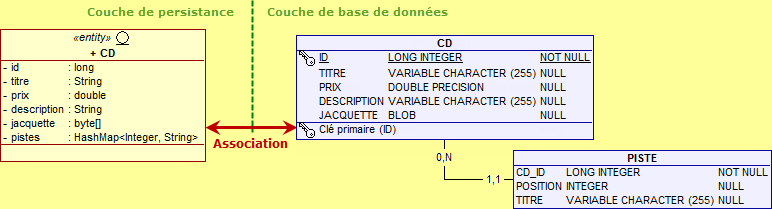
@Entity public class CD implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; @Lob private byte[] jacquette; private String description; private HashMap<Integer, String> pistes = new HashMap<Integer, String>(); ... }
Comme précédemment, je propose de ne spécifier aucune annotation particulière sur l'attribut pistes. Là aussi, la colonne représentative PISTES de la table CD est alors de type BLOB :
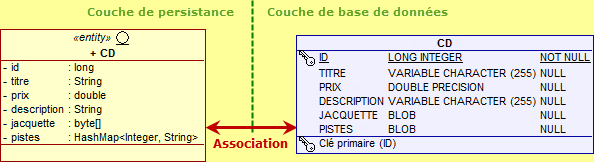
Là aussi, nous obtenons qu'une seule table qui possède alors toutes les caractéristiques. Cela peut suffire et fonctionne parfaitement. Ceci dit, encore une fois, la colonne représentant les pistes est totalement illisible (mais ce n'est peut-être pas un problème).
@Entity public class CD implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; @Lob private byte[] jacquette; private String description; @ElementCollection(fetch = FetchType.EAGER) @CollectionTable(name = "Piste") @MapKeyColumn(name = "Position") @Column(name = "Titre") private HashMap<Integer, String> pistes = new HashMap<Integer, String>(); ... }
Dans le chapitre sur "les clés primaires composées" plus haut dans cette étude, nous avons rapidement vu comment une classe pouvait être intégrée pour servir de clé primaire avec l'annotation @EmbeddedId.
Les objets intégrables sont des objets qui n'ont pas d'identité persistante par eux-mêmes. Une entité peut contenir des collections d'objets intégrables ainsi qu'un simple attribut d'une classe intégrable : dans les deux cas, ils seronts stockés comme faisant partie de l'entité et partageront son identité. Ceci signifie que chaque attribut de l'objet intégré est associé à la table de l'entité.
Il s'agit donc d'une relation de propriété stricte (agrégation forte ou composition). Ainsi, quand l'entité est supprimée, l'objet intégré disparaît également.
Cette composition entre deux classes passe par des annotations.
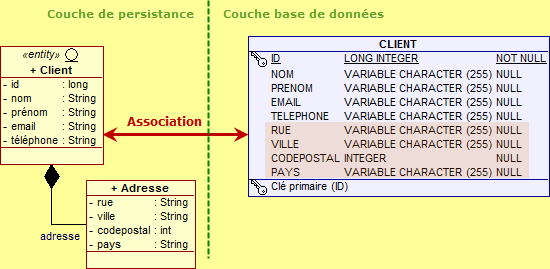
@Embeddable public class Adresse { private String rue; private String ville; private int codepostal; private String pays; ... }
Comme vous pouvez le constater à la lecture de ce code source, la classe Adresse est annotée comme étant non pas une entité mais une classe intégrable - l'annotation @Embeddable indique qu'Adresse peut être intégrée dans une entité (ou dans une autre classe intégrable). A l'autre extrémité de la composition, l'entité Client doit utiliser l'annotation @Embedded pour indiquer qu'Adresse est un attribut persistant qui sera stockée comme composante interne et qu'il partage son identité.
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private String téléphone; @Embedded private Adresse adresse; ... }
Chaque attribut d'Adresse est associé à la table de l'entité Client. Nous disposerons ainsi d'une seule table qui fusionne l'ensemble des attributs des deux classes.
Nous venons d'étudier toutes sortes d'annotations permettant de mapper une classe (ou plusieurs) dans une seule table. Le monde orienté objet regorge aussi de relations entre les classes, agrégation comme nous venons de la voir, associations unidirectionnelles, associations multiples, héritage, etc. Il est possible de rendre persistante cette information de telle sorte qu'une classe peut être liée à une autre dans un modèle relationnel.
Il s'avère qu'une entité ne travaille généralement pas seule mais qu'elle est reliée à d'autres entités. On parle de relations entre entités. Cela correspond, bien entendu, à une base de données relationnelle où les tables sont effectivement en relations les unes avec les autres.
client.getAdresse().getPays();nous navigons d'un objet de type Client vers un objet de type Adresse puis vers un objet de type Pays.
En UML, une relation :
En Java, une relation qui représente plusieurs objets utilise les collections de :
Ces types de conteneur sont en réalités des interfaces. Il faudra bien sur prévoir des conteneurs concrets en correspondance avec l'interface choisie. Ainsi par exemple, nous pourrons créer un conteneur de type ArrayList lorsque nous choisissons l'interface Collection.
Une relation possède un propriétaire. Dans une relation unidirectionnelle, ce propriétaire est implicite. Dans une relation bidirectionnelle, il faut en revanche l'indiquer explicitement en désignant le côté propriétaire, qui spécifie l'association physique, et le côté opposé (non propriétaire).
Au cours de ce chapitre, nous verrons comment associer des collections d'objets à l'aide des annotations JPA.
Dans le monde relationnel, les choses sont différentes puisque, à proprement parler, une base de données relationnelle est un ensemble de relations (également appelées tables) : tout est modélisé sous forme de table - pour modéliser une relation, vous ne disposez ni de listes, ni d'ensembles, ni de cartes : vous ne possédez que des tables.
Ainsi, une relation entre deux classes Java sera représentée dans la base de données par une référence à une table qui peut être modélisée de deux façons :
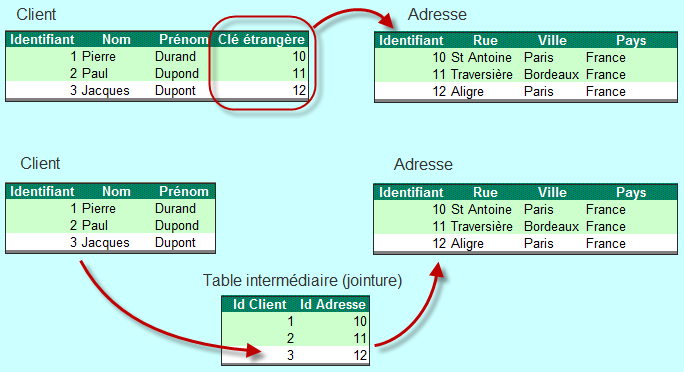
Nous n'utilisons jamais de table de jointure pour représenter une relation 1-1 car cela pourrait avoir des conséquences sur les performances (il faudrait effectivement toujours accéder à la troisième table pour obtenir l'adresse d'un client) ; elles sont généralement réservées aux relations 1-N ou N-M.
Comme nous le verrons par la suite, JPA utilise ces deux méthodes pour associer les relations entre les objets à une base de données.
.
Revenons maintenat à JPA. La plupart des entités doivent pouvoir référencer ou être en relation avec d'autres entités. JPA permet d'associer ces relations de sorte qu'une entité puisse être liée à une autre dans un modèle relationnel.
Comme pour les annotations d'associations élémentaires, que nous avons déjà étudiées, JPA utilise une configuration par exception pour ces relations : il utilise un mécanisme par défaut pour stocker une relation mais, si cela ne convient pas, vous disposez de plusieurs annotations pour adapter l'association à vos besoins.
Les annotations correpondantes aux cardinalités d'une relation entre deux entités sont les suivantes, en sachant que chacune d'elles peut être utilisée de façon unidirectionnelle ou bidirectionnelle :
Du point de vue de la modélisation objet, la direction entre les classes est naturelle. Dans une relation unidirectionnelle, un objet de type Classe1 pointe uniquement vers un objet de type Classe2, alors que dans une relation bidirectionnelle, ils se font mutuellement référence.
Cependant, comme le montre l'exemple suivant d'un client et de son adresse, un peu de travail est nécessaire lorsque nous désirons représenter une relation bidirectionnelle dans une base de données.
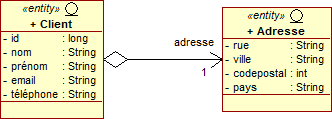
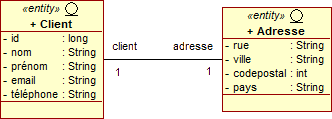
En termes de Java et d'annotations, ceci revient à posséder deux associations de type 1-1 dans les deux directions opposées. Nous pouvons donc considérer une relation bidirectionnelle comme une paire de relations unidirectionnelles dans les deux sens.
Comment associer une bidirectionnalité à une base de données ? Qui est le propriétaire de cette relation bidirectionnelle ? A qui appartient l'information sur la colonne ou la table de jointure ? Posons-nous ces questions une fois pour toutes. Les cas les plus fréquents restent l'unidirectionnalité que nous traiterons par la suite. Pour une fois, nous commençons par le plus difficile (ce qui est très relatif).
Si les relations unidirectionnelles possèdent un côté propriétaire, les bidirectionnelles ont à la fois un côté propriétaire et un côté opposé, qui doivent impérativement être indiqué explicitement par l'élément mappedBy des annotations @OneToOne, @OneToMany et @ManyToMany. mappedBy identifie ainsi l'attribut priopriétaire de la relation : il est obligatoire pour les relations bidirectionnelles.
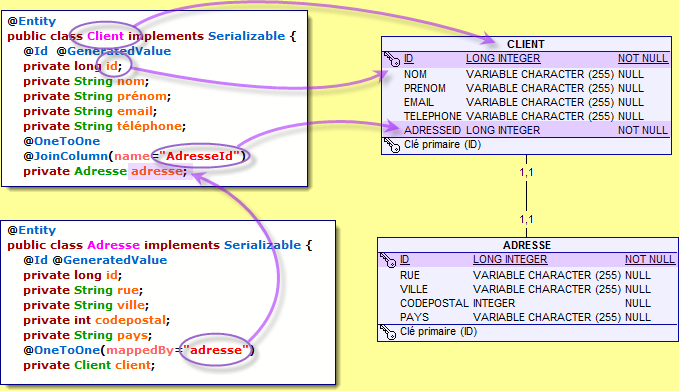
Il existe un élément mappedBy pour les annotations @OneToOne, @OneToMany et @ManyToMany, mais pas pour @ManyToOne.
.
Maintenant que nous connaissons comment gérer la bidirectionnalité, revenons à des cas plus classiques. Une relation 1-1 est utilisée pour lier deux entités uniques indissociables. Par exemple, un corps ne possède qu'un seul coeur, ou une personne n'a qu'une seule carte d'identité. Une relation 1-1 unidirectionnelle entre deux entités a une référence de cardinalité 1 qui ne peut être atteinte que dans une seule direction.
En Java, ceci signifie que la classe Client possède tout simplement un attribut adresse.
.
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private String téléphone; private Adresse adresse; ... }
@Entity public class Adresse { @Id @GeneratedValue private long id; private String rue; private String ville; private int codepostal; private String pays; ... }
Comme vous pouvez le constater à la lecture de ces différents codes sources, ces deux entités utilisent un nombre minimal d'annotations - @Entity plus @Id et @GeneratedValue pour la clé primaire, c'est tout ...
Grâce à la configuration par exception, le fournisseur de persistance les associera à deux tables et ajoutera une clé étrangère pour représenter la relation (allant du client à l'adresse). Cette relation 1-1 est déclenchée par le fait qu'Adresse est déclarée comme une entité et qu'elle est incluse dans l'entité Client sous forme d'un attribut. Nous n'avons donc pas besoin d'annotation @OneToOne parce que le comportement par défaut suffit.
Comme vous le savez, si un attribut n'est pas annoté, JPA lui applique les règles d'association par défaut. Ainsi, la colonne de la clé étrangère s'appelera donc ADRESSE_ID, qui est la concaténation du nom de l'attribut (adresse, ici), d'un underscore et du nom de la clé primaire de la table de destination (ici, la colonne ID de la table ADRESSE). Notez également que, dans le langage de définition des données, la colonne ADRESSE_ID peut, par défaut, recevoir des valeurs NULL : par défaut, une relation 1-1 est donc associée à zéro (NULL) ou une valeur :

package javax.persistence; import java.lang.annotation.*; @Target(value = {ElementType.METHOD, ElementType.FIELD}) @Retention(value = RetentionPolicy.RUNTIME) public @interface OneToOne { public Class targetEntity() default void.class; public CascadeType[] cascade() default {}; public FetchType fetch() default FetchType.EAGER; public boolean optional() default true; public String mappedBy() default ; public boolean orphanRemoval() default false; }
package javax.persistence; import java.lang.annotation.*; @Target(value = {ElementType.METHOD, ElementType.FIELD}) @Retention(value = RetentionPolicy.RUNTIME) public @interface JoinColumn { public String name() default ; public String referencedColumnName() default ; public boolean unique() default false; public boolean nullable() default true; public boolean insertable() default true; public boolean updatable() default true; public String columnDefinition() default ; public String table() default ; }
Le codage suivant présente un exemple d'utilisation de ces deux méthodes :
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private String téléphone; @OneToOne(cascade=CascadeType.PERSIST)
@JoinColumn(name="AdresseId", nullable=false) private Adresse adresse; ... }
Le code précédent, grâce à l'annotation @JoinColumn permet de renommer la colonne de la clé étrangère en ADRESSEID et rendre la relation obligatoire en refusant les valeurs NULL. L'annotation @OneToOne quant à elle, demande au fournisseur de persistance d'enregistrer automatiquement l'adresse lorsque nous rendons persistant un client.

Dans certain cas très particulier, il peut être possible de faire en sorte que les deux tables possèdent la même clé primaire pour identifier leurs propres éléments respectifs. Cela permet d'éviter de manipuler une clé étrangère, et donc de s'affranchir d'une colonne supplémentaire. Vous pouvez alors préciser ce choix au travers de l'annotation @PrimaryKeyJoinColumn (jointure par clé primaire).
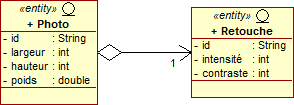
@Entity public class Photo implements java.io.Serializable { @Id private String id; private int largeur; private int hauteur; private long poids; @OneToOne(cascade=CascadeType.PERSIST)
@PrimaryKeyJoinColumn private Retouche retouche; ... }
@Entity public class Retouche implements java.io.Serializable { @Id private String id; private int intensité; private int contraste; ... }
J'aimerais faire quelques remarques quand à la persistance de deux entités quelque soit la stratégie de l'élaboration de chacune des tables :
Attention, dans ce genre de situation, vous devez gérer vous-même l'identifiant commun. Vous ne pouvez pas demander une génération automatique de vos clés primaires à l'aide de l'annotation @GeneratedValue.
Voici la constitution des deux tables au niveau de la base de données associées à ces deux entités respectives :

Une relation Un à Zéro est implémentée de la même manière qu'une relation Un à Un. La seule différence réside dans le fait qu'elle est optionnelle.
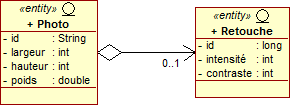
Pour transformer une relation Un à Un en une relation Un à Zéro, il suffit d'autoriser la valeur null dans la colonne implémentant la relation. Pour cela, il est nécessaire de positionner l'attribut nullable de l'annotation @JoinColumn à true. En réalité, c'est la valeur par défaut. Nous n'avons donc pas besoin de le spécifier.
Attention, l'annotation @PrimaryKeyJoinColumn ne possède pas un tel attribut, ce qui sous-entends que l'aspect facultatif ne peut pas être prise en compte et que la seule relation possible dans ce cas là, ne peut être qu'une relation de type 1-1. Finalement, si vous désirez intégrer le caractère facultatif d'un élément, vous êtes obligé de passer par une clé étrangère.
@Entity public class Photo implements java.io.Serializable { @Id private String id; private int largeur; private int hauteur; private long poids; @OneToOne(cascade=CascadeType.PERSIST)
@JoinColumn(nullable=true) private Retouche retouche; ... }
@Entity public class Retouche implements java.io.Serializable { @Id @GeneratedValue private long id; private int intensité; private int contraste; ... }
Attention, dans l'entité Retouche, il est préférable de prendre un identifiant de type long avec une génération automatique.
.
Voici la constitution des deux tables dans la base de données associées à ces deux entités respectives :

Dans une relation 1-N, l'entité source référence un ensemble d'entités cibles. Une commande, par exemple, est composée d'un ensemble d'articles. cela peut être évoqué au moyen de l'annotation @OneToMany. Inversement, un article pourrait faire référence à la commande dont elle fait partie à l'aide, cette fois-ci, d'une annotation @ManyToOne.
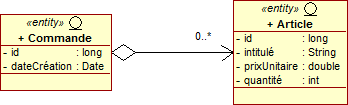
La cardinalité est multiple et la navigation ne se fait que dans le sens Commande vers Article. En Java, cette multiplicité est décrite par les interfaces Collection, List et Set du paquetage java.util.
@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; private List<Article> articles = new ArrayList<Article>(); ... }
@Entity public class Article implements java.io.Serializable { @Id @GeneratedValue private long id; private String intitulé; private double prixUnitaire; private int quantité; ... }
Comme vous pouvez le constater à la lecture du code relatif à l'entité Commande, nous n'avons placé aucune annotation particulière sur la collection d'articles. Comme toujours, cela veut dire que nous restons dans une configuration par exception.

Comme précédemment, si vous n'aimez pas le nom de la table de jointure ou celui des clés étrangères, ou si vous désirez associer la relation à une table existante, vous pouvez vous servir des annotations JPA pour redéfinir ces valeurs par défaut.
package javax.persistence; import java.lang.annotation.*; @Target(value = {ElementType.METHOD, ElementType.FIELD}) @Retention(value = RetentionPolicy.RUNTIME) public @interface JoinTable { public String name() default ; public String catalog() default ; public String schema() default ; public JoinColumn[ ] joinColumns() default { }; public JoinColumn[ ] inverseJoinColumns() default { }; public UniqueConstraint[ ] uniqueConstraints() default { }; }
Dans l'API de l'annotation @JoinTable, vous pouvez remarquer deux attributs de type @JoinColumn : joinColumns et inverseJoinColumns. Ils permettent de différencier l'extrémité propriétaire de la relation et son extrémité opposée. L'extrémité propriétaire de la relation est décrite dans l'élément joinColumns et, dans notre exemple, désigne la table COMMANDE. L'extrémité opposée, la cible de la relation, est précisée par l'élément inverseJoinColumns et désigne la table ARTICLE.
@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; @JoinTable(name="ArticlesCommandés",
joinColumns=@JoinColumn(name="NuméroCommande"),
inverseJoinColumns=@JoinColumn(name="Article")) private List<Article> articles = new ArrayList<Article>(); ... }

@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; @JoinColumn private List<Article> articles = new ArrayList<Article>(); ... }

Le nom d'une colonne de jointure est formée par défaut par la concaténation du nom de l'attribut associé à l'annotation @JoinColumn, de l'underscore et du nom de la clé primaire désignée par la clé étrangère (ARTICLES_ID). Il est tout à fait possible de paramétrer le nom de cette colonne en renseignant l'attribut name de l'annotation @JoinColumn :
@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; @JoinColumn(name="NuméroCommande") private List<Article> articles = new ArrayList<Article>(); ... }

Attention, le mode de parcours par défaut dans une relation 1-N est le mode paresseux. Si vous désirez systématiquement avoir à votre possession l'ensemble des articles constituant une commande en spécifiant le mode EAGER dans l'annotation @OneToMany. Comme précédemment, vous pouvez également en profiter pour imposer une persistance automatique de l'ensemble des articles au moment de la persistance de la commande.
@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; @OneToMany(fetch=FetchType.EAGER, cascade=CascadeType.ALL) @JoinColumn(name="NuméroCommande") private List<Article> articles = new ArrayList<Article>(); ... }
Une relation N-M bidirectionnelle intervient lorsqu'un objet source fait référence à plusieurs cibles et qu'une cible fait elle-même référence à plusieurs sources. Un album CD, par exemple, est créé par plusieurs artistes, et un même artiste peut apparaître sur plusieurs albums.
@Entity public class Artiste implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; @ManyToMany private List<CD> présentSurCDs = new ArrayList<CD>(); ... }
@Entity public class CD implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; private String description; @ManyToMany(mappedBy="présentSurCds") private List<Artiste> artistes = new ArrayList<Artiste>(); ... }
La structure de la base de données obtenue est la suivante :
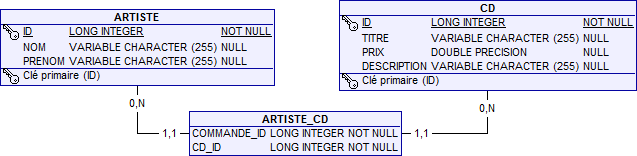
Dans une relation N-M et 1-1 bidirectionnelle, chaque entité peut, en fait, être considérée comme la propriétaire de la relation. Quoi qu'il en soit, l'autre extrémité doit inclure l'élément mappedBy : dans le cas contraire, le fournisseur considérera que les deux extrémités sont propriétaires et traitera cette relation comme deux relations 1-N unidirectionnelles distinctes. Ici, cela produirait donc quatre tables : ARTISTE et CD et deux tables de jointures, ARTISTE_CD et CD_ARTISTE. Vous comprenez bien que nous ne pouvons pas non plus utiliser un élément mappedBy des deux côtés de la relation.
Toutes les annotations que nous venons de découvrir (@OneToOne, @OneToMany, @ManyToOne et @ManyToMany) définissent un attribut de chargement qui précise que les objets associés doivent être chargés immédiatement (chargement "glouton") ou plus tard (chargement "paresseux") et qui influe donc sur les performances.
Vous pouvez optimiser les performances en chargeant les données de la base lors de la première lecture de l'entité (glouton) ou uniquement lorsqu'elle est utilisée (paresseux).
Chaque annotation possède une stratégie de chargement par défaut que nous devons connaître et qu'il est souhaitable de pouvoir modifier si cela ne convient pas. Nous pouvons donc changer ce comportement au travers du paramètre fetch qui peut prendre les deux valeurs : LAZY (paresseux) ou EAGER (glouton).
| Annotation | Stratégie de chargement par défaut |
| @OneToOne | EAGER |
| @ManyToOne | EAGER |
| @OneToMany | LAZY |
| @ManyToMany | LAZY |
A titre d'exemple, prenons deux cas extrèmes :


Le paramètre fetch est finalement très important car, mal utilisé, il peut pénaliser les performances.
.
Lorsque, par exemple, vous chargez une commande dans votre application, vous avez toujours besoin d'accéder aux différents articles de cette commande. Il est donc plutôt avantageux de changer le mode de chargement par défaut de l'annotation @OneToMany en EAGER.
@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; @OneToMany(fetch=FetchType.EAGER, cascade=CascadeType.ALL) @JoinColumn(name="NuméroCommande") private List<Article> articles = new ArrayList<Article>(); ... }
Avec les relations 1-N, les entités gèrent des collections d'objets. Du point de vue de Java, ces collections ne sont généralement pas triées et les bases de données relationnelles ne garantissent pas non plus d'ordre sur leurs tables. Si vous désirez obtenir une liste triée, vous devez donc soit trier la collection dans votre programme, soit utiliser une requête JPQL avec une clause Order By. Pour le tri des relations, JPA dispose de mécanismes plus simples reposant sur les annotations.
L'annotation @OrderBy permet de réaliser un tri dynamique à la volée : les éléments de la collection seront ainsi triés lors de leur récupération à partir de la base de données.
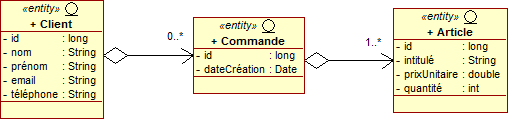
Dans l'entité Client, nous trions la liste des commandes par ordre décroissant des dates de création de chaque commande, en combinant l'annotation @OrderBy avec l'annotation @OneToMany.
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private String téléphone; @OneToMany(fetch=FetchType.EAGER)
@OrderBy("dateCréation desc") private Commande commandes; ... }
@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; @OneToMany(fetch=FetchType.EAGER, cascade=CascadeType.ALL) @JoinColumn(name="NuméroCommande") private List<Article> articles = new ArrayList<Article>(); ... }
L'annotation @OrderBy prend en paramètre les noms des attributs sur lesquels portera le tri (dateCréation, ici) et la méthode (représentée par la chaîne ASC ou DESC, pour signifier, respectivement, un tri croissant ou décroissant). Vous pouvez utiliser plusieurs paires attribut/méthode en les séparant par des virgules : immaginons, par exemple, qu'une entité supérieure ait besoin de trier les clients ; d'abord suivant leurs noms et ensuite suivant leurs prénoms. Voici ce que nous pourrions placer sur un attribut représentant une collection de clients.
@OrderBy("nom asc", "prénom asc")
Cette annotation n'a aucun impact sur l'association dans la base de données - le fournisseur de persistance est simplement informé qu'il doit utiliser une clause order by lorsque la collection est récupérée.
JPA 1.0 supportait le tri dynamique avec l'annotation @OrderBy mais ne permettait pas de maintenir un ordre persistant. JPA 2.0 règle ce problème à l'aide d'une nouvelle annotation, @OrderColumn, qui informe le fournisseur de persistance qu'il doit gérer la liste triée à l'aide d'une colonne séparée contenant un index.
L'API de @OrderColumn est semblable à celle de @Column :
package javax.persistence; import java.lang.annotation.*; @Target(value = {ElementType.METHOD, ElementType.FIELD}) @Retention(value = RetentionPolicy.RUNTIME) public @interface OrderColumn { public String name() default ; public boolean nullable() default true; public boolean insertable() default true; public boolean updatable() default true; public String columnDefinition() default ; public boolean contiguous() default true; public int base() default 0; public String table() default ; }
Dans l'entité Client, nous pouvons alors annoter la relation avec les commandes avec @OrderColumn afin que cette fois-ci le fournisseur de persistance associe l'entité Client à une table contenant une colonne supplémentaire pour stocker l'ordre.
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private String téléphone; @OneToMany(fetch=FetchType.EAGER)
@OrderColumn private Commande commandes; ... }
@Entity public class Commande implements java.io.Serializable { @Id @GeneratedValue private long id; @Temporal(TemporalType.TIMESTAMP) private Date dateCréation; @OneToMany(fetch=FetchType.EAGER, cascade=CascadeType.ALL) @JoinColumn(name="NuméroCommande") private List<Article> articles = new ArrayList<Article>(); ... }
L'annotation @OrderColumn prend éventuellement en paramètre le nom de la nouvelle colonne. Si ce nom n'est pas redéfini, cette colonne porte alors le nom formé de la concaténation de l'entité référencée et la chaîne _ORDER (COMMANDES_ORDER, ici). Le type de cette colonne doit absolument être numérique.
Cette annotation a des conséquences sur les performances car le fournisseur de persistance doit maintenant également gérer les modifications de l'index. Il doit maintenir le tri après chaque insertion, suppression ou réordonnacement. Si les données sont insérées au milieu d'une liste triée, le fournisseur devra retrier tout l'index.
Pour réaliser un tri, vous avez donc le choix entre ces deux annotations @OrderColumn et @OrderBy. Pour ma part, je préfère largement cette dernière puisqu'elle prend moins de ressources au niveau de la base de données. Par ailleurs, avec @OrderColumn, vous ne pouvait pas spécifier le critère d'ordonancement. Attention, quelque soit votre choix, ces deux annotations ne peuvent pas être utilisées en même temps.
L'héritage est une notion essentielle et fondamentale de la programmation objet qui se retrouve dans la quasi-totalité de tout les types d'applications. En programmation orientée objet, les développeurs réutilisent fréquemment le code existant en héritant des attributs et des comportements de classes existantes. Toutefois, la représentation relationnelle d'un héritage d'objets est tout à fait particulier au niveau des tables de la base de données.
Nous venons de voir que les relations entre entités ont des équivalents directs dans les bases de données. Ce n'est pas le cas avec l'héritage car ce concept est totalement inconnu du modèle relationnel. Il impose donc plusieurs contorsions pour être traduit dans un SGBDR.
Pour représenter un modèle hiérarchique dans un modèle relationnel plat, JPA propose alors trois stratégies possibles :
Le support de la stratégie une table pour chaque classe concrète est encore facultatif avec JPA 2.0. Les applications portables doivent donc l'éviter tant que ce support n'a pas été officiellement déclaré comme obligatoire dans toutes les implémentations.
Tirant parti de la simplicité d'utilisation des annotations, JP 2.0 fournit un support déclaratif pour définir et traduire les hiérérachies d'héritage comprenant des entités concrètes, des entités abstraites, des classes traduites et des classes transitoires.
L'annotation @Inheritance s'applique à une entité racine pour imposer une stratégie d'héritage à cette classe et à ses classes filles. JPA traduit aussi la notion objet de redéfinition qui permet aux attributs de la classe fille d'être redéfinis dans les classes filles.
JPA propose donc trois stratégies pour traduire l'héritage. Lorsqu'il existe une hiérarchie d'entités, sa racine est toujours une entité qui peut définir la stratégie d'héritage à l'aide de l'annotation @Inheritance. Si elle ne le fait pas, c'est la stratégie par défaut qui est appliquée, consistant à créer une seule table pout toute la hiérarchie.
Attention : une seule clé primaire doit être définie dans une hiérarchie. Elle est généralement déclarée dans la classe ancêtre afin que toutes les classes filles puissent en bénéficier.
Pour chaque cas, nous étudierons les annotations utilisées et la structure relationnelle engendrée. Ces annotations sont primordiales uniquement pour choisir l'organisation souhaitée au niveau de la base de données. Par contre, lorsque nous utilisons les beans entités, côté codage Java, nous restons dans une écriture et une utilisation tout à fait classique.
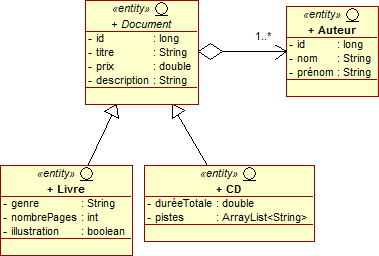
Document est l'entité racine ; elle possède un identifiant unique qui servira de clé primaire pour l'ensemble de la hiérarchie. La clé primaire sera ainsi automatiquement récupérée par le mécanisme d'héritage. Chacune de ses classes filles ajoute également ses propres attributs supplémentaires comme genre pour l'entité Livre et duréeTotale pour l'entité CD.
Il s'agit de la stratégie de traduction de l'héritage par défaut, dans laquelle toutes les entités de la hiérarchie sont mappées dans une même et unique table.
@Entity public abstract class Document implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; private String description; private Auteur auteur; ... }
Document est la classe parente des entités Livre et CD. Ces entités héritent des attributs de Document ainsi que de la stratégie d'héritage par défaut : elles n'ont donc pas besoin elles-même d'utiliser l'annotation @Inheritance.
@Entity public class Livre extends Document { private String genre; private int nombrePages; private boolean illustration; ... }
@Entity public class CD extends Document { private double duréeTotale; @ElementCollection private List<String> pistes = new ArrayList<String>(); ... }
Sans l'héritage, ces trois entités seraient traduites en trois tables distinctes. Avec la stratégie de traduction de l'héritage par une seule table, elles finiront toutes dans la table portant par défaut le nom de la classe racine : DOCUMENT.
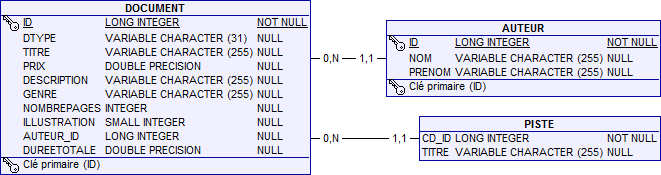
Comme vous pouvez le constater, la table DOCUMENT rassemble tous les attributs des entités Document, Livre et CD. Cependant, elle contient une colonne supplémentaire qui n'est liée à aucun des attributs des entités : la colonne discriminante, DTYPE.
La table DOCUMENT sera remplie de livres et de CD. Lorsqu'il accède aux données, le fournisseur de persistance doit savoir à quelle entité appartient chaque ligne afin d'instancier la classe d'objet appropriée (Livre ou CD) : la colonne discriminante est donc là pour préciser explicitement le type de chaque colonne.

La colonne discriminante, s'appelle DTYPE, par défaut, elle est de type String (traduit en VARCHAR avec une taille par défaut de 31) et elle contient tout simplement le nom de l'entité (ce qui offre une grande lisibilité au niveau de la table).
Si ce comportement par défaut ne vous convient pas, il est tout-à-fait possible d'utiliser l'annotation @DiscriminatorColumn pour modifier le nom et le type de cette colonne. Les attributs de cette annotation sont alors :
@Entity @DiscriminatorColumn(name="Document", discriminatorType=DiscriminatorType.CHAR) public abstract class Document implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; private String description; private Auteur auteur; ... }
L'entité racine Document définit la colonne discriminante pour toute la hiérarchie à l'aide de l'annotation @DiscriminatorColumn. Pour que cela fonctionne correctement, chaque entité fille doit uniquement redéfinir sa propre valeur discriminante au moyen de l'annotation @DiscriminatorValue.
@Entity @DiscriminatorValue("L") public class Livre extends Document { private String genre; private int nombrePages; private boolean illustration; ... }
@Entity @DiscriminatorValue("C") public class CD extends Document { private double duréeTotale; @ElementCollection private List<String> pistes = new ArrayList<String>(); ... }
Voici le résultat obtenu par rapport au choix que nous venons de réaliser :

Pour terminer, il est également possible de mapper cette colonne DOCUMENT sur un attribut (typeDocument) afin de pouvoir contrôler par programme les différents types d'objets enregistrés, à condition toutefois de bien préciser insertable=false et updatable=false :
@Entity @DiscriminatorColumn(name="Document", discriminatorType=DiscriminatorType.CHAR) public abstract class Document implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; private String description; private Auteur auteur; @Column(name="Document", insertable=false, updatable=false) private char typeDocument; ... }
Dans cette stratégie, chaque entité de la hiérarchie est associée à sa propre table. Ici, la classe ancêtre des entités est représentée par une table, avec, là aussi, une colonne discriminante.
Ainsi, chaque sous-classe est représentée par une table distincte contenant ses propres attributs (non hérités de la classe racine) et une clé primaire qui fait référence à celle de la table racine. Les classes filles n'ont, en revanche, pas de colonne discriminante.
Le seul attribut de cette annotation est strategy. Il permet de spécifier le type de stratégie à utiliser pour construire la ou les tables à mettre en oeuvre, via l'énumération InheritanceType.
Pour indiquer que nous désirons une stratégie par jointure, nous prenons le paramètre InheritanceType.JOINED dans l'annotation @Inheritance. Par contre, les classes filles n'ont pas besoin d'autre annotation que @Entity (sauf éventuellement l'annotation propre à la valeur du discriminant). A ce sujet, nous pouvons là aussi utiliser l'annotation @DiscriminatorColumn dans l'entité racine afin de personnaliser la colonne discriminante.
@Entity @Inheritance(strategy=InheritanceType.JOINED) @DiscriminatorColumn(name="Document", discriminatorType=DiscriminatorType.CHAR) public abstract class Document implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; private String description; private Auteur auteur; ... }
@Entity @DiscriminatorValue("L") public class Livre extends Document { private String genre; private int nombrePages; private boolean illustration; ... }
@Entity @DiscriminatorValue("C") public class CD extends Document { private double duréeTotale; @ElementCollection private List<String> pistes = new ArrayList<String>(); ... }
Du point de vue du développeur, la stratégie par jointure est naturelle car chaque entité, qu'elle soit abstraite ou concrète, sera traduite dans une table distincte.
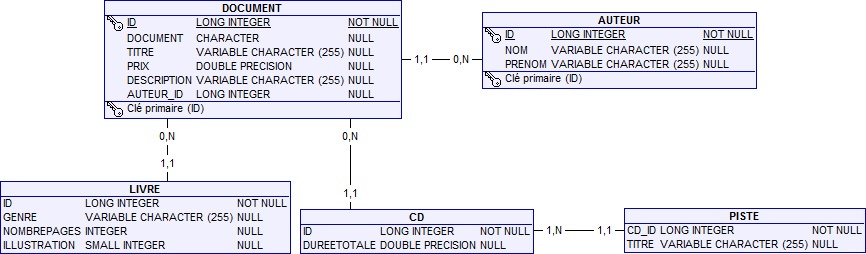
Dans cette stratégie (une table par classe concrête), chaque entité est traduite dans sa propre table, comme avec la stratégie par jointure. La différence est qu'ici tous les attributs de l'entité racine seront également traduits en colonnes de la table associée à l'entité fille. Cela signifie que toutes les propriétés de la classe (avec celles récupérées par héritage) sont incluses dans la table liée à cette entité. Ici, nous n'avons pas de table partagée, pas de colonne partagée ni de colonne discriminante. La seule exigence est que toutes les tables de la hiérarchie doivent partager la même clé primaire.
@Entity @Inheritance(strategy=InheritanceType.TABLE_PER_CLASS) public abstract class Document implements java.io.Serializable { @Id @GeneratedValue private long id; private String titre; private double prix; private String description; private Auteur auteur; ... }
@Entity public class Livre extends Document { private String genre; private int nombrePages; private boolean illustration; ... }
@Entity public class CD extends Document { private double duréeTotale; @ElementCollection private List<String> pistes = new ArrayList<String>(); ... }
Voici les tables obtenues. Vous remarquez que LIVRE et CD dupliquent les colonnes ID, TITRE, PRIX, DESCRIPTION et AUTEUR_ID de la table DOCUMENT et que les tables ne sont plus liées entre elles.

L'exemple utilisé pour expliquer les stratégies de traduction de l'héritage n'utilise que des entités, mais les entités n'héritent pas que d'entités. Une hiérarchie de classes peut contenir un mélange d'entités, de classes qui ne sont pas des entités (classes transitoires), d'entités abstraites et de superclasses déjà traduites. Hériter de ces différents types de classes a un impact sur la traduction de la hiérarchie.
Nous l'avons vu au travers de nos différents exemples, une classe abstraite comme Document peut tout-à-fait être désignée comme une entité. Elle ne diffère d'une entité concrète que parce qu'elle ne peut pas être directement instanciée, mais elle fournit une structure de données que partagerons toutes ses entités filles (Livre et CD) et elle respecte les stratégies de traduction d'héritage.
Du point de vue du fournisseur de persistance, la seule différence se situe du côté de Java, pas dans la correspondnce avec les tables.
.
Les non-entités sont également appelées classes transitoires. Une entité peut hériter d'une non-entité ou peut être étendue par une non-entité. La modélisation objet et l'héritage permettent de partager les états et les comportements ; dans une hiérachie de classes, les non-entités peuvent donc servir à fournir une structure de données commune à leurs entités filles.
L'état d'une superclasse non entité n'est pas persistant car il n'est pas géré par le fournisseur de persistance (n'oubliez pas que la condition pour qu'une classe le soit est la présence de l'annotation @Entity).
public abstract class Document implements java.io.Serializable { private String titre; private double prix; private String description; private Auteur auteur; ... }
L'entité Livre hérite toujours de Document ; le code Java peut donc accéder aux attributs titre, prix, description et auteur ainsi qu'à toutes les méthodes de Document. Que cette dernière soit concrète ou abstraite n'aura aucune influence sur la traduction finale.
@Entity public class Livre extends Document { @Id @GeneratedValue private long id; private String genre; private int nombrePages; private boolean illustration; ... }
Livre est une entité qui hérite de Document, mais seuls les attributs de Livre seront stockés dans une table. Aucun attribut de Document n'apparaît dans la structure de la table ci-dessous. Pour qu'un Livre soit persistant, vous devez créer une instance de Livre, initialiser les attributs que vous souhaitez (titre, prix, description, etc.), mais seuls ceux de Livre (genre, nombrePages, etc.) seront stockés.

JPA définit un type de classe spéciale, appelé superclasse "mapped", qui partage son état, son comportement ainsi que des informations de traduction des entités qui en héritent.
@MappedSuperclass @Inheritance(strategy=InheritanceType.JOINED) public abstract class Document implements java.io.Serializable { @Id @GeneratedValue private long id; @Column(length=50, nullable=false) private String titre; private double prix; @Column(length=2000) private String description; ... }
L'entité Livre hérite toujours de Document ; le code Java peut donc accéder aux attributs titre, prix, description et auteur ainsi qu'à toutes les méthodes de Document. Que cette dernière soit concrète ou abstraite n'aura aucune influence sur la traduction finale.
@Entity public class Livre extends Document { private String genre; private int nombrePages; private boolean illustration; ... }
Livre est une entité qui hérite encore de Document. Cette hiérarchie sera traduite en une seule table. Document n'est pas une entité et n'a donc aucune table associée. Les attributs de Document seront traduits en colonnes de la table LIVRE - les superclasses "mapped" partageant également leurs informations de traduction, les annotations @Column de Document seront donc également héritées.
