Gestion des objets persistants
Gestion des objets persistants
 Dans l'étude précédente, nous avons passé pas mal de temps à prendre connaissance des entités. Le gros avantage de ce type de bean c'est qu'il permet de s'occuper automatiquement de la sauvegarde dans une base de données alors que nous travaillons avec des objets. Ainsi, nous sommes en présence d'une base de données objet plutôt qu'une base de données relationnelle. Dans cette étude, nous allons prolonger nos connaissances dans ce type de base de données.
Dans l'étude précédente, nous avons passé pas mal de temps à prendre connaissance des entités. Le gros avantage de ce type de bean c'est qu'il permet de s'occuper automatiquement de la sauvegarde dans une base de données alors que nous travaillons avec des objets. Ainsi, nous sommes en présence d'une base de données objet plutôt qu'une base de données relationnelle. Dans cette étude, nous allons prolonger nos connaissances dans ce type de base de données.
L'API de persistance de Java, JPA, a deux aspects :
Le monde des bases de données relationnelles repose sur SQL. Ce langage de programmation a été conçu pour faciliter la gestion des données relationnelles (récupération, insertion, mise à jour et suppression), et sa syntaxe est orientée vers la manipulation de tables. Vous pouvez ainsi sélectionner des colonnes de tables constituées de lignes, joindre des tables, combiner les résultats de deux requêtes SQL à l'aide d'une union, etc. Ici, nous n'avons pas d'objets mais uniquement des lignes, des colonnes et des tables.
Dans le monde de Java, où nous manipulons des objets, un langage conçu pour les tables (SQL) doit être un peu déformé pour convenir à un langage à objets (Java). C'est là que JPQL (Java Persistence Query Language) entre en jeu. JPQL est le langage qu'utilise JPA pour interroger les entités stockées dans une base de données relationnelle. Sa syntaxe ressemble à celle de SQL mais opère sur des objets entités au lieu d'agir directement sur les tables. JPQL ne voit pas la structure de la base de données sous-jacente et ne manipule ni les tables ni les colonnes - uniquement des objets et des attributs.
Lors de cette étude, nous verrons comment gérer les objets persistants. Nous apprendrons comment réaliser les opérations CRUD (Create, Read, Update et Delete) avec le gestionnaire d'entités et créerons des requêtes complexes avec JPQL. La fin de l'étude expliquera comment JPA gère la concurrence d'accès aux données ainsi que le cycle de vie des entités.
JPA permet de faire correspondre les entités à des bases de données et de les interroger en utilisant différents critères. La puissance de cette API vient du fait qu'elle offre la possibilité d'interroger les entités et leurs relations de façon orientée objet sans devoir utiliser les clés étrangères ou les colonnes de la base de données sous-jacentes.
L'élément central de l'API, responsable de l'orchestration des entités, est le gestionnaire d'entité : son rôle consiste à gérer les entités, à lire et à écrire dans une base de données et à autoriser les opérations CRUD simples sur les entités, ainsi que des requêtes complexes avec JPQL.
import java.awt.image.BufferedImage; import java.util.Date; import javax.persistence.*; @Entity public class Photo { @Id private String id; @Temporal(TemporalType.TIMESTAMP) private Date instant; private int largeur; private int hauteur; private long poids; public String getId() { return id; } public int getHauteur() { return hauteur; } public Date getInstant() { return instant; } public int getLargeur() { return largeur; } public long getPoids() { return poids; } public Photo() { } public Photo(String nom, long poids) { id = nom; instant = new Date(); this.poids = poids; } public void setDimensions(BufferedImage image) { largeur = image.getWidth(); hauteur = image.getHeight(); } @Override public String toString() { return id++largeur++hauteur+; } }
L'entité Photo contient les informations pour l'association. Ici, elle utilise la plupart des valeurs par défaut : les données seront stockées dans une table portant le même nom que l'entité (PHOTO) et chaque attribut sera associé à une colonne homonyme.
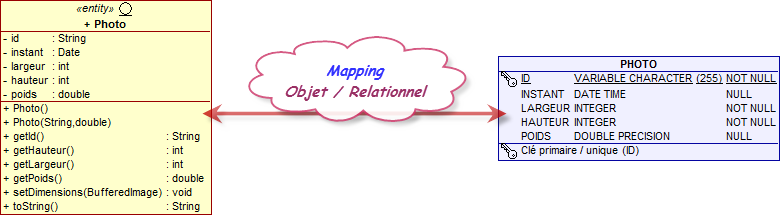
Nous pouvons maintenant utiliser un bean session qui utilise l'interface javax.persistence.EntityManager pour stocker, récupérer ou supprimer une instance de Photo dans la table.
package session; import java.util.List; import javax.ejb.*; import javax.persistence.*; import entité.Photo; import java.awt.image.BufferedImage; import java.io.*; import javax.imageio.ImageIO; @Stateless public class Archiver implements ArchiverRemote { private final String répertoire = ; @PersistenceContext(unitName="Photos-ejbPU") // s'il existe une seule unité de persistance, la désignation de son nom n'est pas obligatoire EntityManager persistance; @Override public void stocker(String nom, byte[] octets) throws IOException { File fichier = new File(répertoire+nom); if (fichier.exists()) return; FileOutputStream fluxphoto = new FileOutputStream(fichier); fluxphoto.write(octets); fluxphoto.close(); enregistrer(nom); } @Asynchronous private void enregistrer(String nom) throws IOException { File fichier = new File(répertoire+nom); BufferedImage image = ImageIO.read(fichier); Photo photo = new Photo(nom, fichier.length()); photo.setDimensions(image); persistance.persist(photo); } ... @Override public Photo getPhoto(String nom) { return persistance.find(Photo.class, nom); } @Override public void supprimer(String nom) { new File(répertoire+nom).delete(); Photo photo = getPhoto(nom); persistance.remove(photo); } }
Le bean session Archiver utilise des étapes fondamentales pour savoir stocker des informations sur une photo dans la base de données, de savoir ensuite les récupérer et éventuellement de les supprimer :
Dans l'analyse du code proposé ci-dessus, vous remarquez qu'il n'existe aucune requête SQL ou JPQL, ni d'appel JDBC. Le schéma ci-dessous nous rappelle les différentes interactions.
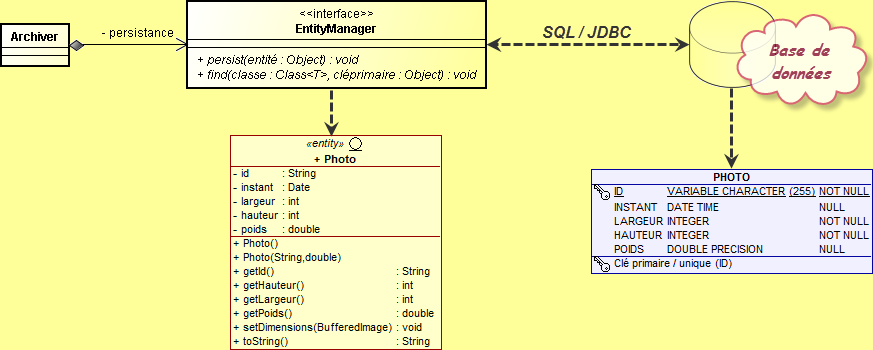
Le bean session Archiver interagit avec la base de données sous-jacente via l'interface EntityManager, qui fournit un ensemble de méthodes standard permettant de réaliser des opérations sur l'entité Photo. En coulisse, cet EntityManager utilise le fournisseur de persistance pour interagir avec la base de données. Lorsque nous appelons l'une des méthodes de l'EntityManager, le fournisseur de persistance produit et exécute une instruction SQL via le pilote JDBC correspondant.
Quel pilote JDBC utiliser ? Comment se connecter à la base ? Quel est le nom de la base ? Toutes ces informations sont absentes du code source précédent. Lorsque le bean session crée le gestionnaire d'entité, il lui passe le nom d'une unité de persistance en paramètre au travers de l'annotation @PersistenceContext - ici Photos-ejbPU. Cette unité de persistance indique au gestionnaire d'entités le type de la base à utiliser et les paramètres de connexion : toutes ces informations sont précisées dans le fichier prévu à cet effet, persistence.xml qui doit être déployé avec les classes.
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"> <persistence-unit name="PhotoListe-ejbPU" transaction-type="JTA"> <provider>org.eclipse.persistence.jpa.PersistenceProvider</provider> <jta-data-source>photo</jta-data-source> <properties> <property name="eclipselink.ddl-generation" value="create-tables"/> </properties> </persistence-unit> </persistence>
11 import javax.persistence.*; 12 13 public class Visionneuse extends JFrame implements ActionListener { 14 private static FichiersPhotoRemote fichiers; 15 private static EntityManagerFactory fabrique; 16 private static EntityManager persistance; ... 25 private Photo photo; ... 80 public static void main(String[] args) throws Exception { 81 Context ctx = new InitialContext(); 82 fichiers = (FichiersPhotoRemote) ctx.lookup(photos.FichiersPhotoRemote.class.getName()); 83 fabrique = Persistence.createEntityManagerFactory("Photos-ejbPU"); 84 persistance = fabrique.createEntityManager(); 85 persistance.getTransaction().begin(); 86 new Visionneuse(); 87 } ...
Le gestionnaire d'entités est une composante essentielle de JPA. JPA gère l'état et le cycle de vie des entités et les interroge dans un contexte de persistance. C'est également lui qui est responsable de la création et de la suppression des instances d'entités persistantes et qui les retrouve à partir de leur clé primaire.
Il peut les verrouiller pour les protéger des accès concurrents en utilisant un verrouillage optimiste ou pessimiste et se servir de requêtes JPQL pour rechercher celles qui répondent à certains critères.
L'interface javax.persistence.EntityManager est le point central de la gestion des entrées persistantes. Elle offre des méthodes d'ajout, de modification, de suppression et de recherche. Nous allons détailler les différentes méthodes de cette interface et expliquer leur comportement.
Lorsqu'un gestionnaire d'entités obtient une référence à une entité, celle-ci est dite gérée ou attachée. Avant cela, elle n'était considérée que comme une simple instance de classe (elle était détachée).
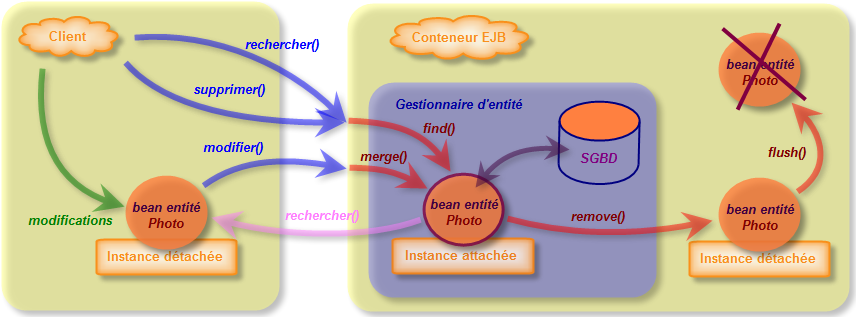
L'avantage de JPA est que les entités peuvent être utilisées comme des objets normaux par les différentes couches de l'application et devenir gérées par le gestionnaire d'entités lorsque nous désirons charger ou insérer des données dans la base.
En résumé : Le véritable travail de persistance commence donc avec le gestionnaire d'entités. L'interface javax.persistence.EntityManger est implémentée par un fournisseur de persistance qui produira et exécutera les instructions SQL.
Avant d'explorer en détail l'API de EntityManager, vous devez avoir compris un concept essentiel : le contexte de persistance, qui est l'ensemble des instances d'entités gérées à un instant donné.
Dans un contexte de persistance, il ne peut exister qu'une seule instance d'entité avec le même identifiant de persistance - si, par exemple, une instance de Livre ayant l'identifiant 4256 existe dans le contexte de persistance, aucun autre livre portant cet identifiant ne peut exister dans le même contexte.
Seules les entités contenues dans le contexte de persistance sont gérées par le gestionnaire d'entités - leurs modifications seront reflétées dans la base de données.
Nous le verrons ultérieurement, le gestionnaire d'entités sert à créer des requêtes JPQL complexes pour récupérer une ou plusieurs entités. Lorsqu'elle manipule des entités uniques, l'interface EntityManager permet également et tout simplement d'effectuer les opérations CRUD sur n'importe quelle entité :
| Méthode | Description |
| void persist(Object entité) | Crée une instance gérée et persistante. |
| <T> T find(Class<T> entité, Object cléprimaire) | Recherche une entité de la classe spécifiée à l'aide de son identifiant. |
| <T> T getReference(Class<T> entité, Object cléprimaire) | Obtient une instance dont l'état peut être récupéré de façon paresseuse. |
| void remove(Object entité) | Supprime l'instance d'entité du contexte de persistance et de la base de données. |
| <T> T merge(T entité) | Fusionne l'état de l'entité indiquée dans le contexte de persistance courant. |
| void refresh(Object entité) | Rafraîchit l'état de l'instance à partir de la base de données en écrasant les éventuelles modifications apportées à l'entité. |
| void flush() | Synchronise le contexte de persistance avec la base de données. |
| void clear() | Vide le contexte de persistance. Toutes les entités gérées deviennent détachées. |
| void clear(Object entité) | Supprime l'entité indiquée du contexte de persistance. |
| boolean contains(Object entité) | Teste si l'instance est une entité gérée appartenant au contexte de persistance courant. |
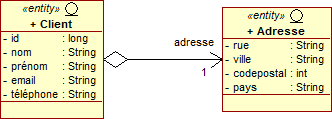
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @OneToOne(fetch=FetchType.LAZY) private Adresse adresse; ... }
@Entity public class Adresse implements java.io.Serializable { @Id @GeneratedValue private long id; private String rue; private String ville; private int codepostal; private String pays; ... }
Ces deux entités seront traduites dans la base de données avec la structure présentée ci-dessous. Notez que la colonne ADRESSE_ID est la colonne de type clé étrangère permettant d'accéder à ADRESSE :

Rendre une entité persistante signifie que nous l'insérons dans la base de données. Celle-ci ne s'applique que sur des entités encore non enregistrées dans la base de données (sinon une exception sera lancée).

@Stateless public class Archiver implements ArchiverRemote { @PersistenceContext EntityManager stockage; @Override private void enregistrer() { Client client = new Client("Emmanuel", "REMY", "emmanuel.remy@wanadoo.fr"); Adresse adresse = new Adresse("Rue", "AURILLAC", 15000, "FRANCE"); client.setAdresse(adresse); stockage.persist(client); stockage.persist(adresse); } ... }
Le client et l'adresse ne sont que deux objets qui résident dans la mémoire de la JVM. Tous les deux ne deviennent des entités gérées que lorsque le gestionnaire d'entités stockage les prend en compte en les rendant persistantes (une fois que la méthode find() est appelée, les objets client et adresse deviennent managés et leurs insertions dans la base de données est mise dans la file d'attente du gestionnaire d'entité EntityManager).
Lorsque la tansaction est effective, les données sont écrites dans la base : une ligne d'adresse est ajoutée à la table ADRESSE et une ligne client, à la table CLIENT. L'entité Client étant la propriétaire de la relation, sa table contient une clé étrangère vers ADRESSE.
Pour rappel, si vous injectez un contexte persistant étendu (via @PersistenceContext) alors il est automatiquement associé à la transaction. Dans les autres cas (manuellement via EntityManagerFactory) vous devez appeler la méthode joinTransaction() de EntityManager pour associer le contexte à la transaction courante.
Une fois les objets sauvegardés, il est important de pouvoir les récupérer. Il existe deux façons de récupérer ces objets de la base de données. Nous allons détailler la récupération des objets à partir de leur clé primaire. L'autre solution consiste à travailler avec les requêtes JPQL qui seront traitées dans l'un des chapitres qui suit.
Le gestionnaire d'entité possède deux méthodes simples pour trouver une entité à partir de sa clé primaire :
Cette méthode est prévue pour les situations où nous avons besoin d'une instance d'entité gérée, mais d'aucune autre donnée que la clé primaire de l'entité recherchée.
Lors d'un appel à getReference(), les données de l'état sont récupérées de façon paresseuse, ce qui signifie que, si nous n'accédons pas à l'état avant que l'entité soit détachée, les données peuvent être manquantes. Par ailleurs, cette méthode lève une exception EntityNotFoundException si elle ne retrouve pas l'entité.
La méthode remove() de EntityManager supprime une entité qui est également ôtée de la base de données. Cette entité se trouve alors détachée du gestionnaire d'entités et ne peut plus être synchroniser avec la base de données.
En réalité, il s'agit d'une demande car la suppression n'est pas effective immédiatement mais seulement à l'appel de la méthode flush() ou à la fermeture du contexte de persistance. Entre temps, il est possible d'annuler la suppression.
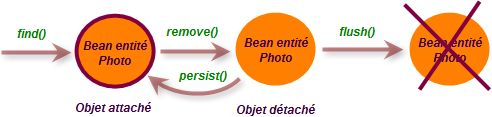
L'appel à la méthode remove() détache l'entité du contexte de persistance. Pour annuler cette suppression (dans le même contexte de persistance) il faut appeler la méthode persist() afin de rattacher l'objet entité au contexte.
@Stateless public class Archiver implements ArchiverRemote { @PersistenceContext EntityManager stockage; @Override private void enregistrer() { Client client = new Client("Emmanuel", "REMY", "emmanuel.remy@wanadoo.fr"); Adresse adresse = new Adresse("Rue", "AURILLAC", 15000, "FRANCE"); client.setAdresse(adresse); stockage.persist(client); stockage.persist(adresse); ... stockage.remove(client); } ... }
Puis dans le code de cette méthode, nous ne supprimons que l'entité Client : selon la configuration de la suppression en cascade, l'instance peut éventuellement être laissée intacte alors qu'aucune autre entité ne la référence plus - dans ce cas, la ligne d'adresse est alors orpheline.
Pour des raisons de cohérence des données, il faut éviter de produire des orphelins car ils correspondent à des lignes de la base de données qui ne sont plus référencées par aucune autre table et qui ne sont donc plus accessibles
Avec JPA, vous pouvez demander au fournisseur de persistance de supprimer automatiquement les orphelins ou de répercuter en cascade une opération de suppression. Si une entité cible (Adresse) appartient uniquement à une source (Client) et que cette source soit supprimée par l'application, le fournisseur doit également supprimer la cible.
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @OneToOne(fetch=FetchType.LAZY, orphanRemoval=true) private Adresse adresse; ... }
@Entity public class Adresse implements java.io.Serializable { @Id @GeneratedValue private long id; private String rue; private String ville; private int codepostal; private String pays; ... }
Désormais, le gestionnaire d'entités supprimera automatiquement l'entité Adresse lorsque le client correspondant sera supprimé. L'opération de suppression effective n'intervient qu'au moment de l'écriture dans la base de données (lorsque la transaction est validée).
Jusqu'à maintenant, la synchronisation avec la base de données s'est effectuée uniquement lorsque la transaction est validée.
@Stateless public class Archiver implements ArchiverRemote { @PersistenceContext EntityManager stockage; @Override private void enregistrer() { Client client = new Client("Emmanuel", "REMY", "emmanuel.remy@wanadoo.fr"); Adresse adresse = new Adresse("Rue", "AURILLAC", 15000, "FRANCE"); client.setAdresse(adresse); stockage.persist(client); stockage.persist(adresse); ... } ... }
Toutes les modifications en attente exigent une instruction SQL et les deux INSERT ne seront produits et rendus permanents que lorsque la transaction sera validée. Pour la plupart des applications, cette synchronisation automatique suffit : nous ne savons pas exactement quand le fournisseur écrira vraiment les données dans la base, mais nous pouvons être sûrs que l'écriture aura lieu lorsque la transaction sera validé.
Bien que la base de données soit synchronisée avec les entités dans le contexte de persistance, nous pouvons explicitement écrire des données dans la base à l'aide de la méthode flush(), ou, inversement, rafraîchir des données à partir de la base avec refresh().
Lorsque vous appelez les méthodes persist(), merge() ou remove(), les changements ne sont pas synchronisés immédiatement. Cette synchronisation s'établit automatiquement à la fin de la transaction ou lorsque le gestionnaire d'entité décide de vider (to flush en anglais) sa file d'attente. Toutefois, le développeur peut forcer la synchronisation en appelant explicitement la méthode flush() du gestionnaire d'entité.
La méthode flush() de EntityManager force le fournisseur de persistance à écrire les données dans la base ; elle permet donc de déclencher manuellement le même processus que celui utilisé en interne par le gestionnaire d'entités lorsqu'il écrit le contexte de parsistance dans la base de données.
@Stateless public class Archiver implements ArchiverRemote { @PersistenceContext EntityManager stockage; @Override private void enregistrer() { Client client = new Client("Emmanuel", "REMY", "emmanuel.remy@wanadoo.fr"); Adresse adresse = new Adresse("Rue", "AURILLAC", 15000, "FRANCE"); client.setAdresse(adresse); stockage.persist(client); stockage.flush(); stockage.persist(adresse); ... } ... }
Il se passe deux choses intéressantes dans le code précédent :
Si vous savez que l'objet entité ne reflète pas les valeurs de la base de données (parce que celle-ci a été modifiée entre-temps ...), vous pouvez utiliser la méthode refresh() de EntityManager afin de recharger l'entité depuis la base de données. Cette opération écrase, bien entendu, toutes les modifications qui ont pu être apportées à l'entité.
La méthode refresh() effectue une synchronisation dans la direction opposée de flush(), c'est-à-dire qu'elle écrase l'état courant d'une entité gérée avec les données qui se trouvent dans la base.
Son utilisation typique consiste à annuler des modifications qui ont été suggérées sur l'entité en mémoire.
.
Le contexte de persistance contient les entités gérées. Grâce à l'interface EntityManager, vous pouvez tester si une entité est gérée et supprimer toutes les entités du contexte de persistance :
Attention : toutes les modifications affectées sont perdues à l'appel de la méthode clear(). Pour éviter cela, il faut appeler la méthode flush() avant l'appel de clear().
Une entité détachée n'est plus associée à un contexte de persistance. Si vous désirez la gérer de nouveau, vous devez la fusionner. Prenons l'exemple d'une entité devant s'afficher dans une page JSF.
@Stateless public class Archiver implements ArchiverRemote { @PersistenceContext EntityManager stockage; @Override private void enregistrer() { Client client = new Client("Emmanuel", "REMY", "emmanuel.remy@wanadoo.fr"); Adresse adresse = new Adresse("Rue", "AURILLAC", 15000, "FRANCE"); client.setAdresse(adresse); stockage.persist(client); stockage.clear(); client.setNom("Nouveau nom"); ... stockage.merge(client); ... } ... }
Dans le code ci-dessus :
Il existe deux façons de modifier une entité. Soit vous la chargez depuis la base de données et vous lui appliquez les modifications au sein de la transaction, soit vous souhaitez mettre à jour un objet détaché et dans ce cas-là, vous devez utiliser la méthode merge().
Bien que la modification d'une entité soit simple, elle peut être en même temps être difficile à comprendre. Comme nous venons de le voir, vous pouvez utiliser merge() pour attacher une entité et synchroniser son état avec la base de données. Lorsqu'une entité est gérée, les modifications qui lui sont apportées seront automatiquement reflétées mais, si elle ne l'est pas, vous devez appeler explicitement merge(). Voici ci-dessous un certain nombre de situations qui se présentent fréquemment :
Par défaut, chaque opération du gestionnaire d'entités ne s'applique qu'à l'entité passée en paramètre à l'opération. Parfois, cependant, nous désirons propager son action à ses relations - c'est ce que nous appelons répercuter un événement, ou encore opérations en cascade.
@Stateless public class Archiver implements ArchiverRemote { @PersistenceContext EntityManager stockage; @Override private void enregistrer() { Client client = new Client("Emmanuel", "REMY", "emmanuel.remy@wanadoo.fr"); Adresse adresse = new Adresse("Rue", "AURILLAC", 15000, "FRANCE"); client.setAdresse(adresse); stockage.persist(client); stockage.persist(adresse); ... } ... }
Comme il existe une relation entre Client et Adresse, nous pouvons répercuter l'action persist() du client vers son adresse. Ceci signifie qu'un appel à persist(client) répercutera l'événement PERSIST à l'entité Adresse si elle autorise la propagation de ce type d'événement. Le code peut donc être allégé en supprimant la persistance explicite au niveau de l'adresse :
@Stateless public class Archiver implements ArchiverRemote { @PersistenceContext EntityManager stockage; @Override private void enregistrer() { Client client = new Client("Emmanuel", "REMY", "emmanuel.remy@wanadoo.fr"); Adresse adresse = new Adresse("Rue", "AURILLAC", 15000, "FRANCE"); client.setAdresse(adresse); stockage.persist(client); ... } ... }
Sans cette répercussion, le client serait persistant, mais pas son adresse. Pour que cette répercution ait lieu, l'assosiation de la relation doit être modifiée. Les annotations @OneToOne, @OneToMany, @ManyToOne et @ManyToMany possédent toutes l'attribut cascade pouvant recevoir un tableau d'événements à propager. Celui-ci spécifie les opérations à effectuer en cascade. La cascade signifie qu'une opération appliquée à une entité se répercute (se propage) sur les autres entités qui sont en relation avec elle. Par exemple, lorsqu'un utilisateur est supprimé, son compte peut être automatiquement supprimé également.
La liste ci-dessous énumère les événements que vous pouvez propager vers une cible de la relation. Vous pouvez même toutes les propager en une seule fois. Ces opérations sont regroupées dans l'énumération CascadeType :
Nous devons donc modifier l'association de l'entité Client en ajoutant un attribut cascade à l'annotation @OneToOne. Ici, nous nous contentons pas de propager PERSIST, nous faisons de même pour l'événement REMOVE, afin que la suppression d'un client entraîne celle de son adresse :
@Entity public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @OneToOne(fetch=FetchType.LAZY, cascade={CascadeType.PERSIST, CascadeType.REMOVE}) private Adresse adresse; ... }
L'utilisation du mécanisme de cascade est une réelle simplification pour le développeur. En effet, il n'a plus à gérer les boucles de suppression, de modification... Toutefois, cet outil doit être utilisé judicieusement et avec parcimonie. En effet, une utilisation trop importante de ce mécanisme peut très vite nuire aux performances de l'application.
Nous venons de voir comment manipuler séparément les entités avec l'API d'EntityManager. Vous savez maintenant comment récupérer une entité à partir de son identifiant, la supprimer, modifier ses attributs, etc. Mais rechercher une entité par son identifiant est assez limité (ne serait-ce que parce qu'il vous faut connaître cet identifiant... ).
En pratique, vous aurez plutôt besoin de récupérer une entité en fonction de critères autres que son identifiant (par son nom et son prénom, par exemple) ou de récupérer un ensemble d'entités satisfaisant certianes conditions (tous les clients qui habitent en France, par exemple). Cette possibilté est inhérente aux base de données relationnelles et JPA dispose d'un langage permettant ce type d'interactions : JPQL.
En coulisse, JPQL utilise un mécanisme de traduction pour transformer une requête JPQL en langage compréhensible par une base de données SQL. La requête s'exécute sur la base de données sous-jacente avec SQL et des appels JDBC, puis les instances d'entités sont initialisées et sont renvoyées à l'application - tout ceci de façon simple et à l'aide d'une syntaxe riche.
SELECT livre FROM Livre livre
Pour restreindre le résultat, nous utilisons la clause WHERE affin d'introduire un critère de recherche supplémentaire :
SELECT livre FROM Livre livre WHERE livre.titre = "Astérix le Gaulois"
Vous remarquez que l'alias est très utile et sert à naviguer dans les attributs de l'entité via l'opérateur de séparation, le point ".". L'entité Livre possédant un attribut titre de type String, livre.titre désigne donc l'attribut titre de l'entité Livre. L'exécution de cette instruction produira une liste de zéros ou plusieurs instances de Livre ayant pour titre Astérix le Gaulois.
Une requête JPQL est similaire à du SQL, avec les clauses suivantes :
La requête la plus simple est formée de deux parties obligatoires : les clauses SELECT et FROM. La première définit le format du résultat de la requête tandis que la seconde indique l'entité ou les entités à partir desquelles le résultat sera obtenu. Une requête peut également contenir des clauses WHERE, ORDER BY, GROUP BY et HAVING pour restreindre et trier le résultat.
Il existe également les instructions DELETE et UPDATE, qui permettent respectivement de supprimer et de modifier plusieurs instances d'une classe d'entité.
La clause SELECT porte sur une expression qui peut être une entité, un attribut d'entité, une expression constucteur, une fonction agrégat ou toute séquence de ce qui précède. Ces expression sont les briques de base des requêtes et servent à atteindre les attributs des entités ou de traverser les relations (ou une collection d'entités) via la notation pointée classique.
SELECT <expression de sélection> FROM <clause form> [WHERE <expression conditionnelle> ] [ORDER BY <clause de mise dans l'ordre> ]
[GROUP BY <clause de mise dans l'ordre> ]
[HAVING <clause de mise dans l'ordre> ]
SELECT c FROM Client c
SELECT c.prénom FROM Client c
SELECT c.prénom, c.nom FROM Client c
Lorsque une requête attend plusieurs attributs pour une même entité, le résultat est intégré dans un tableau d'objet (Object[]), et si plusieurs beans sont concernés par cette recherche, c'est toujours la liste qui est utilisée (java.util.List) grâce à la méthode getResultList().
SELECT c.adresse FROM Client c
SELECT c.adresse.pays FROM Client c
SELECT NEW entité.Client(c.prénom, c.nom) FROM Client c
Le résultat de cette requête sera une liste d'objets Client instanciés avec l'opérateur NEW et initialisés avec le prénom et le nom des clients.
SELECT DISTINCT c FROM Client c
SELECT DISTINCT c.prénom FROM Client c
SELECT DISTINCT photo FROM Photo AS photo ORDER BY photo.id DESC
SELECT COUNT(c) FROM Client c
Les clauses SELECT, WHERE et HAVING peuvent également utiliser des expressions scalaires portant sur des nombres (ABS, SQRT, MOD, SIZE, INDEX), des chaînes (CONCAT, SUBSTRING, TRIM, LOWER, UPPER, LENGTH) et des dates (CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP).
La clause FROM d'une requête définit les entités en déclarant des variables d'identification ou alias qui pourront être utilisés par la suite dans les autres clauses (SELECT, WHERE, etc.). Sa syntaxe est simplement formée du nom de l'entité et de son alias. Dans l'exemple qui suit, l'entité est Client et l'alias est client :
SELECT client FROM Client client
La clause WHERE d'une requête est formée d'une expression conditionnelle permettant de restreindre le résultat d'une instruction SELECT, UPDATE ou DELETE. Il peut s'agir d'une expression simple ou d'un ensemble d'expressions conditionnelles permettant de filtrer très précisément la requête.
Les permissions incluses dans la clause WHERE existent pour la plupart dans une forme similaire à celles que nous utilisons avec SQL. Voici une liste résumant celles qui sont le plus couramment utilisées :
SELECT client FROM Client client WHERE client.prénom = 'Vincent'
SELECT photo FROM Photo photo WHERE photo.identification = 'Mésange bleue'
Si votre littéral est de type primitif, vous n'avez pas besoin d'utiliser des simples quotes pour proposer votre valeur. Ainsi dans le cas où vous avez besoin de récupérer une photo particulière, voici ce que je peux écrire :SELECT photo FROM Photo photo WHERE photo.id = 1183645734090
SELECT client FROM Client client WHERE client.prénom = 'Vincent' AND client.adresse.pays = 'France'
SELECT photo FROM Photo photo WHERE (photo.largeur + 250) > 1350
SELECT photo FROM Photo photo WHERE photo.largeur <=900 OR photo.largeur > 1000
SELECT photo FROM Photo photo WHERE photo.largeur BETWEEN 1000 AND 2000
SELECT photo FROM Photo photo WHERE photo.identification LIKE '_pa%'
L'expression LIKE est formée d'une chaîne constituant un motif pouvant contenir des caractères "jockers" : Le premier est "%" et il s'utilise pour représenter un nombre quelconque de caractères (éventuellement nul). Le second "_" représente un seul caractère. Au cas où votre chaîne de caractères utiliserait réellement ces deux caractères, vous avez à votre disposition le caractère d'échappement "\".
SELECT photo FROM Photo photo WHERE photo.identification IN ('Oiseau', 'Papillon')
SELECT photo FROM Photo photo WHERE photo.identification IS NULL
Nous pouvons, très souvent dans ce cas là, utiliser l'opérateur de négation. Ainsi, nous pouvons récupérer toutes les photos qui ont été identifiées :SELECT photo FROM Photo photo WHERE photo.identification IS NOT NULL
SELECT photographe FROM Utilisateur photographe WHERE :photo MEMBER OF photographe.photos
SELECT photographe FROM Utilisateur photographe WHERE photographe.photos IS EMPTY
Les paramètres début et longueur sont des entiers (int). Vous pouvez utiliser ces fonctions avec la clause WHERE pour affiner votre recherche.
.
la recherche suivant retourne un ensemble de photos dont le genre possède plus de six caractères et dont l'identification comporte le mot mésange :
SELECT photo FROM Photo photo WHERE LENGTH(photo.genre) > 6 AND LOCATE(UPPER(photo.identification), 'MESANGE') > -1
SELECT photo FROM Photo photo WHERE photo.instantStockage = CURRENT_DATE
Par exemple, nous pouvons utiliser la fonction COUNT() pour déterminer le nombre de photos présentes dans le serveur :
SELECT COUNT(photo) FROM Photo photo
ou alors le nombre de photos correspondantes aux mésanges :
SELECT COUNT(photo) FROM Photo photo WHERE UPPER(photo.identification) LIKE 'MESANGE%'
Il est possible d'utiliser la clause GROUP BY pour appliquer la fonction d'agrégation sur un lot d'enregsitrements.
.
Voici un exemple permettant de retourner le nombre de photo par photographe :
SELECT photographe.nom , COUNT(photographe.photos) AS nombre FROM Utilisateur photographe GROUP BY photographe
L'intérêt du GROUP BY dans cette requête est de pouvoir appliquer cette fonction COUNT() sur chaque photographe.
.
La clause HAVING permet de spécifier des critères, comme avec la clause WHERE, sur une colonne générée par une des fonctions d'agrégation.
Voici un exemple qui retourne le nom des photographes qui possèdent plus de deux photos stockées dans le serveur :
SELECT photographe.nom , COUNT(photographe.photos) AS nombre FROM Utilisateur photographe GROUP BY photographe.nom HAVING nombre > 2
La clause DISTINCT peut également être avantageuse utilisé, avec des fonctions d'agrégation, afin d'éliminer toutes les duplications.
.
SELECT DISTINCT COUNT(photographe.photos) AS nombre FROM Utilisateur photographe GROUP BY photographe
La majeure partie des relations utilise des collections. Le parcours de leurs entrées est particulièrement intéressante car il n'existe pas dans la logique relationnelle du SQL. Nous avons pour cela l'opérateur IN. Il doit être placé dans la clause FROM, et permet de déclarer un alias pour les entrées de la collection.
SELECT photo FROM Utilisateur photographe , IN (photographe.photos) photo
Nous regroupons ainsi tous les éléments contenus dans la collection photographe.photos, dans l'objet photo. De ce fait, la requête regroupe toutes les photos de tous les photographes.
Les identifiants dans la clause FROM sont déclarés de gauche à droite. Lorsqu'un identifiant est déclaré, nous pouvons l'utiliser dans les déclarations suivantes.
La requête suivante permet de récupérer l'ensemble des retouches effectuées sur l'ensemble des photos (il faut imaginer, dans ce cas là, quil existe une collections de retouches pour une photo) :
SELECT retouche FROM Utilisateur photographe , IN(photographe.photos) photo , IN(photo.retouches) retouche
Une seconde fonction, ELEMENTS, remplit le même rôle, mais se situe dans la clause SELECT. Voici une requête avec un résultat similaire au premier exemple.
SELECT ELEMENTS(photographe.photos) FROM Utilisateur photographe
Les jointures permettent de manipuler les relations entre les entités. Nous verrons que les fonctionnalités disponibles sont multiples et pourront s'adapter à de nombreux besoins.
@Entity public class Retouche implements Serializable { private long id; private int luminosite; private int contraste; private Photo photo; @Id @GeneratedValue public long getId() { return id; } public void setId(long id) { this.id = id; } @OneToOne(mappedBy="retouche")
public Photo getPhoto() { return photo; }
public void setPhoto(Photo photo) { this.photo = photo; } public int getLuminosite() { return luminosite; } public void setLuminosite(int luminosite) { this.luminosite = luminosite; } public int getContraste() { return contraste; } public void setContraste(int contraste) { this.contraste = contraste; } }
8 @Entity 9 public class Photo implements Serializable { 10 private long id; 11 private Date instantStockage; 12 private String genre; 13 private String identification; 14 private int largeur; 15 private int hauteur; 16 private long poids; 17 private Retouche retouche; 18 19 @OneToOne 20 @JoinColumn(name="RETOUCHE_ID", referencedColumnName="ID") 21 public Retouche getRetouche() { return retouche; } 22 public void setRetouche(Retouche retouche) { this.retouche = retouche; } ... 61 }
Et voici les différentes approches que nous pouvons en faire :
SELECT photo.identification, retouche.contraste FROM Photo photo, Retouche retouche WHERE photo.retouche.id = retouche.id
SELECT photo.identification , photo.retouche.contraste FROM Photo photo
SELECT photo.identification , retouche.contraste FROM Photo photo JOIN photo.retouche AS retouche
Les résultats retournés sont les mêmes pour chacune des requêtes à quelques exceptions près. En effet, le fonctionnement des jointures est subtil. Lorsqu'une entité Photo ne possède pas de relation avec l'entité Retouche, l'enregistrement ne sera pas retourné !
Afin de renvoyer les enregistrements de l'entité Retouche, même s'ils n'ont pas de relation, il faut effectuer une jointure dite "ouverte". Pour cela, nous utilisons les instructions LEFT OUTER JOIN ou RIGHT OUTER JOIN, également existantes en SQL.
En JPQL, l'expression LEFT JOIN permet d'inclure systématiquement la première entité dans le résultat de la requête. RIGHT JOIN, quand à elle, ajoute les résultats de la seconde entité.
Remarque : L'instruction OUTER, utilisée en SQL, est devenue optionnelle.
.
L'exemple suivant utilise une jointure ouverte. Les résultats sont alors différents :
SELECT photo.identification , retouche.contraste FROM Photo photo LEFT JOIN photo.retouche AS retouche
En effet, la requête a désormais pris en compte toutes les photos prévues même si aucune retouche n'y est associée.
Nous avons vu précédemment l'utilisation de l'opérateur IN. La jointure de type INNER provoque le même résultat. Elle est cependant plus familière aux développeurs utilisant couramment SQL. Il suffit d'utiliser le mot clé INNER JOIN pour réaliser ce type de jointure.
SELECT photo FROM Utilisateur photographe INNER JOIN photographe.photos photo
La requête précédente retourne l'ensemble des photos créées quel que soit l'utilisateur. Il est toutefois plus simple d'utiliser l'opérateur IN. Voici la correspondance utilisant IN :
SELECT photo FROM Utilisateur photographe , IN(photographe.photos) photo
JPQL supporte nativement le polymorphisme, c'est-à-dire les requêtes portant sur une hiérarchie d'objets.
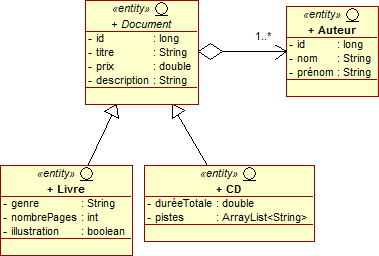
L'exécution de la requête suivante retourne tous les enregistrement liés à l'entité Document.
SELECT document FROM Document document
La collection de résultat contient des objets, aussi bien de type Livre, que de type CD.
.
Jusqu'à maintenant, les clauses WHERE dont nous nous sommes servis n'utilisaient que des valeurs fixes. Dans une application, cependant, les requêtes dépendent souvent de paramètres et JPQL fournit deux moyens pour lier ces paramètres :
SELECT client FROM Client client WHERE client.prénom = ?1 AND client.adresse.pays = ?2
SELECT client FROM Client client WHERE client.prénom = :prenom AND client.adresse.pays = :pays
Nous verrons dans la section "Requêtes", plus loin dans ce chapitre, comment lier ces paramètres à une application.
.
Une sous-requête est une requête SELECT intégrée dans l'expression conditionnelle d'une clause WHERE ou HAVING. Le résultat de cette sous-requête est évalué et interprété dans l'expression conditionnelle de la requête principale. Comme leur équivalent SQL, les sous-requêtes permettent d'imbriquer les requêtes.
SELECT client FROM Client client WHERE client.âge = (SELECT MIN (client.âge) FROM Client client)
Les sous-requêtes peuvent être placées dans les clauses WHERE et HAVING.
SELECT photographe FROM Utilisateur photographe WHERE (SELECT COUNT(photo) FROM Photo photo GROUP BY photographe) > 3
Nous remarquons l'utilisation de l'objet (l'alias) photographe de la requête principale dans la sous-requête. Un des principaux intérêt est de pouvoir se substituer aux jointures, notamment dans les requêtes de type UPDATE et DELETE.
Utilisez les sous-requêtes lorsque vous ne pouvez pas faire autrement. Nous vous conseillons d'étudier, d'abord, l'utilisation de jointures ou d'instructions telles que IN, ELEMENTS... qui sont d'ailleurs obligatoires dans des systèmes ne prenant pas en compte les sous-requêtes.
Lorsqu'une sous-requête est susceptible de retourner plusieurs lignes, il est alors possible de quantifier le résultat devant être retourné. Pour cela, nous utilisons les expressions :
FROM Photo photo WHERE 0 < ALL (SELECT retouche.contraste FROM photo.retouche retouche)
FROM Photo photo WHERE 0 = ANY (SELECT retouche.contraste FROM photo.retouche retouche)
L'opérateur EXISTS retourne true si le résultat d'une sous-requête obtient au moins une valeur. Au contraire, si aucune valeur n'est trouvée par la sous-requête, la valeur false est retournée.
FROM Photo photo WHERE EXIST (SELECT retouche FROM photo.retouche retouche WHERE retouche.contraste = 20)
La clause ORDER BY permet de ranger par ordre les résultats d'une requête, à partir d'un ou plusieurs attributs en utilisant l'ordre alphanumérique puis alphabétique.
Le mot clé optionnel ASC signifie que le classement se fait de façon ascendante. Pour l'effectuer dans l'ordre descendante, il faut utiliser DESC (du plus grand au plus petit). Par défaut, c'est ASC qui est appliqué.
SELECT client FROM Client client WHERE client.âge > 18 ORDER BY client.âge DESC
La requête suivante retourne l'ensemble des photos suivant l'ordre de stockage :
SELECT photo FROM Photo photo ORDER BY photo.id ASC
ou
SELECT photo FROM Photo photo ORDER BY photo.id
L'exemple suivant retourne les photos, avec en premier, les toutes dernières sauvegardées :
SELECT photo FROM Photo photo ORDER BY photo.id DESC
Il est bien entendu possible de combiner ces critères. Ainsi, la requête suivante récupère les photos de la plus petite largeur vers la plus grande et pour une largeur données, le tri se fait ensuite sur la hauteur décroissante :
SELECT photo FROM Photo photo ORDER BY photo.largeur, photo.hauteur DESC
SELECT client.adresse.pays, COUNT(client) FROM Client client GROUP BY client.adresse.pays
La requête suivante retourne l'ensemble des photos suivant l'ordre de stockage :
SELECT photo FROM Photo photo ORDER BY photo.id ASC
ou
SELECT photo FROM Photo photo ORDER BY photo.id
L'exemple suivant retourne les photos, avec en premier, les toutes dernières sauvegardées :
SELECT photo FROM Photo photo ORDER BY photo.id DESC
Il est bien entendu possible de combiner ces critères. Ainsi, la requête suivante récupère les photos de la plus petite largeur vers la plus grande et pour une largeur données, le tri se fait ensuite sur la hauteur décroissante :
SELECT photo FROM Photo photo ORDER BY photo.largeur, photo.hauteur DESC
GROUP BY et HAVING ne peuvent apparaître que dans une clause SELECT.
.
Nous savons supprimer une entité à l'aide de la méthode remove() de EntityManager et interroger une base de données afin d'obtenir une liste d'entités correspondant à certains critères.
Pour supprimer un ensemble d'entité, nous pourrions donc exécuter une requête et parcourir son résultat pour supprimer séparément chaque entité. Bien que ce soit un algorithme tout à fait valide, ses performances seraient désastreuses car il implique trop d'accès à la base de données. Il existe une meilleure solution : les suppressions multiples.
JPQL sait effectuer des suppressions multiples sur les différentes instances d'une classe d'entités précise, ce qui permet de supprimer un grand nombre d'entités en une seule opération. L'instruction DELETE ressemble à l'instruction SELECT car elle peut utiliser une clause WHERE et prendre des paramètres. Elle renvoie le nombre d'entités concernées par l'opération.
DELETE FROM <nom de l'entité> [[AS] <variable d'identification> ] [WHERE <expression conditionnelle> ]L'exemple suivant, par exemple, supprime tous les clients âgés de moins de 18 ans :
DELETE FROM Client client WHERE client.âge < 18
La grande particularité de ce type de cette instruction est de n'avoir qu'une seule entité dans la clause FROM. Ainsi, si vous souhaitez supprimer (ou modifier, voir plus loin) des enregistrements de plusieurs beans entités, vous devez effectuer plusieurs requêtes.
DELETE FROM Photo AS photo WHERE photo.identification = 'Mésange bleue'
UPDATE Photo AS photo WHERE photo.id = 1183645734090
La clause DELETE de JPQL ne supporte pas la suppression en cascade. En effet, même si la relation est configurée avec CascadeType.REMOVE ou CascadeType.ALL, il faudra tout de même écrire manuellement leur retrait de la base de données.
Dans cette requête DELETE, nous risquons de recevoir des exceptions dans le cas où le bean entité Client possèderait des relations. Nous avons alors trois possibilités :
Dans ce dernier cas, il est possible d'utiliser l'expression ON DELETE CASCADE pour, par exemple, les bases de données de type MySQL version 5 et du moteur de stockage InnoBD.
L'instruction UPDATE permet de modifier toutes les entités répondant aux critères de sa clause WHERE.
UPDATE <nom de l'entité> [[AS] <variable d'identification> ] SET <mise à jour> {, <mise à jour>}* [WHERE <expression conditionnelle> ]L'instruction suivante, par exemple, modifie le prénom de tous nos jeunes clients en "trop jeune" :
UPDATE Client client SET client.prénom = 'trop jeune' WHERE client.âge < 18
JPQL est très utile pour tout ce qui est recherche. Par contre, les requêtes DELETE et UPDATE me semble pas très utiles surtout UPDATE d'ailleurs. Le gestionnaire de persistance se comporte très bien avec les mises à jours des beans entités sans passer par JPQL. Toutefois, j'utilise quelquefois la requête DELETE, mais jamais UPDATE.
Nous connaissons maintenant la syntaxe de JPQL et nous savons comment écrire ses instructions à l'aide de différentes clauses (SELECT, FROM, WHERE, etc.). Le problème consiste maintenant à les intégrer dans une application. Pour ce faire, JPA 2.0 permet d'intégrer quatre sortes de requêtes dans le code, chacune correspondant à un besoin différent :
Le choix entre ces quatre types est centralisé au niveau de l'interface EntityManager, qui dispose de plusieurs méthodes de fabrique renvoyant toutes une interface Query.
| Méthode | Description |
| Query createQuery(String jpql) | Crée une instance de Query permettant d'exécuter une instruction JPQL pour des requêtes dynamiques. |
| Query createQuery(QueryDefinition qdef) | Crée une instance de Query permettant d'exécuter une requête par critère. |
| Query createNamedQuery(String nom) | Crée une instance de Query permettant d'exécuter une requête nommée (en JPQLou en SQL natif). |
| Query createNativeQuery(String sql) | Crée une instance de Query permettant d'exécuter une instruction SQL native. |
| Query createNativeQuery(String sql, Class classe) | Crée une instance de Query permettant d'exécuter une instruction SQL native en lui passant la classe du résultat attendu. |
public interface Query { // Exécute une requête et renvoie un résultat. public List getResultList(); public Object getSingleResult(); public int executeUpdate(); // Initialise les paramètres de la requête public Query setParameter(String name, Object value); public Query setParameter(String name, Date value, TemporalType temporalType); public Query setParameter(String name, Calendar value, TemporalType temporalType); public Query setParameter(int position, Object value); public Query setParameter(int position, Date value, TemporalType temporalType); public Query setParameter(int position, Calendar value, TemporalType temporalType); public Map<String, Object> getNamedParameters(); public List getPositionalParameters(); // Restreint le nombre de résultats renvoyés par une requête public Query setMaxResults(int maxResult); public int getMaxResults(); public Query setFirstResult(int startPosition); public int getFirstResult(); // Fixe et obtient les hints d'une requête public Query setHint(String hintName, Object value); public Map<String, Object> getHints(); public Set<String> getSupportedHints(); // Fixe le mode flush pour l'exécution de la requête public Query setFlushMode(FlushModeType flushMode); public FlushModeType getFlushMode(); // Fixe le mode de verrouillage utilisée par la requête public Query setLockMode(LockModeType lockMode); public LockModeType getLockMode(); // Permet d'accéder à l'API spécifique du fournisseur public <T extends Object> T unwrap(Class<T> cls); }
Les méthodes les plus utilisées de cette API sont celles qui exécutent la requête. Ainsi, pour effectuer une requête SELECT, vous devez choisir entre deux méthodes en fonction du résultat que vous souhaitez obtenir :
Pour exécuter une mise à jour ou une suppression, utiliser la méthode executeUpdate(), qui exécute la requête et renvoie le nombre d'entités concernées par son exécution.
Comme nous l'avons vu plus haut dans le chapitre JPQL, une requête peut prendre des paramètres nommés (:prénom, par exemple) ou positionnel (?1, par exemple). L'API Query définit plusieurs méthodes setParameter() pour initialiser ces paramètres avant l'exécution d'une requête.
Une requête peut renvoyer un grand nombre de résultats. Selon l'application, ceux-ci peuvent être traités tous ensembles ou par morceaux (une application Web, par exemple, peut vouloir n'afficher que dix lignes à la fois). Pout contrôler cette pagination, l'interface Query définit les méthodes setFirstResult() et setMaxResults(), qui permettent d'indiquer le premier résultat que nous souhaitons obtenir (en partant de zéro) et le nombre maximal de résultats par rapport à ce point précis.
Le mode flush indique au fournisseur de persistance comment gérer les modifications et les requêtes en attente. Deux modes sont possibles :
Enfin, les requêtes peuvent être verrouillées par un appel à la méthode setLockMode(LockType).
.
Les sections qui suivent décrivent les trois types de requêtes en utilisant quelque unes des méthodes que nous venons de décrire.
.
Les requêtes dynamiques sont définies à la volée par l'application lorsqu'elle en a besoin. Elles sont créées par un appel à la méthode createQuery() de EntityManager, qui prend en paramètre une chaîne représentant une requête JPQL.
Query requête = persistance.createQuery("SELECT client FROM Client client"); List<Client> clients = requête.getResultList();
Si vous savez que la requête ne renverra qu'une seule entité, utilisez plutôt la méthode getSingleResult() car cela vous évitera de devoir ensuite extraire cette entité d'une liste .
La chaîne contenant la requête peut également être élaborée dynamiquement par l'application - en cours d'exécution - à l'aide de l'opérateur de concaténation et en fonction de certains critères :
String jpql = "SELECT client FROM Client client"; if (critère) jpql += " WHERE client.prénom = 'Emmanuel'" Query requête = persistance.createQuery(motif); List<Client> clients = requête.getResultList();
La requête précédente récupère les clients prénommés Emmanuel, mais vous voudrez peut-être pouvoir choisir ce prénom et le passer en paramètre : vous pouvez le faire en utilisant des noms ou des positions. Dans l'exemple suivant, nous utilisons un paramètre nommé :prenom (notez bien le préfix deux-points) dans la requête et nous le lions à une valeur à l'aide de la méthode setParameters() :
String jpql = "SELECT client FROM Client client"; if (critère) jpql += " WHERE client.prénom = :prenom" Query requête = persistance.createQuery(motif); requête.setParameter("prenom", "Emmanuel"); List<Client> clients = requête.getResultList();
Notez bien que dans la méthode setParameter(), le nom du paramètre ne doit plus contenir le symbole deux-points utilisé dans la requête. Le code équivalent avec un paramètre positionnel serait le suivant :
String jpql = "SELECT client FROM Client client"; if (critère) jpql += " WHERE client.prénom = ?1" Query requête = persistance.createQuery(motif); requête.setParameter(1, "Emmanuel"); List<Client> clients = requête.getResultList();
Si vous désirez paginer la liste des clients par groupe de dix, utilisez la méthode setMaxResult() de la façon suivante :
Query requête = persistance.createQuery("SELECT client FROM Client client"); requête.setMaxResults(10); List<Client> clients = requête.getResultList();
Le problème des requêtes dynamiques est le coût de la traduction de la chaîne JPQL en instruction SQL au moment de l'exécution. La requête étant créée à l'exécution, elle ne peut pas être prévue à la compilation : à chaque appel, le fournisseur de persistance doit donc analyser la chaîne JPQL, obtenir les métadonnées de l'ORM et produire la requête SQL correspondante.
Ce surcoût de traitement des requêtes dynamiques peut donc être un problème : lorsque cela est possible, utilisez plutôt des requêtes statiques (requêtes nommées).
Les requêtes nommées sont différentes des requêtes dynamiques parce qu'elles sont statiques et non modifiables. Bien que cette nature statique n'offre pas la souplesse des requêtes dynamiques, l'exécution des requêtes nommées peut être plus efficace car le fournisseur de persistance peut traduire la chaîne JPQL en SQL au démarrage de l'application au lieu d'être obligé de le faire à chaque fois que la requête est exécutée.
Les requêtes nommées sont exprimées dans les métadonnées via une annotation @NamedQuery. Cette annotation prend deux éléments : le nom de la requête et son contenu. Cette annotation doit être placée au niveau de la classe du bean entité. L'attribut name définit le nom de la requête et query la requête JPQL elle-même.
@Entity @NamedQueries({ @NamedQuery(name="tousLesClients", query="SELECT client FROM Client client"), @NamedQuery(name="emmanuel", query="SELECT client FROM Client client WHERE client.prénom = 'Emmanuel'"), @NamedQuery(name="unPrénom", query="SELECT client FROM Client client WHERE client.prénom = :prenom") }) public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @OneToOne(fetch=FetchType.LAZY, cascade={CascadeType.PERSIST, CascadeType.REMOVE}) private Adresse adresse; ... }
L'entité Client définissant plusieurs requêtes nommées, nous utilisons alors l'annotation @NamedQueries, qui prend en paramètre un tableau de @NamedQuery.
Si l'entité Client n'avait défini qu'une seule requête, nous aurions simplement utilisé une annotation @NamedQuery, comme dans l'exemple qui suit :
@Entity @NamedQuery(name="tousLesClients", query="SELECT client FROM Client client") public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @OneToOne(fetch=FetchType.LAZY, cascade={CascadeType.PERSIST, CascadeType.REMOVE}) private Adresse adresse; ... }
L'exécution de ces requêtes ressemble à celles des requêtes dynamiques. Cette fois-ci toutefois, il faut utiliser la méthode createNamedQuery() de EntityManager. Celle-ci prend en paramètre le nom de la requête nommée que nous souhaitons utiliser, telle qu'il est défini dans les annotations. Le gestionnaire de persistance fait alors automatiquement le lien avec les requêtes déclarées.
Cette méthode createNamedQuery() renvoie un objet Query qui peut servir à initialiser les paramètres, le nombre maximal de résultats, le mode de récupération, etc.
Pour, par exemple, exécuter la requête tousLesClients, nous écrivons le code suivant :
Query requête = persistance.createNamedQuery("tousLesClients"); List<Client> clients = requête.getResultList();
Le fragment de code qui suit appelle la requête unPrénom en lui passant le paramètre prenom et en limitant le nombre de résultat à 3 :
Query requête = persistance.createNamedQuery("unPrénom"); requête.setParameter("prenom", "Emmanuel"); requête.setMaxResults(3); List<Client> clients = requête.getResultList();
La plupart des méthodes de l'API Query renvoyant un objet Query, vous pouvez utiliser un raccourci élégant qui consiste à appeler les méthodes les unes après les autres :
Query requête = persistance.createNamedQuery("unPrénom"); requête.setParameter("prenom", "Emmanuel").setMaxResults(3); List<Client> clients = requête.getResultList();
Les requêtes nommées permettent d'organiser les définitions des requêtes et améliorer les performances de l'application. Cette organisation vient du fait qu'elles sont définies de façon statique sur les entités et généralement placées sur la classe entité qui correspond directement au résultat de la requête (ici, tousLesClients renvoie des clients et doit donc être définie sur l'entité Client).
Cependant, la portée du nom de la requête est celle de l'unité de persistance et ce nom doit être unique dans cette portée, ce qui signifie qu'il ne peut exister qu'une seule requête tousLesClients : ceci implique donc de nommer différemment cette requête si nous devions, par exemple, en écrire une autre pour rechercher toutes les adresses, comme toutesLesAdresses.
Un autre problème est que le nom de la requête, qui est une chaîne, est modifiable et que vous risquez donc d'obtenir une exception indiquant que la requête n'existe pas si vous faites une erreur de frappe ou que vous refactorisiez le code. Pour limiter ce risque, vous pouvez remplacer ce nom par une constante :
@Entity @NamedQuery(name="tousLesClients", query="SELECT client FROM Client client") public class Client implements java.io.Serializable { private static final String TousLesClients = "tousLesClients"; @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @OneToOne(fetch=FetchType.LAZY, cascade={CascadeType.PERSIST, CascadeType.REMOVE}) private Adresse adresse; ... }
La constante TousLesClients identifie la requête tousLesClients sans ambiguïté en préfixant son nom du nom de l'entité. C'est cette même constante qui est ensuite utilisée dans l'annotation @NamedQuery et que vous pouvez utiliser pour exécuter la requête :
Query requête = persistance.createNamedQuery(Client.TousLesClients); List<Client> clients = requête.getResultList();
JPQL dispose d'une syntaxe riche permettant de gérer les entités sous n'importe quelle forme et de façon portable entre les différentes bases de données. Cependant, JPA autorise également l'utilisation des fonctionnalités spécifiques d'un SGDBR via des requêtes natives.
Les requêtes natives prennent en paramètre une instruction SQL (SELECT, UPDATE ou DELETE) et renvoient une instance de Query pour exécuter cette instruction. En revanche, les requêtes natives peuvent ne pas être portables d'une base de données à l'autre.
Si le code n'est pas portable, pourquoi alors ne pas utiliser des appels JDBC ? La raison principale d'utiliser les requêtes JPA natives plutôt que des appels JDBC est que le résultat de la requête sera automatiquement converti en entités.
Query requête = persistance.createNativeQuery("SELECT * FROM CLIENT", Client.class); List<Client> clients = requête.getResultList();
Comme vous pouvez le constater, la requête SQL est une chaîne qui peut être créée dynamiquement en cours d'exécution (exactement comme les requêtes dynamiques JPQL). Là aussi la requête pourrait être complexe et, ne la connaissant pas à l'avance, le fournisseur de persistance sera obligé de l'interpréter à chaque fois, ce qui aura des répercussions sur les performances de l'application.
Toutefois, comme les requêtes nommées, les requêtes natives peuvent utiliser le mécanisme des annotations pour définir des requêtes SQL statiques. Ici, cette annotation s'appelle @NamedNativeQuery et peut être placée sur n'importe quelle entité. Comme avec JPQL, le nom de la requête doit être unique dans l'unité de persistance.
@Entity @NamedNativeQuery(name="tousLesClients", query="SELECT * FROM CLIENT") public class Client implements java.io.Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; @OneToOne(fetch=FetchType.LAZY, cascade={CascadeType.PERSIST, CascadeType.REMOVE}) private Adresse adresse; ... }
Vous pouvez de nouveau appeler la méthode createNamedQuery() pour utiliser cette requête nommée :
Query requête = persistance.createNamedQuery("tousLesClients"); List<Client> clients = requête.getResultList();
Dans les chapitres précédents, nous avons vu comment interroger les entités liées à une base de données. Nous savons maintenant comment rendre une entité persistante, la supprimer, la modifier et la retrouver à partir de son identifiant. Grâce à JPQL, nous pouvons récupérer une ou plusieurs entités en fonction de certains critères de recherche avec des requêtes dynamiques, statiques et natives. Toutes ces opérations sont réalisées par le gestionnaire d'entités - la composante essentielle qui manipule les entités et gère leur cycle de vie.
Nous avons déjà décrit ce cycle de vie en écrivant que les entités sont soit gérées par le gestionnaire d'entités (ce qui signifie qu'elles disposent d'une unité de persistance et qu'elles sont synchronisées avec la base de données), soit détachées de la base de données et utilisées comme de simples objets classiques.
Cependant, le cycle de vie d'une entité est un peu plus riche. Surtout JPA permet d'y greffer du code métier lorsque certains événements concernent l'entité : ce code est ensuite automatiquement appelé par le fournisseur de persistance à l'aide des méthodes de rappel.
Vous pouvez considérer les méthodes de rappel comme les triggers d'une base de données relationnnelle. Un trigger exécute du code métier pour chaque ligne d'une table alors que les méthodes de rappel sont appelées sur chaque instance d'une entité en réponse à un événement ou, plus précisément, avant et après la survenue d'un événement. Pour utiliser ces méthodes "Pre" et "Post", nous pouvons utiliser des annotation spécifiques.
Maintenant que nous connaissons la plupart des mystères des entités, intéressons-nous à leur cycle de vie. Lorsqu'une entité est créée ou rendue persistante par le gestionnaire d'entité, celle-ci est dite gérée. Auparavant, elle n'était considérée par la JVM que comme une simple classe (elle était alors détachée) et pouvait être utilisé par l'application comme un objet normal. Dès qu'une entité devient gérée, le gestionnaire synchronise automatiquement la valeur de ses attributs avec la base de données sous-jacente.
Pour mieux comprendre tout ceci, vous avez ci-dessous un diagramme d'état qui preprésente tous les états que peut prendre une entité Client, ainsi que les transitions entre ces états :
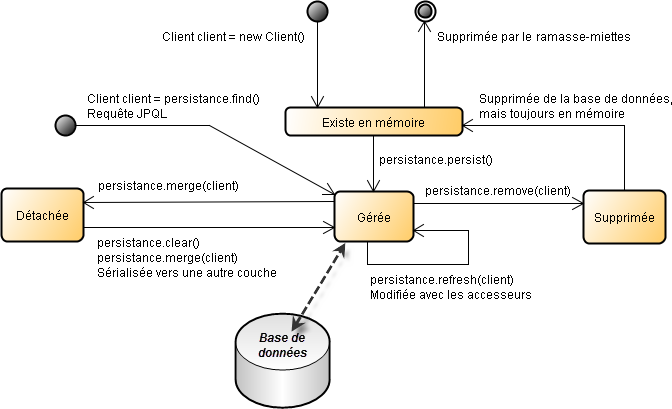
Bien que dans de nombreux exemple de cette étude, les entités n'héritent d'aucune classe, elles doivent implémenter l'interface java.io.Serializable pour passer par un réseau afin d'être invoquée à distance ou pour traverser des couches afin d'être affichées dans une couche de présentation - cette restriction est due non pas à JPA mais à Java. Une entité qui est sérialisée, qui passe par le réseau est désérialisée et donc ensuite est considérée comme un objet détachée : pour la réattacher, il faut appeler la méthode merge().
Les méthodes de rappel permettent d'ajouter une logique métier qui s'exécutera lorsque certains événements du cycle de vie d'une entité surviennent, voire à chaque fois qu'un événement intervient dans le cycle de vie d'une entité.
Le cycle de vie d'une entité se décompose en quatre parties : persistance, modification, suppression et chargement, qui correspondent aux opérations équivalentes sur la base de données.
| Annotation | Description |
| @PrePersist | La méthode sera appelée avant l'exécution de la méthode persist() de EntityManager. |
| @PostPersist | La méthode sera appelée après que l'entité sera devenue persistante. Si l'entité produit sa clé primaire (avec @GeneratedValue), sa valeur est accessible dans la méthode. |
| @PreUpdate | La méthode sera appelée avant une opération de modification de l'entité dans la base de données (appel de setters de l'entité ou de la méthode merge() de EntityManager). |
| @PostUpdate | La méthode sera appelée après une opération de modification de l'entité de la base de données. |
| @PreRemove | La méthode sera appelée avant l'exécution de la méthode remove() de EntityManager. |
| @PostRemove | La méthode sera appelée après la suppression de l'entité. |
| @PostLoad | La méthode sera appelée après le chargement de l'entité (par une requête JPQL ou par un appel de la méthode find() de EntityManager) ou avant qu'elle soit rafraîchie à partir de la base de données. Il n'existe pas de méthode @PreLoad car cela n'aurait aucun sens d'agir sur une entité qui n'a pas encore été construite. |
Voici le diagramme d'états précédent avec les annotations :
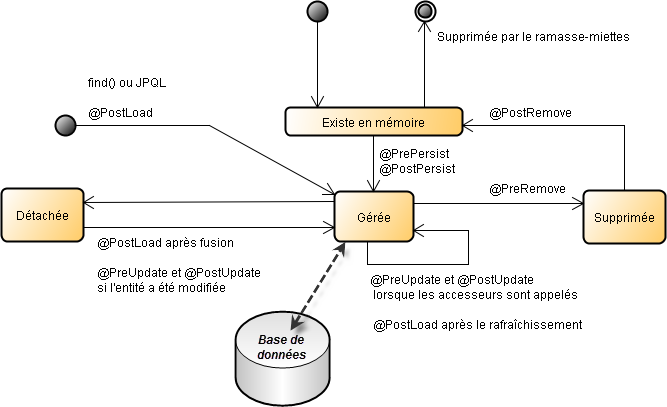
Outre les attributs, les constructeurs et les méthodes accesseurs, les entités peuvent contenir du code métier pour valider leur état ou calculer certains de leurs attributs.
Du code peut être ainsi placé dans des méthodes Java classiques invoquées par d'autres classes ou dans une méthode de rappel (callbacks). Dans ce dernier cas, c'est le gestionnaire d'entités qui les appelera automatiquement en fonction de l'événement qui a été déclenché.
@Entity public class Client implements Serializable { @Id @GeneratedValue private long id; private String nom; private String prénom; private String email; private String téléphone; @OneToOne(cascade=CascadeType.PERSIST) @JoinColumn private Adresse adresse; @Temporal(TemporalType.DATE) private Date anniversaire; @Transient private int âge; @PrePersist @PreUpdate private void validation() { if (anniversaire.getTime() > new Date().getTime()) throw new IllegalArgumentException(); if (!téléphone.startsWith()) throw new IllegalArgumentException(); } @PostLoad @PostPersist @PostUpdate public void calculAge() { if (anniversaire==null) return; Calendar jourAnniversaire = new GregorianCalendar(); jourAnniversaire.setTime(anniversaire); Calendar maintenant = new GregorianCalendar(); maintenant.setTime(new Date()); int ajustement = 0; if (maintenant.get(Calendar.DAY_OF_YEAR) - jourAnniversaire.get(Calendar.DAY_OF_YEAR) < 0) ajustement = -1; âge = maintenant.get(Calendar.YEAR) - jourAnniversaire.get(Calendar.YEAR) + ajustement; } ... }
Dans ce code, l'entité Client définit une méthode de validation des données (elle vérifie les valeurs des attributs anniversaire et téléphone). Cette méthode étant annotée @PrePersist et @PreUpdate, elle sera appelée avant l'insertion ou la modification des donnée dans la base. Si ces données ne sont pas valides, la méthode lèvera une exception à l'exécution et l'insertion ou la modification sera annulée : ceci garantit que la base contiendra toujours des données valides.
La méthode calculAge() calcule l'âge du client. L'attribut âge est transitoire et n'est donc pas écrit dans la base de données : lorsque l'entité est chargée, rendue persistante ou modifiée, cette méthode calcule l'âge à partir de la date de naissance et initialise l'attribut.
Les méthodes de rappel doivent respecter les règles suivantes :
Afin de valider tout ce que nous venons d'apprendre lors de cette étude, mais également lors de l'étude précédente, je vous propose de réaliser un projet d'entreprise qui permet de gérer une petite bibliothèque (stockage de livres uniquement).
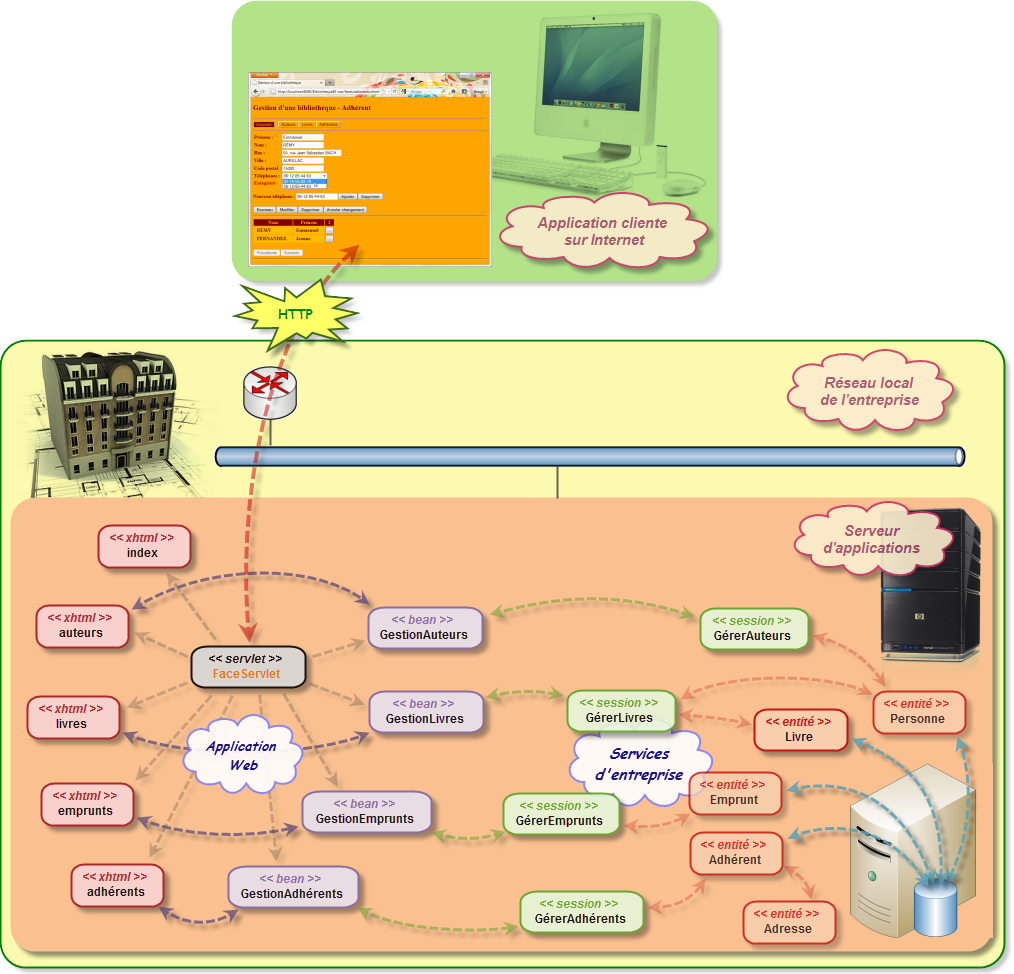
Toutes les opérations de gestion se font au travers d'un simple navigateur, au moyen donc d'une application Web qui est en relation interne avec un module EJB. C'est ce dernier qui s'occupe réellement de la gestion complète de la bibliothèque de prêts, c'est-à-dire archiver l'ensemble des livres, introduire les nouveaux adhérents, suivre les différents emprunts effectués, etc.
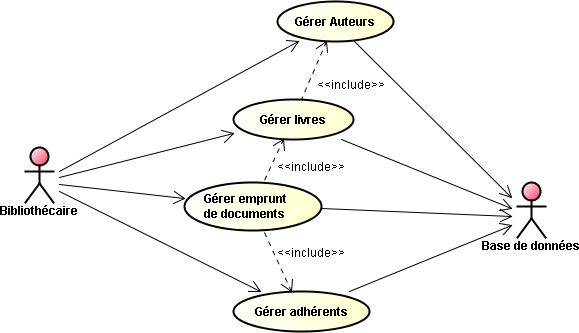
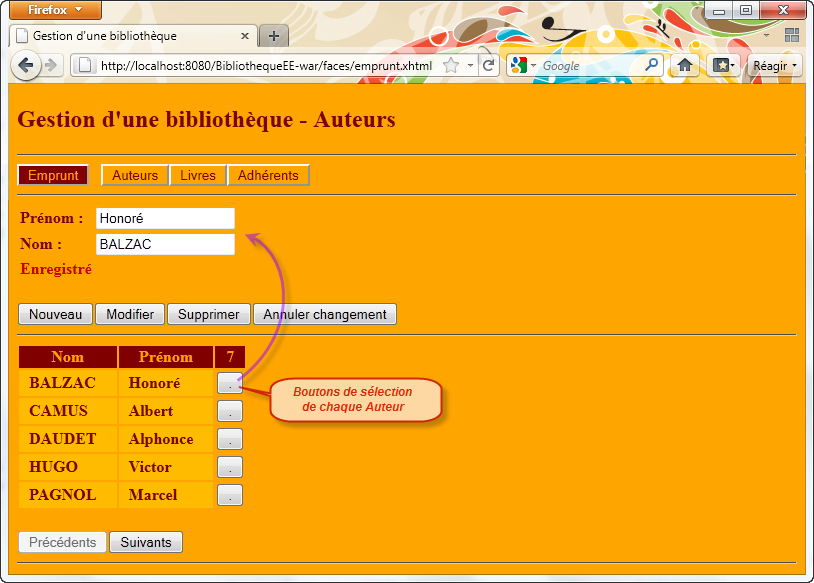
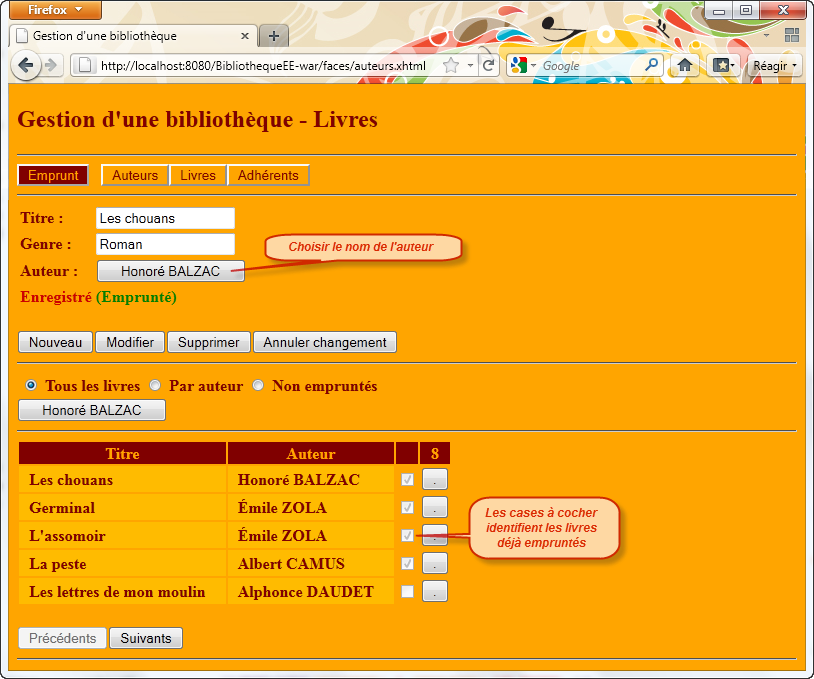
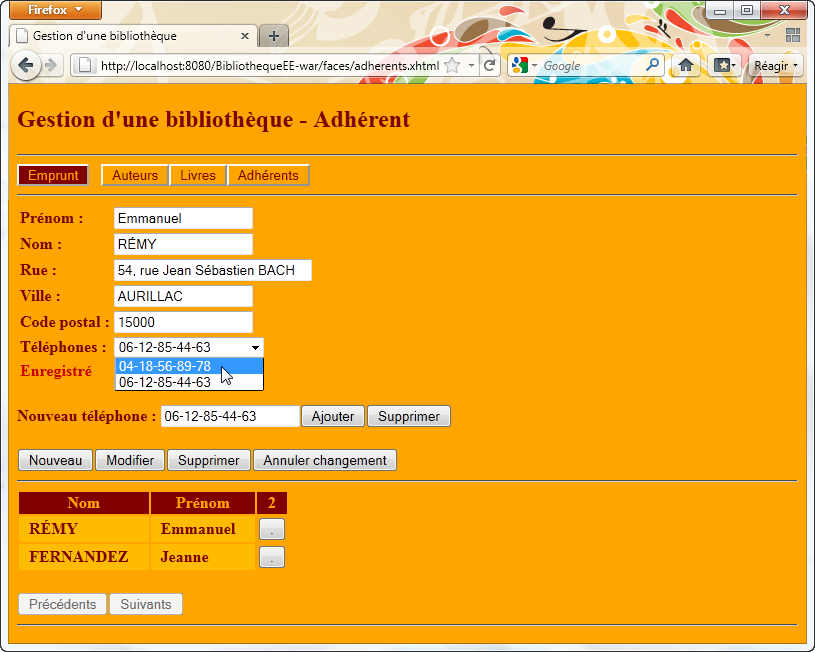
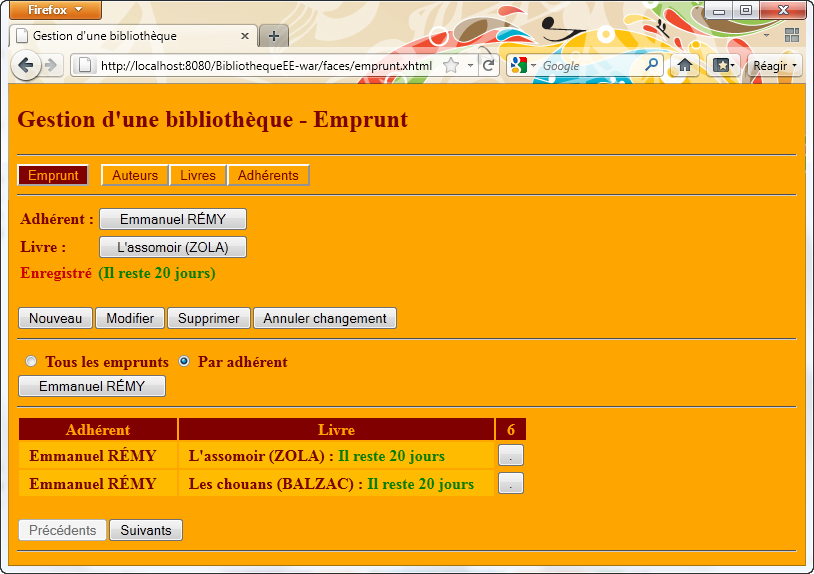
A l'aide du serveur d'application Glassfish, nous allons développer une application d'entreprise, nommée BibliothequeEE qui regroupe deux projets internes :

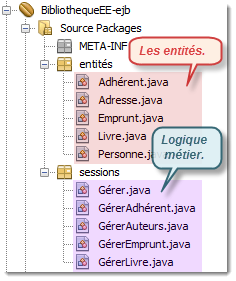
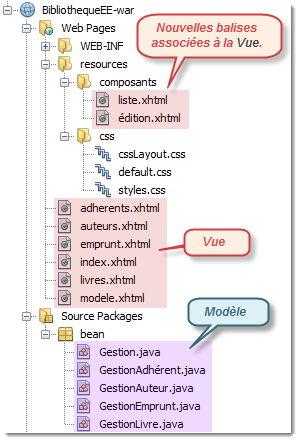
Nous allons procéder par étape en précisant ce qui se passe successivement sur chacun des cas d'utilisations que nous avons établi antérieurement. Au préalable toutefois, je vous invite à regarder globalement la partie "persistance des données" au travers donc des entités correspondantes.
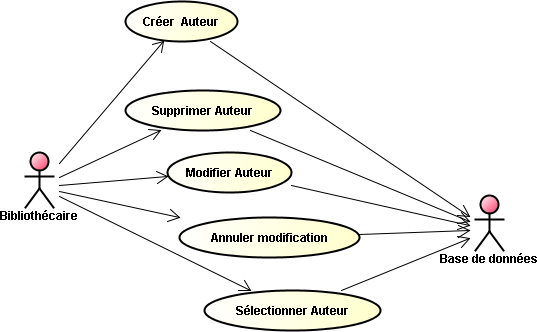
Nous allons maintenant visualiser l'ensemble du code en passant respectivement, par l'application Web, par le service proposé par le bean session correspondant, pour aboutir aux entités qui permettent les différents enregistrements dans la base de données. Nous allons pour cela traiter séparément chacun des cas d'utilisations. Nous commençons par "Gérer Auteurs".
Afin de bien montrer tous les chéminements des différentes informations pour aboutir au résultat final, je vous propose de voir l'enchaînement des traitements en commençant par la fin. Ainsi, à chaque fois, nous commencerons par l'entité correspondante suivie du bean session qui gère la persistance. Ensuite nous nous intéresserons au bean de l'application Web qui fait appel au service donné par ce bean session pour finir sur le visuel géré par la page Web dynamique correspondante.
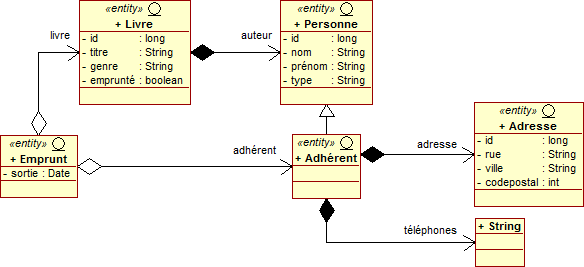
Commençons par l'entité Personne qui est à la fois utile pour la gestion globale des auteurs ainsi que pour les adhérents qui s'inscrivent dans cette bibliothèque. J'en profite pour revisualiser le diagramme des classes de l'ensemble des entités présentes dans cette application d'entreprise.
package entités; import java.io.Serializable; import javax.persistence.*; @Entity @NamedQueries({ @NamedQuery(name=, query=), @NamedQuery(name=, query=), @NamedQuery(name=, query=) }) @Inheritance(strategy=InheritanceType.JOINED) @DiscriminatorValue(value=) public class Personne implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private long id; private String prénom; private String nom; @Column(name=, insertable=false, updatable=false) private String type; public long getId() { return id; } public String getNom() { return nom; } public String getPrénom() { return prénom; } public String getType() { return type; } public void setNom(String nom) { this.nom = nom.toUpperCase(); } public void setPrénom(String prénom) { if (!prénom.isEmpty()) this.prénom = majuscule(prénom); } private String majuscule(String original) { char première = Character.toUpperCase(original.charAt(0)); StringBuilder chaîne = new StringBuilder(original); chaîne.setCharAt(0, première); return chaîne.toString(); } @Override public String toString() { return prénom+' '+nom; } }
Nous allons prendre le temps de bien analyser le code ci-dessus. Effectivement, beaucoup d'écritures spécifiques méritent toutes notre attention. Voici quelques remarques importantes :
Après avoir pris connaissance avec l'entité Personne, nous allons maintenant travailler avec le bean session GérerAuteurs qui s'occupe plus particulièrement de la persistence de cette entité.
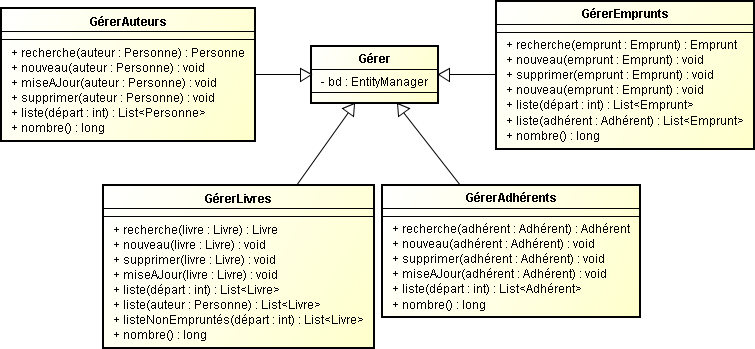
Au préalable, visualisons le diagramme de classes de l'ensemble des beans sessions de cette application d'entreprise. Globalement, vous pouvez remarquer que chaque bean session est dédié à la gestion de la persistance de l'entité correspondante.
package sessions; import javax.persistence.*; public abstract class Gérer { @PersistenceContext protected EntityManager bd; }
Dans un premier temps, nous proposons une classe abstraite Gérer qui possède un seul attribut bd qui s'occupe plus particulièrement du gestionnaire d'entité en relation avec l'unité de persistance. Chaque enfant de cette classe n'aura plus à se préoccuper de cet élément particulier.
package sessions; import entités.*; import java.util.List; import javax.ejb.*; import javax.persistence.*; @Stateless @LocalBean public class GérerAuteurs extends Gérer { public Personne recherche(Personne auteur) { return bd.find(Personne.class, auteur.getId()); } public void nouveau(Personne auteur) { Query requête = bd.createNamedQuery(); requête.setParameter(, auteur.getNom()); requête.setParameter(, auteur.getPrénom()); try { Personne personne = (Personne) requête.getSingleResult(); } catch (Exception ex) { bd.persist(auteur); } } public void miseAJour(Personne auteur) { Personne recherche = recherche(auteur); if (recherche!=null) bd.merge(auteur); } public void supprimer(Personne auteur) { Personne recherche = recherche(auteur); if (recherche!=null) bd.remove(recherche); } public List<Personne> liste(int départ) { Query requête = bd.createNamedQuery(); requête.setMaxResults(5); requête.setFirstResult(départ); return requête.getResultList(); } public long nombre() { Query requête = bd.createNamedQuery(); return (Long) requête.getSingleResult(); } }
Maintenant que la persistance est bien gérée, je vous propose de passer sur le module correspondante à la couche présentation, notamment sur la partie Modèle, représenté par des beans managés, de la technologie JSF. C'est le bean GestionAuteurs qui est spécialisé, comme son nom l'indique, à la gestion globale de l'ensemble des auteurs, avec donc la possiblité de créer de nouveaux auteurs, de les modifier, de les supprimer, etc.
Avant de consulter le codage correspondant, je vous propose, comme tout à l'heure, le diagramme des classes de l'ensemble des beans managés.

package bean; import java.io.Serializable; import javax.faces.bean.*; @ManagedBean @SessionScoped public class Gestion implements Serializable { protected boolean enregistré; protected int page; protected long nombre; public boolean isEnregistré() { return enregistré; } public String getÉtat() { return enregistré ? : ; } public String getNomBouton() { return enregistré ? : ; } public boolean isPrécédent() {return page!=0; } public boolean isSuivant() {return page < nombre-5 ; } public long getNombre() { return nombre; } }
Dans l'ensemble de ces beans managés, nous retrouvons systématiquement les mêmes traitements. Plutôt que d'effectuer une série de copier-coller, il est bien entendu plus judicieux de factoriser ces éléments communs dans une même classe, ici Gestion, et de proposer ensuite un héritage spécifique sur chacune des gestions particulières. Globalement, ce tronc commun permet de faire la gestion des boutons de la partie Vue pour qu'ils deviennent éventuellement inactifs, ou qu'ils changent d'intitulé.
package bean; import entités.Personne; import java.util.List; import javax.annotation.PostConstruct; import javax.ejb.EJB; import javax.faces.bean.*; import sessions.GérerAuteurs; @ManagedBean @SessionScoped public class GestionAuteurs extends Gestion { @EJB GérerAuteurs gestion; private Personne auteur; private List<Personne> liste; public Personne getAuteur() { return auteur; } public void setAuteur(Personne auteur) { this.auteur = auteur; } public void pagePrécédente() { page-=5; liste = gestion.liste(page); } public void pageSuivante() { page += 5; liste = gestion.liste(page); } public List<Personne> getListe() { return liste; } @PostConstruct private void init() { nombre = gestion.nombre(); if (page>0 && page>=nombre) page -= 5; liste = gestion.liste(page); if (liste.isEmpty()) auteur = new Personne(); else auteur = liste.get(0); enregistré = auteur.getId() != 0; } private void miseAjour() { nombre = gestion.nombre(); liste = gestion.liste(page); enregistré = auteur.getId() != 0; } public void sélectionner(Personne auteur) { this.auteur = auteur; } public void nouveau() { auteur = new Personne(); enregistré = false; } public void enregistrer() { if (enregistré) gestion.miseAJour(auteur); else gestion.nouveau(auteur); miseAjour(); } public void supprimer() { gestion.supprimer(auteur); init(); } public void annuler() { auteur = gestion.recherche(auteur); } }
Pour terminer, il ne nous reste plus qu'à proposer la partie Vue de la couche présentation. Il s'agit des différents documents xhtml avec l'ensemble des bibliothèques de balises spécifiques propre à JSF.
Je vous propose de revisualiser l'architecture de notre application Web. Nous revoyons ainsi les différents beans managés et nous pouvons également découvrir les pages web au format xhtml correspondant.
Vous pouvez remarquer toutefois que d'autres éléments supplémentaires existent en parallèle. C'est le cas notamment de index.xhtml, modele.xhtml, liste.xhtml et édition.xhtml.
Pour le premier, index.xhtml, nous le comprenons bien, il s'agit de la page d'accueil du site qui comporte juste le menu de navigation principal.
Ce menu est en fait entièrement décrit dans le modèle de page, modele.xhtml, prévu pour l'ensemble des Vues.
Les éléments liste.xhtml et édition.xhtml décrivent en réalité des nouvelles balises bien utiles et dont l'utilisation est récurrence pour ce projet d'entreprise.
Attention, ces deux éléments ne sont pas situés n'importe où dans l'architecture de l'application Web. Vous devez impérativement les placer dans un répertoire dont le nom est à votre libre choix, mais par contre, lui-même doit être imbriqué dans le répertoire nommé resources.
root { display: block; } body { background-color: orange; color: maroon; font-weight: bold; } .bouton { background-color: orange; color: maroon; } .inverse { background-color: maroon; color: orange; } .etat { color: #cc0000; } .ligne { background-color: #ffbb00; padding-left: 10px; padding-right: 20px; text-decoration: none; color: maroon; } .largeur { width: 150px; }
Avant tout, la première chose à ne pas négliger lorsque nous constituons une application Web est de prévoir une feuille de style pour que l'aspect proposé sur vos pages puisse être facilement modifié.
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:mod=> <h:head> <title><h:outputText value= /></title> </h:head> <h:outputStylesheet library= name= /> // intégration de notre feuille de style dans le modèle de l'ensemble des pages <h:body> <h2> <h:outputText value= /> <mod:insert name= /> // possibilité d'insertion pour les pages qui se servent du modèle </h2> <hr /> <h:form> <h:commandButton value= styleClass=inverse action=#{gestionEmprunt.changer(gestionAdhérent.adhérent, gestionLivre.livre)}/> <h:commandButton value= action= styleClass=bouton /> <h:commandButton value= action=#{gestionLivre.changerAuteur(gestionAuteur.auteur)} styleClass=bouton /> <h:commandButton value= action= styleClass=bouton /> <br /> <hr /> <mod:insert name= /> // possibilité d'insertion pour les pages qui se servent du modèle </h:form> <hr /> </h:body> </html>
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:cc=> <!-- INTERFACE --> <cc:interface> <cc:attribute name= required= /> </cc:interface> <!-- IMPLEMENTATION --> <cc:implementation> <br /> <h:commandButton value= action=#{cc.attrs.nom.nouveau} /> <h:commandButton value=#{cc.attrs.nom.nomBouton} action=#{cc.attrs.nom.enregistrer} /> <h:commandButton value= action=#{cc.attrs.nom.supprimer} disabled=#{not cc.attrs.nom.enregistré} /> <h:commandButton value= action=#{cc.attrs.nom.annuler} disabled=#{not cc.attrs.nom.enregistré} /> <br /> </cc:implementation> </html>
Vous avez ci-dessous la création d'un autre composant capable de gérer l'affichage d'une liste, par exemple, la liste des auteurs, la liste des livres, la liste des adhérents, etc.
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f= xmlns:cc=> <!-- INTERFACE --> <cc:interface> <cc:attribute name= required= /> </cc:interface> <!-- IMPLEMENTATION --> <cc:implementation> <hr /> <h:dataTable value=#{cc.attrs.nom.liste} var= headerClass=inverse columnClasses=ligne, ligne> <cc:insertChildren /> <h:column> <f:facet name=>#{cc.attrs.nom.nombre}</f:facet> <h:commandButton value= action=#{cc.attrs.nom.sélectionner(élément)} /> </h:column> </h:dataTable> <br /> <h:commandButton value= action=#{cc.attrs.nom.pagePrécédente} disabled=#{not cc.attrs.nom.précédent}/> <h:commandButton value= action=#{cc.attrs.nom.pageSuivante} disabled=#{not cc.attrs.nom.suivant} /> </cc:implementation> </html>
Je tiens à rajouter une explication supplémentaire. Lors de l'utilisation de nos nouvelles balises, il est possible de pouvoir rajouter d'autres balises à l'intérieur. Pour cela, vous devez préciser dans la conception de votre composant l'endroit où cette insertion est possible, au moyen de la balise <cc:insertChildren />.
Passons maintenant aux pages Web qui vont représenter les différentes Vues, et commençons par la page d'accueil, index.xhtml.
.
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:mod=> <mod:composition template=> <mod:define name=> <h:outputText value= /> </mod:define> </mod:composition> </html>
Nous en arrivons enfin à la page Web qui s'occupe de la gestion des auteurs.
.
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f= xmlns:mod= xmlns:comp=> <mod:composition template=> <mod:define name=> <h:outputText value= /> </mod:define> <mod:define name=> <h:panelGrid columns=> <h:outputText value= /> <h:inputText value=#{gestionAuteurs.auteur.prénom} /> <h:outputText value= /> <h:inputText value=#{gestionAuteurs.auteur.nom} /> <h:outputText value=#{gestionAuteurs.état} styleClass=etat/> </h:panelGrid> <comp:édition nom=#{gestionAuteurs} /> <comp:liste nom=#{gestionAuteurs}> <h:column> <f:facet name=>Nom</f:facet> #{élément.nom} </h:column> <h:column> <f:facet name=>Prénom</f:facet> #{élément.prénom} </h:column> </comp:liste> </mod:define> </mod:composition> </html>
Nous avons passé pas mal de temps sur le cas d'utilisation "Gérer Auteurs" puisque tous les fonctionnalités annexes étaient à décrire. Maintenant, nous pourrons avancer plus rapidement. Passons donc au cas d'utilisation "Gérer Livres".
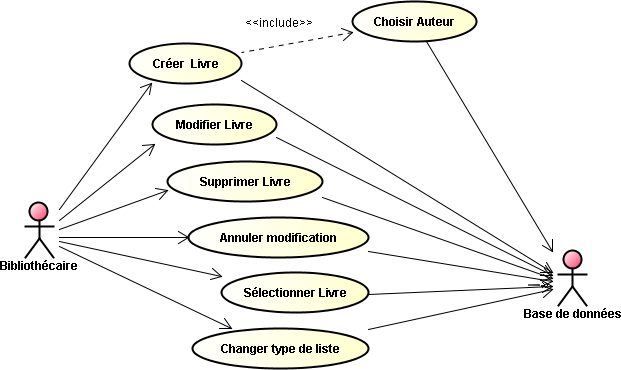
Je vous propose de reprendre la même progression en partant de l'entité avec la table de la base de données correspondante, le bean session qui gère la persistance de ces livres, le bean managé côté application Web avec le visuel correspondant. Je vous repropose également le diagramme des classes de l'ensemble des entités :
package entités; import java.io.Serializable; import javax.persistence.*; @Entity @NamedQueries({ @NamedQuery(name=, query=), @NamedQuery(name=, query=), @NamedQuery(name=, query=), @NamedQuery(name=, query=), @NamedQuery(name=, query=) }) public class Livre implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private long id; private String titre; private String genre = ; @OneToOne(fetch=FetchType.EAGER) private Personne auteur; private boolean emprunté; public long getId() { return id; } public Personne getAuteur() { return auteur; } public String getGenre() { return genre; } public String getTitre() { return titre; } public boolean isEmprunté() { return emprunté; } public void setAuteur(Personne auteur) { this.auteur = auteur; } public void setGenre(String genre) { this.genre = majuscule(genre); } public void setTitre(String titre) { if (!titre.isEmpty()) this.titre = majuscule(titre); } public void setEmprunté(boolean emprunté) { this.emprunté = emprunté; } private String majuscule(String original) { char première = Character.toUpperCase(original.charAt(0)); StringBuilder chaîne = new StringBuilder(original); chaîne.setCharAt(0, première); return chaîne.toString(); } @Override public String toString() { return titre++auteur.getNom()+; } }
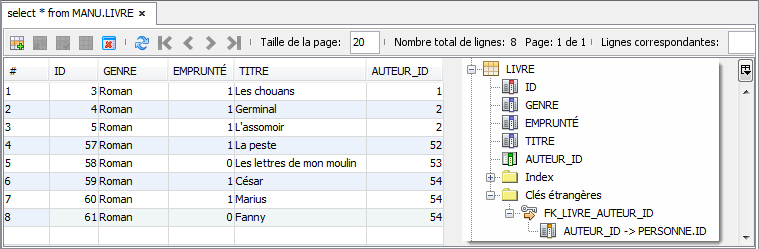
Passons maintenant au bean session GérerLivres qui s'occupe de la persistance complète de l'entité Livre. Je rappelle au passage le diagramme de classes correspondant à l'ensemble des beans sessions de cette application d'entreprise.
package sessions; import entités.*; import java.util.List; import javax.ejb.*; import javax.persistence.*; @Stateless @LocalBean public class GérerLivres extends Gérer { public Livre recherche(Livre livre) { return bd.find(Livre.class, livre.getId()); } public void nouveau(Livre livre) { Query requête = bd.createNamedQuery(); requête.setParameter(, livre.getTitre()); try { Livre document = (Livre) requête.getSingleResult(); } catch (Exception ex) { bd.persist(livre); } } public void supprimer(Livre livre) { Livre recherche = recherche(livre); if (recherche!=null) bd.remove(recherche); } public void miseAJour(Livre livre) { Livre recherche = recherche(livre); if (recherche!=null) bd.merge(livre); } public List<Livre> liste(int départ) { Query requête = bd.createNamedQuery(); requête.setMaxResults(5); requête.setFirstResult(départ); return requête.getResultList(); } public List<Livre> liste(Personne auteur) { Query requête = bd.createNamedQuery(); requête.setParameter(, auteur); return requête.getResultList(); } public List<Livre> listeNonEmpruntés(int départ) { Query requête = bd.createNamedQuery(); requête.setMaxResults(5); requête.setFirstResult(départ); return requête.getResultList(); } public long nombre() { Query requête = bd.createNamedQuery(); return (Long) requête.getSingleResult(); } }
Je ne ferais aucune remarque particulière, puisque nous avons pratiquement la même ossature que le bean session précédent. Nous passons donc tout de suite au bean managé GestionLivres qui utilise les compétences de ce bean session GérerLivres. Je rappelle également à titre indicatif le diagramme de classes des beans managés de l'application Web.
package bean; import entités.*; import java.util.List; import javax.annotation.PostConstruct; import javax.ejb.EJB; import javax.faces.bean.*; import javax.faces.event.*; import sessions.*; @ManagedBean @SessionScoped public class GestionLivres extends Gestion { @EJB GérerLivres gestion; private Livre livre; private List<Livre> liste; private Personne auteur; private int typeListe = 1; public Livre getLivre() { return livre; } public Personne getAuteur() { return auteur; } public void setLivre(Livre livre) { this.livre = livre; } public List<Livre> getListe() { return liste; } public String getLivreEmprunté() { return livre.isEmprunté() ? : ; } public int getTypeListe() { return typeListe; } public void setTypeListe(int typeListe) { this.typeListe = typeListe; } private void récupérerListe() { switch (typeListe) { case 1: liste = gestion.liste(page); break; case 2: liste = gestion.liste(auteur); break; case 3: liste = gestion.listeNonEmpruntés(page); break; } } public String changerAuteur(Personne auteur) { if (enregistré) this.auteur = auteur; else livre.setAuteur(auteur); récupérerListe(); return ; } public void changeTypeListe(ValueChangeEvent evt) { typeListe = (Integer)evt.getNewValue(); récupérerListe(); } public void pagePrécédente() { page-=5; liste = gestion.liste(page); } public void pageSuivante() { page += 5; liste = gestion.liste(page); } @PostConstruct private void init() { nombre = gestion.nombre(); if (page>0 && page>=nombre) page -= 5; récupérerListe(); if (liste.isEmpty()) livre = new Livre(); else livre = liste.get(0); enregistré = livre.getId() != 0; } private void miseAjour() { nombre = gestion.nombre(); récupérerListe(); enregistré = livre.getId() != 0; } public void sélectionner(Livre livre) { this.livre = livre; } public String choix() { miseAjour(); return ; } public void nouveau() { livre = new Livre(); livre.setAuteur(auteur); enregistré = false; } public void enregistrer() { if (enregistré) gestion.miseAJour(livre); else { gestion.nouveau(livre); auteur = livre.getAuteur(); } miseAjour(); } public void supprimer() { gestion.supprimer(livre); init(); } public void annuler() { livre = gestion.recherche(livre); } }
Nous retrouvons pratiquement la même ossature que le bean managé précédent. J'évoquerais juste une petite nouveauté concernant la méthode void changeTypeListe(ValueChangeEvent evt). Cette méthode sera sollicité lorsqu'un événement de type changement de valeur interviendra au niveau de la partie visuelle. C'est le cas, comme vous allez le découvrir ci-dessous, lorsque l'utilisateur sélectionne le bouton radio correspond au type de liste à afficher.
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f= xmlns:mod= xmlns:comp=> <mod:composition template=> <mod:define name=> <h:outputText value= /> </mod:define> <mod:define name=> <h:panelGrid columns=> <h:outputText value= /> <h:inputText value=#{gestionLivres.livre.titre} /> <h:outputText value= /> <h:inputText value=#{gestionLivres.livre.genre} /> <h:outputText value= /> <h:commandButton value=#{gestionLivres.livre.auteur} action= styleClass=largeur/> <h:outputText value=#{gestionLivres.état} styleClass=etat/> <h:outputText value=#{gestionLivres.livreEmprunté} style=color: green /> </h:panelGrid> <comp:édition nom=#{gestionLivres} /> <hr /> <h:selectOneRadio value=#{gestionLivres.typeListe} valueChangeListener=#{gestionLivres.changeTypeListe} onchange=submit()> <f:selectItem itemValue= itemLabel= /> <f:selectItem itemValue= itemLabel= /> <f:selectItem itemValue= itemLabel= /> </h:selectOneRadio> <h:commandButton value=#{gestionLivres.auteur} action= styleClass=largeur/> <comp:liste nom=#{gestionLivres}> <h:column> <f:facet name=>Titre</f:facet> #{élément.titre} </h:column> <h:column> <f:facet name=>Auteur</f:facet> #{élément.auteur} </h:column> <h:column> <h:selectBooleanCheckbox disabled= value=#{élément.emprunté} /> </h:column> </comp:liste> </mod:define> </mod:composition> </html>
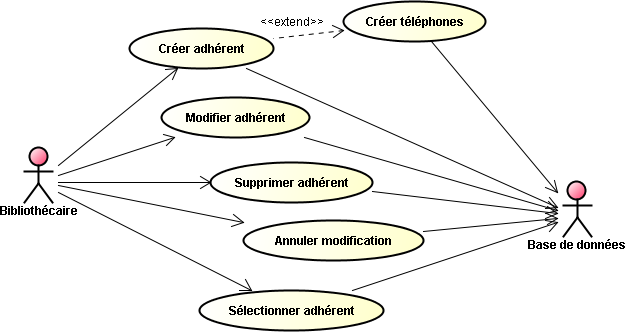
Diagramme des classes de l'ensemble des entités :
package entités; import java.io.Serializable; import javax.persistence.*; @Entity public class Adresse implements Serializable { @Id @GeneratedValue(strategy = GenerationType.AUTO) private long id; private String rue; private String ville; private int codePostal; public int getCodePostal() { return codePostal; } public String getRue() { return rue; } public String getVille() { return ville; } public long getId() { return id; } public void setCodePostal(int codePostal) { this.codePostal = codePostal; } public void setRue(String rue) { this.rue = rue; } public void setVille(String ville) { this.ville = ville.toUpperCase(); } @PrePersist @PreUpdate private void validation() { if (codePostal<0 || codePostal>=100000) throw new IllegalArgumentException(); } }
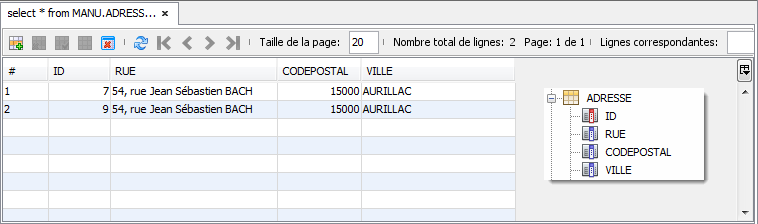
package entités; import java.util.ArrayList; import javax.persistence.*; @Entity @NamedQueries({ @NamedQuery(name=, query=), @NamedQuery(name=, query=), @NamedQuery(name=, query=) }) public class Adhérents extends Personne { @ElementCollection(fetch = FetchType.EAGER) private ArrayList<String> téléphones = new ArrayList<String>(); @OneToOne(cascade=CascadeType.ALL) private Adresse adresse = new Adresse(); public Adresse getAdresse() { return adresse; } public void setAdresse(Adresse adresse) { this.adresse = adresse; } public ArrayList<String> getTéléphones() { return téléphones; } public void ajoutTéléphone(String numéro) { téléphones.add(numéro); } public void supprimeTéléphone(String numéro) { téléphones.remove(numéro); } }
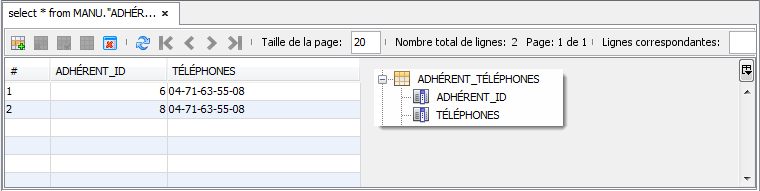
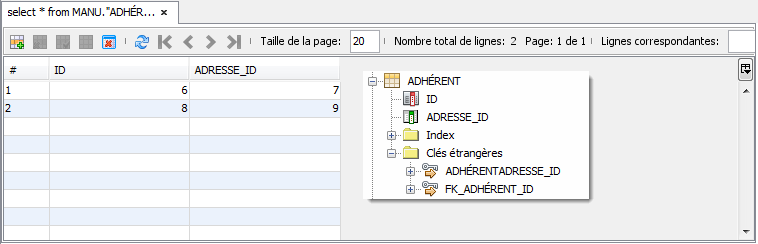
Passons maintenant au bean session GérerAdhérents qui s'occupe de la persistance complète des entités Adhérent et Adresse. Je rappelle au passage le diagramme de classes correspondant à l'ensemble des beans sessions de cette application d'entreprise.
package sessions; import entités.*; import java.util.List; import javax.ejb.*; import javax.persistence.Query; @Stateless @LocalBean public class GérerAdhérents extends Gérer { public Adhérent recherche(Adhérent adhérent) { return bd.find(Adhérent.class, adhérent.getId()); } public void nouveau(Adhérent adhérent) { Query requête = bd.createNamedQuery(); requête.setParameter(, adhérent.getNom()); requête.setParameter(, adhérent.getPrénom()); try { Adhérent personne = (Adhérent) requête.getSingleResult(); } catch (Exception ex) { bd.persist(adhérent); } } public void supprimer(Adhérent adhérent) { Adhérent recherche = recherche(adhérent); if (recherche!=null) bd.remove(recherche); } public void miseAJour(Adhérent adhérent) { Adhérent recherche = recherche(adhérent); if (recherche!=null) bd.merge(adhérent); } public List<Adhérent> liste(int départ) { Query requête = bd.createNamedQuery(); requête.setMaxResults(5); requête.setFirstResult(départ); return requête.getResultList(); } public long nombre() { Query requête = bd.createNamedQuery(); return (Long) requête.getSingleResult(); } }
Je ne ferais aucune remarque particulière, puisque nous avons pratiquement la même ossature que le bean session précédent. Nous passons donc tout de suite au bean managé GestionAdhérents qui utilise les compétences de ce bean session GérerAdhérents. Je rappelle également à titre indicatif le diagramme de classes des beans managés de l'application Web.
package bean; import entités.Adhérent; import java.util.List; import javax.annotation.PostConstruct; import javax.faces.bean.*; import sessions.GérerAdhérent; import javax.ejb.EJB; @ManagedBean @SessionScoped public class GestionAdhérents extends Gestion { @EJB GérerAdhérents gestion; private Adhérent adhérent; private List<Adhérent> liste; private String téléphone; public Adhérent getAdhérent() { return adhérent; } public void setAdhérent(Adhérent adhérent) { this.adhérent = adhérent; } public String getTéléphone() { return téléphone; } public void setTéléphone(String téléphone) { this.téléphone = téléphone; } public void ajoutTéléphone() { adhérent.ajoutTéléphone(téléphone); } public void supprimeTéléphone() { adhérent.supprimeTéléphone(téléphone); } public void pagePrécédente() { page-=5; liste = gestion.liste(page); } public void pageSuivante() { page += 5; liste = gestion.liste(page); } public List<Adhérent> getListe() { return liste; } @PostConstruct private void init() { nombre = gestion.nombre(); if (page>0 && page>=nombre) page -= 5; liste = gestion.liste(page); if (liste.isEmpty()) adhérent = new Adhérent(); else adhérent = liste.get(0); enregistré = adhérent.getId() != 0; } private void miseAjour() { nombre = gestion.nombre(); liste = gestion.liste(page); enregistré = adhérent.getId() != 0; } public void sélectionner(Adhérent adhérent) { this.adhérent = adhérent; } public void nouveau() { adhérent = new Adhérent(); enregistré = false; } public void enregistrer() { if (enregistré) gestion.miseAJour(adhérent); else gestion.nouveau(adhérent); miseAjour(); } public void supprimer() { gestion.supprimer(adhérent); init(); } public void annuler() { adhérent = gestion.recherche(adhérent); } }
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f= xmlns:mod= xmlns:comp=> <mod:composition template=> <mod:define name=> <h:outputText value= /> </mod:define> <mod:define name=> <h:panelGrid columns=> <h:outputText value= /> <h:inputText value=#{gestionAdhérents.adhérent.prénom} /> <h:outputText value= /> <h:inputText value=#{gestionAdhérents.adhérent.nom} /> <h:outputText value= /> <h:inputText value=#{gestionAdhérents.adhérent.adresse.rue} size= /> <h:outputText value= /> <h:inputText value=#{gestionAdhérents.adhérent.adresse.ville} /> <h:outputText value= /> <h:inputText value=#{gestionAdhérents.adhérent.adresse.codePostal} /> <h:outputText value= /> <h:selectOneMenu value=#{gestionAdhérents.téléphone} styleClass=largeur> <f:selectItems value=#{gestionAdhérents.adhérent.téléphones} /> </h:selectOneMenu> <h:outputText value=#{gestionAdhérents.état} styleClass=etat/> </h:panelGrid> <br /> <h:outputText value= /> <h:inputText value=#{gestionAdhérents.téléphone} /> <h:commandButton value= action=#{gestionAdhérents.ajoutTéléphone} /> <h:commandButton value= action=#{gestionAdhérents.supprimeTéléphone} /> <br /> <comp:édition nom=#{gestionAdhérents} /> <comp:liste nom=#{gestionAdhérents}> <h:column> <f:facet name=>Nom</f:facet> #{élément.nom} </h:column> <h:column> <f:facet name=>Prénom</f:facet> #{élément.prénom} </h:column> </comp:liste> </mod:define> </mod:composition> </html>
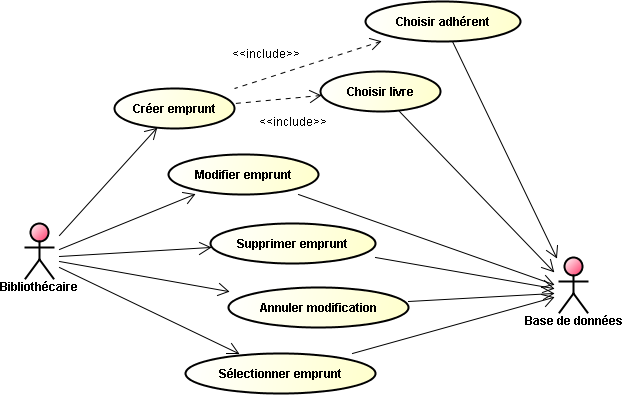
Diagramme des classes de l'ensemble des entités :
package entités; import java.io.Serializable; import java.util.Date; import javax.persistence.*; @Entity @NamedQueries({ @NamedQuery(name=, query=), @NamedQuery(name=, query=), @NamedQuery(name=, query=) }) public class Emprunt implements Serializable { @Id @GeneratedValue private long id; private Adhérent adhérent; private Livre livre; @Temporal(TemporalType.DATE) private Date sortie; @Transient private final int JOURS = 21; public long getId() { return id; } public Adhérent getAdhérent() { return adhérent; } public void setAdhérent(Adhérent adhérent) { this.adhérent = adhérent; } public Livre getLivre() { return livre; } public void setLivre(Livre livre) { this.livre = livre; } public Date getSortie() { return sortie; } public Emprunt() { sortie = new Date(); } public long getJoursRestant() { long maintenant = new Date().getTime(); long instantSortie = sortie.getTime(); long nombreJours = (maintenant - instantSortie) / 1000 / 3600 / 24; return JOURS - nombreJours; } public boolean isTempsDépassé() { return getJoursRestant() < 0; } }
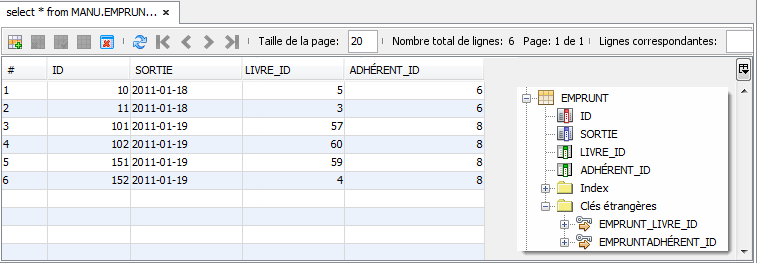
Passons maintenant au bean session GérerEmprunts qui s'occupe de la persistance complète des entites Emprunt. Je rappelle au passage le diagramme de classes correspondant à l'ensemble des beans sessions de cette application d'entreprise.
package sessions; import entités.*; import java.util.List; import javax.ejb.*; import javax.persistence.*; @Stateless @LocalBean public class GérerEmprunts extends Gérer { public Emprunt recherche(Emprunt emprunt) { return bd.find(Emprunt.class, emprunt.getId()); } public void nouveau(Emprunt emprunt) { Livre livre = emprunt.getLivre(); livre.setEmprunté(true); bd.merge(livre); bd.persist(emprunt); } public void supprimer(Emprunt emprunt) { Emprunt recherche = recherche(emprunt); if (recherche!=null) { Livre livre = recherche.getLivre(); livre.setEmprunté(false); bd.merge(livre); bd.remove(recherche); } } public List<Emprunt> liste(int départ) { Query requête = bd.createNamedQuery(); requête.setMaxResults(5); requête.setFirstResult(départ); return requête.getResultList(); } public long nombre() { Query requête = bd.createNamedQuery(); return (Long) requête.getSingleResult(); } public List<Emprunt> liste(Adhérent adhérent) { Query requête = bd.createNamedQuery(); requête.setParameter(, adhérent); return requête.getResultList(); } }
Je ne ferais aucune remarque particulière, puisque nous avons pratiquement la même ossature que le bean session précédent. Nous passons donc tout de suite au bean managé GestionEmprunts qui utilise les compétences de ce bean session GérerEmprunts. Je rappelle également à titre indicatif le diagramme de classes des beans managés de l'application Web.
package bean; import entités.*; import java.util.List; import javax.annotation.PostConstruct; import javax.faces.bean.*; import sessions.GérerEmprunt; import javax.ejb.EJB; import javax.faces.event.ValueChangeEvent; @ManagedBean @SessionScoped public class GestionEmprunts extends Gestion { @EJB GérerEmprunts gestion; private Emprunt emprunt; private List<Emprunt> liste; private Adhérent adhérent; private Livre livre; private int typeListe = 1; public Emprunt getEmprunt() { return emprunt; } public void setEmprunt(Emprunt emprunt) { this.emprunt = emprunt; } public Adhérent getAdhérent() { return adhérent; } public Livre getLivre() { return livre; } public String changer(Adhérent adhérent, Livre livre) { if (enregistré) { this.adhérent = adhérent; this.livre = livre; } else { emprunt.setAdhérent(adhérent); emprunt.setLivre(livre); } récupérerListe(); return ; } public int getTypeListe() { return typeListe; } public void setTypeListe(int typeListe) { this.typeListe = typeListe; } private void récupérerListe() { switch (typeListe) { case 1: liste = gestion.liste(page); break; case 2: liste = gestion.liste(adhérent); break; } } public void changeTypeListe(ValueChangeEvent evt) { typeListe = (Integer)evt.getNewValue(); récupérerListe(); } public void pagePrécédente() { page-=5; liste = gestion.liste(page); } public void pageSuivante() { page += 5; liste = gestion.liste(page); } public List<Emprunt> getListe() { return liste; } @PostConstruct private void init() { nombre = gestion.nombre(); if (page>0 && page>=nombre) page -= 5; liste = gestion.liste(page); if (liste.isEmpty()) emprunt = new Emprunt(); else emprunt = liste.get(0); enregistré = emprunt.getId() != 0; } private void miseAjour() { nombre = gestion.nombre(); récupérerListe(); enregistré = emprunt.getId() != 0; } public void sélectionner(Emprunt emprunt) { this.emprunt = emprunt; } public void nouveau() { emprunt = new Emprunt(); emprunt.setAdhérent(adhérent); enregistré = false; } public void enregistrer() { if (!enregistré) gestion.nouveau(emprunt); miseAjour(); } public void supprimer() { gestion.supprimer(emprunt); init(); } }
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f= xmlns:mod= xmlns:comp=> <mod:composition template=> <mod:define name=> <h:outputText value= /> </mod:define> <mod:define name=> <h:panelGrid columns=> <h:outputText value= /> <h:commandButton value=#{gestionEmprunts.emprunt.adhérent} action= styleClass=largeur/> <h:outputText value= /> <h:commandButton value=#{gestionEmprunts.emprunt.livre} action=#{gestionLivre.choix} styleClass=largeur/> <h:outputText value=#{gestionEmprunts.état} styleClass=etat/> <h:outputFormat value= style=color: green> <f:param value=#{gestionEmprunts.emprunt.joursRestant} /> </h:outputFormat> </h:panelGrid> <comp:édition nom=#{gestionEmprunts} /> <hr /> <h:selectOneRadio value=#{gestionEmprunts.typeListe} valueChangeListener=#{gestionEmprunts.changeTypeListe} onchange=submit()> <f:selectItem itemValue= itemLabel= /> <f:selectItem itemValue= itemLabel= /> </h:selectOneRadio> <h:commandButton value=#{gestionEmprunts.adhérent} action= styleClass=largeur/> <comp:liste nom=#{gestionEmprunts}> <h:column> <f:facet name=>Adhérent</f:facet> #{élément.adhérent} </h:column> <h:column> <f:facet name=>Livre</f:facet> <h:outputText value=#{élément.livre} /> <h:outputFormat value= style=color: green> <f:param value=#{gestionEmprunts.emprunt.joursRestant} /> </h:outputFormat> </h:column> </comp:liste> </mod:define> </mod:composition> </html>