Introduction à Java EE
Introduction à Java EE
 Les derniers chapitres étaient consacrés à la programmation réseau. Ils nous ont permis de maîtriser un certain nombre de concept, avec :
Les derniers chapitres étaient consacrés à la programmation réseau. Ils nous ont permis de maîtriser un certain nombre de concept, avec :
Toute cette technologie que nous venons d'apprendre est vraiment primordiale pour le développement réseau. Toutefois, un certain nombre de sujets n'ont pas encore été abordé.
En fait, tout ce que nous avons appris dans l'étude de la programmation réseaux est un préalable à Java EE. Java EE reprend tout ces concepts là, mais va encore plus loin, notamment dans la modularité et la sécurité. Java EE est une architecture aboutie et performante, elle a été mise en oeuvre pour le monde des entreprises qui ont besoin d'un système stable qui accepte facilement la montée en charge sans poser de problème de sécurité. Pour terminer, Java EE exploite au maximum la technologie des objets distribués, ce qui permet d'avoir un système simple à utiliser côté clients.
Java EE signifie Java Entreprise Edition et représente essentiellement des applications d'entreprise. Cela inclut le stockage sécurisé des informations, ainsi que leur manipulation et leur traitement : factures clients, calculs d'amortissement, réservation de vols, etc.
Ces applications peuvent avoir des interfaces utilisateurs multiples, par exemple une interface Web pour les clients, accessible sur Internet et une interface graphique fonctionnant sur les ordinateurs de l'entreprise sur le réseau privé de celle-ci.

Elles doivent gérer les communications entre systèmes distants, s'occuper automatiquement des différents protocoles de commmunication, synchroniser les sources avec éventuellement des technologies différentes, et s'assurer que le système respecte en permanences les règles de l'activité de l'entreprise, appelés règles "métier". Pour finir, ces applications s'occupe également automatiquement de la base de données sans que le développeur est à intervenir (bien entendu si le besoin s'en fait sentir).
Tout comme les bibliothèques d'interfaces graphiques comme Swing fournissent les services nécessaires au développement d'application graphiques, les serveurs d'applications mettent à disposition les fonctionnalités permettant de réaliser des applications d'entreprise : communication entre ordinateurs, mis en place de protocole adaptés, gestion des connexions avec une base de données, présentation de pages Web, gestion des transactions, etc.
Java EE propose justement un ensemble de bibliothèques avec des objets de très haut niveau pour mettre en oeuvre facilement ses serveurs d'applications. Chacun de ces objets est adaptée à la situation en correspondant parfaitement au canevas de l'ensemble du processus. Ainsi, les développeurs n'ont pas à partir d'une feuille blanche et surtout Java EE permet d'avoir une démarche standardisée.
Pour de nombreux développeurs, Java EE est souvent synonyme de Entreprise JavaBeans. En fait, Java EE est beaucoup plus que cela. En simplifiant, nous pouvons dire que Java EE est une collection de composants, de conteneurs et de services permettant de créer et de déployer des applications distribuées au sein d'une architecture standardisée.
Java EE est logiquement destiné aux gros systèmes d'entreprise. Les logiciels employés à ce niveau ne fonctionne pas sur un simple PC mais requière une puissance beaucoup plus importante. Pour cette raison, les applications doivent être constituées de plusieurs composants pouvant être déployés sur des plate-formes multiples afin de disposer de la puissance de calcul nécessaire. C'est la raison d'être des applications distribuées.
Java EE fournit un ensemble de composants standardisés facilitant le déploiement des applications, des interfaces définissant la façon dont les modules logiciels peuvent être interconnectés, et les services standards, avec leur protocole associé, grâce auxquels ces modules peuvent communiquer.
Un des thèmes récurrent du développement d'applications Java EE est la décomposition de celles-ci en plusieurs niveaux, ou tiers. Généralement, une application d'entreprise est composée de trois couches fondamentales (d'où le terme décomposition en trois tiers) :

Les applications bureautiques sont conçues pour fonctionner sur un ordinateur unique. Toutes les services fournis par l'application - interface utilisateur, persistance des données (sauvegarde dans des fichiers propriétaires) et logique de traitement de ces données - résident sur la même machine et sont inclus dans l'application. Cette architecture monolitique est appelée simple tiers car toutes les fonctionnalités sont comprises dans une seule couche logicielle.
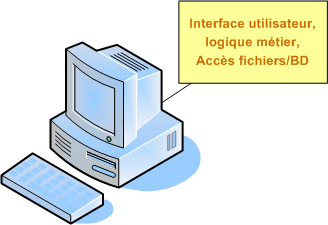
Les applications plus complexes peuvent tirer parti d'une base de données et accéder aux informations qu'elle contient en envoyant des commandes SQL à un serveur pour lire et écrire les données. Dans ce cas, la base de données fonctionne dans un processus indépendant de celui de l'application, et parfois sur une machine différente. Les composants permettant l'accès aux données sont séparés du reste de l'application.
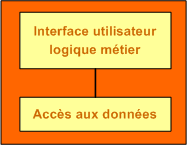
La raison de cette approche est de centraliser les données afin de permettre à plusieurs utilisateurs d'y accéder simultanément. Les données peuvent ainsi être partagées entre plusieurs utilisateurs de l'application. Cette architecture est communément appelée client-serveur, qui dans notre approche peut être représentée en deux tiers.
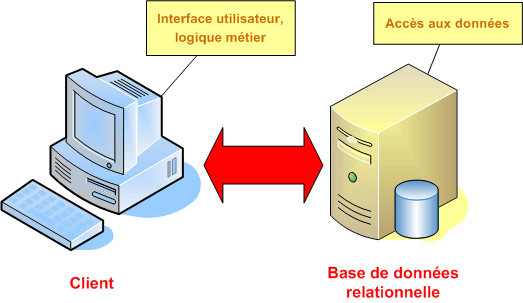
Un des inconvénient de l'architecture deux-tiers est que la logique chargée de la manipulation des données et de l'application des règles métiers afférentes est incluse dans l'application elle-même. Cela pose problème lorsque plusieurs applications doivent partager l'accès à une base de données. Il peut y avoir, par exemple, une règle stipulant qu'un client affichant un retard de paiement de plus de 90 jours verra son compte suspendu. Il n'est pas compliqué d'implémenter cette règle dans chaque application accédant aux données client. Toutefois, si la règle change et qu'un délai de 60 jours est appliqué, il faudra mettre à jour toutes les applications, ce qui peut être contraignant.
Pour éviter cette pagaille, la solution consiste à séparer physiquement les règles métier en les plaçant sur un serveur où elles n'auront à être remise à jour qu'une seule fois, et non autant de fois qu'il y a d'applications qui y accède. Cette solution ajoute un troisième tiers à l'architecture client-serveur.
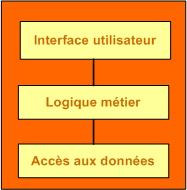
Selon ce modèle, toute la logique métier est extraite de l'application cliente. Celle-ci n'est plus responsable que de la présentation de l'interface à l'utilisateur et de la communication avec le tiers médian. Elle n'est plus responsable de l'application des règles. Son rôle est réduit à la couche présentation.
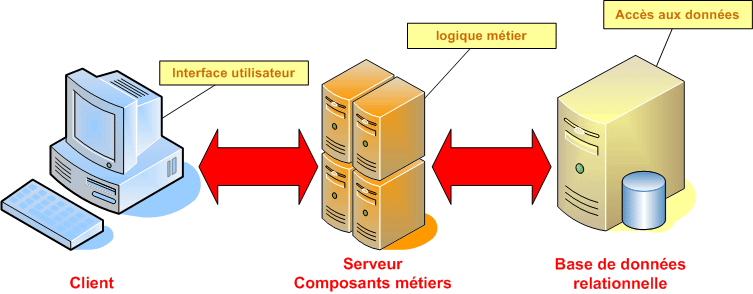
Un des avantages essentiel de cette architecture est qu'elle rend possible la création d'applications dans lesquelles les classes définies au niveau de la logique métier sont directement tirées du domaine de l'application. Le code de cette couche peut utiliser des classes modélisant les objets du monde réel (par exemple des clients) au lieu de manipuler des requêtes SQL complexes.
En plaçant les détails de l'implémentation dans les couches appropriées et en concervant des applications fonctionnant avec des classes modélisant les objets du monde réel, les applications sont plus faciles à maintenir et à faire évoluer.
Les termes "client" et "serveur" recouvrent des concepts spécifiques dans le contexte J2EE
Un client Java EE peut être une application console (texte seulement) écrite en Java, ou une application dotée d'une interface graphique développée en Swing. Ce type de client est appelé client lourd, en raison de la quantité importante de code qu'il met en oeuvre.
Un client Java EE peut également être conçu pour être utilisé à partir du Web. Ce type de client fonctionne à l'intérieur d'un navigateur Web. La plus grande partie du travail est reportée sur le serveur et le client ne comporte que très peu de code. Pour cette raison, on parle de client léger. Un client léger peut être une simple interface HTML, une page contenant des scripts JavaScript, ou encore une applet Java si une interface un peu plus riche est nécessaire.
Les composants déployés sur le serveur peuvent être classés en deux groupes. Les composants Web sont réalisés à l'aide de servlets ou de JavaServer Pages (JSP). Les composants métiers, dans le contexte Java EE, sont des Entreprise JavaBeans (EJB).
Les conteneurs sont les éléments fondamentaux de l'architecture Java EE. Les conteneurs fournis par Java EE sont de même type. Ils fournissent une interface parfaitement définie ainsi qu'un ensemble de services permettant aux développeurs d'applications de se concentrer sur la logique métier à mettre en oeuvre pour résoudre le problème qu'ils ont à traiter, sans qu'ils aient à se préocuper de toute l'infrastructure interne.
Les conteneurs s'occupent de toutes les tâches fastidieuses liées au démarrage des services sur le serveur, à l'activation de la logique applicative, la gestion des protocoles de communication intrinsèque ainsi qu'à la libération des ressources utilisées.

Java EE et la plate-forme Java disposent de conteneurs pour les composants Web et les composants métiers. Ces conteneurs possèdent des interfaces leur permettant de communiquer avec les composants qu'ils hébergent. Les principaux conteneurs Java EE sont notamment ceux dédiées aux EJB, aux JSP, aux servlets et aux clients Java EE.
Nous avons déjà traité les servlets dans deux cours précédents. Rappelons de quoi il s'agit :
Vous avez sans doute l'habitude d'accéder à des pages HTML statiques à l'aide d'un navigateur envoyant une requête à un serveur Web, celui-ci renvoyant alors une page stockée sur son disque dur. Dans cette configuration, le serveur joue le rôle d'un bibliothécaire virtuel qui renvoie le document demandé.
Ce modèle ne permet pas d'accéder à des pages dynamiques, dont le contenu serait créé à la demande. Supposons par exemple que le client souhaite obtenir une liste des documents HTML correspondant à certains critères. Dans ce cas, il est nécessaire de créer une page HTML différente en fonction des critères spécifiés par le client.
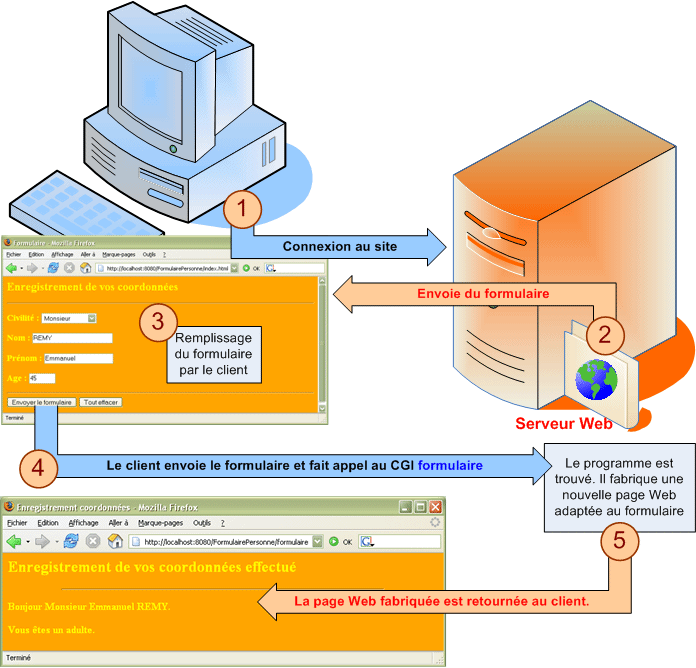
Une servlet Java est un composant implémentant l'interface javax.servlet.Servlet. Son invocation est la conséquence de la requête du client, dirigé vers cette servlet. Bien que cela ne soit pas obligatoire, généralement les servlets sont associées à l'environnement Web et aux requêtes HTTP. Le serveur Web reçoit une demande adressée à une servlet sous la forme d'une requête HTTP. Il transmet la requête à la servlet concernée, puis renvoie la réponse fournie par celle du client . La servlet reçoit également les paramètres de la requête envoyée par le client. Elle peut alors effectuer toutes les opérations nécessaires pour construire la réponse avant de renvoyer celle-ci sous forme de code HTML.
Le conteneur de servlets permet une gestion facile des sessions qui autorise l'écriture d'applications Web complexes. Les servlets peuvent également utiliser les composants JavaBeans (qui n'ont rien en commun avec les Entreprise JavaBeans, en dehors de leur nom). Les JavaBeans sont tout simplement des classes connexe à la servlet et qui permettent d'augmenter de manière significative la modularité des applications. Dans ce cas là, nous avons la même démarche que pour la fabrication d'une application classique constituée de plusieurs classes qui forment les briques de l'ensemble.
package formulairepersonne;
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
public class Formulaire extends HttpServlet {
//Traiter la requête HTTP Get
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html"); // type MIME pour l'en-tête http --> Page HTML
PrintWriter out = response.getWriter();
out.println("<html>");
out.println("<head><title>Enregistrement coordonnées</title></head>");
out.println("<body bgcolor=orange text=yellow>");
out.println("<h2>Enregistrement de vos coordonnées effectué</h2>");
out.println("<hr width=75%>");
out.print("<p><b>Bonjour "+ request.getParameter("civilite")+" ");
out.print(request.getParameter("prenom")+" ");
out.println(request.getParameter("nom")+".");
int âge = Integer.parseInt(request.getParameter("age"));
String message = "Vous êtes un";
if (âge>0 && âge<12) message += " enfant.";
if (âge>=12 && âge<18) message += " adolescent.";
if (âge>=18 && âge<60) message += " adulte.";
if (âge>=60) message += "e personne du troisième âge.";
out.println("<p>"+ message +"</b></body></html>");
}
//Traiter la requête HTTP post
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
Les JavaServer Pages, ou JSP, servent, comme les servlets, à créer du contenu Web de manière dynamique. Ces deux types de composants représentent à eux seuls un très fort pourcentage du contenu des applications Web.
Créer des servlets consiste à construire des composants Java capables de produire du code HTML. Dans de nombreux cas, cela fonctionne sans problème. Toutefois, il n'est pas facile, pour les personnes chargées de concevoir l'aspect visuel des pages Web, de manipuler du code Java, auquel elles n'ont probablement pas été formées. C'est la raison d'être des JavaServer Pages. Les JSP sont des documents de type texte, contenant du code HTML ainsi que des scriptlets (et/ou des expressions), c'est-à-dire des morceaux de code Java.
Les développeur des pages JSP peuvent mélanger du contenu statique et du contenu dynamique. Ces pages étant basées sur du code HTML ou XML, elles peuvent être créées et manipulées par du personnel non technique. Un développeur Java peut être en charge de la création des scriptlets (et/ou des expressions) qui s'interfaceront avec les sources de données ou effectueront des calculs permettant la génération de code dynamique.

Les pages JSP s'exécutent, en fait, sous la forme de servlets. Elle sont donc compilées comme les servlets et sont donc plus rapides dans leur traitement. Elles disposent du même support pour la gestion des sessions. Elles peuvent également charger des JavaBeans et appeler leurs méthodes, accéder à des sources de données se trouvant sur des serveurs distants, ou effectuer des calculs complexes.
Généralement, lorsque parlons de Java EE, nous pensons immédiatement au EJB. Les EJB représentent à un niveau beaucoup plus sophistiqué, aux objets distants que nous avons déjà mis en oeuvre lors de l'études des RMI. Faisons un petit retour sur les RMI.
RMI (Remote Method Invocation) correspond au modèle d'invocation à distance mis en oeuvre par Java. Grâce à RMI, Java permet l'accès via un réseau aux objets se trouvant sur un ordinateur distant.
Pour créer un objet avec RMI :
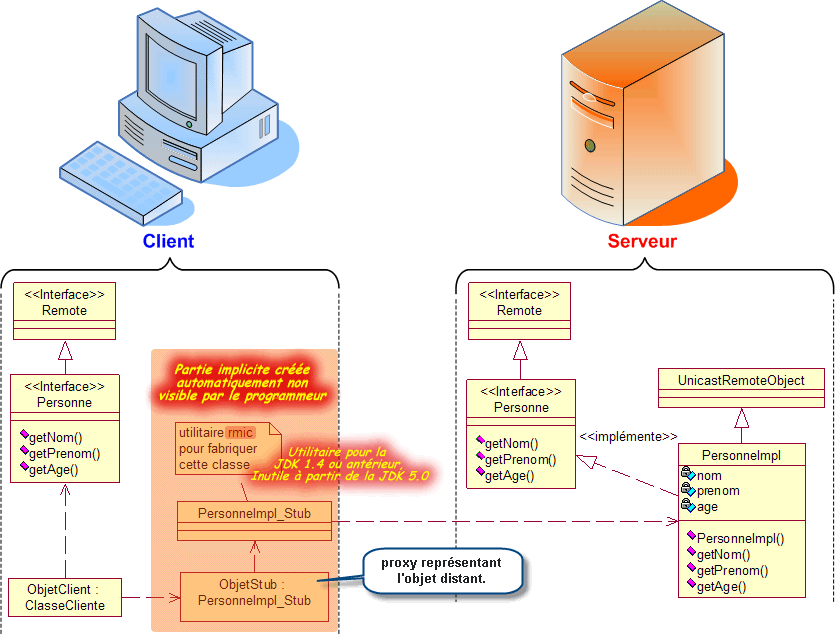
Ce que fournie les bases de l'implémentation d'une architecture client / serveur :
Toutefois, RMI est une technologie légère, insuffisante pour satisfaire les besoins des applications d'entreprises distribuées. Il lui manque les éléments essentiels que sont une gestion avancée de la sécurité, le contrôle des transactions ou la faculté de répondre efficacement à une montée en charge. Bien qu'elle fournisse les classes fondamentales, elles ne constitue pas une infracstructure pour un serveur d'applications devant recevoir les composants métier et s'adapter à l'évolution du système et de sa charge. Il reste notamment nécessaire d'écrire les applications serveur et client.
C'est là qu'intervient les Entreprise JavaBeans. Les EJB sont des composants Java qui implémentent la logique métier de l'application, ce qui permet à cette logique d'être décomposée en éléments indépendants de la partie de l'application qui les utilise.
L'architecture Java EE comporte un serveur qui sert de conteneur pour les EJB. Ce conteneur charge tous les composants à la demande et invoque les opérations qu'ils exposent, en appliquant les règles de sécurité et en contrôlant les transactions. Cette architecture est très complexe mais heureusement totalement transparente au développeur. Le conteneur d'EJB fournit automatiquement toutes la plomberie et le câblage nécessaire pour la réalisation d'applications d'entreprise.
La création des EJB ressemble beaucoup à celle des objets RMI. Cependant, le conteneur fournissant des fonctionnalités supplémentaires, vous pouvez passer plus de temps à créer l'application au lieu d'avoir à gérer des problèmes d'intendance tels que la sécurité ou les transactions.
Il existe plusieurs types d'EJB :
Dans les exemples que nous avons mis en oeuvre dans tout le chapitre sur la programmation réseau notamment au niveau des servlets, le modèle architectural utilisé était le modèle 1. Dans ce type d'architecture, les requêtes HTTP sont gérées par des composants Web, qui reçoivent ces requêtes, créent les réponses et les retournent aux clients. Un seul composant (la servlet) est donc responsable de la logique d'affichage, de la logique métier et de la manipulation des requêtes.
Il existe une autre architecture, appelée Modèle 2, qui partage les responsabilités. Ce modèle est appelé Modèle - Vue - Contrôleur ou MVC. Dans cette architecture, trois composants permettent de séparer clairement les trois activités.
Dans l'architecture Modèle 1, la logique métier, la logique d'affichage et la manipulation des requêtes sont mélangés dans un même composant. Cette architecture conduit à placer du code Java dans des JSP ou du code HTML dans les servlets. Lorsqu'il s'agit d'une petite application, cela ne pose pas de problème, et le sujet est correctement traité. Mais imaginez une application réelle avec des pages Web très sophistiquées et un traitement complexe des données. Une telle application est d'une maintenance très délicate.
Dans le Modèle 2 ou Modèle MVC, un composant est chargé de recevoir les requêtes, un autre de traiter les données et un troisième de préparer l'affichage. Si les interfaces entre ces trois composants sont clairement définies, il devient facile d'en modifier un sans toucher aux deux autres. Dans ce contexte, il est d'ailleurs possible de prévoir plusieurs affichages, un pour un PC par exemple, et un autre pour un PDA.
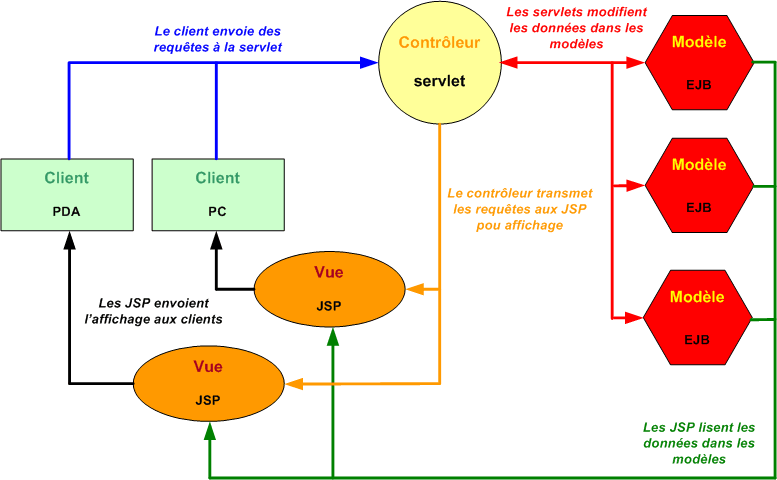
Les composants d'une application MVC sont donc réparti en trois catégories : le modèle, la vue, le contrôleur.
Le Web est de plus en plus le support privilégié des applications d'entreprise. Les services Web constituent le développement ultime dans ce domaine. Un service Web est un système logiciel identifié par une URI, dont l'interface publique et les liens sont définis à l'aide d'XML. Ce système peut être découvert ou localisé par d'autres systèmes logiciels. Ces systèmes peuvent interagir avec le service d'une manière prescrite par sa définition, en utilisant des messages XML transmis à l'aide des protocoles d'Internet.
La norme impose les contraintes suivantes :
Le W3C a établi WSDL (Web Service Description Language - Langage de description des services Web) comme le format utilisé pour la description des services et la façon d'y accéder. Pour appeler un service, un client doit être capable d'obtenir sa description. Les registres XML fournissent le moyen de publier les descriptions des services, d'effectuer les recherches et d'obtenir les informations WSDL les concernant.
Il existe plusieurs services de registre XML dont UDDI (Universal Description, Discovery and Integration - Description, découverte et intégration universelle). JARX fourni une API permettant d'accéder à ces registres de manière indépendante de leur implémentation.
SOAP (Simple Object Access Protocol - Protocole simple d'accès aux objets) est l'esperando des services Web et de leurs clients, utilisés pour l'invocation et le passage des paramètres et des valeurs de retour. SOAP définit les messages XML standards et le mode de conversion des données permettant à un client d'appeler un service et de lui passer des paramètres. Grâce à l'API JAX-RPC, il est possible de développer une interface simple sans se préoccuper de la technique sous-jacente.
Bien entendu, Java EE fournit un conteneur pour les services Web et un modèle de composants permettant de les déployer facilement.