Descripteur de déploiement
Descripteur de déploiement
 Lorsque nous avons étudiés les servlets, nous avons déjà rencontrés et utilisés les descripteurs de déploiement. Dans ce chapitre, nous allons découvrir un peu plus en détail toutes les subtilités de ce fichier particulier.
Lorsque nous avons étudiés les servlets, nous avons déjà rencontrés et utilisés les descripteurs de déploiement. Dans ce chapitre, nous allons découvrir un peu plus en détail toutes les subtilités de ce fichier particulier.
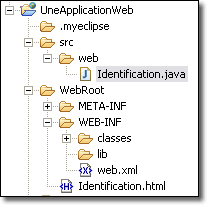
Les descripteurs de déploiement sont fichiers XML contenant toutes les informations de configuration relatifs à une application Web. Pour chaque application Web, le descripteur de déploiement s'appelle <web.xml>. Par ailleurs, une application Web doit respecter une structure particuliere. Avant de rentrer dans le vif du sujet concernant le descripteur de déploiement, il me paraît primordial de connaître ce qu'est une application Web.
Une application Web doit répondre à un certain nombre d'attente de la part du client. Elle est généralement composée d'un certain nombres d'éléments en interaction entre eux. Une application Web peut être relativement conséquente et être composée de beaucoup d' éléments. Elle peut posséder :
Cette complexité ne doit pas du tout apparaître pour le client. L'utilisation de l'application Web doit au contraire être la plus conviviale possible et sa structure totalement transparente. En fait, pour l'utilisateur, il doit juste proposer le nom de l'application Web, dans l'URL, à la suite du nom du site.
http://NomDuSite/ApplicationWeb comme par exemple http://localhost:8080/FormulairePersonne
Pour que cela soit aussi simple pour l'utilisateur, il est nécessaire d'avoir une architecture particulière, prédéfinie, qui sera la même pour toutes les applications Web de type Java.
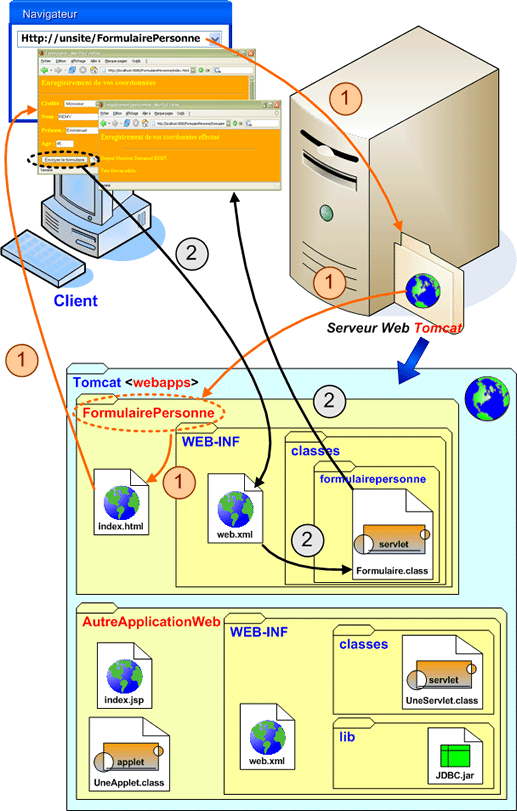 Une application web est donc visible par son nom d'appel dans l'URL lors de l'exécution d'un script. Elle correspond de façon cachée à une arborescence particulière des fichiers sur le disque dur. Cette arborescence possède une structure préétablie que nous devons respecter.
Une application web est donc visible par son nom d'appel dans l'URL lors de l'exécution d'un script. Elle correspond de façon cachée à une arborescence particulière des fichiers sur le disque dur. Cette arborescence possède une structure préétablie que nous devons respecter.
Lorsque l'utilisateur se connecte sur le site, et grâce à cette organisation particulière, le serveur Web (Tomcat par exemple) va systématiquement procéder à la même démarche :
Pour que tout se passe convenablement, il faut donc respecter l'architecture des dossiers, telle qu'elle vous est présentée dans le tableau ci-dessous :
| Dossiers | Type de fichier | ||
| webapp | ressources Web publiques (pages accessibles directement) |
||
| WEB-INF | ressources Web privée (pages non accessibles directement) |
||
| classes | Emplacement des servlets et des JavaBeans : <*.class>. |
||
| tlds | Bibliothèques de balises | ||
| lib | Bibliothèques <*.jar> non standards comme les drivers JBDC. | ||
Le tableau ci-dessus nous montre donc l'architecture à respecter pour mettre en oeuvre une application Web. Normalement, il est préférable qu'elle dispose d'un dossier personnel nommée ici <webapp>.
Ce dossier peut prendre le nom que vous désirez comme FormulairePersonne. Généralement le nom choisi correspond au nom de l'application Web.
.
Votre application Web se situe donc dans le répertoire qui servira au déploiement. Tous les fichiers qui se trouvent dans la racine de ce répertoire constitue la partie publique de l'application, celle qui sera uniquement accessible directement par les clients Web potentiels. Au niveau de la racine, nous devons trouver au moins la page d'accueil, plus quelques pages Web statiques ou dynamiques (JSP) qui ont un intérêt public. Se trouvent également les pages Web avec client "riche", c'est-à-dire celles qui comportent des applets. Les applets doivent donc se situer dans cette partie publique sinon elles ne seraient pas accessibles.
La page d'accueil est généralement, soit :
Il est possible d'utiliser un autre nom de page d'accueil comme <Identification.html>. Il est alors nécessaire de le préciser dans la descripteur de déploiement. Dans l'extrême, nous pouvons donner une liste de pages d'accueil potentielles, mais la plupart du temps, nous indiquons dans ce descripteur juste la page que nous avons décidé de prendre.
Dans l'application Web se trouve systématiquement le répertoire <WEB-INF> qui est un répertoire spécial contenant toutes les informations de déploiement et le code de l'application. Ce répertoire est protégé par le serveur Web, et son contenu est invisible, même si l'on rajoute /WEB-INF/ à L'URL de base. <WEB-INF> est donc la partie privée de l'application Web et ne peut-être accessible que par décision des développeur au travers du descripteur de déploiement contenu dans ce répertoire. Toutefois, vos classes d'application peuvent charger des fichiers complémentaires directement à partir de cette zone, en utilisant la méthode getResource( ), et c'est un endroit sûr pour stocker des ressources d'application.
Le répertoire <WEB-INF> contient le très important fichier <web.xml> qui est justement le descripteur de déploiement.
.
Ces deux répertoires contiennent, respectivement, des fichiers de classes Java et les bibliothèques Jar.
Le répertoire <WEB-INF/classes> est automatiquement rajouté au chemin de classe de l'application Web, et chaque fichier de classes qui y est stockée est donc disponible pour l'application. Nous y retrouvons spécialement les classes des servlets et des Javabeans.
Le répertoire <WEB-INF/lib> est utile pour stocker les bibliothèques nécessaires à l'application Web, mais qui ne font pas partie de JRE standard comme, par exemple, les pilotes JDBC.
Pour chaque application Web, nous avons besoin d'un descripteur de déploiement. Il est unique. Il s'agit d'un fichier XML qui porte le nom de <web.xml>. Nous venons de le voir, ce fichier doit être placé dans le répertoire <WEB-INF> de l'application Web. <web.xml> est un fichier de configuration de l'application Web.
Ce descripteur de déploiement permet de recencer les composants Web (servlets, JSP, EJB) qui font parti de l'application Web. Il permet également de maîtriser la gestion des exceptions en proposant des pages d'erreur (Web) personnalisés suivant le type d'erreur survenu lors d'une mauvaise saisie du client. Il permet également de mettre en place des filtres afin de recencer toutes les requêtes soumises par le client et ainsi de lancer le bon composant Web qui sera adapté à la situation.
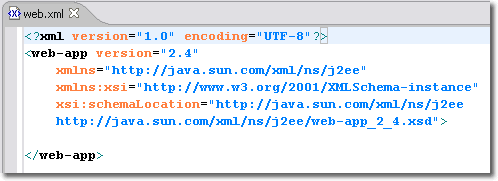
Ce document XML comporte l'élément racine <web-app>. Le descripteur de déploiement étant contenu dans un fichier XML, il doit être conforme à cette spécification. Il doit donc commencer par une déclaration XML suivi d'une déclaration DOCTYPE (jusqu'à la spécification Servlet 2.3) ou par un Schéma XML (à partir de la spécification 2.4).
L'élément racine <web-app> dispose généralement d'un ou plusieurs sous-éléments suivant :
| Elément | Description |
|---|---|
| icon | Le chemin d'accès a une icône qui peut être employée par un outil graphique pour représenter l'application Web. |
| display-name | Un nom qui peut être employé par un outil de gestion d'applications pour représenter l'application Web. |
| description | Une description de l'application. |
| distributable | Indique si l'application peut être distribuée entre plusieurs serveurs. La valeur par défaut est false. |
| context-param | Contient les valeurs des paramètres valables pour toute l'application Web. |
| filter | Définit une classe de filtre qui sera aplliquée avant la servlet. |
| filter-mapping | Définit un alias pour un filtre. |
| listener | Définit une classe de listener qui sera appelée par le conteneur à la survenue d'un événement particulier. |
| servlet | Définit une servlet par son nom et sa classe. |
| servlet-mapping | Définit un alias pour une servlet. |
| session-config | Définit un délai maximal d'inactivité pour les sessions. |
| mime-mapping | Définit une association entre les fichiers publics de l'application et des types MIME. |
| welcome-file-list | Définit la ressource à retourner par défaut au client si aucune ressource n'est spécifiée. |
| error-page | Définit la page d'erreur à retourner si aucune erreur particulière se produit. |
| taglib | Définit l'emplacement des bibliothèques de balises. |
| resource-env-ref | Configure une ressource externe qui peut être utilisée par la servlet. |
| resource-ref | Configure une ressource externe qui peut être utilisée par la servlet. |
| security-constraint | Décrit les rôles des utilisateurs pouvant accéder à l'application Web. |
| login-config | Configure la méthode d'authentification. |
| security-role | Définit un rôle de sécurité pour l'application. |
| env-entry | Définit le nom d'une ressource accessible grâce à l'interface JNDI. |
| ejb-ref | Définit une référence distante à un Entreprise JavaBean (EJB). |
| ejb-local-ref | Définit une référence locale à un EJB. |
Nous ne ferons pas une étude exhaustive. Dans la suite, nous allons décrire un certain nombre de balises que vous serez succeptible de rencontrer ou d'utiliser. Nos premiers descripteurs de déploiement seront exploités à partir d'exemples simples. Nous commencerons par un exemple que nous étofferons au fur et à mesure.
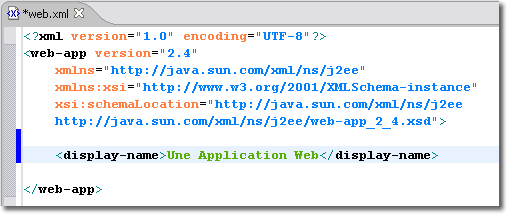
Cette balise représente tout simplement un nom qui peut être employé par un outil de gestion d'applications (comme le Gestionnaire d'applications WEB Tomcat) pour représenter l'application Web. Elle n'a pas une grande importance, mais cela peut être sympathique d'avoir une visualisation sommaire de ce que réalise notre Application Web.
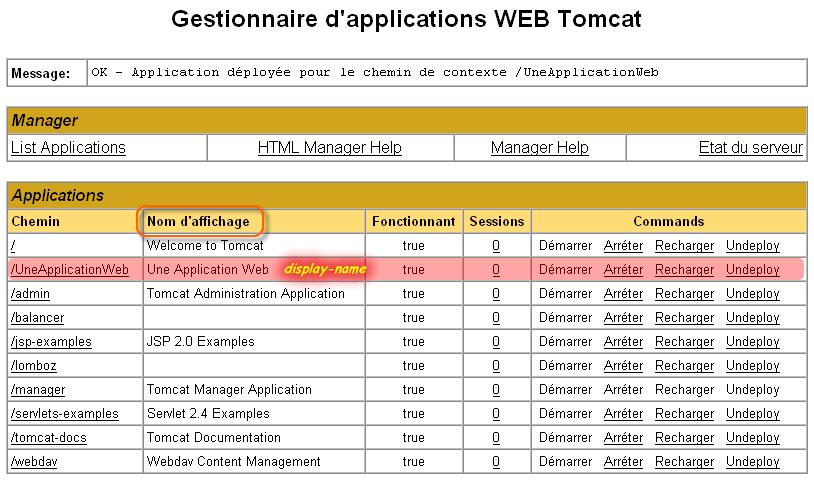
Cette balise permet de définir le document à retourner par défaut au client si aucune ressource n'est spécifiée. Afin d'illustrer l'intérêt de cette balise, nous allons prendre l'exemple de la page d'accueil ci-dessous située dans la partie publique de notre application Web.
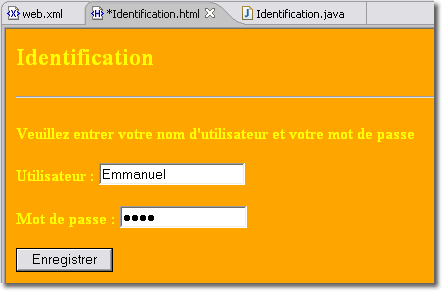
Pour accéder à cette page, le client Web, sur son URL, doit obligatoirement désigner en plus du nom du site et de l'application Web, le nom de la page Web à afficher. Ainsi, en effectuant le test sur l'ordinateur où se situe le serveur Web, nous devrions écrire :
http://localhost:8080/UneApplicationWeb/Identification.html
Cela impose que le client connaisse le nom de la page Web à afficher et doit en plus écrire une URL relativement longue. Il serait préférable que le client spécifie uniquement le nom de l'application Web sans qu'il se tracasse du nom de la page d'accueil qui est derrière. C'est au serveur Web à s'occuper de trouver la bonne page à afficher automatiquement.
La première solution consiste, et nous en avons souvent parler, de prendre comme nom de page d'accueil <index.html>. Seulement, il peut aussi être intéressant de conserver le nom de la page que nous avons choisi puisque ce nom est relativement évocateur.
C'est là qu'intervient le descripteur de déploiement. En effet, la balise <welcome-file-list> permet justement de spécifier l'ensemble des documents à ouvrir automatiquement lorsque le client se contente de spécifier uniquement le nom de l'application Web dans son URL.
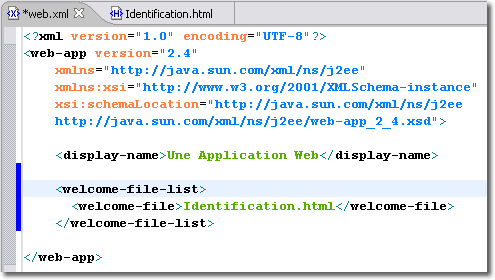
Lorsque le client devrait écrire uniquement ceci :
http://localhost:8080/UneApplicationWeb
Le serveur renvoie le premier document trouvé parmi ceux proposés de la liste donnée par la balise <welcome-file-list>. Chaque document est ensuite désigné par la balise <welcome-file>. Nous pouvons effectivement proposer plusieurs documents dans le cas où plusieurs solutions sont envisageables. Toutefois, dans la pratique, un seul document sera souvent suffisant.
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file> <welcome-file>index.jsp</welcome-file> </welcome-file-list>
Dans cet exemple, <welcome-file-list> indique lorsqu'une requête partielle (chemin de répertoire) est reçue, le serveur doit d'abord chercher un fichier appelé <index.html> puis, en cas d'échec, un fichier appelé <index.htm> puis, de nouveau en cas d'échec, un fichier appelé <index.jsp>. Si aucun de ces fichiers n'est trouvé, c'est au serveur de décider quelle page à afficher. En général, les serveurs sont configurés pour afficher une liste organisée comme un répertoire ou pour renvoyer un message d'erreur.
L'élément <servlet> est l'un des plus important du descripteur de déploiement. Il permet de décrire les servlets de l'application Web. L'élément <servlet> indique au conteneur la classe qu'il doit associer au nom de la servlet. Eventuellement, l'élément <servlet-mapping> (qui est souvent en relation avec cet élément <servlet> ) associe une URL à ce nom.
L'élément <servlet> peut posséder les sous-éléments suivant :
Les sous-éléments obligatoires sont <servlet-name> et un des éléments <servlet-class> ou <jsp-file> (Les pages JSP sont automatiquement compilées sous forme de servlets). L'élément <servlet-name> définit un nom qui peut être utilisé pour désigner la ressource. Les éléments <servlet-class> et <jsp-file> définissent les noms qualifiés de la classe de la servlet ou du fichier JSP.
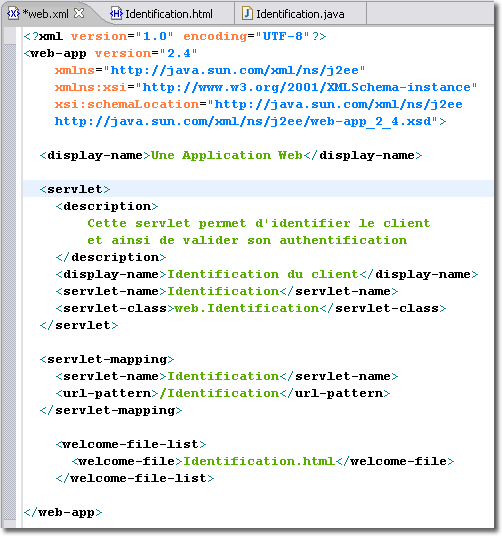
En définissant le nom de la servlet Identification et en utilisant l'élément <servlet-mapping> pour associer une URL /Identification au nom Identification, nous pouvons accéder à la servlet à l'aide de l'URL :
http://localhost:8080/UneApplicationWeb/Identification
Ce n'est pas ici une économie impressionnante, mais si le nom de la classe était web.entreprise.service.subdivision.Identification, il serait agréable de pouvoir y accéder par un nom plus simple.
<servlet> <load-on-start-up>5</load-on-start-up>
... </servlet>
L'élément <load-on-start-up> lorsqu'il est présent, contient un entier positif qui indique qu'il faut charger la servlet au démarrage du serveur. L'ordre de chargement des servlets est déterminé par cette valeur. Les servlets ayant la plus petite valeur sont chargées les premières. En cas de valeurs égales, l'ordre de chargement est arbitraire.
Si l'élément est absent, la servlet est chargée lors de la première requêtes.
.
Une servlet possède une méthode init() qui est sollicité juste après sa création. Cette méthode permet à la servlet de lire les paramètres d'initialisation ou les données de configuration, d'initialiser des ressources externes telles des connexions à une base de données ou d'effectuer diverses autres tâches qui seront accomplies une seule fois juste après la création de la servlet. La classe GenericServlet fournit deux formes de cette méthode :
public void init() throws ServletException
public void init(ServletConfig) throws ServletException
Le descripteur de déploiement peut définir des paramètres qui s'appliquent à la servlet au moyen de l'élément <init-param>. Le conteneur de servlets lit ces paramètres dans le fichier <web.xml> et les stocke sous forme de paires clé/valeur dans l'objet ServletConfig. L'interface Servlet ne définissant que init(ServletConfig), c'est cette méthode que le conteneur doit appeler. GenericServlet implémente cette méthode pour stocker la référence à ServletConfig puis appelle la méthode init( ) sans paramètres.
Aussi pour effectuer l'initialisation, nous avons seulement besoin de redéfinir init( ) sans paramètre. La référence à ServletConfig étant déjà mémorisée, la méthode init( ) a accès à tous les paramètres d'initialisation qui y sont stockées. Pour récupérer ces paramètres, il suffit d'utiliser la méthode getInitParameter(String).
public String GenericServlet.getInitParameter(String nomDuParamètre) ; // retourne la valeur du paramètre
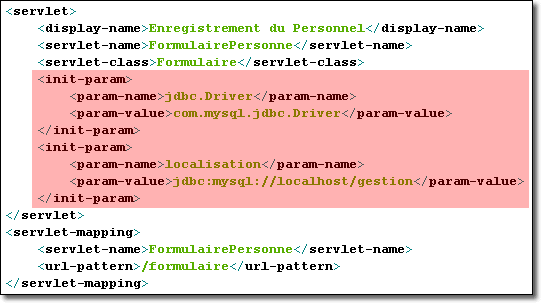
L'intérêt des paramètres d'initialisation est de permettre de changer de configuration sans avoir besoin de recompiler la servlet. Par exemple, vous pouvez placer dans le descripteur de déploiement, le nom du pilote du serveur d'une base de données ainsi que sa localisation. Si plutard, vous devez changer de serveur, il suffit de modifier les valeurs directement dans la balise <init-param> du descripteur de déploiement (changement de texte) sans recompiler la servlet qui a déjà été mis en oeuvre. Ainsi notre servlet fonctionne quelque soit le serveur de base de données.
<init-param> est composé de deux sous-éléments qui correspondent respectivement au nom du paramètre suivi de sa valeur :
Voici un exemple de paramètres initiaux définissant le serveur de base de données MySql définies dans le descripteur de déploiement associés à la servlet FormulairePersonne :
Récupération de ses paramètres initiaux dans la servlet FormulairePersonne :

Pour cet exemple, nous avons utilisé la méthode getInitParameter(String) à l'intérieur de la méthode init(). Il est possible de l'utiliser dans les autres méthodes de la servlet comme doGet() ou doPost(). Cela correspond alors à des paramètres moins spécifiques.
Cet élément est utilisé pour définir des associations entre des URL et des noms de servlets. Dans l'exemple ci-dessous, l'URL /Identification est finalement associée à la classe web.Identification par l'intermédiaire de l'alias proposé : Identification.
Il existe une association par défaut pour toutes les servlets utilisées par Tomcat. Les URL correspondantes au schéma /servlet/* sont en effet transmises à une servlet spéciale nommée invoker. Cette servlet lit les URL et transmet les requêtes aux servlets correspondantes.
<url-pattern>/Identification</url-pattern>
La balise <url-pattern> spécifiée dans l'exemple précédent était une simple chaîne, "/Identification". Pour ce modèle, seule une correspondance finissant exactement par "/Identification" invoquerait la servlet, comme l'URL suivante :
http://localhost:8080/UneApplicationWeb/Identification
La balise <url-pattern> permet d'utiliser des modèles beaucoup plus puissant, incluant même des caractères jokers. Par exemple, spécifier le mappage suivant :
<url-pattern>/Identifi*</url-pattern>
permet à la servlet d'être invoquée par les URL suivantes :
http://localhost:8080/UneApplicationWeb/Identification ou http://localhost:8080/UneApplicationWeb/Identifier
Il est même possible de spécifier des caractères jockers suivis d'extensions, par exemple, <*.html> ou <*.perso>. Dans ce cas, la servlet peut être invoquée par n'importe quel chemin finissant par ces caractères.
En imaginant que votre application Web dispose de plusieurs servlets qui font appel à la même base de données, il peut être génant de placer les mêmes paramètres d'initialisation <init-param> du pilote JDBC pour chacune de ces servlets. En effet, l'élément <init-param> défini dans le descripteur de déploiement, est associé à une servlet en particulier. Il serait préférable d'utiliser plutôt les paramètres d'initialisation de l'application Web, appelé paramètres de contexte <context-param>, qui sont accessibles pour tous les composants Web constituant l'application Web.
<context-param>, comme pour <init-param> est composé de deux sous-éléments qui correspondent respectivement au nom du paramètre suivi de sa valeur :
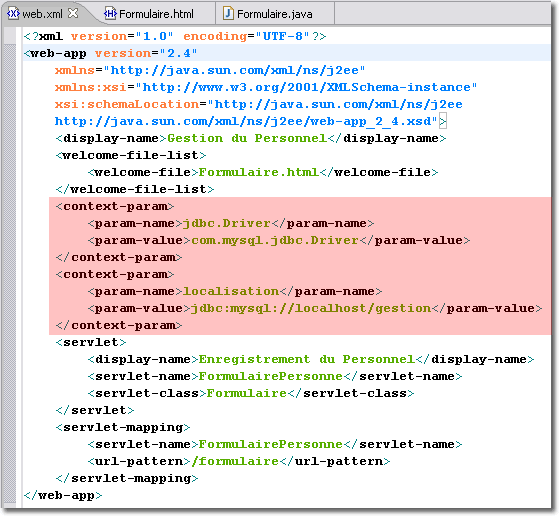
Pour que chacune des servlets récupèrent ces paramètres, il est nécessaire d'abord de solliciter l'objet correspondant au contexte de la servlet (plus précisément, au contexte de l'application Web) à l'aide de la méthode getServletContext(). Cet objet ensuite, peut délivrer les paramètres initiaux de l'application Web grâce à la méthode getInitParameter().

Les exemples de servlets proposés jusqu'à présent consistait au maximum à enregistrer la trace dans un journal. C'est bien pour l'administrateur, ça l'est beaucoup moins pour le client. Reprenons l'exemple précédent avec comme scenario, le serveur de base de données non opérationnel. Voilà ce que reçoit le client lorsqu'il remplit le formulaire et qu'il envoie la requête au serveur :
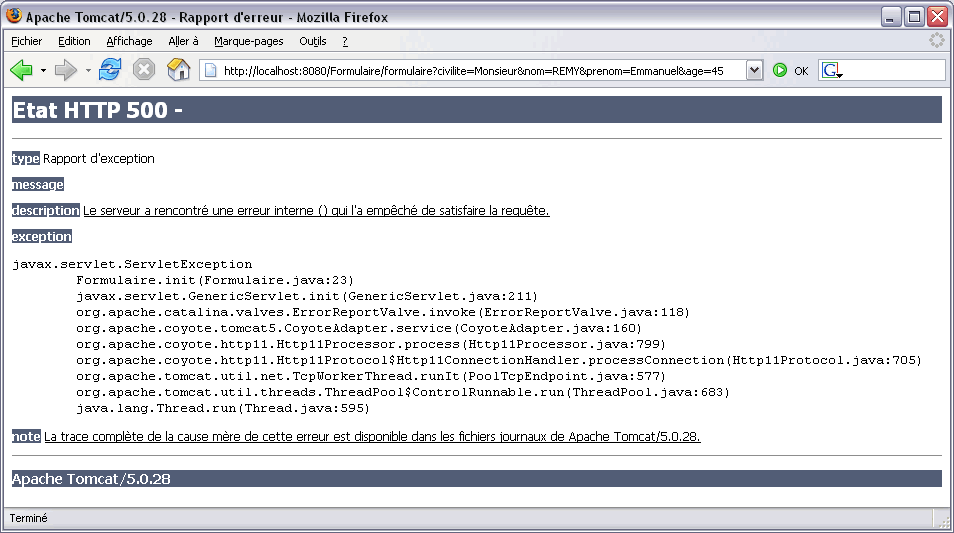
Suivant les serveurs, l'utilisateur voit s'afficher la trace de l'exception ou alors il n'obtient aucune réponse du serveur. Dans tous les cas, l'utilisateur a le sentiment que l'application est défectueuse, ce qui est le cas puisque pour l'instant, il n'y a pas de véritable gestion d'exception.

Autre exemple, que se passe-t-il lorsque l'utilisateur saisie une valeur non numérique dans le champ correspondant à l'âge ? Dans ce cas, le constructeur de la classe Integer lance une exception qui au niveau du client se traduit également par l'affichage de la trace de l'exception.
Cette situation n'est pas acceptable. Nous avertissons le client lorsque l'enregistrement c'est bien déroulé. Nous devons également l'avertir lorsqu'un problème s'est rencontré et lui proposer une solution éventuelle, notamment lors de la mauvaise saisie d'un champ. C'est la moindre des choses. Bref, nous devons gérer l'exception.
Règle de bonne conduite : A moins que l'exception soit une IOException (communication interrompue) survenant lors de l'écriture de la réponse, le client devrait toujours recevoir une réponse intelligible.
La solution au problème que nous venons d'évoquer pourrait être de ne placer un bloc try...catch qu'autour des instructions susceptibles de lancer des exceptions ou d'ajouter des instructions d'affichage dans le bloc catch pour retourner une réponse spécifique en cas d'erreur. C'est effectivement une solution plausible, mais le code de la servlet devient relativement surchargé. Il est préférable de séparer le code du fonctionnement normal de la servlet, avec le code relatif aux problèmes rencontrés, grâce à des pages spécialisées qui s'appellent des pages d'erreur.
Il est possible de définir des pages Web ou des pages JSP qui seront retournées au client suivant le type d'erreur survenu. Ainsi, le client sait toujours à quoi s'en tenir quelque soit le scenario rencontré. Chaque page correspond donc a un type d'erreur. Il faut que le développeur indique quel est la page qui doit être envoyée au client au regard de l'exception lancée. Il le définit, tout simplement, à l'aide du descripteur de déploiement.
Ainsi, lorsqu'un problème survient, le conteneur de servlets activera une page d'erreur d'une part, suivant l'exception qui est lancée, et d'autre part suivant ce que décrit le descripteur de déploiement au regard de cette exception.
Dans le descripteur de déploiement, l'élément qui décrit les pages d'erreur est <error-page>.
Deux scenarii sont possibles. Soit nous indiquons le type d'erreur exacte, soit un code d'erreur délivré par le protocole HTTP (500 par exemple) qui correspond alors à une erreur plus générique. Le conteneur de servlets prend toujours, dans le descripteur de déploiement, en premier la page qui correspond pile à l'erreur. S'il ne la trouve pas, il se rabat alors sur le code d'erreur qui englobe un ensemble d'erreurs potentielles.
Nous avons donc deux écritures possibles dans le descripteur de déploiement qui correspondent au deux scenarii. C'est le choix des sous-éléments de <error-page> qui détermine le scenario choisi. Ainsi nous pouvons avoir les sous-éléments suivants :
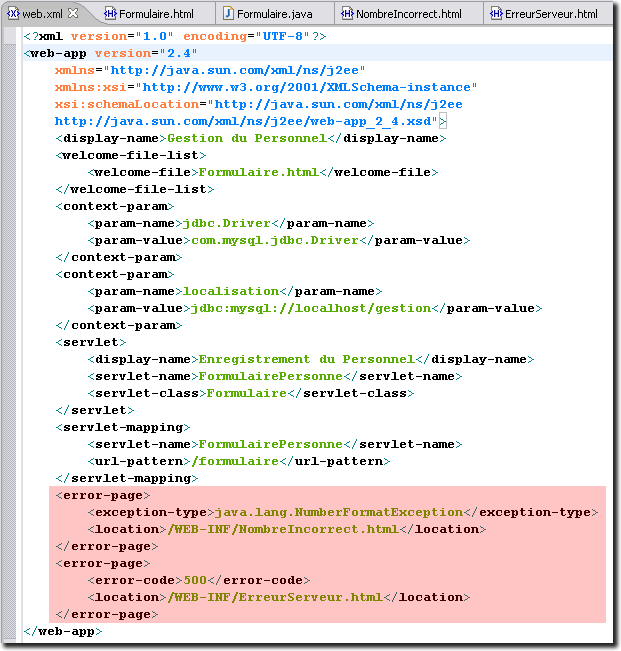
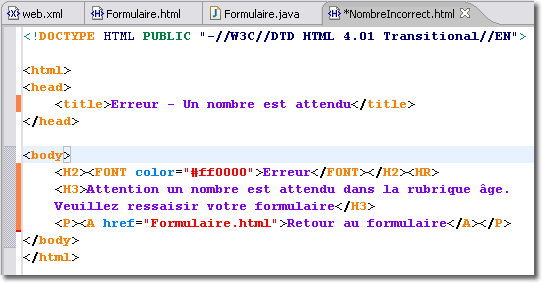
<error-page> <exception-type>java.lang.NumberFormatException</exception-type> <location>/WEB-INF/NombreIncorrect.html</location> </error-page>
ou/et les sous-éléments suivant :
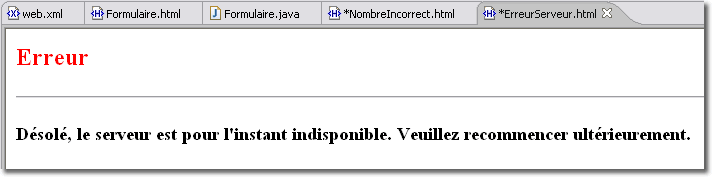
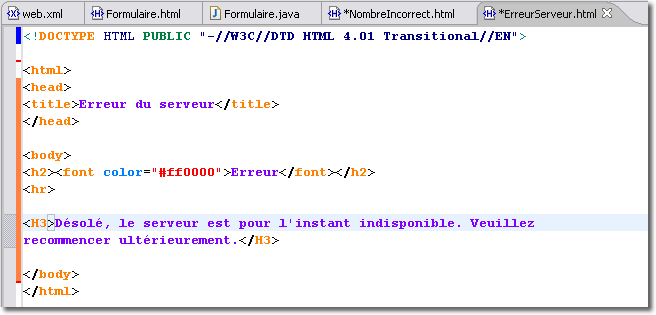
<error-page> <code-type>500</exception-type> <location>/WEB-INF/ErreurServeur.html</location> </error-page>
La première écriture indique que si une erreur de type numérique intervient, c'est la page <NombreIncorrect.html> qui va être envoyée au client. Dans le deuxième cas, c'est l'erreur 500 donnée par le protocole HTTP qui permet d'envoyer au client la page <ErreurServeur.html>.
L'erreur 500 devrait systématiquement être traitée de cette façon. Ce code indique une erreur interne du serveur que celui-ci ne peut traiter. Il peut s'agir d'un problème de compilation d'une JSP ou d'une exception dans une servlet.
En spécifiant une page d'erreur, vous vous assurez que le client recevra une page lisible et correctement mis en forme, plutôt qu'une trace cabalistique.
.
L'élément <location> permet de déterminer quelle est la page qui doit être affichée au client. C'est le serveur qui l'envoie. Ce n'est pas le client qui l'utilise directement. Les pages d'erreur doivent donc être inaccessible de l'extérieur et doivent du coup être placée dans la zone privée de l'application Web, c'est-à-dire dans le répertoire <WEB-INF>.
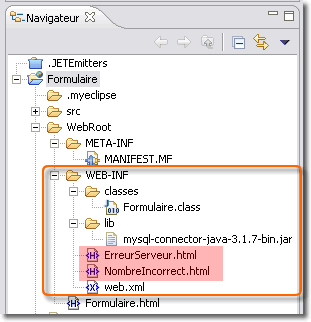

Avec l'API Servlet 2.3, l'une des fonctionnalité les plus puissantes dans une application Web est la possibilité de définir des contraintes de sécurité déclarative. Par sécurité déclarative, on entend le fait qu'il suffit de décrire dans votre fichier web.xml les parties de votre application Web (accès à des documents, répertoires, servlets, etc.) qui sont protégés par mot de passe, le type d'utilisateurs autorisés à y accéder et la classe du protocole de sécurité nécessaire aux communications (crypté ou pas).
Pour implémenter ces procédures de sécurité de base, il n'est pas nécessaire d'ajouter du code à vos servlets.
.
Deux types d'entrées du fichier web.xml contrôlent la sécurité et l'authentification (avec toutefois un troisème pour la définition du rôle) :
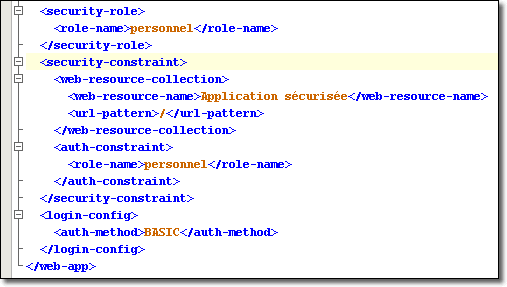
Revenons sur notre application Web Personnel. Je désire que cette application Web ne soit accessible que par login et mot de passe. L'extrait suivant du fichier web.xml définit une zone appelée Application sécurisée, à partir d'un modèle d'URL “/” et précise que seul les utilisateurs possédant le rôle personnel peuvent y accéder.
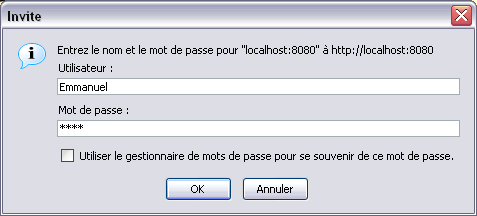
Il utilise la forme la plus simple du processus de connexion : le modèle d'identification BASIC, qui affiche dans le navigateur une simple boîte de dialogue nom d'utilisateur/mot de passe :
Ici, le modèle d'URL est “/”, ce qui signifie que toute l'application Web est sécurisée. Nous pourrions sécuriser qu'une seule partie de l'application Web, par exemple un répertoire de l'application qui ne sera accessible que par mot de passe.
Soit, par exemple, le répertoire secret qui devrait être sécurisé, il faudrait alors préciser le modèle d'URL suivant :
<url-pattern>/secret/</url-pattern>
L'entrée de contrainte de sécurité apparaît donc dans le fichier web.xml après toutes les entrées relatives à la servlet et au filtre. Chaque bloc <security-constraint> contient une section <web-ressource-collection> qui fournit une liste nommée de modèle d'URL d'accès à certaines zones de l'application Web, suivie d'une section <auth-contraint> listant les rôles utilisateur autorisés à accéder à ces zones, au moyen des balises successives <role-name>.
Toutefois, pour que la section <auth-contraint> soit efficace, il est préférable que ces rôles aient été préalablement définies, en dehors de la balise <security-contraint>, au moyen de la balise <security-role> à l'intérieur de laquelle se trouve également une suite de balises <role-name>.
<security-role> <role-name>personnel</role-name> </security-role> <security-constraint> ... <auth-constraint> <role-name>personnel</role-name> </auth-constraint> </security-constraint>
Attention : Avant que cela fonctionne, il reste toutefois une étape à franchir : créer le rôle utilisateur "personnel", ainsi qu'un véritable utilisateur "Emmanuel" possédant ce rôle dans votre serveur d'application.
Dans le serveur Tomcat, il est facile d'ajouter des utilisateurs et d'attribuer des rôles ; il suffit d'éditer le fichier conf/tomcat-users.xml. En voici un exemple ci-dessous avec l'ajout d'un seul utilisateur (N'oubliez pas de fabriquer le rôle).
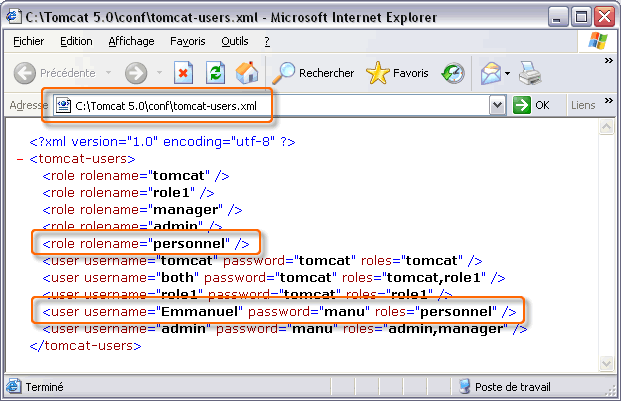
Le droit d'accès à des zones protégées est accordé à des rôles d'utilisateur et non pas à des utilisateurs individuels. Un rôle utilisateur représente en fait un groupe d'utilisateurs. Au lien d'allouer les droits à chaque utilisateur, par nom, on les alloue à des rôles, les utilisateurs se voyant attribuer un ou plusieurs rôles. C'est le cas notamment ci-dessus avec l'utilisateur admin qui peut aussi bien jouer le rôle de gestionnaire d'application Web (manager) que le rôle d'administrateur (admin) du serveur web Tomcat.
Lorsqu'un utilisateur essaie d'accéder à une zone protégée par mot de passe, le login est testé afin de vérifier s'il possède le rôle adéquat.
.
Pour que votre application Web soit parfaitement sécurisée, il faudrait également protéger les informations qui transitent sur le réseau. Il nous faut donc aborder un élément supplémentaire de la contrainte de sécurité : la garantie de transport. Chaque bloc <security-contraint> peut finir par une entrée <user-data-contraint>, qui indique lequel des trois niveaux de sécurité de transport est retenu pour le protocole utilisé lors du transfert de données de et vers la zone protégées.

Les trois niveaux de sécurité sont :
La section <login-config> détermine exactement comment un utilisateur s'authentifie à l'entrée de la zone protégée. La balise <auth-method> permet d'utiliser quatre types d'authentification :
La méthode FORM est la plus utilisée car elle permet de personnaliser la pagede connexion (nous vous recommandons l'usage de SSL afin de sécuriser le stream de données. Il est également possible de spécifier une page d'erreur en cas d'échec de l'authentification.

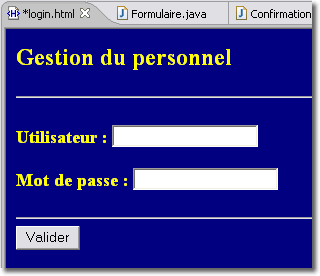
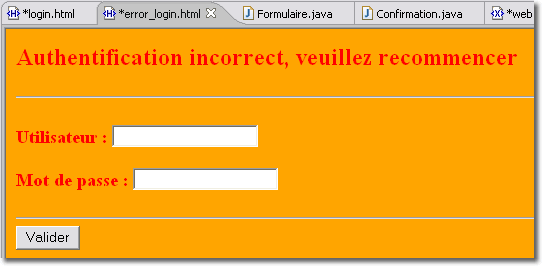
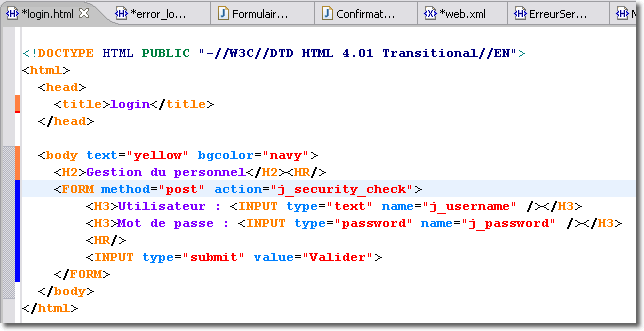
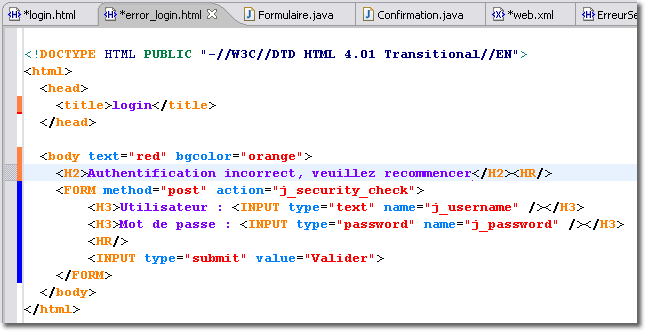
La servlet "Formulaire.java" que nous avons mis en oeuvre est relativement sophistiquée puisqu'elle intègre le stockage des informations, saisie par l'opérateur, dans la base de données. Cette servlet intègre également la journalisation des requêtes dans un fichier journal mémorisant toutes les tentatives d'accès. Pour cette journalisation, nous avons dû modifier la servlet en ce sens, la recompiler et la redéployer. C'est alors que l'on (votre patron, ou votre client) va vous demander de modifier l'application pour que le journal soit enregistré dans une base de données. Il vous faudra modifier de nouveau la servlet, la compiler, la déployer... C'est alors que l'on va vous demander ...
Bientôt, votre servlet sera remplie de code utile mais pas exactement en rapport avec sa fonction initiale : recevoir les requêtes et répondre aux clients. Nous avons besoin d'une solution plus efficace.
Les filtres sont un moyen permettant de donner à une application une structure modulaire. Ils permettent d'encapsuler différentes tâches annexes qui peuvent être indispensables pour traiter les requêtes. Ainsi, dans notre exemple, nous pouvons créer un filtre prévu uniquement pour la journalisation des événements, alors que la servlet principale s'occupe du traitement de la requête proprement dite. Grâce à cette modularité, il devient facile de modifier le comportement de l'application Web en modifiant uniquement son descripteur de déploiement.
La fonction principale d'une servlet consiste uniquement à recevoir des requêtes et répondre aux clients. Toute autre activité annexe est du ressort d'une autre classe. Aussi, lorsque que vous avez à implémenter une fonction particuliere, vous pouvez tirer profit des filtres et de la façon dont ils permettent d'encapsuler ces traitements spécifiques. Par ailleurs, leur modularité leur permet d'être utilisés avec plusieurs servlets différentes, ce qui facilite la maintenance en évitant la duplication du code.
Les filtres sont chaînés, ce qui signifie que lorsque nous appliquons plus d'un filtre, la requête du serveur est passée à travers chacun d'eux de manière séquentielle, chacun ayant l'opportunité d'agir dessus ou de la modifier (notion de filtre) avant de passer au prochain. De manière similaire, à l'exécution, le résultat de la servlet est repassée à travers la chaîne en sens inverse. Il est donc possible au travers des filtres de modifier également la réponse de la servlet, même si le cas le plus fréquent consiste plutôt à faire des traitements au niveau de la requête. L'ordre des filtres de la chaîne est spécifié dans le descripteur de déploiement.
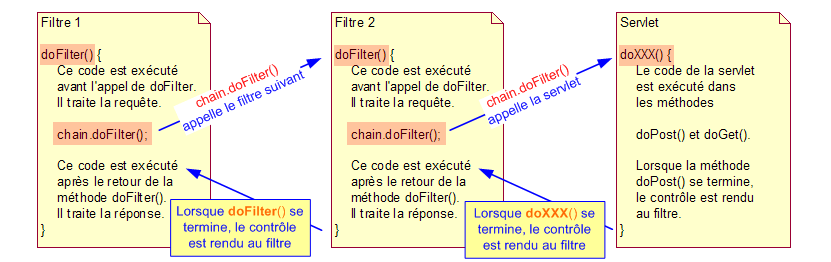
Lorsque la méthode doFilter() d'un filtre est appelée, un des arguments passés est une référence à un objet de type FilterChain. Lorsque le filtre appelle chain.doFilter(), le filtre suivant la chaîne est exécuté. Le code placé avant chain.doFilter() est exécuté avant le traitement de la servlet (ou d'un autre filtre). Toute modification que le filtre doit apporter à la requête doit donc être effectué avant cet appel. Le code placé après cet appel est exécuté après le traitement de la servlet. C'est donc là que doivent être effectuées toutes les modifications à apporter à la réponse. Si le filtre doit agir sur la requête et sur la réponse, il contiendra donc du code avant et après l'invocation de la méthode chain.doFilter().
Par ailleurs, si l'un des filtres doit interrompre le traitement (par exemple en cas d'échec de l'authentification d'un client implémenté dans le prmier filtre), il peut le faire simplement en n'appelant pas la méthode doFilter().
Les filtres de servlet peuvent opérer sur tout type de requêtes d'une application Web, pas seulement sur celles gérées par des servlets. Ils peuvent également être appliqués à du contenu statique. Finalement ils peuvent être utilisés pour tous les composants Web : Servlet, JSP, EJB et HTML.
Pour créer un filtre pour notre application Web, nous devons accomplir deux tâches. La première consiste à écrire une classe implémentant l'interface Filter, la seconde à modifier le descripteur de déploiement de l'application pour indiquer au conteneur qu'il doit utiliser le filtre.
L'API Filter comporte trois interfaces : Filter, FilterChain, et FilterConfig. javax.servlet.Filter est l'interface implémntée par les filtres. Elle déclare trois méthodes :
Vous pouvez constater que cette interface ressemble beaucoup à l'interface Servlet. Vous ne serez donc sûrement pas surpris d'apprendre que le cycle de vie des filtres ressemble également beaucoup à celui des servlets :
L'interface javax.servlet.FilterChain représente une chaîne de filtres. Elle déclare une méthode que chaque filtre peut invoquer pour appeler le filtre suivant dans la chaîne :
void doFilter(ServletRequest request, ServletResponse response) : Cette méthode entraine l'appel du filtre suivant dans la chaîne. Si le filtre appelant est le dernier de la chaîne, la ressource cible de la requête est appelée (par exemple une servlet).
Lorsque la méthode doFilter() d'un filtre est appelée, un des arguments passés est une référence à un objet de type FilterChain. Lorsque le filtre appelle chain.doFilter(), le filtre suivant la chaîne est exécuté.
Le descripteur de déploiement est utilisé pour indiquer au conteneur le ou les filtres qu'il doit appeler pour chaque servlet de l'application. Deux éléments sont utilisés pour décrire les filtres et indiquer à quelles servlets, ils doivent être appliqués.
Le premier est <filter>. Voici un exemple de <filter> contenant tous les sous-éléments possibles :
<filter> <icon>Chemin d'accès à une icône</icon> <filter-name>Le nom du filtre pour l'application Web</filter-name> <display-name>Le nom utilisé par le gestionnaire d'application Web</display-name> <description>Une description de l'application</description> <filter-class>Le nom qualifié de la classe filtre</filter-class> <init-param> <param-name>nom du paramètre</param-name> <param-value>valeur du paramètre</param-value> </init-param> </filter>
Seuls les sous-éléments <filter-name> et <filter-class> sont requis. Si un élément <init-param> est employé, les sous-éléments <param-name> et <param-value> doivent être présents. Ces paramètres sont accessibles grâce à l'interface FilterConfig.
Le second élément est filter-mapping. Il peut prendre une des deux formes suivantes :
<filter-mapping> <filter-name>Même nom que pour l'élément filter</filter-name> <url-pattern>Schéma d'URL auquel le filtre doit être appliqué</url-pattern> </filter-mapping>
ou
<filter-mapping> <filter-name>Même nom que pour l'élément filter</filter-name> <servlet-name>Nom de la servlet auquel le filtre doit être appliqué</servlet-name> </filter-mapping>
N'oubliez pas que l'ordre des éléments dans le descripteur de déploiement est important. Les éléments <filter> doivent être placés avant les éléments <filter-mapping> qui doivent se trouver avant les éléments <servlet>.
Si plusieurs filtres sont nécessaires, ils doivent être présentés par des éléments <filter-mapping> séparés. Les filtres sont appliqués dans l'ordre du descripteur de déploiment.
<filter-mapping> <filter-name>FiltreB</filter-name> <servlet-name>Formulaire</servlet-name> </filter-mapping> <filter-mapping> <filter-name>FiltreA<filter-name> <servlet-name>Formulaire</servlet-name> </filter-mapping>
Toute requête adressée à la servlet Formulaire est d'abord envoyée à FiltreB, car il est le premier dans le descripteur de déploiement. Lorsque FiltreB invoque la méthode chain.doFilter(), le FiltreA est appelé. Lorsque ce dernier invoque lui-même la méthode chain.doFilter(), la servlet Formulaire est enfin exécutée.
Nous allons reprendre l'application Web précédente, et nous allons modifier son comportement. En effet, souvenez-vous, dans la servlet Formulaire, nous avions placée la journalisation des événements - grâce à la méthode log(). Ce n'est pas du tout le but de cette servlet qui doit s'occuper avant tout de la sauvegarde des informations saisies par l'opérateur dans la base de données.
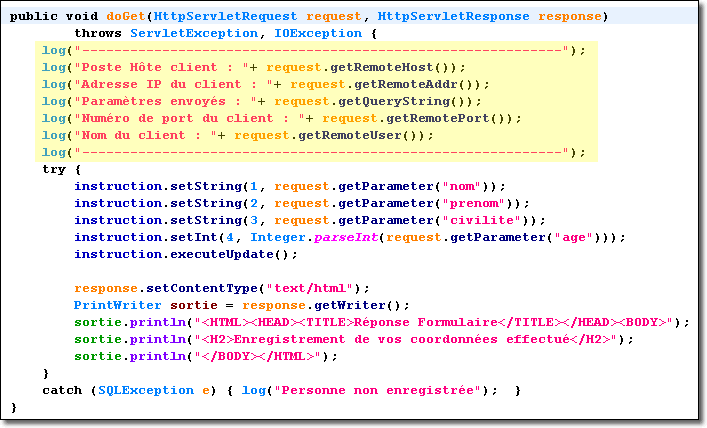
Nous allons donc mettre en oeuvre un filtre qui va s'occuper uniquement de cette journalisation. De plus, nous allons faire en sorte que cette journalisation, donc ce filtre, soit lancée pour tous les composants qui constitue notre application Web. Ainsi, il sera possible de contrôler précisément le parcours de l'opérateur.
L'exemple ci-dessous nous montre le passage de l'opérateur par la page d'accueil "Formulaire.html", la confirmation de sa saisie grâce à la servlet "Confirmation.java" ainsi que l'enregistrement définitif au moyen de la servlet "Formulaire.java".
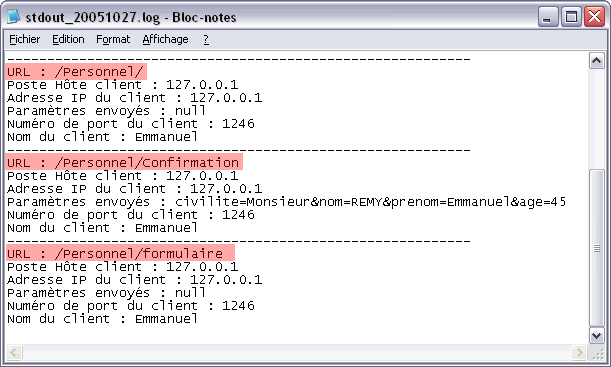
Nous enlevons toutes les commandes log() de la servlet "Formulaire.java" et nous les plaçons dans le filtre "Journal.java" implémenté ci-dessous :
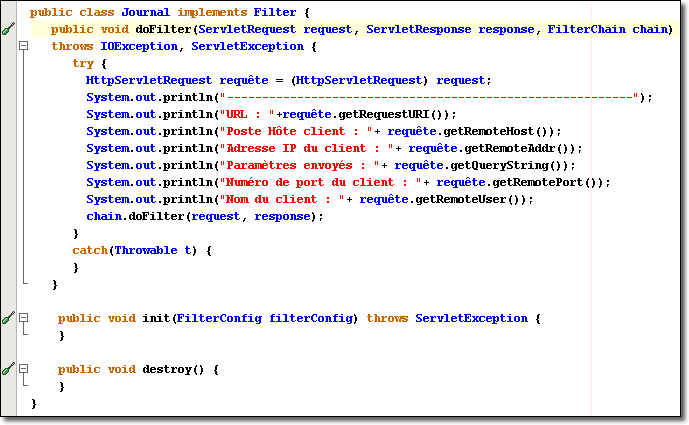
Vous remarquez que les méthodes log() ont été supplantées par les méthodes println() sur la sortie standard. Le journal ainsi créé est représenté alors par le fichier stdout.log, comme vous l'avez vu d'ailleurs sur le journal d'exemple.
Voici ce que devient la servlet "Formulaire.java" sans les méthodes log() :
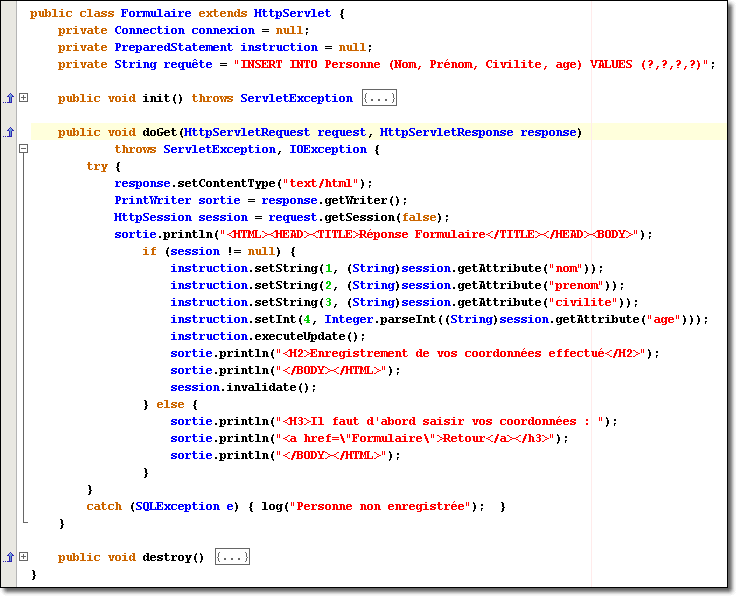
Attention, n'oubliez pas de compléter le descripteur de déploiement pour que ce filtre soit utilisé. Si vous désirez que tous les éléments de l'application Web activent le filtre avant d'être lancés, il suffit de prendre plutôt la balise <url-pattern> dans la mapping de filtre et de placer l'URL suivante : /* (le joker spécifie bien la prise en compte de tous les éléments).
