EJB 3.1 - Bean session
EJB 3.1 - Bean session
 Après avoir longuement travailler sur les applications Web, nous allons passer, à partir de maintenant, sur l'autre grande ossature concernant Java EE, c'est-à-dire les EJB. Je rappelle que EJB veut dire Entreprise Java Bean. C'est ce type de composants qui s'intéressent plus particulièrement à la logique métier au travers d'objets distants. Ces EJB servent d'intermédiaire entre les applications de type fenêtrées, ou application Web, et la base de données.
Après avoir longuement travailler sur les applications Web, nous allons passer, à partir de maintenant, sur l'autre grande ossature concernant Java EE, c'est-à-dire les EJB. Je rappelle que EJB veut dire Entreprise Java Bean. C'est ce type de composants qui s'intéressent plus particulièrement à la logique métier au travers d'objets distants. Ces EJB servent d'intermédiaire entre les applications de type fenêtrées, ou application Web, et la base de données.
Après avoir vu les différents concepts généraux sur les systèmes client-serveur et les architectures multi-tiers, nous passerons ensuite sur l'installation et l'utilisation de serveur d'applications qui intègrent ces EJB. Nous montrerons l'utilisation de ces EJB au travers d'applications classiques, en mode console et en mode graphique, mais aussi au travers des applications Web. Par contre, nous nous limiterons dans cette étude qu'à une partie des EJB, je veux dire les Beans de type session.
Avant de rentrer dans le vif du sujet concernant les Beans de type session, nous allons revoir les principes fondamentaux constituant les applications distribuées.
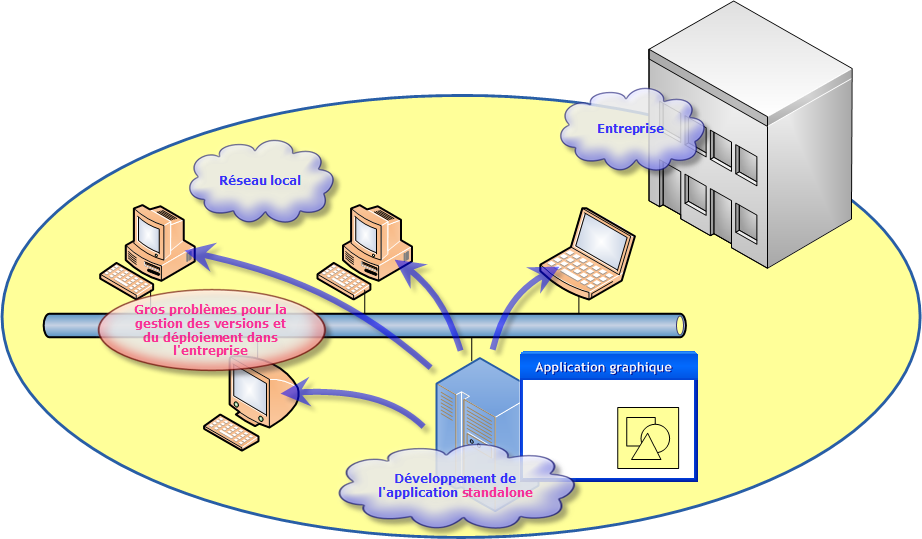
Une application monolitique est un programme constitué d'un seul bloc et s'exécute sur une seule machine. Ces applications sont généralement utilisées dans le domaine du temps réel ou bien au sein d'applications demandant de grandes performances. Ces applications sont utilisées en standalone (de manière autonome) sur des machines personnelles.
L'avantage de cette structure c'est que l'application possède un grand niveau de performance en terme de temps de réponse. Le problème, c'est de pouvoir déployer cette application sur l'ensemble du parc machines de l'entreprise, avec également le souci de la gestion des versions.
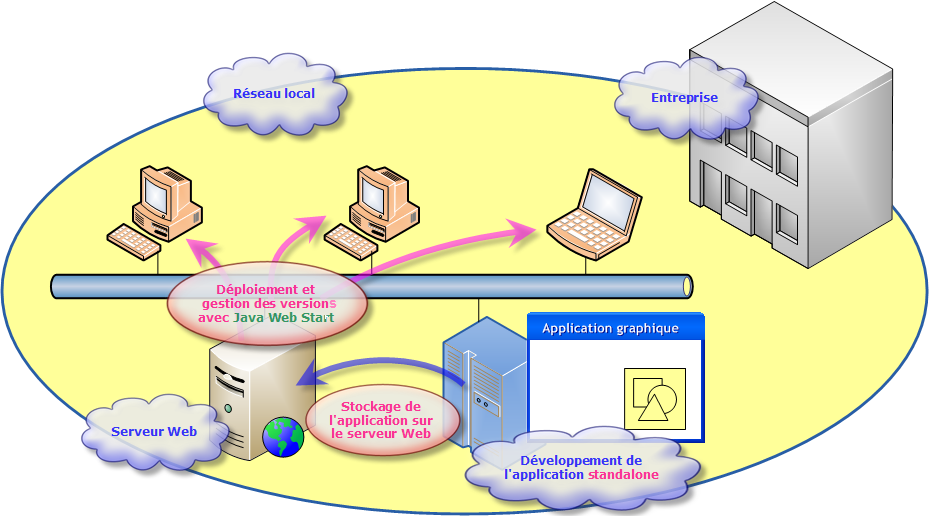
Comme nous l'avons découvert dans une étude antérieure, pour gérer le déploiement, il est possible de passer par Java Web Start au travers d'un serveur Web. Grâce à cette technique, la gestion des versions est totalement assurée.
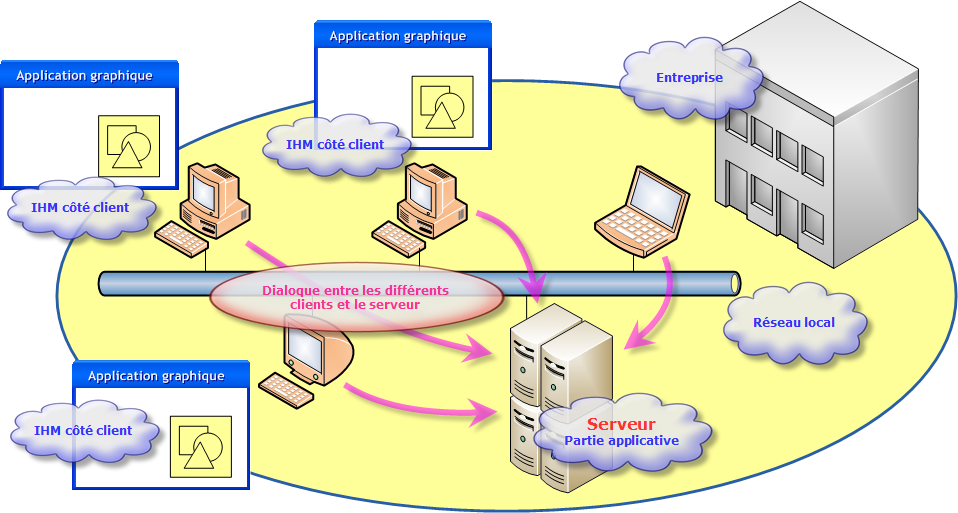
Dès l'apparition des réseaux, ces applications ont cherché à évoluer et ont abouti à des architectures dites client-serveur, permettant de séparer la partie cliente qui s'intéresse plus particulièrement à l'IHM, et de regrouper la partie applicative sur un serveur.
Cependant, le développement de ce genre d'application nécessite la création d'un protocole de communication entre le client et le serveur. Ce protocole étant souvent propriétaire, l'évolution de ces applications doivent se faire par les mêmes développeurs. Par ailleurs, le serveur doit gérer la connexion de plusieurs clients en même temps.
Pour les systèmes d'information d'entreprise, ces solutions restent trop limitées. En effet, leur problème majeur est leur manque de séparation entre les différents éléments qui les constituent. C'est également le manque de standard qui a poussé la communauté au concept de séparation par tiers afin d'optimiser leurs développements.
Dans le milieu professionnel, les applications doivent être plus robustes et travaillent généralement sur des gros volumes de données. Elles doivent, de plus, connecter différents départements au sein même d'une entreprise.
La maintenance et la stabilité de ces applications sont donc des priorités pour les architectes et les développeurs. Différents modèles existent. Le plus connu est sans doute le modèle trois-tiers, largement utilisé par les grandes entreprises ayant besoin de systèmes complexes basés sur la même organisation des informations : la logique métier.
Ce modèle permet donc d'avoir plusieurs applications différentes avec une même logique métier, elles peuvent alors mettre en place facilement des applications distribuées dans un environnement hétérogène.
De manière théorique, une application distribuée est une application découpée en plusieurs unités. Chaque unité peut être placée sur une machine différente, s'exécuter sur un système différent et être écrite dans un langage différent.
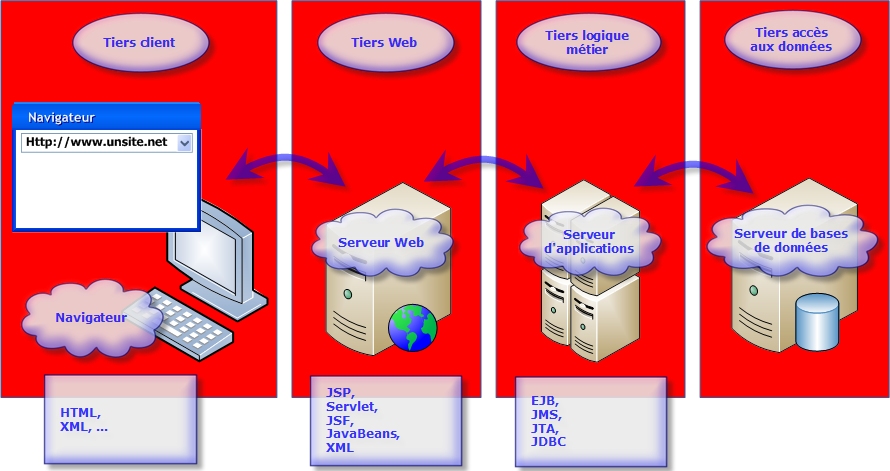
Le modèle trois-tiers : Ce modèle est une évolution du modèle d'application client-serveur. L'architecture trois-tiers est donc divisées en trois niveaux :
> Tiers client qui correspond à la machine sur laquelle l'application cliente est exécutée.
> Tiers métier qui correspond à la machine sur laquelle l'application centrale est exécutée.
> Tiers accès aux données qui correspond à la machine gérant le stockage des données.

Ce système utilise un navigateur pour représenter l'application sur la machine cliente, un serveur Web pour la gestion de la logique de l'application et un serveur de bases de données pour le stockage des données. La communication entre le serveur Web peut s'effectuer via le protocole HTTP, la communication avec la base de données via l'API JDBC.
La séparation entre le client, l'application et le stockage, est le principal atout de ce modèle. Toutefois, dans des architectures qui demandent de nombreuses ressources, il sera assez limité. En effet, aucune séparation n'est faite au sein même de l'application, qui gère aussi bien la logique métier que la logique fonctionnelle ainsi que l'accès aux données.
Le modèle multi-tiers : Dans le cadre d'applications beaucoup plus importantes, l'architecture trois-tiers montre ses limites. L'architecture multi-tiers est simplement une généralisation du modèle précédent qui prend en compte l'évolutivité du système et évite les inconvénients de l'architecture trois-tiers vus précédemment.
Dans la pratique, on travaille généralement
avec un tiers permettant de regrouper la logique métier de l'entreprise. L'avantage de ce système, c'est que ce tiers peut être appelé par différentes applications clientes, et même par des applications classiques, de type fenêtrées, qui ne passent donc pas par le serveur Web. Entre parenthèses, dans ce dernier cas de figure, nous nous retrouvons de nouveau avec une architecture trois-tiers.
Si l'architecture est bien étudiée dès le début et s'exécute sur une plate-forme stable et évolutive, le développeur n'aura alors plus qu'à connecter les différents systèmes entre eux. De même, les types de clients peuvent être plus variés et évoluer sans avoir d'impact sur le coeur du système.
La logique métier est la principale de toute l'application. Elle doit s'occuper aussi bien de l'accès aux différentes données qu'à leurs traitements, suivant les processus définis par l'entreprise. On parle généralement de traitement métier qui regroupe :
- la vérification de la cohésion entre les données,
- l'implémentation de la logique métier de l'entreprise au niveau de l'application.
Il est cependant plus propre de séparer toute la partie accès aux données de la partie traitement de la logique métier. Cela offre plusieurs avantages. Tout d'abord, les développeurs ne se perdent pas entre le code métier (représenté par les EJBs de type session), qui peut parfois être complexe, et le code d'accès aux données (représenté par les entités), plutôt élémentaire mais conséquent. Cela permet aussi d'ajouter un niveau d'abstraction sur l'accès aux données et donc d'être plus modulable en cas de changement de type de stockage. Il est alors plus facile de se répartir les différentes parties au sein d'une équipe de développement.
D'une façon générale, nous pouvons présenter l'architecture globale d'une informatique distribuée sous formes de couches. La couche métier se situe ainsi au-dessus de la couche de persistance avec comme point d'entrée les technologies de la couche présentation : les applications Web au travers de JSF (JavaServer Faces) ou les applications "standalone" plus classiques au travers de Swing.

Le modèle d'architecture distribuée que nous venons de découvrir impose l'idée qu'une application est découpée en plusieurs unités. Des standards ont vu le jour. Le plus général est sans doute CORBA qui correspond au modèle idéal des applications distribuées. Cependant la lourdeur et la complexité de mise en oeuvre de ce genre d'application sont les inconvénients majeurs de cette technologie. C'est pourquoi, un modèle plus restrictif mais plus performant a vu le jour : le modèle EJB.
La communication entre les applications, comme nous l'avons vu dans nos différentes études antérieures, a été introduite par la programmation client-serveur et le principe des sockets. Ce modèle de bas niveau oblige les concepteurs et développeurs à inventer des protocoles pour faire communiquer leurs applications. Avec l'arrivée de le programmation orientée objet, la communauté a souhaité développer des standards et surtout faciliter la communication inter-applications via des modèles de plus haut niveaux par l'intermédiaire de la technique d'objets distants. Ainsi, des objets existent sur différentes machines et communiquent entre eux, c'est ce que nous définissons par objets distribués.
Les objets distribués sont une solution à ce problème d'efficacité. Nous pouvons les considérer simplement comme des objets pouvant communiquer entre eux par le réseau de façon autonome. Il est souhaitable, alors, d'avoir un mécanisme permettant, au développeur d'application cliente, d'effectuer un appel de méthode sur l'objet de façon ordinaire, sans se préoccuper du format de la requête. De la même façon, le développeur de l'application serveur pourra répondre aux applications clientes, sans avoir à s'inquiéter du protocole à mettre en place. Au travers de ce mécanisme, nous utilisons ainsi un objet à distance.
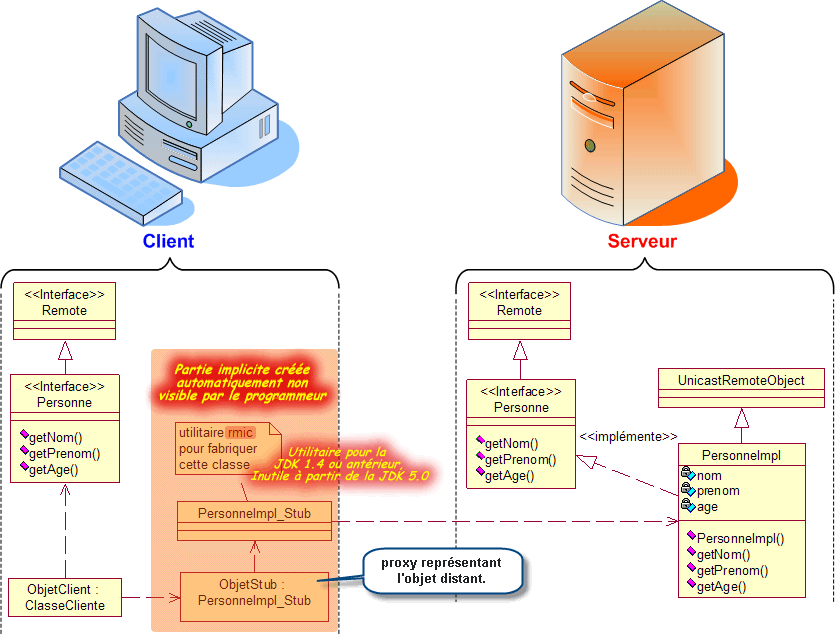
Nous avons déjà abordé cette approche au travers notamment de RMI. Les EJB, toutefois, représentent à un niveau beaucoup plus sophistiqué, les objets distants que nous avons déjà mis en oeuvre lors de l'études des RMI. Faisons quand même un petit rappel sur cette technologie RMI.
RMI (Remote Method Invocation) correspond au modèle d'invocation à distance mis en oeuvre par Java. Grâce à RMI, Java permet l'accès via un réseau aux objets se trouvant sur un ordinateur distant.
Pour créer un objet avec RMI :
Ce que fournit les bases de l'implémentation d'une architecture client - serveur :
Toutefois, RMI est une technologie légère, insuffisante pour satisfaire les besoins des applications d'entreprises distribuées. Il lui manque les éléments essentiels que sont une gestion avancée de la sécurité, le contrôle des transactions ou la faculté de répondre efficacement à une montée en charge. Bien qu'elle fournisse les classes fondamentales, elles ne constitue pas une infracstructure pour un serveur d'applications devant recevoir les composants métier et s'adapter à l'évolution du système et de sa charge.
C'est là qu'intervient les Entreprise JavaBeans. Les EJB sont des composants Java qui implémentent la logique métier de l'application, ce qui permet à cette logique d'être décomposée en éléments indépendants de la partie de l'application qui les utilise.
L'architecture Java EE comporte un serveur qui sert de conteneur pour les EJB. Ce conteneur charge tous les composants à la demande et invoque les opérations qu'ils exposent, en appliquant les règles de sécurité et en contrôlant les transactions. Cette architecture est très complexe mais heureusement totalement transparente au développeur. Le conteneur d'EJB fournit automatiquement toute la plomberie et le câblage nécessaire pour la réalisation d'applications d'entreprise.
La création des EJB ressemble beaucoup à celle des objets RMI. Cependant, le conteneur fournissant des fonctionnalités supplémentaires, vous pouvez passer plus de temps à créer l'application au lieu d'avoir à gérer des problèmes d'intendance tels que la sécurité ou les transactions.
import javax.ejb.Stateless; @Stateless public class Conversion { private final double TAUX = 6.55957; public double euroFranc(double euro) { return euro*TAUX; } public double francEuro(double franc) { return franc/TAUX; } }
Dans l'exemple ci-dessus est créé un EJB Conversion qui réalise la conversion entre les €uros et les Francs. Vous remarquez la mise en oeuvre d'une classe des plus basiques avec une simple annotation @Stateless. Ce composant doit être déployé dans le serveur d'application pour que le conteneur d'EJB le prenne en compte. A partir de là, ce composant reste côté serveur et peut rendre les services requis. Côté client il suffit de faire appel à distance aux méthodes euroFranc() et francEuro() qui délivrerons les calculs désirés.
Un conteneur EJB est un environnement d'exécution qui fournit des services comme la gestion des transactions, le contrôle de la concurrence, la gestion des pools et la sécurité, mais les serveurs d'applications lui ont ajouté d'autres fonctionnalités, comme la mise en cluster, la répartition de la charge et la reprise en cas de panne. Les développeurs d'EJB peuvent désormais se concentrer sur l'implémentation de la logique métier et laisser au conteneur le soin de s'occuper des détails techniques.
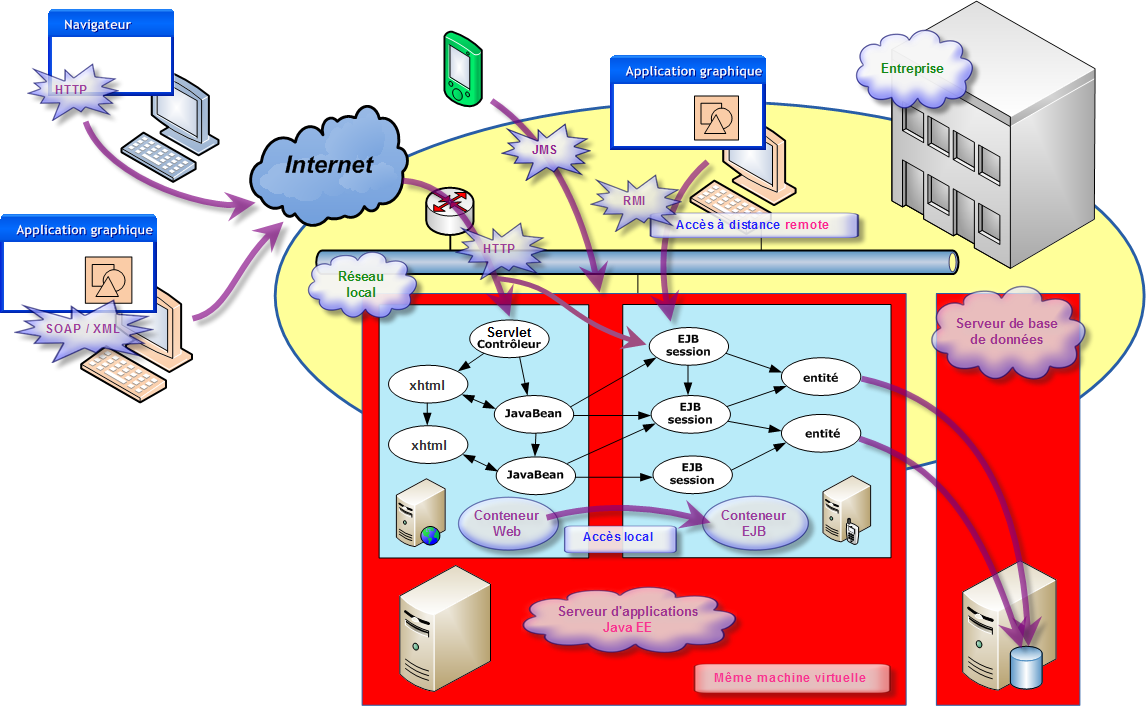
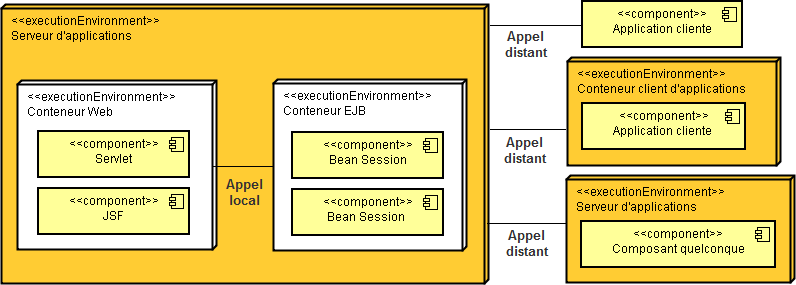
Un serveur d'application met en oeuvre toute les spécifications prévues par Java EE. Nous avons déjà pris connaissance que Java EE permet de fabriquer des applications Web à l'aide de servlet et de pages xHTML, le tout orchestré par la technologie JSF. Par ailleurs, nous découvrons maintenant que Java EE intègre les EJB. En réalité, un serveur d'application possède deux conteneurs, un pour la partie Web et un autre pour les objets distribués. C'est comme si nous avions deux services en un seul. L'avantage ici, c'est que ces deux services font parties de la même machine virtuelle Java. Du coup, il est possible d'utiliser les EJB comme si c'étaient des objets normaux et non comme des objets distants. Dans ce cas là, il faut passer par l'intermédiaire des composants issues de l'application Web. Si vous désirez atteindre les EJB sans passer par l'application Web, c'est que vous utilisez une autre machine virtuelle qui est d'ailleurs issue d'un autre poste sur le réseau local. Dans ce dernier cas, vous faites un accès distant par RMI qui est l'ossature interne des EJB.
Comme nous l'avons mentionné précédemment, un EJB est un composant côté serveur qui doit s'exécuter dans un conteneur. Cet environnement d'exécution fournit les fonctionnalités essentielles, communes à de nombreuses applications d'entreprise :
Lorsque l'EJB est déployé dans le serveur d'applications, le conteneur s'occupe de toutres ces focntionnalités, ce qui permet au développeur de se concentrer sur la logique métier tout en bénéficiant de ces services sans devoir ajouter le moindre code système.
Les EJB sont des objets gérés. Lorsqu'un client distant appelle un EJB, il ne travaille pas directement avec une instance de cet EJB mais avec un proxy de cette instance sur le client (comme nous l'avons découvert au travers de RMI). A chaque fois qu'un client invoque une méthode de l'EJB, cet appel est en réalité pris en charge par le proxy qui lui-même dialogue avec le véritable objet distant avec un protocole propriétaire spécifique. Tout ceci est, bien entendu, transparent pour le client : de sa création à sa destruction, un EJB vit dans un conteneur.
Dasn une application Java EE, le conteneur d'EJB interagira généralement avec d'autres conteneurs :
Le tiers client est représenté par des applications se connectant aux EJB. Ces applications sont généralement écrites en Java, toutefois, il est également possible de se connecter à un EJB avec un client écrit dans un autre langage via un accès par le service web. Nous pouvons également passer par une application Web qui joue le rôle d'intermédiaire et qui utilise en interne les compétences des EJB. Dans ce cas là, un simple navigateur suffit.
Ainsi, la façon d'accéder aux EJB dépend du type de client :
Les principes fondamentaux de l'architecture métier définissent la création de services en tant qu'intermédiaires entre les applications clientes et l'accès aux données. Au sein d'une architecture Java EE, ce sont des EJB qui remplieront cette fonction : les beans sessions. Plus que de simple classes composés de propriétés et de méthodes, ces beans sessions sont de véritables passerelles de services au sein même de l'application, permettant à tout type de client de les interroger.
Un bean session est une application côté serveur permettant de fournir un ou plusieurs services à différentes applications clientes. Un service sert, par exemple, à récupérer la liste des produits d'une boutique, à enregistrer une réservation ou encore à vérifier la validité d'un stock.
Les beans sessions font office de pont entre les clients et les données. Alors que les entités servent à accéder aux données (ajout, modification, suppression, ...), les beans sessions offrent généralement un accès en lecture seule sur celles-ci.
Lorsqu'un bean session est sollicité et qu'il a rendu le service désiré, son instance n'est pas détruite tout de suite pour que le client actuel puisse sollicité une autre méthode du bean ou bien pour qu'un autre client trouve le bean déjà en état de répondre. Comme les traitements sont généralement très courts, un seul bean session peut répondre aux différentes requêtes des clients. Il peut toutefois arriver que plusieurs clients simultanéments fassent appel à ce servive, d'autres instances sont alors proposées pour résoudre ce parallélisme. Après un certain délai de non activité, les instances sont automatiquement détruites par le conteneur d'EJB pour éviter d'avoir trop de ressources non utilisées, en attente inutilement.
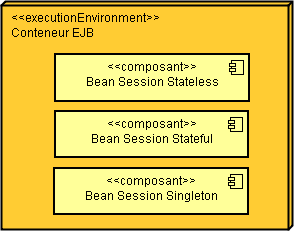 Bien que ces trois types de beans de session aient des fonctionnalités spécifiques, ils en ont aussi beaucoup en commun et, surtout, ils utilisent tous le même modèle de programmation. Comme nous le verrons plus tard, un bean de session peut avoir une interface locale ou distante, ou aucune interface. Les beans de session sont des composants gérés par un conteneur et doivent donc être assemblés dans une archive (un fichier jar, war ou ear) et déployés dans le conteneur. Ce dernier est responsable de la gestion de leur cycle de vie, des transactions, des intercepteurs et de bien d'autres choses encore.
Bien que ces trois types de beans de session aient des fonctionnalités spécifiques, ils en ont aussi beaucoup en commun et, surtout, ils utilisent tous le même modèle de programmation. Comme nous le verrons plus tard, un bean de session peut avoir une interface locale ou distante, ou aucune interface. Les beans de session sont des composants gérés par un conteneur et doivent donc être assemblés dans une archive (un fichier jar, war ou ear) et déployés dans le conteneur. Ce dernier est responsable de la gestion de leur cycle de vie, des transactions, des intercepteurs et de bien d'autres choses encore.
Un bean session Stateless est une collection de services dont chacun est représenté par une méthode. Stateless signifie que le service est autonome dans son exécution et qu'il ne dépend donc pas d'un contexte particulier ou d'un autre service. Le point important réside dans le fait qu'aucun état n'est conservé entre deux invocations de méthodes.
Lorsqu'une application cliente appelle une méthode d'un bean session, celui-ci exécute la méthode et retourne le résultat. L'exécution ne se préoccupe pas de ce qui a pu être fait avant ou ce qui pourra être fait après. Ce type d'exécution est typiquement le même que celui du protocole HTTP (mode déconnecté).
import javax.ejb.Stateless; @Stateless public class Conversion { private final double TAUX = 6.55957; public double euroFranc(double euro) { return euro*TAUX; } public double francEuro(double franc) { return franc/TAUX; } }
Un bean session Stateful est une extension de l'application cliente. Il introduit le concept de session entre le client et le serveur. On parle précisément d'état conversationnel pour qualifier ce type de communication. De ce fait, une méthode appelée sur l'EJB peut lire ou modifier les informations sur l'état conversationnel.
Cet EJB est partagé par toutes les méthodes pour un unique client. Contrairement au type Stateless, les bean sessions Stateful tendent à être spécifique à l'application. Le caddie virtuel est l'exemple le plus commun pour illustrer l'utilisation d'un bean session Stateful.
import javax.ejb.Stateful; @Stateful public class Caddy { private List<Article> articles = new ArrayList<Article>(); public void ajouterArticle(Article article) { if (!articles.contains(article)) articles.add(article); } public void enleverArticle(Article article) { if (articles.contains(article)) articles.remove(article); } public double getTotal() { if (articles == null || articles.isEmpty()) return 0.0; double total = 0.0; for (Article article : articles) total += article.getPrix(); return total; } }
Un bean Singleton est simplement un bean de session qui n'est instancié qu'une seule fois par application d'entreprise. Il garantit qu'une seule instance d'une classe existera dans l'application et fournit un point d'accès global vers cette classe.
Typiquement, les beans Singleton sont nécessaires dans toutes les situations où nous avons besoin que d'un seul exemplaire d'un objet, par exemple, pour décrire un spooler d'imprimante, un système de fichiers, etc. Un autre cas d'utilisation des beans Singleton est la création d'un cache unique pour toute l'application afin d'y stocker des objets spécifiques.
import javax.ejb.Singleton; @Singleton public class Cache { private Map<Element> stockage = new HashMap<String, Element>(); public void ajouterAuCache(String id, Element élément) { if (!stockage.containsKey(id)) stockage.put(id, élément); } public void enleverDuCache(String id) { if (stockage.containsKey(id)) stockage.remove(id); } public Element récupérerDuCache(String id) { if (stockage.containsKey(id)) return stockage.get(id); else return null; } }
Comme vous pouvez le constater, les beans session sans état (Stateless), avec état (Stateful) et singletons (Singleton) sont très simples à écrire puisqu'il suffit d'une seule annotation. Les singletons, toutefois, offrent plus de possibilités : ils peuvent être initialisés au lancement de l'application, chaînés ensemble, et il est possible de personnaliser finement leur accès concurrents : en proposant des verrous, en interdisant l'accès, en synchronisant, etc.
Jusqu'à présent nous nous sommes essentiellement intéressé à l'implémentation des beans sessions côté serveur. Le tout c'est de savoir maintenant comment les utiliser depuis une application cliente. Comme il existe différents types de clients, nous allons étudier comment accéder aux services délivrés par les beans sessions, suivant le cas.
Je rappelle rapidement les clients potentiels :
Pour l'instant, les exemples de beans de session que nous avons choisis utilisaient tous le modèle de programmation le plus simple : une simple classe (un POJO) annoté sans interface. En fonction de vos besoins, les beans peuvent vous offrir un modèle bien plus riche vous permettant de réaliser des appels distants, l'injection de dépendances ou des appels asynchrones.
Les beans sessions que nous venons d'étudiés n'étaient composés que d'une seule classe. En réalité, ils peuvent inclure les éléments suivants :
En résumé, une application cliente peut accéder à un bean session par l'une des interfaces (locale ou distante) ou indirectement en invoquant la classe elle-même.
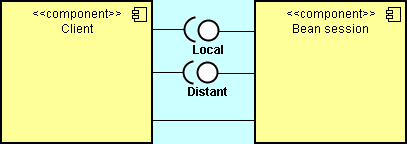
Selon d'où le client invoque un bean session, la classe de ce dernier devra implémenter des interfaces locales ou distantes, voire aucune interface.
Il est tout-à-fait possible qu'une application d'entreprise utilise à la fois des appels distants et locaux sur le même bean session.
.
Les beans session que nous avons vu jusqu'à présent n'avaient pas d'interface - la vue sans interface est une variante de la vue locale qui expose localement toutes les méthodes métiers publiques de la classe bean sans nécessiter l'emploi d'une interface métier.
import javax.ejb.Local; @Local public interface ConversionLocal { double euroFranc(double euro); double francEuro(double franc); String formatFranc(double valeur); String formatEuro(double valeur); }
import javax.ejb.Remote; @Remote public interface ConversionRemote { double euroFranc(double euro); double francEuro(double franc); double getTaux(); }
import javax.ejb.Stateless; import java.text.*; @Stateless public class ConversionBean implements ConversionRemote, ConversionLocal { private final double TAUX = 6.55957; public double euroFranc(double euro) { return euro*TAUX; } public double francEuro(double franc) { return franc/TAUX; } public String formatFranc(double valeur) { String motif = MessageFormat.format("#,##0.00 Franc{0, choice, 0#|1#s}", valeur); DecimalFormat franc = new DecimalFormat(motif); return franc.format(valeur); } public String formatEuro(double valeur) { String motif = MessageFormat.format("#,##0.00 Euro{0, choice, 0#|1#s}", valeur); DecimalFormat euro = new DecimalFormat(motif); return euro.format(valeur); } public double getTaux() { return TAUX; } }
Ce codage côté serveur présente une interface locale ConversionLocal et une interface distante ConversionRemote implémentées par le bean session sans état ConversionBean. Dans cet exemple, les clients pourront appeler localement ou à distance la méthode euroFranc() puisqu'elle est définie dans ces deux interfaces. La méthode getTaux(), par contre, ne pourra être appelée que par RMI.
Maintenant que nous avons vu des exemples de beans session avec leurs différentes interfaces, nous pouvons étudier la façon dont le client les appelle. Le client d'un bean session peut être n'importe quel type de composant : un POJO, une interface graphique Swing, une servlet, un bean géré par JSF, un service web (SOAP ou REST) ou un autre EJB (déployé dans le même conteneur ou dans un autre).
Ce mode de fonctionnement, pour accéder aux différents services proposés par le bean session, est le plus facile et le plus pratique à mettre en oeuvre. C'est celui que nous utiliserons le plus souvent. Le codage côté client se réduit à écrire la simple annotation @EJB, et toute la communication réseau avec le protocole intégré se fait alors automatiquement.
Si les données risquent de ne pas être utilisées, le bean peut éviter le coût de l'injection en effectuant à la place une recherche JNDI. En ce cas, le code ne prend les données que s'il en a besoin au lieu d'accepter des données qui lui sont transmises et qui ne lui sont plus nécessaires.
Sauf mention contraire, un client invoque un bean de façon synchrone mais, nous le verrons plus loin, EJB 3.1 autorise les appels de méthodes asynchrones.
.
Java EE utilise plusieurs annotations pour injecter des références de ressourses (@Resource), de gestionnaires d'entité (@PersistenceContext), de service web (@WebServiceRef), etc. L'annotation @javax.ejb.EJB, en revanche, est spécialement conçue pour injecter des références de beans session dans du code client.
Attention : L'injection de dépendances n'est possible que dans des environnements gérés, comme les conteneurs EJB, les conteneurs Web et les conteneurs clients d'application (ACC).
.
// Côté serveur @Stateless public class Conversion { ... } // Code client @EJB Conversion convertir;
// Côté serveur @Stateless public class ConversionBean implements ConversionRemote, ConversionLocal { ... } // Code client @EJB ConversionBean convertir; // ATTENTION, interdit ! @EJB ConversionRemote convertirRemote; @EJB ConversionLocal convertirLocal;
// Côté serveur @Stateless @LocalBean public class ConversionBean implements ConversionRemote, ConversionLocal { ... } // Code client @EJB ConversionBean convertir; // Maintenant cette écriture est autorisée @EJB ConversionRemote convertirRemote; @EJB ConversionLocal convertirLocal;
// Côté serveur @Stateless @LocalBean public class Conversion implements ConversionRemote { ... } // Code client @EJB Conversion convertir; @EJB ConversionRemote convertirRemote; // C'est cette écriture globale (serveur et client) qui paraît la plus économe et la plus efficace (c'est en tout cas celle que j'utiliserai le plus).
Dans de rare cas toutefois, il peut arriver que nous ayons besoin de mettre en oeuvre une interface locale pour autoriser uniquement quelques méthodes d'accès sur l'ensemble proposées par le bean session.
Les beans session peuvent également être recherchés par JNDI, qui est surtout utilisée pour les accès distants lorsqu'un client non géré par un conteneur ne peut pas utiliser l'injection de dépendance. Mais JNDI peut également être utilisée par des clients locaux, même si l'injection de dépendances produit un code plus clair. Pour rechercher des beans session, une application cliente doit faire communiquer l'API JNDI avec un service d'annuaire.
Tous les EJB de type Session sont enregistrés dans un annuaire avec un nom unique accessible par un client via un contexte JNDI que ce soit en utilisant directement le contexte (hors du conteneur) ou en utilisant l'injection de dépendance (dans le conteneur).
java:global[/<nom-application>]/<nom-module>/<nom-bean>!<nom-interface>
// Côté serveur @Stateless @LocalBean public class ConversionBean implements ConversionRemote, ConversionLocal { ... } // nom JNDI associé java:global/ProjetConversion/ConversionsEJB/ConversionBean!ConversionBean java:global/ProjetConversion/ConversionsEJB/ConversionBean!ConversionRemote java:global/ProjetConversion/ConversionsEJB/ConversionBean!ConversionLocal
Le nom de l'interface n'est utile que si l'EJB implémente plusieurs interfaces (Local et Remote) : Nous pouvons parfaitement nous en passer si l'EJB n'implémente qu'une seule interface (ou n'a qu'une vue sans interface). Dans ce cas, le conteneur doit aussi proposer un nom JNDI court, associé à ce même EJB :
java:global[/<nom-application>]/<nom-module>/<nom-bean>
En imaginant la construction d'un projet de conversion, avec seulement une interface distante, sous la forme d'un simple module, sans la mise en oeuvre d'une application d'entreprise, voici par exemple ce que nous pouvons écrire :
// Côté serveur @Stateless public class Conversion implements ConversionRemote { ... } // nom JNDI associé java:global/ConversionsEJB/Conversion
java:app/<nom-module>/<nom-bean>!<nom-interface>
Cet accès ne peut se faire que pour un client qui se situe à l'intérieur de la même application d'entreprise.
.
java:module/<nom-bean>!<nom-interface>
Cet accès ne peut se faire que pour un client qui se situe à l'intérieur du même module.
.
Regardons maintenant comment le client peut accéder au service proposé par le bean session. La première chose à faire, nous l'avons souligné en préambule, est de récupérer une instance de l'EJB au moyen de JNDI :
Dans le cas du serveur GlassFish, ces différentes informations sont précisées dans un certain nombre de fichiers d'archive contenus dans le sous répertoire <modules> du répertoire d'installation de GlassFish v3, que vous devez impérativement introduire dans votre projet.
Bien évidemment, pour que la communication se fasse correctement, vous devez préciser l'adresse IP du serveur d'applications dans le réseau local de l'entreprise. Ceci se spécifie au travers d'une propriété nommée .
// Côté serveur @Stateless @LocalBean public class Conversion implements ConversionRemote { ... } // Code client Properties propriétés = new Properties(); propriétés.setProperty(, ); // localisation du serveur d'applications dans le réseau local de l'entreprise Context ctx = new InitialContext(propriétés); ConversionRemote convertirRemote = (ConversionRemote) ctx.lookup("java:global/ProjetConversion/ConversionsEJB/ConversionBean!ConversionRemote");
Nous avons passé beaucoup de temps à comprendre l'ossature de la plate-forme Java EE et à définir ainsi le rôle des EJB. Après toute cette théorie, nous allons maintenant entrer dans le vif du sujet et mettre en pratique nos nouvelles connaissances.
Dans ce chapitre, nous allons créer notre premier EJB de type session sans état, Stateless. Par ailleurs, cet EJB sera, pour l'instant, accessible uniquement à distance. Comme nous sommes en phase d'apprentissage, je vous propose de faire un EJB modeste, afin de bien maîtriser les nouveaux concepts et, derrière, les nouvelles écritures associées.
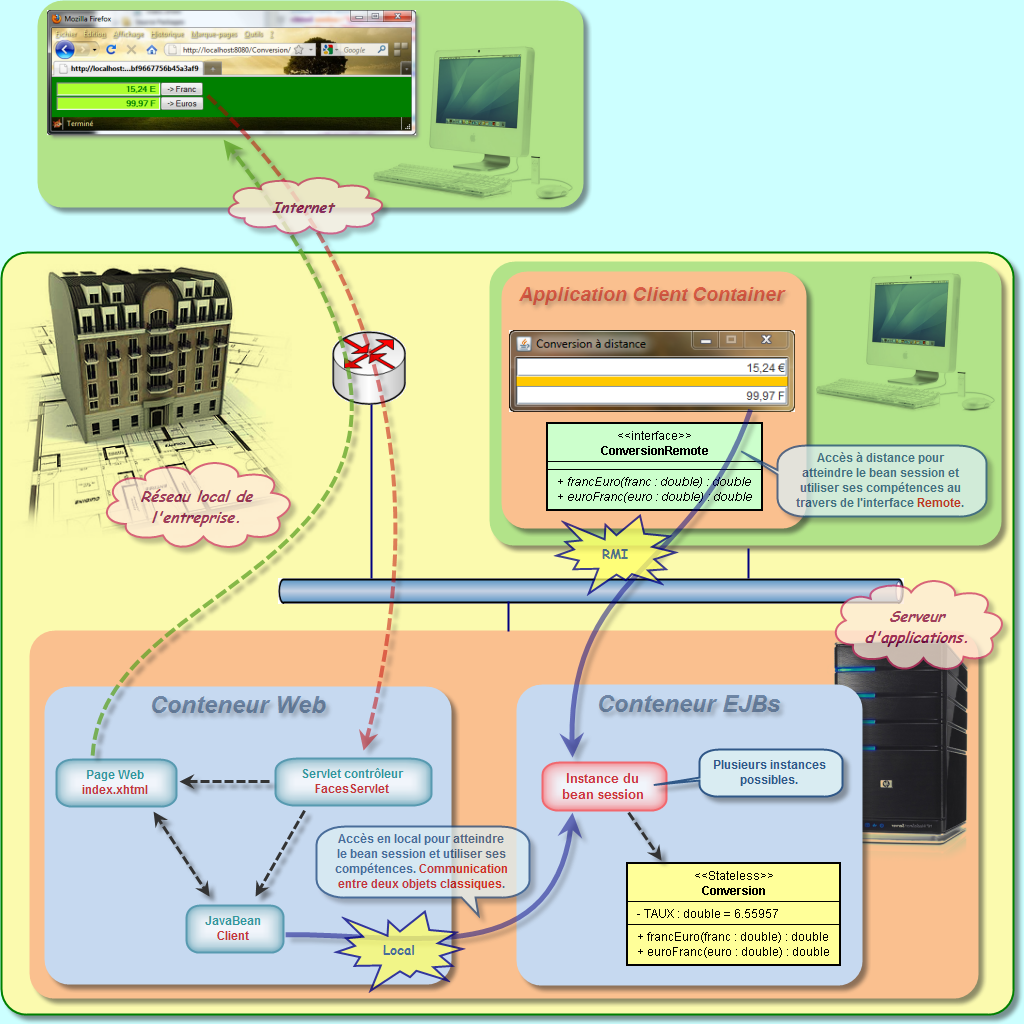
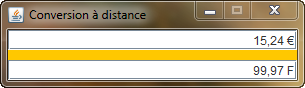
Côté serveur d'application, le service proposé par l'EJB est de permettre la conversion à distance entre les €uros et les Francs. Côté client, une fenêtre sera ouverte afin de permettre la saisie des valeurs et le choix du type de conversion à réaliser. Le traitement proprement dit sera fait par le service proposé par l'EJB de conversion. Avec cette approche, l'EJB est considérée par l'application cliente comme un objet distant.
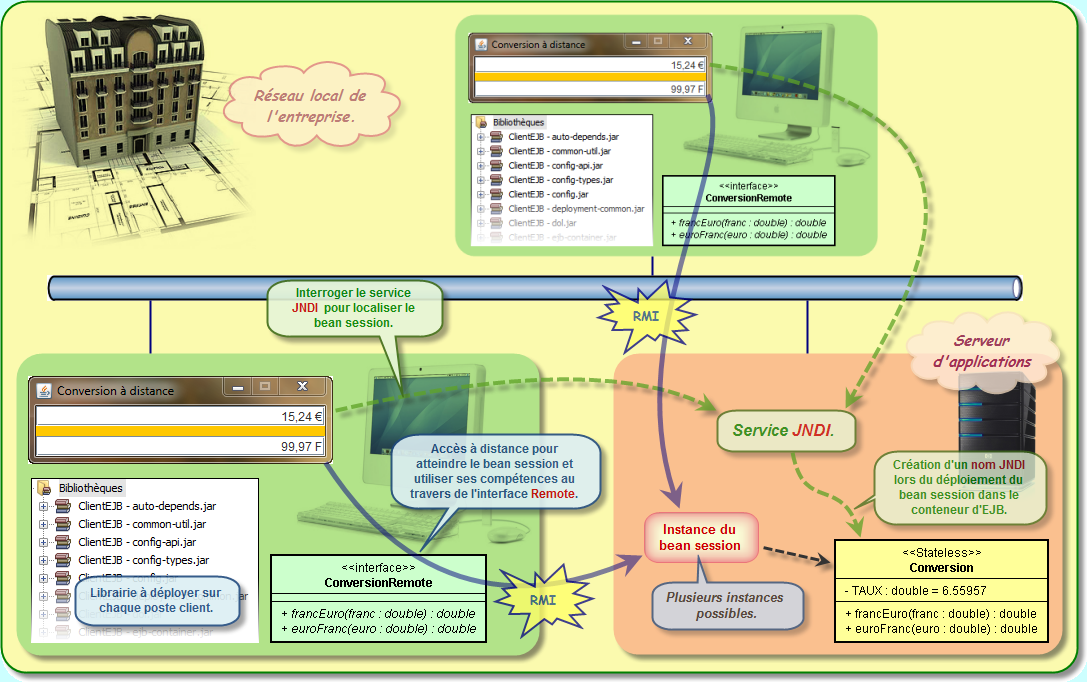
Pour atteindre l'objet distant, et pour que ce dernier puisse rendre le service désiré par le client, nous devons systématiquement passé par une interface qui représente cet objet. Nous nous retrouvons ici exactement suivant le même principe que nous avons évoqué lors de l'étude de RMI. En effet, un objet distant doit systématiquement implémenter une interface qui va spécifier les méthodes qui sont accessibles depuis un poste client. Ce sont d'ailleurs les seules méthodes autorisées. Cet objet distant doit alors respecter le contrat prévu par l'interface et définir le comportement qui va correspondre au traitement nécessaire pour chacune des méthodes prévues. Ainsi, l'interface sera présente à la fois sur le serveur d'application et aussi sur chacun des postes clients.
Je rappelle que lorsqu'un client distant appelle un EJB, il ne travaille pas directement avec une instance de cet EJB mais avec un proxy de cette instance sur le client (comme nous l'avons découvert au travers de RMI). A chaque fois qu'un client invoque une méthode de l'EJB, cet appel est en réalité pris en charge par le proxy qui lui-même dialogue avec le véritable objet distant à l'aide d'un protocole propriétaire spécifique. Tout ceci est, bien entendu, transparent pour le client.

Nous allons maintenant voir comment mettre en oeuvre l'ensemble de cette structure avec les différents codes sources requis à la fois côté serveur et côté client. J'utilise d'une part le serveur d'applications GlassFish et d'autre part l'environnement de développement Netbeans.
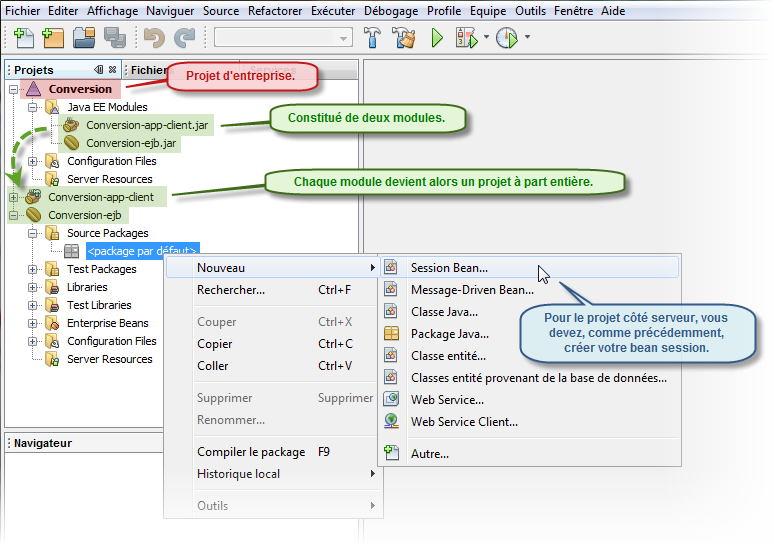
Nous avons deux projets à réaliser. Le premier projet consiste à créer un module EJB qui sera déployé automatiquement sur le serveur d'applications dont le contenu comporte notre bean session sans état qui va rendre le service désiré, c'est-à-dire calculer la conversion entre les euros et les francs.
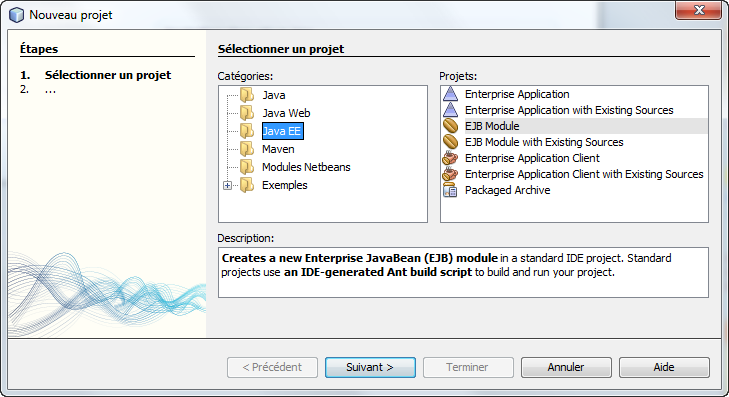


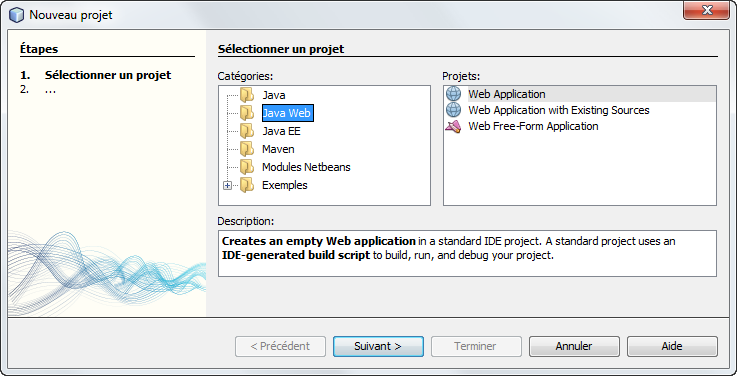
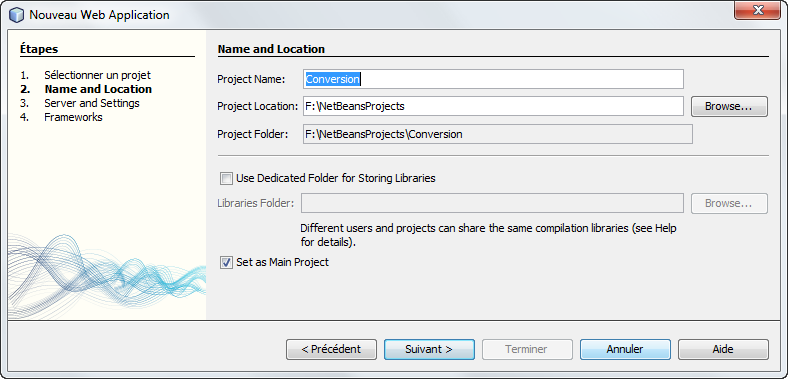
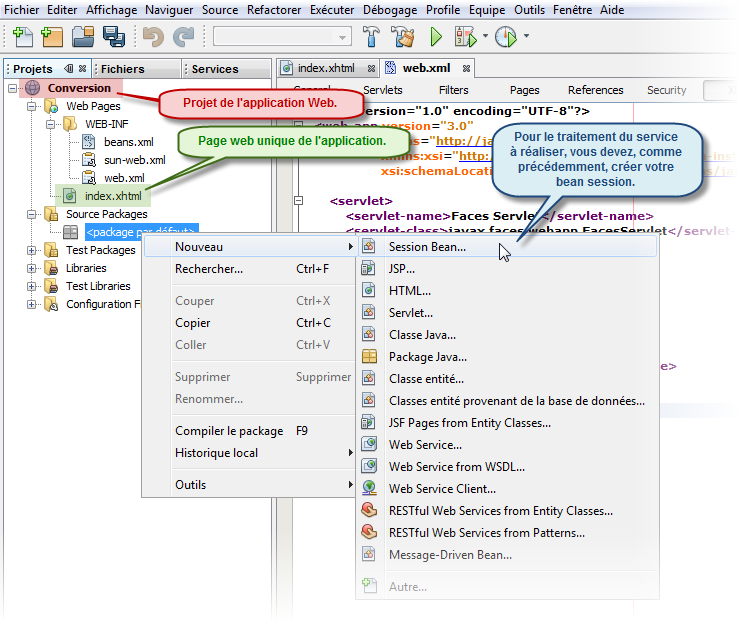
Pour l'instant notre projet est vierge, nous allons donc demander explicitement la création de notre bean session que nous appelerons Conversion.
.
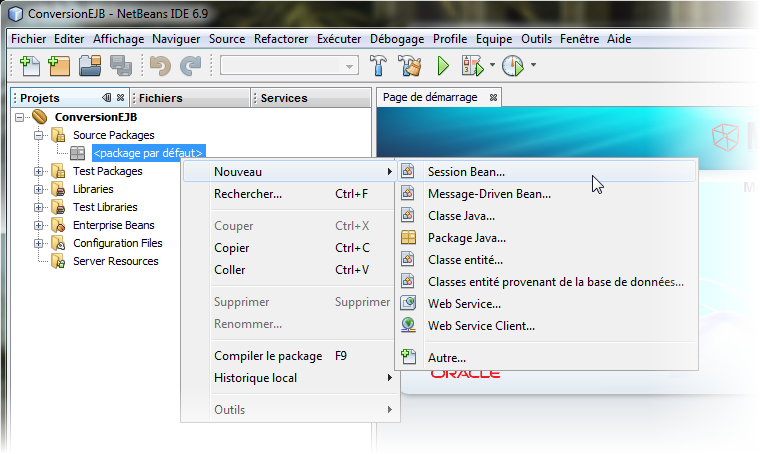
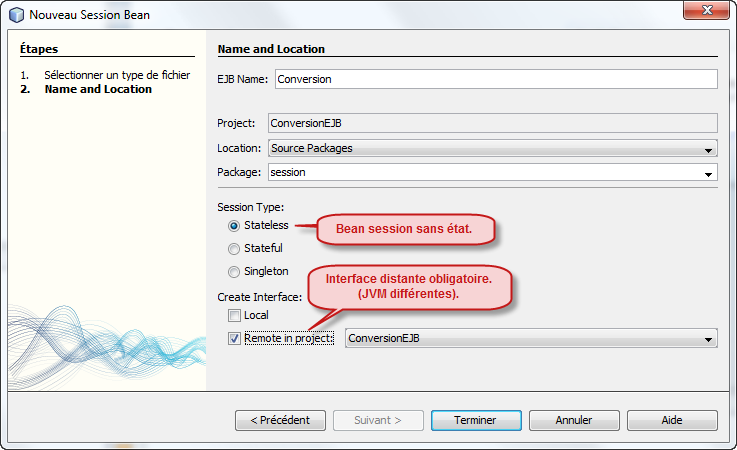
Nous connaissons déjà les interfaces. Vous avez juste à déclarer toutes les méthodes publiques qui doivent être accessibles par le client. Vous n'avez pas besoin de mettre systématiquement le qualificateur public puisque toutes les méthodes qui sont dans l'interface sont nécessairement publiques. Je prévois deux méthodes pour chacune des conversions prévues.
package session; import javax.ejb.Remote; @Remote public interface ConversionRemote { double francEuro(double franc); double euroFranc(double euro); }
Lorsque vous devez mettre en oeuvre des interfaces pour être en relation avec des EJB, vous devez spécifier le type d'accès. Ici, nous désirons que cet EJB soit accessible à distance, vous devez donc rajouter l'annotation @Remote juste avant la déclaration de l'interface. Je rappelle que les annotations sont préfixées par le symbole @. Pour que cette annotation soit prise en compte, vous devez importer cette annotation depuis le paquetage javax.ejb (avec Netbeans, tous ces éléments sont automatiquement spécifiés).
Une fois que l'interface est construite, vous pouvez maintenant vous occuper de la classe du bean session sans état qui va implémenter cette interface et qui va donc redéfinir, au moins, toutes les méthodes désignées et ainsi réaliser tout le traitement de la logique métier. Dans notre cas, nous définissons juste les méthodes de l'interface. Il n'existe pas spécialement de méthodes privées supplémentaires.
package session; import javax.ejb.Stateless; @Stateless public class Conversion implements ConversionRemote { private final double TAUX = 6.55957; @Override public double francEuro(double franc) { return franc / TAUX; } @Override public double euroFranc(double euro) { return euro * TAUX; } }
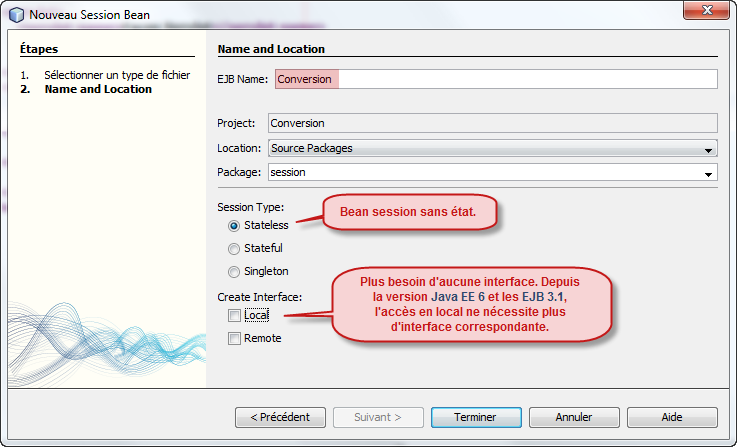
Encore une fois, nous avons besoin d'utiliser une annotation qui va spécifier quel est le type de bean session à construire. Je rappelle qu'il existe trois types de bean session, soit Stateless, soit Stateful ou soit Singleton. Juste avant la déclaration de la classe, vous précisez l'annotation correspondante au type de bean session, ici donc @Stateless. Encore une fois, il est nécessaire de faire l'importation correspondante (ici aussi, avec Netbeans, tous ces éléments sont automatiquement spécifiés).
Au niveau codage, tout est fini. Remarquez bien l'extrême simplicité d'écriture. C'est notamment beaucoup plus simple que RMI puisque vous n'avez pas besoin de vous occuper de créer l'objet distant. C'est le serveur d'applications qui gère tout cela.
Vous devez ensuite déployer votre EJB sur le serveur d'applications. Il faut alors construire une archive (extension .jar) qui comporte ces deux éléments : l'interface métier et la classe du bean. L'idéal est de disposer d'un outil de développement qui permet de réaliser tout cela automatiquement. Avec Netbeans, il suffit de cliquer sur le bouton Run pour que tout soit : compilé, archivé et déployé. Bien évidemment, il faut que votre serveur d'applications soit pris en compte par votre outil de développement comme nous l'avons fait lors de l'élaboration du projet.
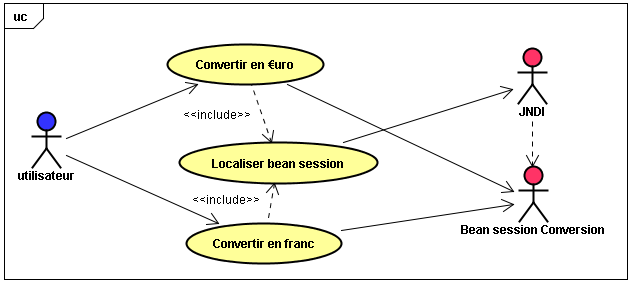
Passons maintenant à la programmation de l'application cliente. Deux aspect sont ici à prendre en compte. Nous devons d'abord réaliser l'IHM qui va permettre la saisie des valeurs à soumettre avec l'affichage du résultat. Nous devons ensuite communiquer avec l'objet distant afin que ce dernier fasse tous les traitements souhaités suivant les requêtes soumises par l'opérateur, soit une conversion en Francs, soit une conversion en €uros.

Ainsi donc, pour que la communication puisse se faire avec l'objet distant, vous devez placer dans votre projet l'interface ConversionRemote qui représente le bean session Conversion qui va rendre le service désiré à distance.
Egalement dans ce projet, pour que l'application cliente autonome (standalone) puisse fonctionner correctement lors de la communication avec le serveur d'applications, vous devez intégrer un nombre conséquent d'archives (défaut de cette solution par appel JNDI) qui se situe dans le sous-répertoire <module> du répertoire d'installation de GlassFish. Ce sous-répertoire possède bien d'autres archives qui peuvent s'avérer nécessaires suivant le cas. Pour éviter de rechercher chacune de ces archives à chaque fois que vous faites une application cliente autonome, l'idéal est de fabriquer une bibliothèque définitive dans NetBeans, ici ClientEJB.
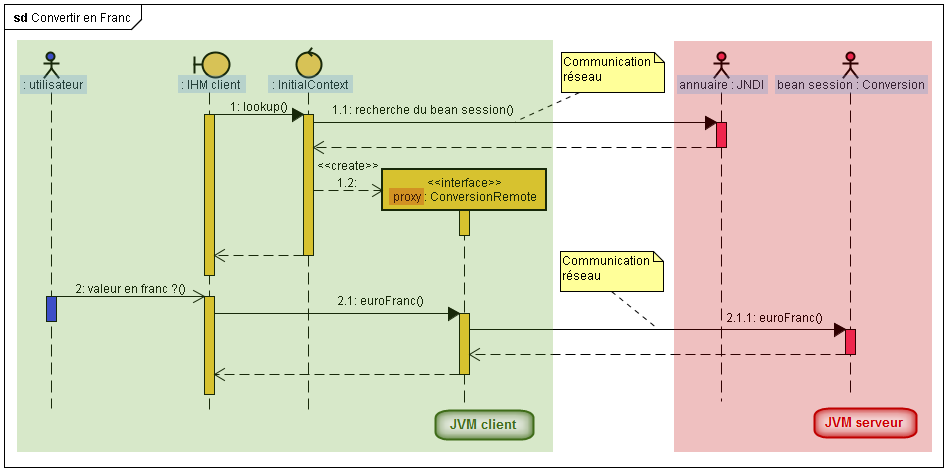
Le client doit localiser l'EJB qu'il souhaite récupérer via le service JNDI. Effectivement, les composants déployés sur le serveur d'applications sont enregistrés dans l'annuaire du serveur avec donc un nom JNDI associé à l'EJB.
Je rappelle que les appels de méthodes distantes se font par RMI (protocole réseau) alors que les appels de méthodes locales se font directement dans la JVM du serveur (sans protocole réseau).
Une fois que la localisation s'est bien déroulée, au moyen de l'interface, le client récupère une référence de l'EJB (proxy) qu'il souhaite utiliser. Celui-ci peut alors appeler les méthodes du proxy sans se soucier des contraintes de communication. En effet, l'appel d'une méthode est automatiquement transmis à l'instance de l'EJB dans le conteneur. Cette instance traite la méthode et retourne le résultat au client. La création du proxy est à la charge du conteneur et reste totalement transparente pour le client.
package conversion; import java.awt.*; import java.awt.event.*; import java.text.*; import java.util.Properties; import javax.naming.*; import javax.swing.*; import session.ConversionRemote; public class Client extends JFrame implements ActionListener { private JFormattedTextField euro = new JFormattedTextField(NumberFormat.getCurrencyInstance()); private JFormattedTextField franc = new JFormattedTextField(new DecimalFormat()); private static ConversionRemote convertir; public Client() { super(); euro.setColumns(25); euro.setHorizontalAlignment(JFormattedTextField.RIGHT); euro.setValue(0); add(euro, BorderLayout.NORTH); franc.setHorizontalAlignment(JFormattedTextField.RIGHT); franc.setValue(0); add(franc, BorderLayout.SOUTH); euro.addActionListener(this); franc.addActionListener(this); getContentPane().setBackground(Color.orange); pack(); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void actionPerformed(ActionEvent evt) { if (evt.getSource()==franc) { Number valeur = (Number) franc.getValue(); euro.setValue(convertir.francEuro(valeur.doubleValue())); } if (evt.getSource()==euro) { Number valeur = (Number) euro.getValue(); franc.setValue(convertir.euroFranc(valeur.doubleValue())); } } public static void main(String[] args) { try { Properties propriétés = new Properties(); propriétés.setProperty(, ); Context ctx = new InitialContext(propriétés); // convertir = (ConversionRemote) ctx.lookup("java:global/ConversionEJB/Conversion!session.ConversionRemote"); convertir = (ConversionRemote) ctx.lookup(); new Client(); } catch (NamingException ex) { JOptionPane.showMessageDialog(null, ); } } }
La première chose à faire, nous l'avons souligné en préambule, est de récupérer une instance de l'EJB au moyen de JNDI. Pour cela vous devez mettre en oeuvre un contexte pour l'application cliente qui va permettre de faire la recherche du nom JNDI stocké dans l'annuaire. Il faut au préalable initialiser ce contexte avec la bonne localisation du serveur d'applications au travers d'une propriété adaptée.
Une fois que la référence du proxy est obtenue, tout devient très simple. Effectivement, il suffit de faire appel aux bonnes méthodes - euroFranc() et francEuro() - de l'objet distant qui réalisent le traitement désiré.
Vous pensez peut-être que nous avons beaucoup de chose à prendre en compte. Oui c'est vrai, mais vous allez aussi découvrir que la programmation devient extrêmement simple et surtout intuitive. En effet, lorsque vous demandez un service particulier, vous faites appel à une simple méthode d'un objet, et vous avez alors l'impression que cet objet est sur le poste client, alors qu'en réalité il est à distance sur le serveur d'applications. Vous n'avez plus besoin, dans la programmation, de stipuler tout ce qui concerne la problématique du réseau (les sockets, les flux, les threads, le protocole d'échange, etc.).
Il est possible d'avoir une autre approche et de proposer un conteneur spécifique côté client qui s'affranchit de tout ces fichiers annexes. Ce conteneur s'appelle Application Client Container que nous traiterons dans le chapitre suivant.
Attention, lorsque vous proposer une connexion distante, toutes les informations qui transitent sur le réseau doivent impérativement être sérialisables.
.
Dans le chapitre précédent, nous avons mis en oeuvre une application cliente distante (dit standalone) qui se trouvait totalement détachée du module EJB, qui lui faisait parti d'un autre projet antérieur. Il a fallu alors mettre en place toute une infrastructure relativement complexe, d'une part en faisant un appel JNDI adapté suivi d'une propriété particulière, sans oublier l'adjonction d'archives propres au serveur d'applications, pour que finalement la communication réseau puisse s'établir correctement.
Il est possible de revoir notre copie afin que cette application cliente fasse partie intégrante du module EJB autour d'un même projet dénommé application d'entreprise. Pour cela, nous devons utiliser un conteneur supplémentaire proposé par le serveur d'applications qui se nomme Application Client Container.
Dans cette nouvelle façon de voir, il ne sera plus nécessaire de prévoir ces fichiers annexes pour l'application cliente. De plus la programmation s'en trouvera largement simplifiée par l'utilisation de l'injection de dépendance automatique par le seul biais de l'annotation @EJB comme nous l'avons déjà évoqué en préambule.
Il existe effectivement un conteneur client spécifique qui offre beaucoup d'avantage pour la mise en oeuvre de ces clients distants. C'est le conteneur d'application cliente ACC (Application Client Container). Le conteneur d'application cliente inclut un ensemble de classes Java, de librairies, et d'autres fichiers requis. Cet ensemble est donc généralement fourni avec le serveur d'applications et ses dépendances sont distribuées automatiquement avec le client Java qui s'exécute dans sa propre machine virtuelle sur le poste distant.
Le conteneur, déployé sur le poste client avec l'ensemble des librairies nécessaires, gère l'exécution du programme client et offre l'accès à de nombreux services Java EE, qui sont eux disponibles sur le serveur d'applications, via le protocole RMI-IIOP. Si nous le comparons avec les autres conteneurs (EJB, WEB), il est alors qualifié de conteneur léger.
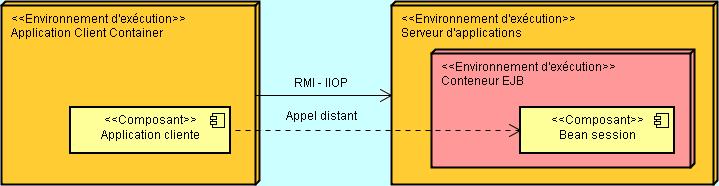
Nous allons tout simplement reprendre le projet précédent dont je rappelle la teneur. Côté serveur d'application, le service proposé par l'EJB est de permettre la conversion à distance entre les €uros et les Francs. Côté client, une fenêtre sera ouverte afin de permettre la saisie des valeurs et le choix du type de conversion à réaliser. Le traitement proprement dit sera fait par le service proposé par l'EJB de conversion. Avec cette approche, l'EJB est considérée par l'application cliente comme un objet distant.

Contrairement aux clients dit standalone, un client container-managed peut utiliser l'injection, grâce à l'annotation @EJB, pour récupérer des références vers les EJB dont il dépend. Cela évite l'écriture de la localisation JNDI. Les références vers les EJB sont automatiquement détectées et gérées par le conteneur client. Avec cette approche, l'application cliente ne fait plus référence à un serveur d'applications en particulier. Du coup, l'écriture devient standard et s'applique à tous les serveurs, ce qui offre une meilleure portabilité à vos applications.
Le principe est le même que ce soit un client dans une application Web, une application cliente fenêtrée ou même un autre EJB session. Il est dorénavent possible de gérer les dépendences des clients vis-à-vis des EJB ou des EJB entre eux par simple injection. Vous pouvez ainsi préciser au conteneur que votre EJB est dépendant de tel autre. Le conteneur se chargera d'injecter automatiquement l'instance demandée. Pour cela, il suffit d'annoter la propriété avec @EJB.
Le conteneur d'application cliente existe sur le serveur d'application, mais cette architecture est déployée également sur les poste clients qui le désirent. Cela permet de s'affranchir des archives nécessaires au déploiement puisqu'elles sont déjà présentes dans l'ACC et nous n'avons également plus besoin de mettre en oeuvre un contexte puisque l'ACC possède tous les renseignements nécessaires.
Maintenant, nous n'avons plus qu'un seul projet global à réaliser pour que l'injection de dépendance puisse se faire correctement. Ce projet global d'entreprise est en réalité une fusion de deux autres projets. D'une part, comme précédemment, le projet qui consiste à la création du module EJB dont le contenu comporte notre bean session sans état qui va calculer la conversion entre les euros et les francs. D'autre part, le projet concernant l'application cliente qui possède une IHM qui va permettre la saisie des valeurs à soumettre au bean session avec l'affichage du résultat correspondant.
Pour le déploiement, une application d'entreprise est une archive qui porte l'extension <*.ear> (Archive d'entreprise) qui elle-même comporte d'autres archives, comme l'archive d'une application Web <*.war> (archive Web), l'archive concernant l'ensemble des EJB <*.jar> et l'archive contenant des applications clientes ACC <*.jar>.
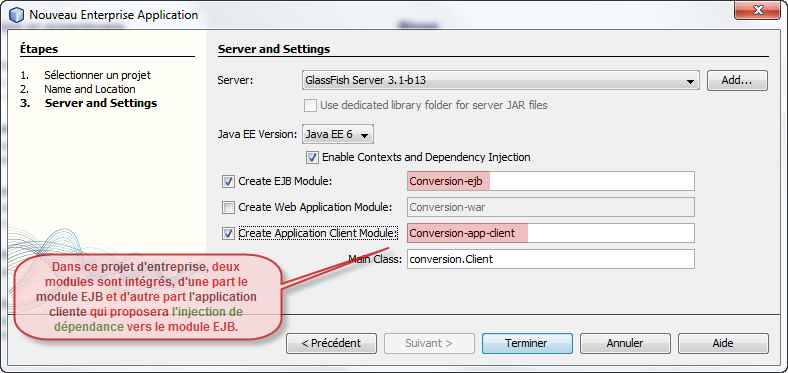
Finalement nous obtenons bien trois projets distincts :

Nous devons écrire exactement les mêmes codes sources. Rien n'a fondamentalement changé, puisque nous devons faire un accès au service proposé à distance sous une autre machine virtuelle Java. Je rappelle ci-dessous les deux codes sources :
package session; import javax.ejb.Remote; @Remote public interface ConversionRemote { double francEuro(double franc); double euroFranc(double euro); }
package session; import javax.ejb.Stateless; @Stateless public class Conversion implements ConversionRemote { private final double TAUX = 6.55957; @Override public double francEuro(double franc) { return franc / TAUX; } @Override public double euroFranc(double euro) { return euro * TAUX; } }
Le codage côté serveur est toujours aussi simple. Dans ces conditions, réaliser un service multi-tâches sans préoccupation du protocole réseau ne pose plus aucun problème de fond. Nous avons juste à nous soucier de la logique métier à mettre en oeuvre.
Comme prédédemment, nous retrouvons le même projet à constituer. Nous devons d'abord réaliser l'IHM qui va permettre la saisie des valeurs à soumettre avec l'affichage du résultat. Nous devons ensuite communiquer avec l'objet distant afin que ce dernier fasse tous les traitements souhaités suivant les requêtes soumises par l'opérateur, soit une conversion en Francs, soit une conversion en €uros.

package conversion; import java.awt.*; import java.awt.event.*; import java.text.*; import javax.ejb.EJB; import javax.swing.*; import session.ConversionRemote; public class Client extends JFrame implements ActionListener { private JFormattedTextField euro = new JFormattedTextField(NumberFormat.getCurrencyInstance()); private JFormattedTextField franc = new JFormattedTextField(new DecimalFormat()); @EJB private static ConversionRemote convertir; public Client() { super(); euro.setColumns(25); euro.setHorizontalAlignment(JFormattedTextField.RIGHT); euro.setValue(0); add(euro, BorderLayout.NORTH); franc.setHorizontalAlignment(JFormattedTextField.RIGHT); franc.setValue(0); add(franc, BorderLayout.SOUTH); euro.addActionListener(this); franc.addActionListener(this); getContentPane().setBackground(Color.orange); pack(); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void actionPerformed(ActionEvent evt) { if (evt.getSource()==franc) { Number valeur = (Number) franc.getValue(); euro.setValue(convertir.francEuro(valeur.doubleValue())); } if (evt.getSource()==euro) { Number valeur = (Number) euro.getValue(); franc.setValue(convertir.euroFranc(valeur.doubleValue())); } } public static void main(String[] args) { new Client(); } }
La grande nouveauté, par rapport à une application standalone, c'est que nous n'avons plus besoin de mettre en place, à la fois le contexte de l'application et faire la recherche par le service JNDI. Tout se fait automatiquement, à la condition, bien entendu, de le spécifier au moyen de l'annotation @EJB.
Attention, l'annotation @EJB ne peut être utilisée qu'à l'intérieur même de la classe de démarrage et doit être positionnée avec le qualificateur static. Cela est du au fait que le conteneur exécute la méthode main() qui est elle-même statique.
L'application cliente s'exécute dans un conteneur. De ce fait, c'est ce dernier qui démarre l'application et non la machine virtuelle directement (comme pour les applications Java standalone). Le temps de démarrage est du coup sensiblement plus long.
Avec Netbeans, lorsque vous cliquez sur le bouton d'exécution un certain nombre d'événements se produit :
Un des autres avantage de cette solution, c'est que l'application cliente est accessible depuis n'importe quel poste sur le réseau local sans avoir fait un seul déploiement sur chaque machine en particulier. Effectivement, l'application cliente est encapsulée dans le système Java Web Start.
Je rappelle que Java Web Start est une technologie qui s'occupe de déployer et d'installer automatiquement une application sur un poste du réseau local, avec en plus une gestion des versions du logiciel proposé. Java Web Start ne fonctionne qu'avec un serveur Web ce qu'est par nature un serveur d'applications. Du coup, un simple navigateur suffit pour récupérer l'application désirée. Dans le cas qui nous occupe, vous devez proposer l'URL suivante :
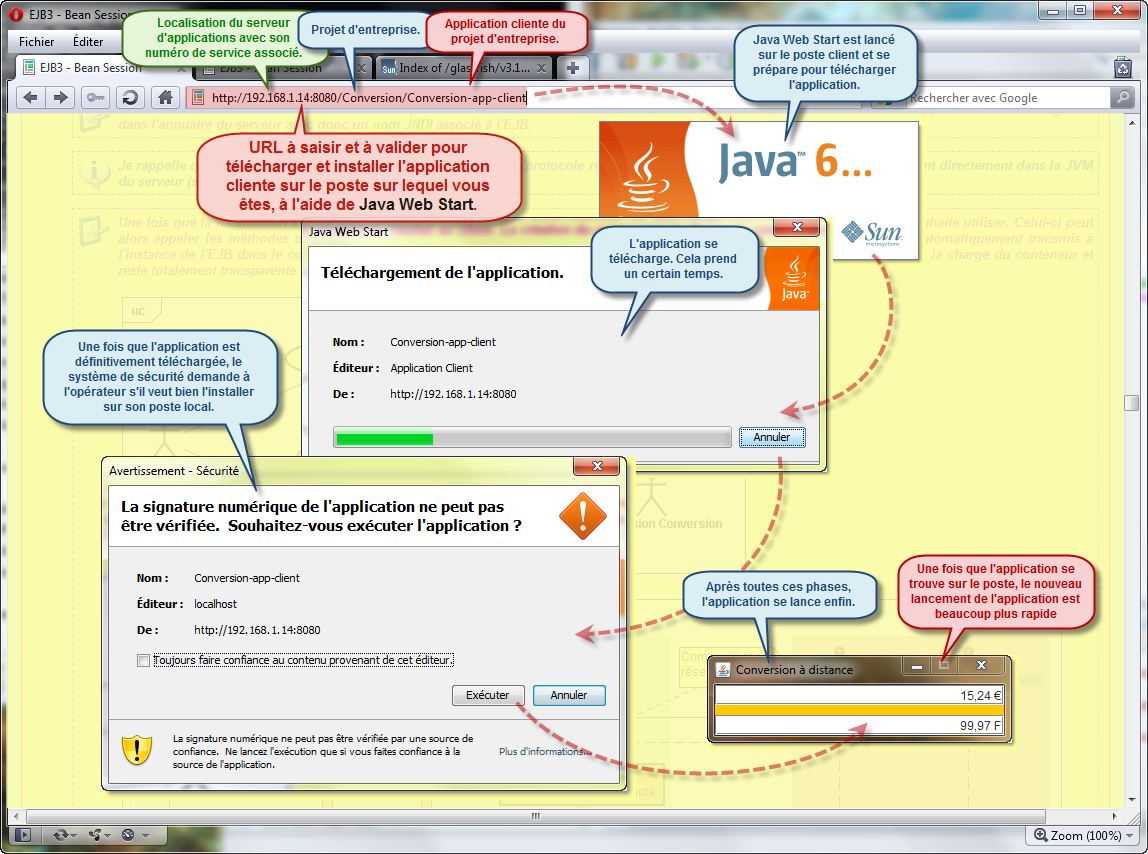
Pour en savoir plus avec Java Web Start.
.
Avec les beans session sans état et l'utilisation de l'injection de dépendance, la programmation réseau client-serveur est d'une extrême simplicité au niveau du codage alors que l'ossature sous-jacente est par contre très sophistiquée et complexe. Je rappelle les différents protagonistes :
Ce type de programmation devient extrêmement simple et surtout intuitive. En effet, lorsque vous demandez un service particulier, vous faites appel à une simple méthode d'un objet, et vous avez alors l'impression que cet objet est sur le poste client, alors qu'en réalité il est à distance sur le serveur d'applications. Vous n'avez plus besoin, dans la programmation, de stipuler tout ce qui concerne le réseau (les sockets, les flux, les threads, le protocole d'échange, etc.).
Les beans session sans état sont également les beans les plus efficaces car ils peuvent être placés dans un pool pour y être partagé par plusieurs clients - le conteneur concerve en mémoire un certain nombre d'instances (un pool) de chaque EJB sans état et les partage entre les clients. Ces beans ne mémorisant pas l'état des clients, toutes leurs instances sont donc équivalentes.

Lorsqu'un client appelle une méthode d'un bean sans état, le conteneur choisit une instance du pool et l'affecte au client ; lorsque ce dernier en a fini, l'instance retourne dans le pool pour y être réutilisée. Il suffit donc d'un petit nombre de beans pour gérer plusieurs clients (le conteneur ne garantit pas qu'il fournira toujours la même instance du bean pour un client donné).
Dans ce chapitre, nous allons reprendre l'étude précédente, en proposant cette fois-ci uniquement un accès local à l'EJB de type session Stateless. Nous conservons effectivement l'EJB du chapitre précédente, en proposant juste quelques petites retouches au niveau de l'accès. J'aimerais également toujours avoir un client ergonomique qui permette d'effectuer les calculs de conversions de façon aussi pratiques que le client fenêtré précédent. L'élément idéal pour cela me paraît être une petite application Web en technologie JSF.
Je rappelle que cette application Web va se trouver également sur le serveur d'applications. L'avantage ici, c'est que la connexion entre l'application Web et l'EJB se fait en mode local. Effectivement, puisque nous sommes sur la même machine virtuelle, nous n'avons plus besoin d'échange sur le réseau avec toute la problématique que nous avons découvert lors du chapitre précédent. Il s'agit juste d'une simple communication classique entre deux objets d'un même projet (même si les conteneurs sont différents).
Finalement, le client sera cette fois-ci un simple navigateur et l'échange entre le poste client et le serveur d'applications se fera par l'intermédiaire du protocole HTTP, ce qui permet du coup d'envisager de diffuser l'information sur Internet.
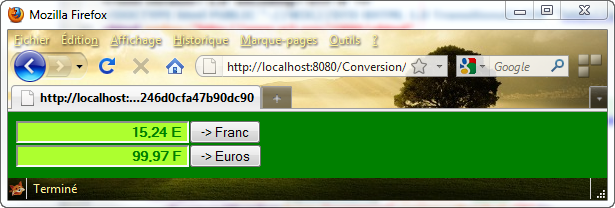
Je vous rappelle la teneur du projet. Côté serveur d'application, le service proposé par l'EJB est de traiter la logique métier qui consiste à réaliser la conversion entre les €uros et les Francs. Côté client, une application Web est activée qui sera ensuite accessible à l'aide d'un simple navigateur. Dans votre navigateur une page Web apparaît afin de permettre la saisie des valeurs et le choix du type de conversion à réaliser. Le traitement proprement dit sera fait par le service proposé par l'EJB de conversion. Avec cette approche, l'EJB est considérée par l'application cliente comme un objet local.

Grâce à l'application Web, la communication avec notre bean session se fait en local. Là aussi, comme dans le chapitre précédent, nous gérons la dépendance du client vis-à-vis des EJB par simple injection. Pour cela, il suffit d'annoter la propriété désirée à l'aide de @EJB.
Lors de ce chapitre, notre bean session sans état n'est accessible uniquement qu'en local, donc à priori soit par un autre EJB, ou soit comme c'est le cas ici par un client Web. Dans ce cas de figure, Java EE 6 permet de construire des beans sessions en passant par un simple projet de type Application Web. C'est ce que nous allons faire ici.
Pour le déploiement, une application Web est une archive qui porte l'extension <*.war> (Archive Web).
.


Comme les précédents chapitres, nous devons réaliser notre étude en deux étapes avec notamment l'élaboration du traitement côté service représenté encore une fois par notre bean session sans état. Cette fois-ci, par contre, le bean session n'a plus besoin de son interface distante puisque l'accès se fait uniquement en local. Il s'agit d'une simple classe Java (POJO) annotée @Stateless.
Nous devons écrire le même code source que précédemment sans ce préoccuper cette fois-ci d'implémenter une quelconque interface. Il s'agit d'une simple classe qui possède l'annotation @Stateless. Par ailleurs, les méthodes métiers ne devront plus également posséder l'annotation @Override puisque nous n'avons plus à les redéfinir, mais simplement à les définir :
package session; import javax.ejb.Stateless; @Stateless public class Conversion { private final double TAUX = 6.55957; public double francEuro(double franc) { return franc / TAUX; } public double euroFranc(double euro) { return euro * TAUX; } }
Le codage côté serveur est encore plus simple que précédemment. Dans ces conditions, nous avons juste à nous soucier de la logique métier à mettre en oeuvre au travers de méthodes adaptées.
Cette fois-ci l'opérateur utilisera un navigateur pour effectuer ses différentes calculs. Pour cela, nous devons réaliser l'IHM qui va permettre la saisie des valeurs à soumettre avec l'affichage du résultat correspondant. Par la suite, nous devons communiquer avec le bean session sans état afin que ce dernier fasse tous les traitements souhaités suivant les requêtes soumises par l'opérateur, soit une conversion en Francs, soit une conversion en €uros.
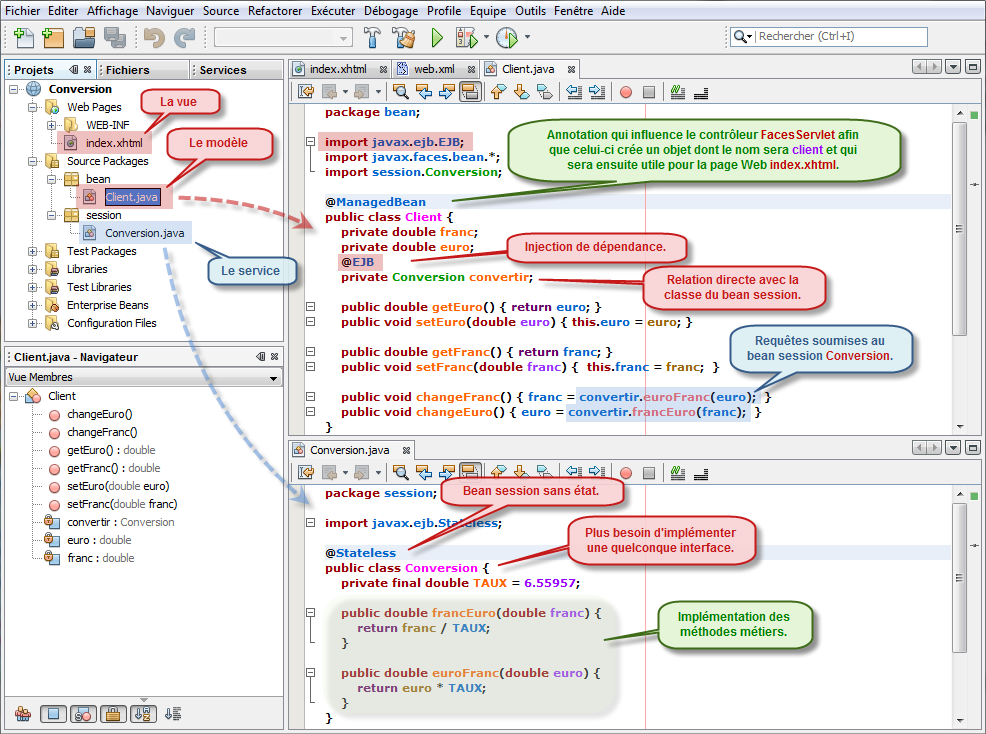
Dans la figure ci-dessus, la servlet contrôleur fabrique un objet (un bean) qui, sauf avis contraire, porte le même nom que la classe avec toutefois la première lettre en minuscule. Ainsi comme notre modèle s'appelle Client, le nom du bean sera donc client. Cet objet persiste jusqu'à ce que l'opérateur quitte l'application Web.
A partir de là, la page Web peut se connecter, si elle le désire, sur ce bean est être en interaction avec les différentes propriétés qu'il propose, à l'occurence ici euro et franc.
Je rappelle qu'une propriété en Java se reconnait par les méthodes dont les signatures sont les suivantes : getXxx() et setXxx() (lecture, écriture). Auquel cas, le nom de la propriété porte le même nom que la méthode sans le get ou le set, le tout en minuscule. Ainsi getEuro() est la méthode de lecture de la propriété euro.
Il est possible d'avoir un seul bean qui gère le traitement des informations pour plusieurs pages Web. Inversement une seule page Web peut réclamer les compétences de plusieurs beans. C'est vous qui décidez de l'architecture la plus adaptée à la situation.
Voilà ci-dessous la page Web qui représente la vue. Remarquez au passage la simplicité d'écriture et surtout la légéreté du code lorsque nous utilisons cette technologie JSF. Avec cette approche, nous séparons le rendu du traitement de fond. Deux experts peuvent alors concevoir une application Web, chacun ayant sa propre tâche ; le WebMaster d'un côté pour la partie visuelle, et le développeur Java pour le traitement des données.

package bean; import javax.ejb.EJB; import javax.faces.bean.*; import session.Conversion; @ManagedBean public class Client { private double franc; private double euro; @EJB private Conversion convertir; public double getEuro() { return euro; } public void setEuro(double euro) { this.euro = euro; } public double getFranc() { return franc; } public void setFranc(double franc) { this.franc = franc; } public void changeFranc() { franc = convertir.euroFranc(euro); } public void changeEuro() { euro = convertir.francEuro(franc); } }
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f=> <style type=> body { background-color: green; } .saisie { text-align: right; font-weight: bold; padding-right: 5px; background-color: greenyellow; color: green; } </style> <h:body> <h:form> <h:inputText value=#{client.euro} styleClass=saisie> <f:convertNumber type= currencySymbol=/> </h:inputText> <h:commandButton action=#{client.changeFranc} value= /> <br /> <h:inputText value=#{client.franc} styleClass=saisie> <f:convertNumber type= currencySymbol= /> </h:inputText> <h:commandButton action=#{client.changeEuro} value= /> </h:form> </h:body> </html>
Certainement le plus gros avantage d'un accès en mode local, c'est que vous n'avez pas besoin de sérialiser vos valeurs qui transitent entre l'EJB et l'application Web.
Par ailleurs, le fait d'avoir une application Web, vous n'avez plus besoin de vous soucier de déployer votre application puisque le client est un simple navigateur sans compétence particulière même sur la technologie Java. Aucun pluggin n'est à installer. En effet, votre application Web propose des pages Web dynamiques, c'est-à-dire que l'application Web va générer des pages web HTML à la volée suivant les requêtes soumises par l'opérateur (donc en finalité des pages HTML standard).
Cette toute dernière version Java EE 6 permet d'intégrer directement des beans sessions à l'intérieur d'un projet d'application web. Ce qui donne une grande souplesse. Cela nous permet d'éviter de faire systématiquement des projets d'entreprise, avec deux projets en interne, le module Web d'un côté, et le module EJB de l'autre.
Au moyen de @EJB l'injection de la référence vers l'EJB session se fait automatiquement. Plus besoin de mettre en place un contexte, et de préciser aussi sa localisationet plus besoin enfin de fichier d'archives à déployer puisque tout se trouve sur place. Effectivement, les EJBs se trouvent dans le même conteneur qui lui se trouve dans un seul serveur d'applications, et par là, sur la même machine virtuelle. Donc, pas besoin de recherche particulière.
Le principe est le même que ce soit un client dans une application Web, une application cliente distante ou même un autre EJB session. Il est dorénavent possible de gérer les dépendences des clients vis-à-vis des EJB ou des EJB entre eux par simple injection. Vous pouvez ainsi préciser au conteneur que votre EJB est dépendant de tel autre. Le conteneur se chargera d'injecter automatiquement l'instance demandée. Pour cela, il suffit d'annoter la propriété avec @EJB.
@Stateless class CommunBean { void uneMéthode() { ... } } @Statefull class GlobalBean implements GlobalRemote { @EJB private CommunBean commun; void uneAutreMéthode() { commun.uneMéthode(); } ... }
Nous connaissons maintenant les différents accès possibles avec un bean session de type Stateless ; à distance sur le réseau local avec un accès de type Remote, et en local, en conjonction avec une application Web sur le serveur d'application. L'idéal, c'est de proposer les deux en même temps. Ainsi, nous avons deux types de client potentiel. D'une part en réseau local, un client riche de type fenêtré, et d'autre part sur internet, l'utilisation d'une application Web accessible au travers d'un simple navigateur.
Nous pouvons élaborer notre structure, vous vous en doutez, autour d'un projet d'entreprise. Ce projet global d'entreprise est maintenant une fusion de trois autres projets :
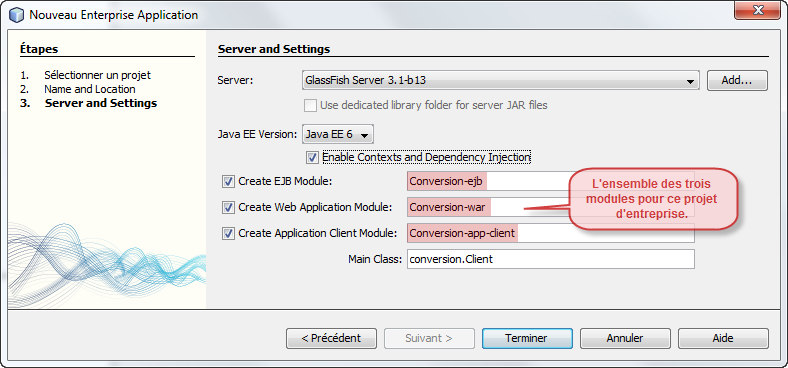
Je ne vais pas vous reproposer les captures d'écran, mais comme précédemment, dans ce module nous devons demander la création d'un bean session sans état avec un accès distant possible.
Bien évidemment nous retrouvons pratiquement les mêmes codes sources. Nous devons penser toutefois à rajouter l'annotation @LocalBean afin que le modèle de l'application Web puisse accéder au service proposé par le bean session en local.
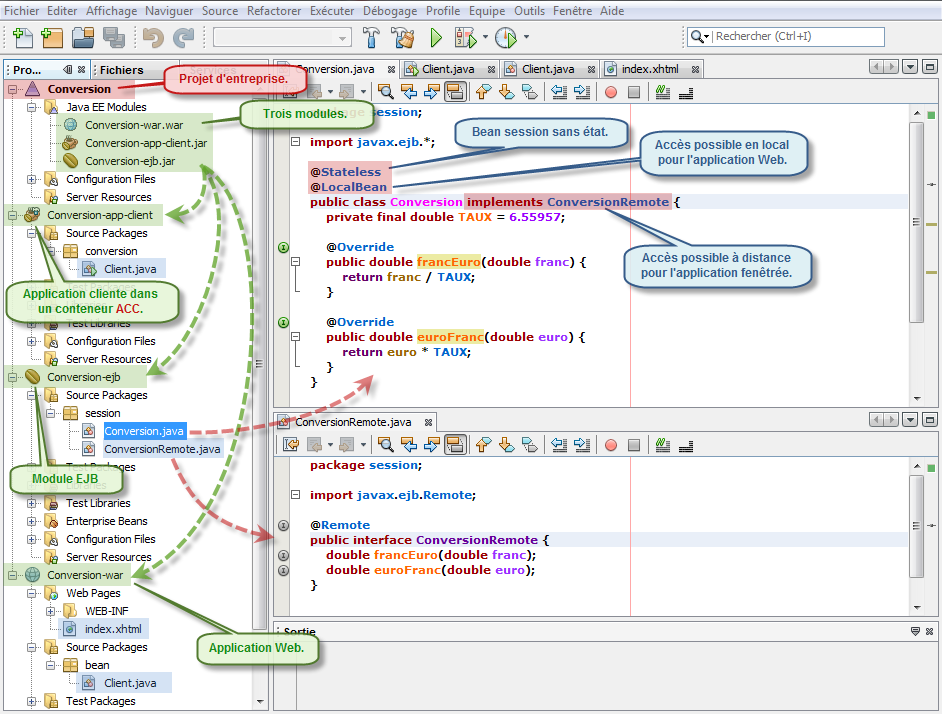
package session; import javax.ejb.Remote; @Remote public interface ConversionRemote { double francEuro(double franc); double euroFranc(double euro); }
package session; import javax.ejb.Stateless; @Stateless @LocalBean public class Conversion implements ConversionRemote { private final double TAUX = 6.55957; @Override public double francEuro(double franc) { return franc / TAUX; } @Override public double euroFranc(double euro) { return euro * TAUX; } }
Pour l'application Web, le code est totalement identique au chapitre précédent. Il existe toutefois une petite particularité, c'est lorsque vous intégrez un module application Web dans un projet d'entreprise, le framework JSF n'est pas introduit. Vous devez le préciser explicitement en réglant les propriétés du projet correspondant (Conversion-war) :

package bean; import javax.ejb.EJB; import javax.faces.bean.*; import session.Conversion; @ManagedBean public class Client { private double franc; private double euro; @EJB private Conversion convertir; public double getEuro() { return euro; } public void setEuro(double euro) { this.euro = euro; } public double getFranc() { return franc; } public void setFranc(double franc) { this.franc = franc; } public void changeFranc() { franc = convertir.euroFranc(euro); } public void changeEuro() { euro = convertir.francEuro(franc); } }
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f=> <style type=> body { background-color: green; } .saisie { text-align: right; font-weight: bold; padding-right: 5px; background-color: greenyellow; color: green; } </style> <h:body> <h:form> <h:inputText value=#{client.euro} styleClass=saisie> <f:convertNumber type= currencySymbol=/> </h:inputText> <h:commandButton action=#{client.changeFranc} value= /> <br /> <h:inputText value=#{client.franc} styleClass=saisie> <f:convertNumber type= currencySymbol= /> </h:inputText> <h:commandButton action=#{client.changeEuro} value= /> </h:form> </h:body> </html>
Pour ce projet, c'est la même chose. Il est totalement identique à l'avant dernier chapitre. Une petite remarque toutefois. Lorsque vous demandez l'exécution du projet, le projet d'entreprise, avec ses trois modules, est automatiquement déployé sur le serveur d'applications. Ensuite, par défaut, c'est le module concernant l'application Web qui est exécuté. Si vous désirez faire en sorte que ce soit l'application cliente fenêtrée qui soit lancée à la place, vous devez régler les propriétés du projet d'entreprise en conséquence :
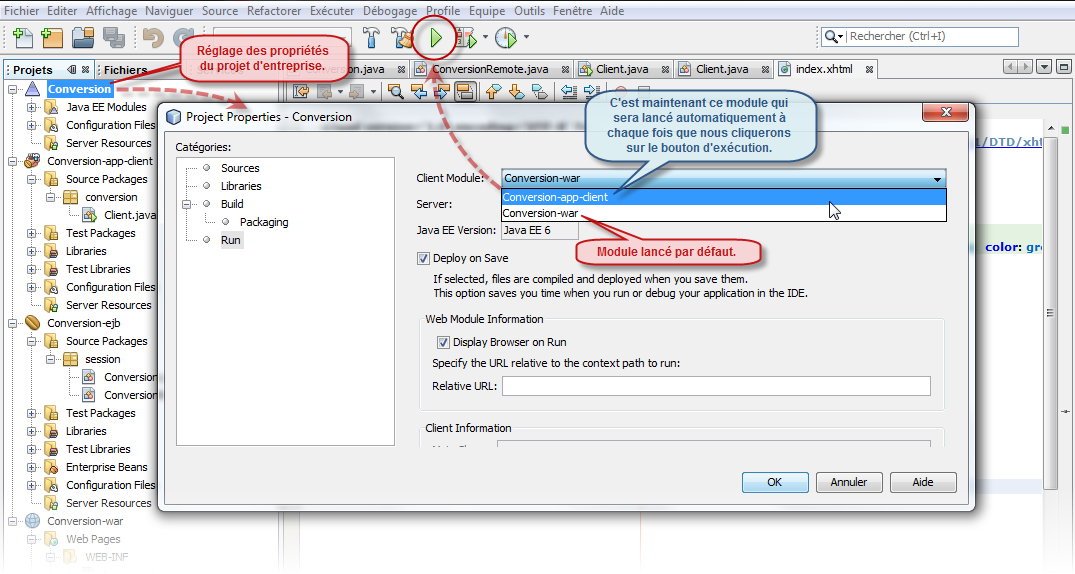
package conversion; import java.awt.*; import java.awt.event.*; import java.text.*; import javax.ejb.EJB; import javax.swing.*; import session.ConversionRemote; public class Client extends JFrame implements ActionListener { private JFormattedTextField euro = new JFormattedTextField(NumberFormat.getCurrencyInstance()); private JFormattedTextField franc = new JFormattedTextField(new DecimalFormat()); @EJB private static ConversionRemote convertir; public Client() { super(); euro.setColumns(25); euro.setHorizontalAlignment(JFormattedTextField.RIGHT); euro.setValue(0); add(euro, BorderLayout.NORTH); franc.setHorizontalAlignment(JFormattedTextField.RIGHT); franc.setValue(0); add(franc, BorderLayout.SOUTH); euro.addActionListener(this); franc.addActionListener(this); getContentPane().setBackground(Color.orange); pack(); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public void actionPerformed(ActionEvent evt) { if (evt.getSource()==franc) { Number valeur = (Number) franc.getValue(); euro.setValue(convertir.francEuro(valeur.doubleValue())); } if (evt.getSource()==euro) { Number valeur = (Number) euro.getValue(); franc.setValue(convertir.euroFranc(valeur.doubleValue())); } } public static void main(String[] args) { new Client(); } }
Après avoir longuement travaillé sur le bean session de type Stateless, venons en maintenant à l'étude du type Stateful. Je rappelle qu'il introduit le concept de session entre le client et le serveur. Il peut effectivement arriver, dans certain cas, que la récupération des informations se fasse en plusieurs phases. Il faut alors mémoriser les actions réalisées à chacune des étapes franchies. Le bean Stateful permet de résoudre ce problème. Il est effectivement capable, après l'appel d'une méthode, de conserver un état spécifique, et ceci pour un client en particulier. Du coup, il y a de grandes chances pour que ce bean possède un certain nombre d'attributs associés à la classe qui vont généralement représenter les différents états attendus.
A retenir : Les beans sans état fournissent des méthodes métiers aux clients mais n'entretiennent pas d'état conversationnel avec eux. Les beans sessions avec état, par contre préservent cet état : ils permettent ainsi d'implémenter les tâches qui nécessitent plusieurs étapes, chacune tenant compte de l'état de l'étape précédente.
Prenons comme exemple le panier virtuel d'un site de commerce en ligne : un client se connecte (sa session débute), choisit un premier livre et l'ajoute au panier, puis choisit un second livre et l'ajoute également. Puis le client valide la commande, la paye et se déconnecte (la session se termine). Ici, le panier virtuel conserve l'état - les livres choisis - pendant tout le temps de la session.

Quand un client invoque un bean avec état sur le serveur, le conteneur d'EJBs doit fournir la même instance à chaque appel de méthode - ce bean ne peut être réutilisé par un autre client. Toutefois, d'un point de vue du développeur, aucun code supplémentaire n'est nécessaire car cette relation est gérée automatiquement par le conteneur.
Cette relation a évidemment un prix : si un million de clients se connectent, ceci signifie que nous aurons un million de beans en mémoire. Pour réduire cette occupation, les beans doivent être supprimés temporairement de la mémoire entre deux requêtes - cette technique est appelée passivation et activation. La passivation consiste à supprimer une instance de la mémoire et à la sauvegarder dans un emplacement (un fichier sur disque, une base de données, etc.) : elle permet de libérer la mémoire et les ressources. L'activation est le processus inverse : elle restaure l'état et l'applique à une instance. Ces deux opérations sont réalisées par le conteneur : le dévelopeur, encore une fois, n'a pas à s'en préoccuper.
Ceci dit, il est tout-à-fait possible de ce passer de ces annotations en se fiant au fait que le conteneur supprime automatiquement une instance lorsqu'une session client se termine ou expire. Mais s'assurer que le bean est détruit au moment adéquat permet de réduire l'occupation mémoire, ce qui peut se révéler essentiel pour les applications à haute concurrence.
Afin d'illustrer toute cette introduction, je vous propose de réaliser une application d'entreprise qui permet d'archiver un ensemble de fichiers qui sont stockés sur la même machine que le serveur d'applications. Dans ce cas de figure, nous pouvons considérer ce serveur comme un serveur de fichiers. Ces fichiers pourront être archivés ou récupérés depuis le réseau local à l'aide d'une application fenêtrée.
Afin que nous puissions sauvegarder n'importe quel type de fichier et surtout quelque soit les tailles de ces derniers, le transfert se fera systématiquement par bloc d'octets. Afin de suivre correctement la sauvegarde complète au travers du réseau de tous ces blocs qui constitue le fichier, nous sommes donc dans l'obligation de prendre un bean session avec état.
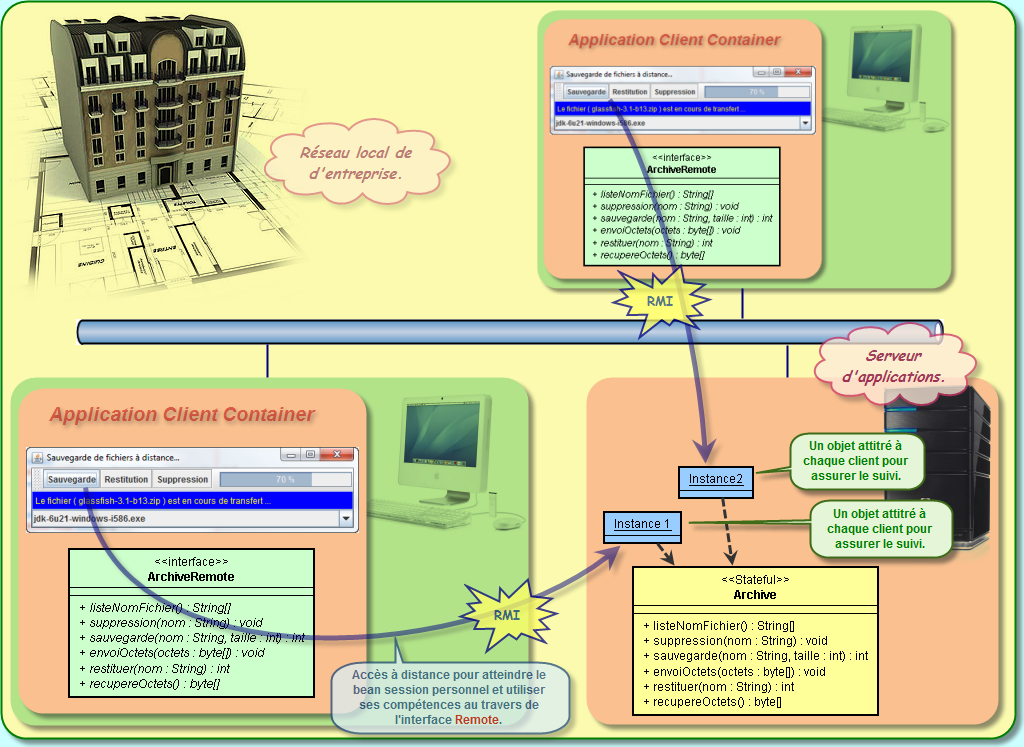
Maintenant que nous connaissons bien le principe, nous devons réaliser un projet d'entreprise avec deux modules, le premier qui met en oeuvre le service d'archivage de fichiers au travers d'un bean session avec état, le deuxième qui met en place l'IHM cliente qui va permettre de stocker des fichiers locaux pour les envoyer sur le serveur de fichiers, de pouvoir les récupérer ultérieurement ou de les supprimer à distance.
Commençons par le module EJB. La seule différence par rapport au projets précédents est de prendre en compte un bean session avec état :

package session; import java.io.IOException; import javax.ejb.Remote; @Remote public interface ArchiveRemote { final int BUFFER = 4096; String[] listeNomFichier(); void suppression(String nomFichier); int sauvegarde(String nomFichier, int taille) throws IOException; void envoiOctets(byte[] octets) throws IOException; int restituer(String nomFichier) throws IOException; byte[] recupereOctets() throws IOException; }
package session; import java.io.*; import javax.ejb.*; @Stateful public class Archive implements ArchiveRemote { private final String répertoire = ; private String nomFichier; private BufferedOutputStream enregistrement; private BufferedInputStream lecture; private int taille; private int nombre; @Override public String[] listeNomFichier() { return new File(répertoire).list(); } @Override public void suppression(String nomFichier) { new File(répertoire+nomFichier).delete(); } @Override public int sauvegarde(String nomFichier, int taille) throws IOException { this.nomFichier = nomFichier; enregistrement = new BufferedOutputStream(new FileOutputStream(répertoire + nomFichier)); this.taille = taille; return nombre = this.taille / BUFFER; } @Override public void envoiOctets(byte[] octets) throws IOException { enregistrement.write(octets); nombre--; if (nombre<0) enregistrement.close(); } @Override public int restituer(String nomFichier) throws IOException { lecture = new BufferedInputStream(new FileInputStream(répertoire+nomFichier)); return lecture.available(); } @Override public byte[] recupereOctets() throws IOException { byte[] octets = lecture.available() >= BUFFER ? new byte[BUFFER] : new byte[lecture.available()]; lecture.read(octets); if (lecture.available() <= 0) lecture.close(); return octets; } }
Ce bean session avec état propose quatre fonctionnalités de base :
Par ailleurs, nous remarquons deux différences fondamentales par rapport au bean session sans état.
Mise à part ces quelques remarques, nous pouvons souligner encore une fois que la mise en oeuvre d'une communication réseau, cette fois-ci d'ailleurs relativement sophistiqué, est d'une extrême simplicité. En aucun moment, nous faisons référence au réseau. Et pourtant, nous envoyons de très gros fichiers au travers de celui-ci. Il suffit juste d'appeler les bonnes méthodes avec les bons paramètres, comme lors de l'utilisation d'un simple objet local, alors qu'ici, il se trouve tout simplement à distance.
D'après ce que nous avons évoqué en introduction, il est possible de rajouter des annotations supplémentaires pour gérer explicitement l'expiration du bean session avec un délai spécifique ou par l'appel d'une méthode adaptée.
package session; import java.io.*; import javax.ejb.*; @Stateful @StatefulTimeout(20000) // délai d'expiration public class Archive implements ArchiveRemote { private final String répertoire = ; private String nomFichier; private BufferedOutputStream enregistrement; private BufferedInputStream lecture; private int taille; private int nombre; @Override public String[] listeNomFichier() { return new File(répertoire).list(); } @Override public void suppression(String nomFichier) { new File(répertoire+nomFichier).delete(); } @Override public int sauvegarde(String nomFichier, int taille) throws IOException { this.nomFichier = nomFichier; enregistrement = new BufferedOutputStream(new FileOutputStream(répertoire + nomFichier)); this.taille = taille; return nombre = this.taille / BUFFER; } @Override public void envoiOctets(byte[] octets) throws IOException { enregistrement.write(octets); nombre--; if (nombre<0) enregistrement.close(); } @Override public int restituer(String nomFichier) throws IOException { lecture = new BufferedInputStream(new FileInputStream(répertoire+nomFichier)); return lecture.available(); } @Override public byte[] recupereOctets() throws IOException { byte[] octets = lecture.available() >= BUFFER ? new byte[BUFFER] : new byte[lecture.available()]; lecture.read(octets); if (lecture.available() <= 0) lecture.close(); return octets; } @Remove // expiration du bean session à l'issu de l'exécution de cette méthode public void annuler() throws IOException { lecture.close(); enregistrement.close(); } }
Pour l'application cliente, nous réalisons une IHM simple qui va nous permettre de communiquer correctement avec le serveur de fichiers. Nous devons donc retrouver les quatre fonctionnalités de base.
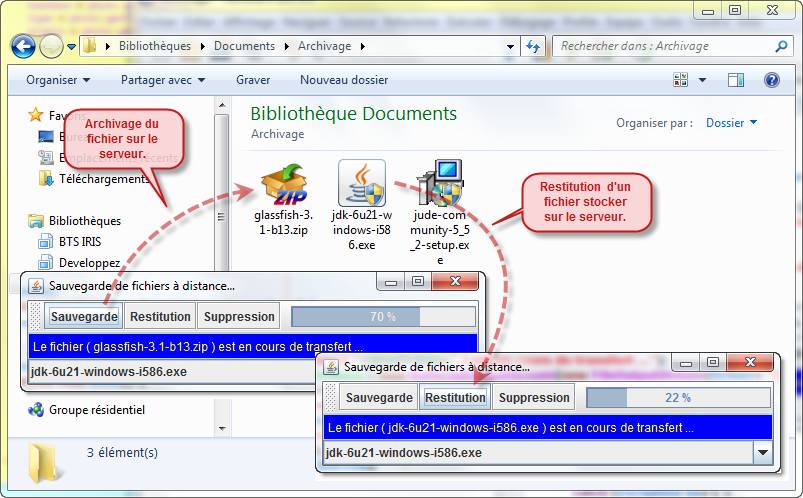
package archivage; import session.ArchiveRemote; import java.awt.*; import java.awt.event.*; import java.io.*; import javax.ejb.EJB; import javax.swing.*; import java.util.List; public class Client extends JFrame { private JToolBar barre = new JToolBar(); private JFileChooser sélecteur = new JFileChooser(); private JComboBox liste = new JComboBox(); private JProgressBar progression = new JProgressBar(); private JTextField résultat = new JTextField(, 40); private enum ChoixTransfert {SAUVEGARDER, RESTITUER}; @EJB private static ArchiveRemote archive; public Client() { super(); add(barre, BorderLayout.NORTH); add(résultat); add(liste, BorderLayout.SOUTH); barre.add(new AbstractAction() { @Override public void actionPerformed(ActionEvent e) { sélecteur.setFileSelectionMode(JFileChooser.FILES_ONLY); if (sélecteur.showDialog(null, )==JFileChooser.APPROVE_OPTION) new TransfertFichier(sélecteur.getSelectedFile(), ChoixTransfert.SAUVEGARDER).execute(); } }); barre.add(new AbstractAction() { @Override public void actionPerformed(ActionEvent e) { sélecteur.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY); if (sélecteur.showDialog(null, )==JFileChooser.APPROVE_OPTION) new TransfertFichier(sélecteur.getSelectedFile(), ChoixTransfert.RESTITUER).execute(); } }); barre.add(new AbstractAction() { @Override public void actionPerformed(ActionEvent e) { String nomFichier = (String) liste.getSelectedItem(); archive.suppression(nomFichier); listeDesFichiers(); résultat.setText(+nomFichier+); } }); barre.addSeparator(); barre.add(progression); progression.setStringPainted(true); progression.setVisible(false); résultat.setEditable(false); résultat.setMargin(new Insets(3, 3, 3, 3)); résultat.setBackground(Color.BLUE); résultat.setForeground(Color.YELLOW); listeDesFichiers(); pack(); setLocationRelativeTo(null); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } private void listeDesFichiers() { liste.removeAllItems(); for (String nomFichier : archive.listeNomFichier()) liste.addItem(nomFichier); } public static void main(String[] args) { new Client(); } private class TransfertFichier extends SwingWorker<String, Integer> { private File fichier; private int octetsLus, maximum, nombre; private ChoixTransfert transfert; private final int BUFFER; private String nomFichier; public TransfertFichier(File fichier, ChoixTransfert transfert) { this.fichier = fichier; this.transfert = transfert; BUFFER = archive.BUFFER; } @Override protected String doInBackground() throws Exception { try { progression.setVisible(true); progression.setValue(0); octetsLus = 0; byte[] octets = new byte[BUFFER]; switch (transfert) { case SAUVEGARDER : nomFichier = fichier.getName(); résultat.setText(+nomFichier+); BufferedInputStream lecture = new BufferedInputStream(new FileInputStream(fichier)); progression.setMaximum(maximum = lecture.available()); nombre = archive.sauvegarde(fichier.getName(), maximum); for (int i=0; i < nombre; i++) { lecture.read(octets); archive.envoiOctets(octets); publish(octetsLus += BUFFER); } octets = new byte[lecture.available()]; lecture.read(octets); archive.envoiOctets(octets); lecture.close(); break; case RESTITUER : nomFichier = (String) liste.getSelectedItem(); résultat.setText(+nomFichier+); BufferedOutputStream écriture = new BufferedOutputStream(new FileOutputStream(fichier+ + nomFichier)); nombre = (maximum = archive.restituer(nomFichier)) / BUFFER; progression.setMaximum(maximum); for (int i=0; i <= nombre; i++) { octets = archive.recupereOctets(); écriture.write(octets); publish(octetsLus += BUFFER); } écriture.close(); break; } listeDesFichiers(); return +nomFichier+; } catch (FileNotFoundException ex) { return ; } catch (IOException ex) { return ; } } @Override protected void process(List<Integer> nombres) { progression.setValue(nombres.get(nombres.size()-1)); } @Override protected void done() { try { résultat.setText(get()); progression.setVisible(false); } catch (Exception ex) { } } } }
Dans cette application cliente, nous désirons faire en sorte de connaître en temps réel la progression du transfert de fichier. Pour cela, nous devons mettre en oeuvre un système multi-tâches afin que la visualisation de la progression ne soit pas bloquée par la commande de transfert.
Lorsqu'un utilisateur émet une commande pour laquelle le traitement est long, vous devez déclencher un nouveau thread pour qu'il effectue le travail. Il existe maintenant, depuis Java SE 6.0, une classe intéressante qui simplifie le travail, et qui permet surtout de suivre une progression. Il s'agit de la classe SwingWorker.
Vous devez construire une nouvelle classe qui hérite de cette classe SwingWorker qui va permettre les fonctionnalités globales suivantes :
La classe SwingWorker simplifie l'implémentation de cette tâche. Voici la procédure exacte à suivre :
Pour en savoir plus avec SwingBuilder.
.
Un bean Singleton est simplement un bean de session qui n'est instancié qu'une seule fois par application d'entreprise. Il garantit qu'une seule instance d'une classe existera dans l'application et fournit un point d'accès global vers cette classe.
Typiquement, les beans Singleton sont nécessaires dans toutes les situations où nous avons besoin que d'un seul exemplaire d'un objet, par exemple, pour décrire un spooler d'imprimante, un système de fichiers, etc. Un autre cas d'utilisation des beans Singleton est la création d'un cache unique pour toute l'application afin d'y stocker des objets spécifiques.
import javax.ejb.Singleton; @Singleton public class Cache { private Map<Element> stockage = new HashMap<String, Element>(); public void ajouterAuCache(String id, Element élément) { if (!stockage.containsKey(id)) stockage.put(id, élément); } public void enleverDuCache(String id) { if (stockage.containsKey(id)) stockage.remove(id); } public Element récupérerDuCache(String id) { if (stockage.containsKey(id)) return stockage.get(id); else return null; } }
L'avantage des EJBs Singletons, c'est qu'ils offrent tous les services d'un EJB : sécurité, transaction, injection de dépendances, gestion du cycle de vie et intercepteurs, ...
.
Comme vous pouvez le constater, les beans session sans état (Stateless), avec état (Stateful) et singletons (Singleton) sont très simples à écrire puisqu'il suffit d'une seule annotation. Les singletons, toutefois, offrent plus de possibilités : ils peuvent être initialisés au lancement de l'application, chaînés ensemble, et il est possible de personnaliser finement leur accès concurrents : en proposant des verrous, en interdisant l'accès, en synchronisant, etc.
Par contre, les singletons ne sont pas compatibles avec les clusters. Un cluster est un groupe de conteneurs fonctionnant de concert (ils partagent les mêmes ressources, les mêmes EJB, etc.). Lorsqu'il y a plusieurs conteneurs répartis en cluster sur des machines différentes, chaque conteneur aura donc sa propre instance du singleton.
Globalement, les EJB de type Singleton permettent d'ajouter de nouvelles fonctionnalités aux EJBs :L'état de l'EJB est maintenu par le conteneur durant toute la durée de vie de l'application : cet état n'est pas persistant à l'arrêt de l'application ou de la JVM.
.
Lorsqu'une classe client veut appeler une méthode d'un bean singleton, le conteneur s'assure de créer l'instance ou d'utiliser celle qui existe déjà. Parfois cependant, l'initialisation d'un singleton peut être assez longue : Cache peut, par exemple, devoir accéder à une base de données pour charger un millier d'objets. En ce cas, le premier appel au bean prendra du temps et le premier client devra attendre la fin de son initialisation.
import javax.ejb.Singleton; @Singleton @Startup public class Cache { ... }
Dans certains cas, l'ordre explicite des initialisations peut avoir de l'importance lorsque nous utilisons plusieurs beans singletons.
@Singleton public class CodePays { ... }
@Singleton @DependsOn("CodePays") public class Cache { ... }
@DependsOn prend en paramètre une ou plusieurs chaînes désignant chacune le nom d'un bean singleton dont dépend le singleton annoté. Le code suivant, par exemple, montre que Cache dépend de l'initialisation de CodePays et de CodePostal :
@Singleton public class CodePostal { ... }
@Singleton public class CodePays { ... }
@DependsOn("CodePays", "CodePostal") @Startup @Singleton public class Cache { ... }
Comme vous pouvez le constater dans le code précédent, il vous est même possible de combiner ces dépendance avec une initialisation lors du démarrage de l'application : Cache étant initialisé dès le lancement (car il est annoté par @Startup), du coup CodePays et CodePostal le seront également, mais avant lui.
Un singleton n'ayant qu'une seule instance partagée par plusieurs clients, les accès concurrents peuvent être contrôlés de trois façons différentes :
La stratégie à suivre doit être précisée par l'annotation @ConcurrencyManagementqui peut donc prendre trois valeurs : ConcurrencyManagementType.CONTAINER, ConcurrencyManagementType.BEAN ou ConcurrencyManagementType.CURRENCY_NOT_ALLOWED. La première stratégie est celle proposée par défaut. Du coup, vous pouvez vous passer d'annoter le bean Singleton correspondant à ce cas de figure.
@Startup @Singleton @DependsOn("CodePays") @ConcurrencyManagement(ConcurrencyManagementType.BEAN) @Lock(LockType.READ) @AccessTimeout(15000) public class Cache { ... }
Avec CMC, la valeur par défaut, le conteneur est responsable du contrôle des accès concurrents à l'instance du bean singleton. Vous pouvez alors vous servir de l'annotation @Lock pour précisez le type de verrouillage :
import javax.ejb.Singleton; @Singleton @Lock(LockType.READ ) public class Cache { private Map<Element> stockage = new HashMap<String, Element>(); public void ajouterAuCache(String id, Element élément) { if (!stockage.containsKey(id)) stockage.put(id, élément); } public void enleverDuCache(String id) { if (stockage.containsKey(id)) stockage.remove(id); } @AccessTimeout(2000) @Lock(LockType.WRITE) public Element récupérerDuCache(String id) { if (stockage.containsKey(id)) return stockage.get(id); else return null; } }
Dans ce code, le bean Cache utilise un verrou READ, ce qui implique que toutes ses méthodes auront un verrou partagé, sauf pour récupérerDuCache() qui a été redéfinie à WRITE (exclusif). Vous remarquez également la présence de l'annotation @AccessTimeout sur cette méthode qui permet de limiter le temps pendant lequel un accès concurrent sera bloqué : si le verrou n'a pas pu être obtenu dans ce délai, la requête sera rejetée avec la levée de l'exception correspondante.
Avec BMC, le conteneur autorise tous les accès à l'instance du bean singleton. C'est donc le développeur qui doit protéger l'état contre les erreurs de synchronisation dues aux accès concurrents. Pour ce faire, il peut utiliser les primitives de synchronisation de Java, comme synchronized et volatile.
import javax.ejb.Singleton; @Singleton @ConcurrencyManagement(ConcurrencyManagementType.BEAN) public class Cache { private Map<Element> stockage = new HashMap<String, Element>(); public synchronized void ajouterAuCache(String id, Element élément) { if (!stockage.containsKey(id)) stockage.put(id, élément); } public void enleverDuCache(String id) { if (stockage.containsKey(id)) stockage.remove(id); } public synchronized Element récupérerDuCache(String id) { if (stockage.containsKey(id)) return stockage.get(id); else return null; } }
Les accès concurrents peuvent également être interdits sur une méthode ou sur l'ensemble du bean : en ce cas, un client appelant une méthode en cours d'utilisation par un autre client recevra l'exception ConcurrentAccessException. Ceci peut avoir des conséquences sur les performances puisque les clients devront gérer l'exception, réessayeront d'accéder au bean, etc.
import javax.ejb.Singleton; @Singleton @Lock(LockType.READ ) public class Cache { private Map<Element> stockage = new HashMap<String, Element>(); @ConcurrencyManagement(ConcurrencyManagementType.CONCURRENCY_NOT_ALLOWED ) public void ajouterAuCache(String id, Element élément) { if (!stockage.containsKey(id)) stockage.put(id, élément); } public void enleverDuCache(String id) { if (stockage.containsKey(id)) stockage.remove(id); } @AccessTimeout(2000 ) @Lock(LockType.WRITE ) public Element récupérerDuCache(String id) { if (stockage.containsKey(id)) return stockage.get(id); else return null; } }
Après tout ce petit descriptif, je vous propose d'illustrer ces nouveaux comportements au travers d'un projet. Nous allons reprendre le projet de conversion auquel nous rajoutons un historique des différents calculs proposés. Ainsi, côté serveur d'applications, nous conservons le service proposé par l'EJB qui traite la logique métier qui calcule la conversion entre les €uros et les Francs. Nous rajoutons un EJB Singleton qui gére l'historique des calculs. Côté client, une application Web est activée qui sera ensuite accessible à l'aide d'un simple navigateur. Dans votre navigateur une page Web apparaît afin de permettre la saisie des valeurs et le choix du type de conversion à réaliser suivi de l'affichage de l'historique.
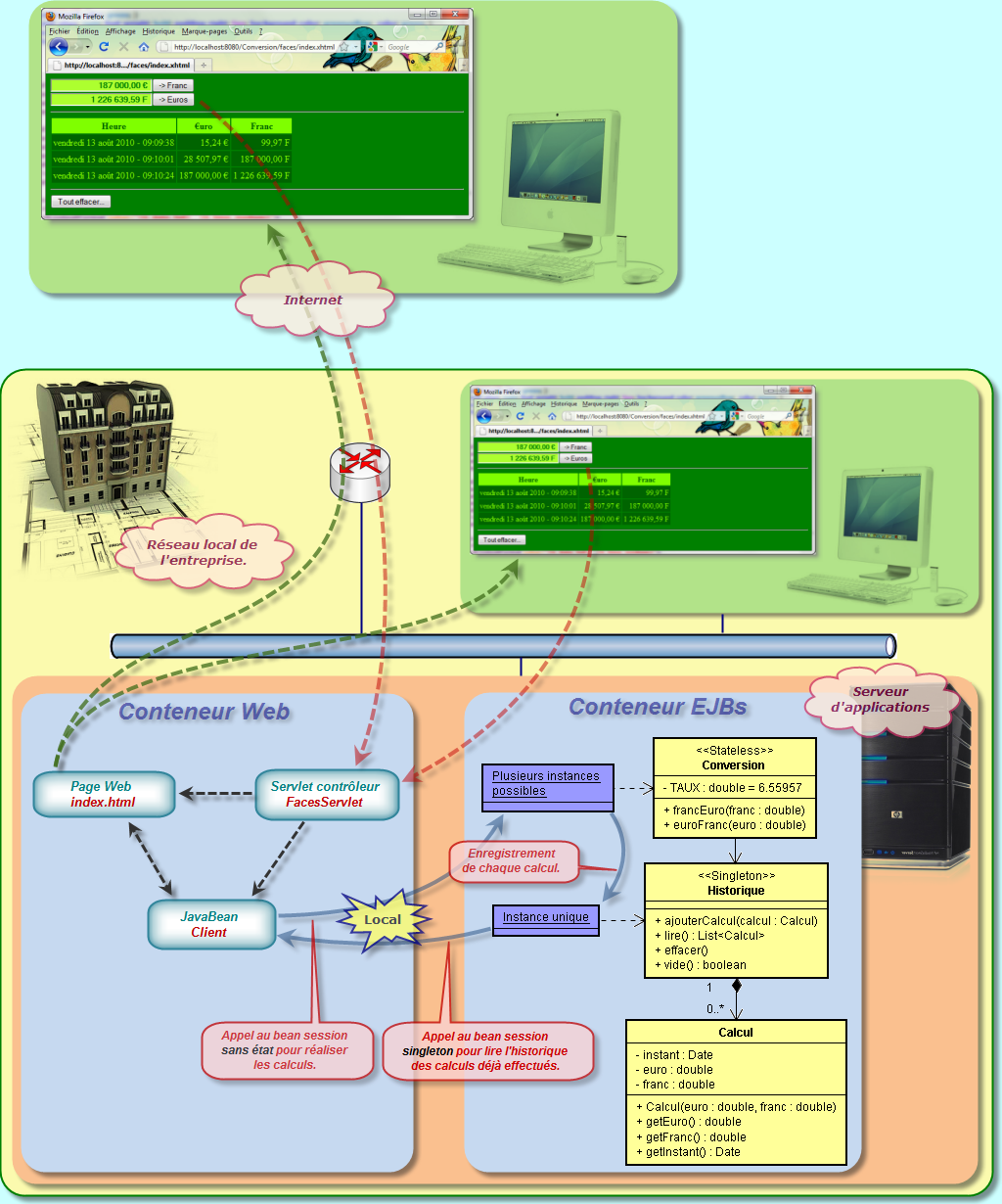
Maintenant, nous connaissons bien la structure d'une application Web qui est somme toute classique par rapport à ce que nous avons déja vu. La structure du conteneur EJB est par contre plus inhabituel :
Nous connaissons déjà bien le principe, puisque l'accès au conteneur EJB, quelque soit le client, se fait uniquement en local, nous pouvons intégrer ce module dans un projet de type application Web, ce qui est le plus simple à implémenter. C'est donc le choix que nous faisons dont voici l'ensemble du cheminement :
Nous réalisons notre étude en deux étapes ; le module EJB qui s'occupe du service global avec ses trois composants (un bean sans état, un bean singleton et une simple classe) et l'application Web qui fabrique l'IHM sous forme de pages Web dynamiques. Regardons plus précisément le côté service :
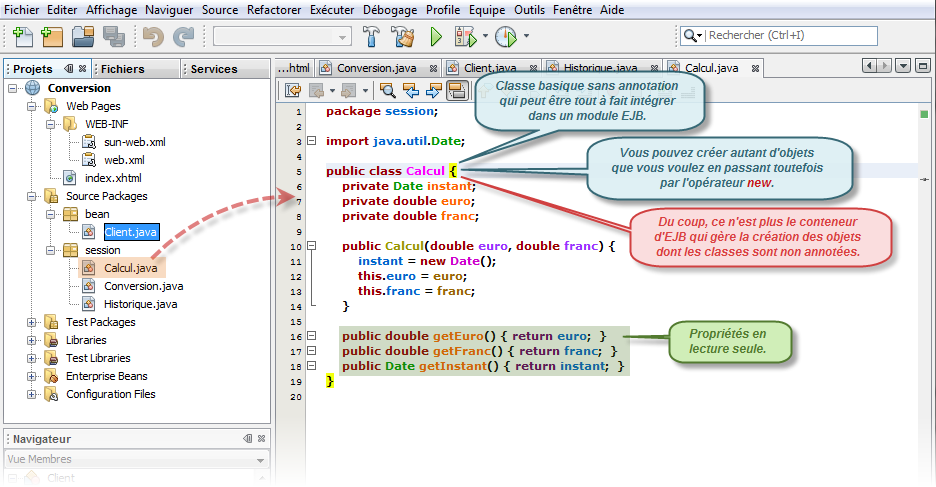
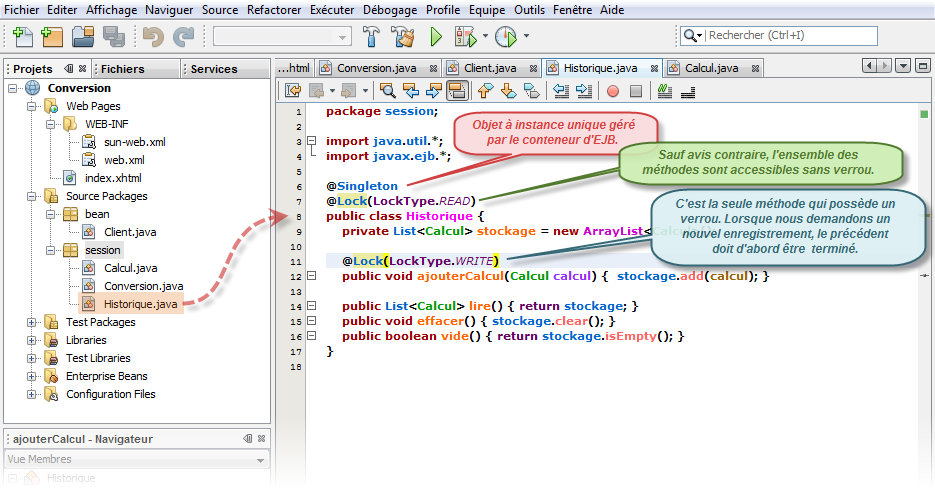
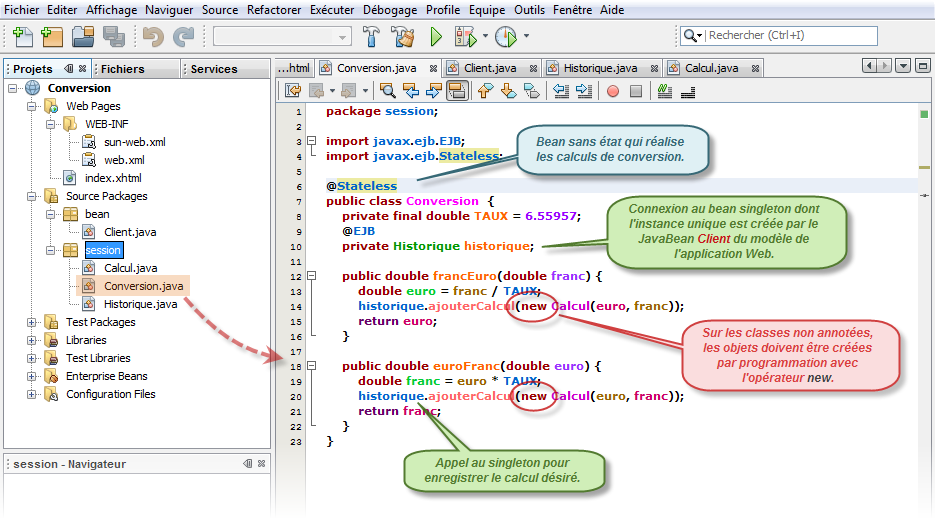
package session; import java.util.Date; public class Calcul { private Date instant; private double euro; private double franc; public Calcul(double euro, double franc) { instant = new Date(); this.euro = euro; this.franc = franc; } public double getEuro() { return euro; } public double getFranc() { return franc; } public Date getInstant() { return instant; } }
package session; import java.util.*; import javax.ejb.*; @Singleton @Lock(LockType.READ) public class Historique { private List<Calcul> stockage = new ArrayList<Calcul>(); @Lock(LockType.WRITE) public void ajouterCalcul(Calcul calcul) { stockage.add(calcul); } public List<Calcul> lire() { return stockage; } public void effacer() { stockage.clear(); } public boolean vide() { return stockage.isEmpty(); } }
package session; import javax.ejb.*; @Stateless public class Conversion { private final double TAUX = 6.55957; @EJB private Historique historique; public double francEuro(double franc) { double euro = franc / TAUX; historique.ajouterCalcul(new Calcul(euro, franc)); return euro; } public double euroFranc(double euro) { double franc = euro * TAUX; historique.ajouterCalcul(new Calcul(euro, franc)); return franc; } }
L'opérateur utilise un navigateur pour effectuer ses différents calculs. Pour cela, nous réalisons l'IHM qui permet la saisie des valeurs à soumettre avec l'affichage du résultat correspondant. Par la suite, nous devons communiquer avec le bean session sans état afin que ce dernier fasse tous les traitements souhaités suivant les requêtes soumises par l'opérateur, soit une conversion en Francs, soit une conversion en €uros. Enfin, si l'historique existe, il s'affiche automatiquement en dessous avec un bouton supplémentaire pour tout remettre à zéro éventuellement.
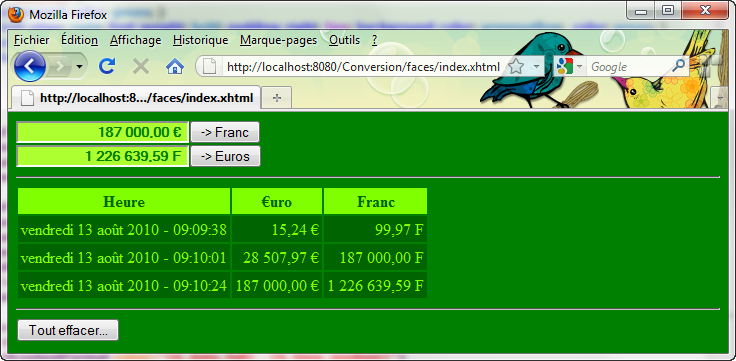
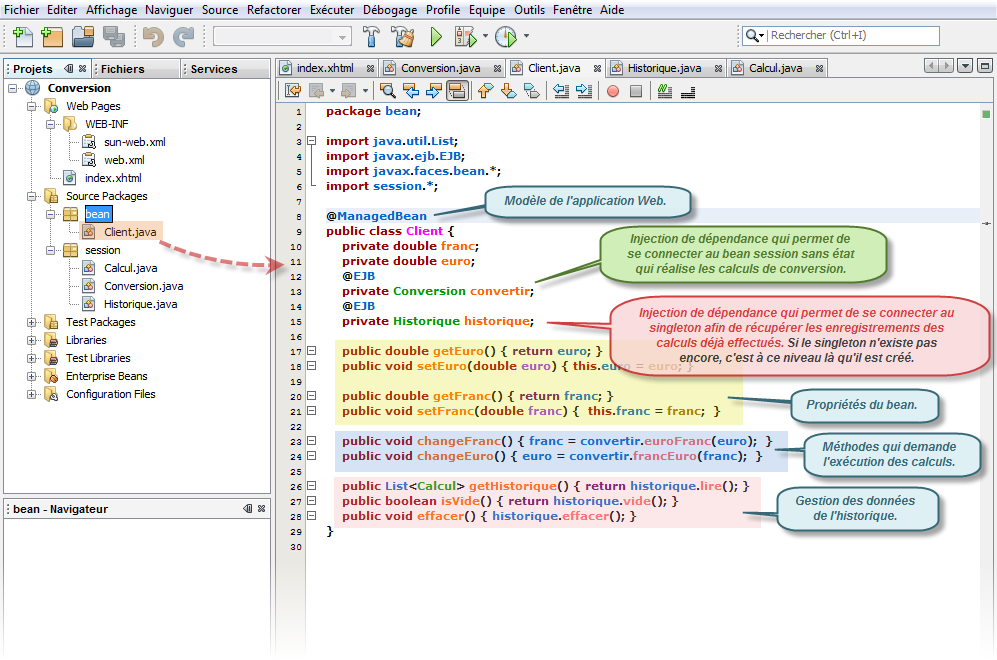

package bean; import java.util.List; import javax.ejb.EJB; import javax.faces.bean.*; import session.*; @ManagedBean public class Client { private double franc; private double euro; @EJB private Conversion convertir; @EJB private Historique historique; public double getEuro() { return euro; } public void setEuro(double euro) { this.euro = euro; } public double getFranc() { return franc; } public void setFranc(double franc) { this.franc = franc; } public void changeFranc() { franc = convertir.euroFranc(euro); } public void changeEuro() { euro = convertir.francEuro(franc); } public List<Calcul> getHistorique() { return historique.lire(); } public boolean isVide() { return historique.vide(); } public void effacer() { historique.effacer(); } }
<?xml version='1.0' encoding='UTF-8' ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns= xmlns:h= xmlns:f=> <style type=> body { background-color: green; } .saisie { text-align: right; font-weight: bold; padding-right: 5px; background-color: greenyellow; color: green; } .titre { background-color: chartreuse; color: darkgreen; } .lignes { background-color: darkgreen; color: chartreuse; text-align: right; } </style> <h:body> <h:form> <h:inputText value=#{client.euro} styleClass=saisie> <f:convertNumber type=/> </h:inputText> <h:commandButton action=#{client.changeFranc} value= /> <br /> <h:inputText value=#{client.franc} styleClass=saisie> <f:convertNumber type= currencySymbol= /> </h:inputText> <h:commandButton action=#{client.changeEuro} value= /> <h:panelGroup rendered=#{not client.vide}> <hr /> <h:dataTable var=calcul value=#{client.historique} rowClasses=lignes headerClass=titre cellpadding= cellspacing=> <h:column> <f:facet name=><h:outputText value= /></f:facet> <h:outputFormat value=> <f:param value=#{calcul.instant}/> </h:outputFormat> </h:column> <h:column> <f:facet name=><h:outputText value= /></f:facet> <h:outputFormat value=> <f:param value=#{calcul.euro}/> </h:outputFormat> </h:column> <h:column> <f:facet name=><h:outputText value= /></f:facet> <h:outputFormat value=> <f:param value=#{calcul.franc}/> </h:outputFormat> </h:column> </h:dataTable> <hr /> <h:commandButton value= action=#{client.effacer} /> </h:panelGroup> </h:form> </h:body> </html>
Faisons un petit retour en arrière. Nous avons déjà évoqué l'injection de dépendances, et vous la rencontrerez encore plusieurs fois. Il s'agit d'un mécanisme simple mais puissant utilisé par Java EE 6 pour injecter des références à toute sorte de ressources sur les attributs. Au lieu que l'application recherche les ressources dans JNDI, celles-ci sont injectées directement par le conteneur.
Les beans sessions sont des composants métiers résidant dans un conteneur. Généralement, il n'accède pas au conteneur et n'utilisent pas directement ses services (transactions, sécurités, injection de dépendances, etc.), qui sont prévus pour être gérés de façon transparente par le conteneur pour le compte du bean session.
Un bean session peut avoir accès à son contexte d'environnement en injectant une référence SessionContext à l'aide d'une annotation @Resource.
import javax.ejb.*; @Stateless public class CommandeLivre { @Resource private SessionContext session; public void commande(Livre commande) { ... if (rechercheNonAboutie()) session.setRollBackOnly(); } ... }
Les composants Java EE 6 utilisent une configuration par exception, ce qui signifie que le conteneur, le fournisseur de persistance ou le serveur de message appliqueront un ensemble de services par défaut à ces composants.
Si nous souhaitons disposer d'un comportement particulier, il faut explicitement utiliser une annotation ou son équivalent XML : c'est ce que nous avons déjà fait avec les beans sessions : une seule annotation (@Stateless, @Stateful, @Singleton, etc.) suffit pour que le conteneur applique certains services (transaction, cycle de vie, sécurité, intercepteurs, concurrence, asynchronisme, etc.) mais, si vous voulez les modifier, d'autres annotations et les descripteurs de déploiement XML permettent en effet d'attacher des informations supplémentaires à une classe, une interface, une méthode ou un attribut.
Un descripteur de déploiement XML est une alternative aux annotations, ce qui signifie que toute annotation possède un marqueur XML équivalent. Lorsque les deux mécanismes sont utilisés, la configuration décrite dans le descripteur de déploiement est priotritaire sur les annotations.
<ejb-jar> <enterprise-beans> <session> <ejb-name>Conversion</ejb-name> <ejb-class>session.Conversion</ejb-class> <remote>session.ConversionRemote</remote> <session-type>Stateless</session-type> <transaction-type>Container</transaction-type> <env-entry> <env-entry-name>TAUX</env-entry-name> <env-entry-type>java.lang.Double</env-entry-type> <env-entry-value>6.55957</env-entry-value> </env-entry> </session> </enterprise-beans> </ejb-jar>
Les paramètres des applications d'entreprise peuvent varier d'un déploiement à l'autre, en fonction par exemple de l'architecture des fichiers utilisés.
@Stateful @SatefulTimeout(20000) public class Archive implements ArchiveRemote { private final String répertoire = ; // nom du répertoire de stockage codé en dur ... @Override public String[] listeNomFichier() { return new File(répertoire).list(); } ... }
Comme vous l'aurez compris, coder en dur ce paramètre implique de modifier le code, de le recompiler et de redéployer le composant pour chaque changement de système de fichiers. Une autre possibilité consisterait à utiliser une base de données, mais cela gaspillerait des ressources pour pas grand chose. En réalité, nous désirons simplement stocker ce paramètre à un endroit où il pourra être modifié lors du déploiement : le descripteur de déploiement est donc un emplacement de choix.
Avec EJB 3.1, le descripteur de déploiement (ejb-jar.xml) est facultatif, mais son utilisation est justifiée lorsque nous avons des paramètres liés à l'environnement. Ces entrées peuvent en effet être placées dans le fichier et être accessibles via l'injection de dépendances (ou par JNDI). Elles peuvent être de type String, Character, Byte, Short, Integer, Long, Boolean, Double et Float.
<ejb-jar> <enterprise-beans> <session> <ejb-name>Archive</ejb-name> <env-entry> <env-entry-name>repertoire</env-entry-name> <env-entry-type>java.lang.String</env-entry-type> <env-entry-value>F:/Archivage/</env-entry-value> </env-entry> </session> </enterprise-beans> </ejb-jar>
Maintenant que les paramètres de l'application ont été externalisés dans le descripteur de déploiement, Archive peut utiliser l'injection de dépendances pour obtenir la valeur souhaitée pour la localisation du répertoire dans le système de fichiers en cours. Ainsi, l'annotation @Resource(name="repertoire") injecte la valeur de l'entrée repertoire dans l'attribut répertoire ; si les types de l'entrée et de l'attribut ne sont pas compatibles, le conteneur lève une exception.
@Stateful @SatefulTimeout(20000) public class Archive implements ArchiveRemote { @Resource(name = "repertoire") private final String répertoire; // nom du répertoire de stockage codé en dur ... @Override public String[] listeNomFichier() { return new File(répertoire).list(); } ... }
Toutes ces différentes rubriques nous seront bien utiles dans les sujets qui suivent, notamment les appels asynchrones.
A titre d'exemple, je vous propose de voir comment se connecter à un annuaire LDAP au travers de JNDI. Dans un premier temps, vous devez configurer votre serveur d'applications pour que ce dernier puisse intégrer une nouvelle ressource JNDI (externe) associée au service LDAP :

Voici, du coup le code source d'un bean session sans état qui permet de vérifier l'authentification d'un utilisateur potentiel (plusieurs classes sont utilisées ici pour faire des recherches adaptées dans l'annuaire LDAP que je ne commenterai pas) :
package ejb3; import com.sun.xml.wss.impl.misc.Base64; import java.security.*; import javax.annotation.Resource; import javax.ejb.Stateless; import javax.naming.*; import javax.naming.directory.*; @Stateless public class LdapBean implements LdapRemote { private String motDePasse = ; @Resource(mappedName="ConnexionLDAP") DirContext contexte; public boolean identification(String utilisateur, char[] passe) { try { SearchControls controle = new SearchControls(); controle.setSearchScope(SearchControls.SUBTREE_SCOPE); String critere = + utilisateur + ; NamingEnumeration<SearchResult> énumération = contexte.search(, critere, controle); if (énumération.hasMore()) { SearchResult résultat = énumération.next(); Attributes attributs = résultat.getAttributes(); motDePasse = new String((byte[]) attributs.get().get()); } MessageDigest sha = MessageDigest.getInstance(); byte[] digest = sha.digest(new String(passe).getBytes()); String pass = Base64.encode(digest); pass = + pass; return motDePasse.equals(pass); } catch (Exception ex) { return false; } } }
Par défaut, les appels des beans session via des vues distantes, locales et sans interface sont synchrones : un client qui appelle une méthode reste bloqué pendant la durée de cet appel. Un traitement asynchrone est donc souvent nécessaire lorsque l'application doit exécuter une opération qui dure longtemps.
L'impression d'une commande, par exemple, peut prendre beaucoup de temps si des dizaines de documents sont déjà dans la file d'attente de l'imprimante, mais un client qui appelle une méthode d'impression d'un document souhaite simplement déclencher un processus qui imprimera ce document, puis continuer son propre traitement.
Comme les threads ne peuvent pas être utilisés dans les EJB, une façon couramment utilisée de permettre une invocation asynchrone d'un EJB est de passer par un message JMS traité par un EJB de type MDB. Cependant, le rôle principal de JMS est l'échange de messages et pas l'invocation de fonctionnalités de façon asynchrone. De plus, cette solution n'est pas idylique car elle ne permet pas facilement d'avoir un retour à la fin des traitements réalisés.
Pour en savoir plus sur JMS et MDB.
L'invocation asynchrone peut être utilisée sur tous les types d'EJB session. Par ailleurs, l'annotation @Asynchronous peut aussi bien être utilisées sur une méthode de l'EJB ou sur la classe elle-même.
Le code ci-dessous montre le bean ValiderCommande qui dispose d'une méthode pour envoyer un e-mail à un client et d'une autre pour imprimer la commande. Ces deux méthodes durant longtemps, elles ont toutes les deux besoins d'être asynchrones. Si ce sont les deux seules méthodes de la classe, il est alors judicieux que ce soit la classe elle-même qui porte l'annotation @Asynchronous.
import javax.ejb.*; @Stateless @Asynchronous public class ValiderCommande { public void envoyerMail(Commande commande, Client client) { // envoi un e-mail } public void imprimerCommande(Commande commande) { // imprime la commande } }
Si par contre le bean ValiderCommande dispose d'autres méthodes qui doivent être appelées de façon synchrone, vous placez l'annotation @Asynchronous uniquement sur celles qui en ont besoin, comme envoyerMail() et imprimerCommande().
import javax.ejb.*; @Stateless public class ValiderCommande { @Asynchronous public void envoyerMail(Commande commande, Client client) { // envoi un e-mail } @Asynchronous public void imprimerCommande(Commande commande) { // imprime la commande } ... // Autres méthodes (synchrones) }
Un Future contient le résultat d'un calcul asynchrone. Un Future permet de démarrer un calcul, de donner le résultat à quelqu'un, puis de l'oublier. Lorsqu'il est prêt, le propriétaire de l'objet Future peut obtenir le résultat.
public interface Future<Value> { Value get() throws ...; Value get(long durée, TimeUnit unitéDeTemps) throws ...; boolean cancel(Boolean peutÊtreInterrompu); boolean isCancelled(); boolean isDone(); }
La classe javax.ejb.AsyncResult<V> est une implémentation fournie en standard de l'interface Future<V> qui propose notamment un constructeur qui attend la valeur de type V en paramètre.
La méthode wasCancelCancelled() de l'interface SessionContext renvoie true si le client a invoqué la méthode Future.cancel() avec la valeur true en paramètre.
.
L'exemple ci-dessous, côté serveur, effectue un traitement qui peut être interrompu par le client. La méthode historique() renvoie un String qui donne la liste des calculs effectués. Elle renvoie la liste complète si tout s'est déroulé correctement ou une partie de liste si une annulation est évoquée entre temps :
@Singleton @Lock(LockType.READ) public class Conversion implements ConversionRemote { private final double TAUX = 6.55957; private List<Calcul> stockage = new ArrayList<Calcul>(); @Resource(name = "nomFichier") private String nomFichier; @Resource SessionContext ctx; ... @Override @Asynchronous public Future<String> historique() { String motif = \n; StringBuilder résultat = new StringBuilder(); for (int i=0; i<stockage.size() && !ctx.wasCancelCalled(); i++) { Calcul calcul = stockage.get(i); résultat.append(MessageFormat.format(motif, calcul.getInstant(), calcul.getEuro(), calcul.getFranc())); } return new AsyncResult<String>(résultat.toString()); } ... }
Le client peut alors faire appel à cette méthode asynchrone historique(). Ensuite, dans un thread séparé, et à l'aide de la méthode blocante get() de Future, nous attendons le résultat de cet appel. Entre temps, il est possible d'écourter le traitement proposée par la méthode asynchrone historique() au moyen de la méthode cancel() de Future :
public class Client extends JFrame { private JTextArea historique = new JTextArea(10, 30); private JButton appel = new JButton(); private JButton annuler = new JButton(); ... @EJB private static ConversionRemote convertir; private Future<String> calculs; public Client() { super(); ... appel.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { calculs = convertir.historique(); // lance la méthode asynchrone new Thread(new Runnable() { @Override public void run() { try { historique.setText(calculs.get()); } catch (Exception ex) {} // récupère la valeur de la méthode asynchrone dans un thread séparé } }).start(); } }); annuler.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { calculs.cancel(true); // Il est possible côté client de proposer une annulation qui est pris en compte par la méthode asynchrone } }); ... } public static void main(String[] args) { new Client(); } }
Voilà pour les principes de base. Nous allons maintenant prendre en compte l'appel asynchrone au travers d'un projet d'entreprise. Nous allons reprendre le projet de conversion avec l'historique. Cette fois-ci, toutefois, l'historique sera rendu persistant au travers d'un fichier spécifique. Par ailleurs, côté serveur d'applications, la logique métier ainsi que la gestion de l'historique sera mis en oeuvre avec un seul bean session de type Singleton. Côté client, je propose également un nouveau changement en prenant cette fois-ci une application fenêtrée. Le client ne pourra donc s'exécuter que dans le réseau local de l'entreprise.
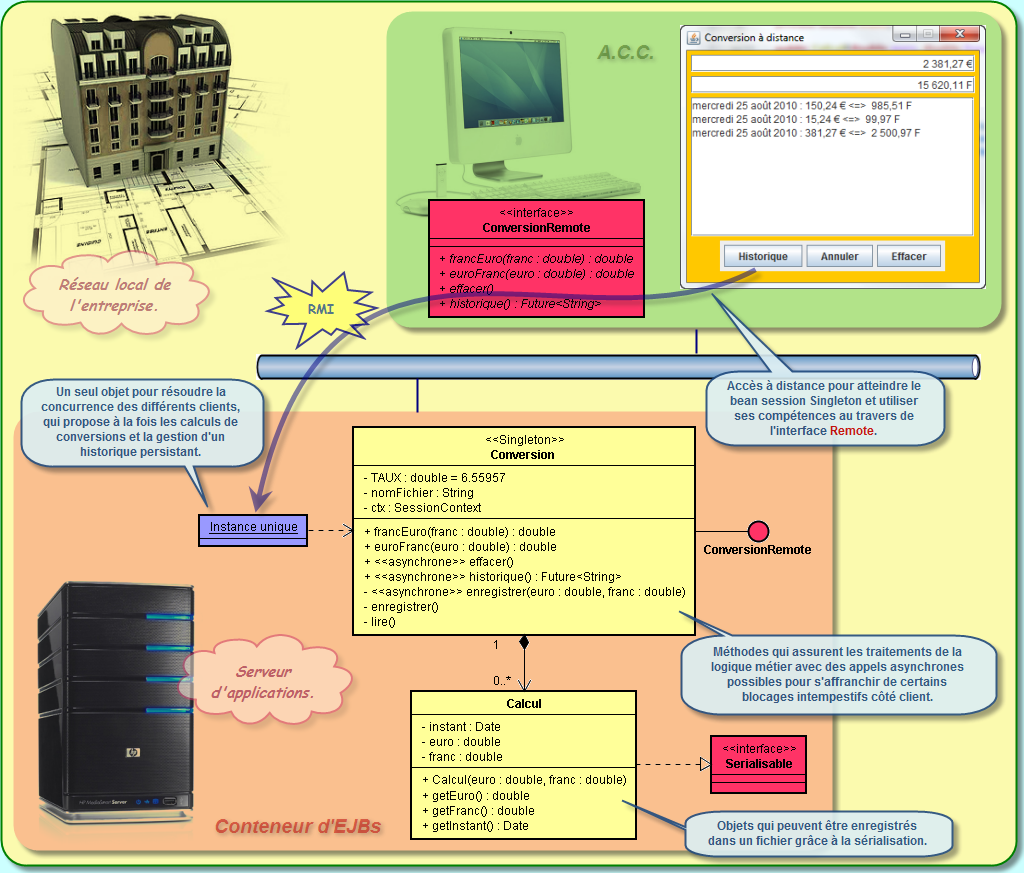
Maintenant, nous n'avons plus qu'un seul projet global à réaliser pour que l'injection de dépendance puisse se faire correctement. Ce projet global d'entreprise est en réalité une fusion de deux autres projets. D'une part, comme précédemment, le projet qui consiste à la création du module EJB dont le contenu comporte notre bean session Singleton qui va calculer la conversion entre les euros et les francs et gérer correctement la persistance de l'historique. D'autre part, le projet concernant l'application cliente qui possède une IHM qui va permettre la saisie des valeurs à soumettre au bean session avec l'affichage du résultat correspondant.
Nous réalisons notre étude en deux étapes ; d'une part le module EJB qui s'occupe du service global avec cette fois-ci uniquement deux composants (un bean singleton avec son interface métier et une simple classe) ; d'autre part l'application fenêtrée. Par rapport au projet précédent, nous utilisons un seul bean qui réalise à la fois le traitement de conversions et la gestion de l'historique persistant.
package session; import java.io.Serializable; import java.util.Date; public class Calcul implements Serializable { private Date instant; private double euro; private double franc; public Calcul(double euro, double franc) { instant = new Date(); this.euro = euro; this.franc = franc; } public double getEuro() { return euro; } public double getFranc() { return franc; } public Date getInstant() { return instant; } }
Nous retrouvons notre classe qui sert d'élément unitaire de stockage pour l'historique, avec une petite nouveauté toutefois par rapport au projet précédent, c'est que cette classe peut être enregistrée directement dans un fichier grâce à l'implémentation de la sérialisation.
package session; import java.util.concurrent.Future; import javax.ejb.Remote; @Remote public interface ConversionRemote { double francEuro(double franc); double euroFranc(double euro); void effacer(); Future<String> historique(); }
Puisque notre accès se fait à distance dans le réseau local de l'entreprise, nous devons implémenter une interface métier qui va nous préciser les méthodes accessibles depuis l'application cliente fenêtrée. Mise à part les types de retour, nous retrouvons les mêmes fonctionnalités que le projet précédent.
<?xml version="1.0" encoding="UTF-8"?> <ejb-jar> <enterprise-beans> <session> <ejb-name>Conversion</ejb-name> <env-entry> <env-entry-name>nomFichier</env-entry-name> <env-entry-type>java.lang.String</env-entry-type> <env-entry-value>F:/Archivage/Historique.sto</env-entry-value> </env-entry> </session> </enterprise-beans> </ejb-jar>
Plutôt que de coder en dur le nom du fichier dans le bean Singleton avec son emplacement dans le système de fichiers, il est souhaitable de proposer un fichier de configuration qui nous permettra par la suite de changer plus facilement le nom de ce fichier, sans avoir besoin de recompiler l'ensemble du module EJB. Il suffira d'effectuer un simple redéploiement.
package session; import java.io.*; import java.text.MessageFormat; import java.util.*; import java.util.concurrent.Future; import javax.annotation.Resource; import javax.ejb.*; @Singleton @Lock(LockType.READ) public class Conversion implements ConversionRemote { private final double TAUX = 6.55957; private List<Calcul> stockage = new ArrayList<Calcul>(); @Resource(name = "nomFichier") private String nomFichier; @Resource SessionContext ctx; @Override public double francEuro(double franc) { double euro = franc / TAUX; enregistrer(euro, franc); return euro; } @Override public double euroFranc(double euro) { double franc = euro * TAUX; enregistrer(euro, franc); return franc; } @Override @Asynchronous public void effacer() { stockage.clear(); enregistrer(); } @Override @Asynchronous public Future<String> historique() { String motif = \n; StringBuilder résultat = new StringBuilder(); lire(); for (int i=0; i<stockage.size() && !ctx.wasCancelCalled(); i++) { Calcul calcul = stockage.get(i); résultat.append(MessageFormat.format(motif, calcul.getInstant(), calcul.getEuro(), calcul.getFranc())); try { Thread.sleep(1000); } catch (InterruptedException ex) {} // ligne inutile mais qui permet de valider les concepts sur l'asynchronisme } return new AsyncResult<String>(résultat.toString()); } @Asynchronous private void enregistrer(double euro, double franc) { stockage.add(new Calcul(euro, franc)); enregistrer(); } private void enregistrer() { try { ObjectOutputStream fichier = new ObjectOutputStream(new FileOutputStream(nomFichier)); fichier.writeObject(stockage); fichier.close(); } catch (IOException ex) { } } private void lire() { try { ObjectInputStream fichier = new ObjectInputStream(new FileInputStream(nomFichier)); stockage = (List<Calcul>) fichier.readObject(); fichier.close(); } catch (Exception ex) { } } }
Passons maintenant dans le vif du sujet et analysons plus particulièrement ce code source :
J'ai rajouté une ligne totalement inutile qui met une pause de une seconde à chaque calcul élémentaire de l'itérative pour que nous ayons le temps, côté client, de demander la liste de l'historique et de pouvoir ensuite l'interrompre à tout moment. C'est juste un cas d'école vu que tout le traitement de cette méthode ne prend finalement que très peu de temps.
L'opérateur utilise une petite application graphique fenêtrée pour effectuer ses différents calculs. Pour cela, nous réalisons l'IHM qui permet la saisie des valeurs à soumettre avec l'affichage du résultat correspondant. Par la suite, nous devons communiquer avec le bean session Singleton afin que ce dernier fasse tous les traitements souhaités suivant les requêtes soumises par l'opérateur, soit une conversion en Francs, soit une conversion en €uros. Nous avons aussi la possibilité de visualiser l'ensemble de l'historique des calculs déjà réalisés avec une éventuelle annulation. Pour finir, l'historique peut être complètement remis à zéro.
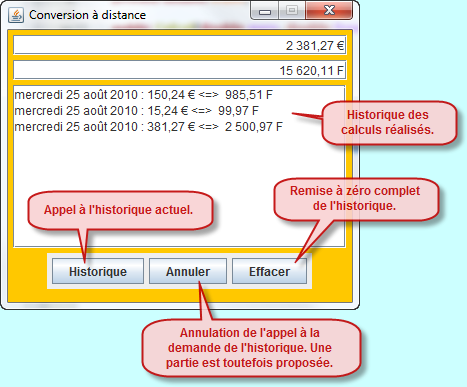
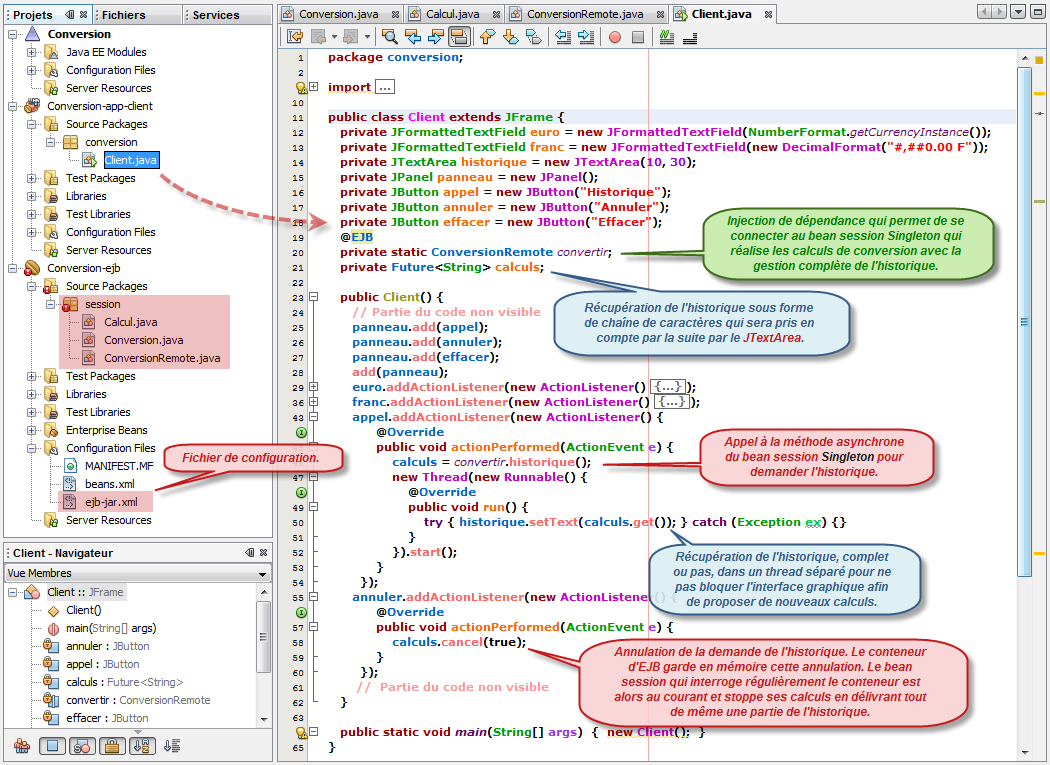
package conversion; import java.awt.*; import java.awt.event.*; import java.text.*; import java.util.concurrent.*; import javax.ejb.EJB; import javax.swing.*; import session.ConversionRemote; public class Client extends JFrame { private JFormattedTextField euro = new JFormattedTextField(NumberFormat.getCurrencyInstance()); private JFormattedTextField franc = new JFormattedTextField(new DecimalFormat()); private JTextArea historique = new JTextArea(10, 30); private JPanel panneau = new JPanel(); private JButton appel = new JButton(); private JButton annuler = new JButton(); private JButton effacer = new JButton(); @EJB private static ConversionRemote convertir; private Future<String> calculs; public Client() { super(); setLayout(new FlowLayout()); euro.setColumns(30); euro.setHorizontalAlignment(JFormattedTextField.RIGHT); euro.setValue(0); add(euro); franc.setColumns(30); franc.setHorizontalAlignment(JFormattedTextField.RIGHT); franc.setValue(0); add(franc); add(new JScrollPane(historique)); getContentPane().setBackground(Color.ORANGE); panneau.add(appel); panneau.add(annuler); panneau.add(effacer); add(panneau); euro.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { Number valeur = (Number) euro.getValue(); franc.setValue(convertir.euroFranc(valeur.doubleValue())); } }); franc.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { Number valeur = (Number) franc.getValue(); euro.setValue(convertir.francEuro(valeur.doubleValue())); } }); appel.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { calculs = convertir.historique(); new Thread(new Runnable() { @Override public void run() { try { historique.setText(calculs.get()); } catch (Exception ex) {} } }).start(); } }); annuler.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { calculs.cancel(true); } }); effacer.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { convertir.effacer(); historique.setText(); } }); getContentPane().setBackground(Color.orange); setSize(350, 300); setResizable(false); setDefaultCloseOperation(EXIT_ON_CLOSE); setVisible(true); } public static void main(String[] args) { new Client(); } }
Tous les chapitres précédents ont montré que les beans sont des composants gérés par un conteneur. Ils résident dans un conteneur qui encapsule le code métier avec plusieurs services annexes (injection de dépendances, gestion des transactions, de la sécurité, etc.). La gestion du cycle de vie et l'interception font également partie de ces services :
Tout d'abord, pour exploiter correctement un bean session, celui-ci doit être instancié, c'est-à-dire que le conteneur d'EJB fabrique l'objet correspondant à la classe du bean en question. De façon très simplifiée, le conteneur crée l'objet grâce à l'appel de la méthode newInstance(). Celle-ci est disponible à partir de l'objet Class lié à la classe du bean session : session.Conversion.class.newInstance();
Effectivement, comme nous l'avons découvert tout au long de cette étude, un client ne crée pas une instance d'un bean session à l'aide de l'opérateur new : il obtient une référence à ce bean via l'injection de dépendances ou par recherche JNDI. C'est le conteneur qui crée l'instance et qui la détruit, ce qui signifie que ni le client ni le bean ne sont responsables du moment où l'instance est créée, où les dépendances sont injectées et où l'instance est supprimée. La responsabilité de la gestion du cycle de vie du bean incombe au conteneur. C'est ce qui en fait l'extrême facilité de conception.
Attention, comme tout JavaBean, qu'il soit entreprise ou pas, ceci implique que la classe d'implémentation du bean session dispose d'un constructeur public par défaut, c'est-à-dire sans argument.
Tous les beans session passent par deux phases évidentes de leur cycle de vie : leur création et leur destruction. En outre, les beans avec état passent par des phases de passivation et d'activation que nous avons décrites dans un des chapitres précédents.
Les beans sans état et singleton partagent la même caractéristique de ne pas mémoriser l'état conversationnel avec leur client et d'autoriser leur accès par n'importe quel client - les beans sans état le font en série, instance par instance, alors que les singletons fournissent un accès concurrent à une seule instance. Tous les deux partagent le cycle de vie suivant :
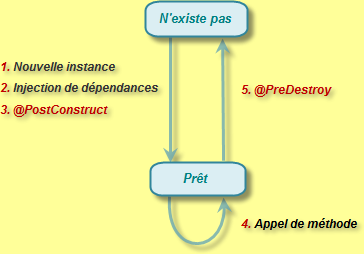
Bien qu'ils partagent le même cycle de vie, les beans sans état et singletons ne sont pas créés et détruits de la même façon :
GlassFish permet de paramétrer le pool des EJB. Vous pouvez ainsi fixer une taille (nombre initial, minimal et maximal de beans dans le pool), le nombre de beans à supprimer du pool lorsque son temps d'inactivité a expiré et le nombre de millisecondes du délai d'expiration du pool.
Du point de vue du programme, les beans session avec état ne sont pas très différents des beans sans état ou singletons. La véritable différence réside dans le fait que les beans avec état mémorisent l'état conversationnel avec leurs clients et qu'ils ont donc un cycle de vie légèrement différent. Le conteneur produit une instance et ne l'affecte qu'à un seul client. Ensuite, chaque requête de ce client sera transmise à la même instance.
Ceci signifie donc que les attributs du bean doivent être sérialisables (donc être d'un type primitif ou qui implémente l'interface java.io.Serializable).
.
Le cycle de vie d'un bean avec état passe donc par les étapes suivantes :

Dans certains cas, un bean contient des ressources ouvertes comme des sockets ou des connexions de base de données. Un conteneur ne pouvant garder ces ressources ouvertes pour chaque bean, vous devez fermer et rouvrir ces ressources avant et après la passivation : c'est là que les méthodes de rappel interviennent.
Comme nous venons de le voir, le cycle de vie de chaque bean session est géré par son conteneur. Ce dernier permet de greffer du code métier aux différentes phases de ce cycle : les passages d'un état à l'autre sont alors interceptés par le conteneur, qui appelera suivant les cas les méthodes annotées suivantes :
void <nom-méthode>();
et respecter les règles suivantes :
Nous allons juste changer le comportement global du bean Singleton du projet précédent. Ce bean est maintenant actif dès le déploiement de l'application sur le serveur. Pour minimiser les temps de stockage et de recherche, nous désirons prévoir la persistance que dans le seul cas où nous arrêtons le serveur d'applications. En fonctionnement normal, l'ensemble du stockage des calculs s'effectue uniquement en mémoire.
package session; import java.io.*; import java.text.MessageFormat; import java.util.*; import java.util.concurrent.Future; import javax.annotation.Resource; import javax.ejb.*; @Singleton @Startup @Lock(LockType.READ) public class Conversion implements ConversionRemote { private final double TAUX = 6.55957; private List<Calcul> stockage = new ArrayList<Calcul>(); @Resource(name = "nomFichier") private String nomFichier; @Resource SessionContext ctx; @Override public double francEuro(double franc) { double euro = franc / TAUX; enregistrer(euro, franc); return euro; } @Override public double euroFranc(double euro) { double franc = euro * TAUX; enregistrer(euro, franc); return franc; } @Override @Asynchronous public void effacer() { stockage.clear(); } @Override @Asynchronous public Future<String> historique() { String motif = \n; StringBuilder résultat = new StringBuilder(); for (int i=0; i<stockage.size() && !ctx.wasCancelCalled(); i++) { Calcul calcul = stockage.get(i); résultat.append(MessageFormat.format(motif, calcul.getInstant(), calcul.getEuro(), calcul.getFranc())); } return new AsyncResult<String>(résultat.toString()); } @Asynchronous private void enregistrer(double euro, double franc) { stockage.add(new Calcul(euro, franc)); } @PreDestroy private void enregistrer() { try { ObjectOutputStream fichier = new ObjectOutputStream(new FileOutputStream(nomFichier)); fichier.writeObject(stockage); fichier.close(); } catch (IOException ex) { } } @PostConstruct private void lire() { try { ObjectInputStream fichier = new ObjectInputStream(new FileInputStream(nomFichier)); stockage = (List<Calcul>) fichier.readObject(); fichier.close(); } catch (Exception ex) { } } }
Il faut également penser à rajouter l'annotation @Startup sur le bean lui-même pour que ce dernier soit opérationnel dès le départ et qu'il récupère les enregistrements de tous les calculs déjà effectués.
Si, au lieu d'avoir un bean singleton, nous avions un bean avec état pour mémoriser les calculs de chacun des clients, voici alors les modifications à apporter :package session; import java.io.*; import java.text.MessageFormat; import java.util.*; import java.util.concurrent.Future; import javax.annotation.Resource; import javax.ejb.*; @Stateful public class Conversion implements ConversionRemote { private List<Calcul> stockage = new ArrayList<Calcul>(); ... @PreDestroy @PrePassivate private void enregistrer() { try { ObjectOutputStream fichier = new ObjectOutputStream(new FileOutputStream(nomFichier)); fichier.writeObject(stockage); fichier.close(); } catch (IOException ex) { } } @PostConstruct @PostActivate private void lire() { try { ObjectInputStream fichier = new ObjectInputStream(new FileInputStream(nomFichier)); stockage = (List<Calcul>) fichier.readObject(); fichier.close(); } catch (Exception ex) { } } @Remove public void interrompre() { } }
Nous rajoutons simplement les annotations @PostActivate et @PrePassivate sur les mêmes méthodes lire() et enregistrer() et nous rajontons une méthode vide interrompre() précédée cette fois-ci de l'annotation @Remove. Cette dernière doit alors être explicitement appelée par le client pour bien spécifier que le bean session ne lui est plus utile. Auquel cas, le conteneur détruira cet objet attitré au client, en passant au préalable par la phase de @PreDestroy qui correspond à l'enregistrement du fichier.
En toute rigueur, ce code n'est pas du tout adapté à ce genre de situation. Il s'agit juste d'un cas d'école. Il faudrait plutôt mettre en place un système de consignation pour chaque client avec donc un fichier journal séparé pour chaque client, ce qui, vous vous en doutez, provoquerez une saturation rapide des ressources matérielles.
Remarquez, par contre, que l'application cliente ne gère absolument pas les appels de méthodes automatiques @PostConstruct et @PreDestroy. C'est le conteneur d'EJB qui le gère tout seul, sans avoir besoin de nous en préoccuper par la suite.
Les EJB offrent la possibilité de capturer les appels de méthodes à l'aide d'intercepteurs, qui seront automatiquements déclenchés par le conteneur lorsqu'une méthode EJB est invoquée.

En fait, vous pouvez considérer qu'un conteneur d'EJB est lui-même une chaînes d'intercepteurs : lorsque vous développez un bean session, vous vous concentrez sur le code métier mais, en coulisse, le conteneur intercepte les appels de méthodes effectués par le client et applique différents services (gestion du cycle de vie, transactions, sécurités, etc.). Grâce aux intercepteurs, vous pouvez ajouter vos propres traitements transverses et les appliquer au code métier de façon transparente.
Il existe trois types d'intercepteurs :
Le moyen le plus simple de définir un intercepteur consiste à ajuter une annotation @javax.interceptor.AroundInvoke (ou l'élément de déploiement <arround-invoque>) dans le bean lui-même.
@AroundInvoke
public Object nomDeMéthode(InvocationContext ctx) throw Exception {
...
}
Une méthode intercepteur autour des appels doit respecter également les règles suivantes :
L'objet représentant InvocationContext permet aux intercepteurs de contrôler le comportement de la chaîne des appels. Lorsque plusieurs intercepteurs sont chaînés, c'est la même instance d'InvocationContext qui est passé à chacun d'eux, ce qui peut impliquer un traitement de ces données contextuelles par les autres intercepteurs.
InvocationContext est en réalité une interface dont voici la signature :
package javax.ejb; public interface InvocationContext { public Object getTarget(); public java.lang.reflect.Method getMethod(); public Object[] getParameters(); public void setParameters(Object[] params); public EJBContext getEJBContext(); public java.util.Map<String, Object> getContextData(); public Object proceed() throw Exception; }
A titre d'exemple, reprenons le projet sur l'archivage :
Sur le bean session stateful Archive nous rajoutons une méthode gestionDesAppelsDeMéthode() qui va contrôler l'ordre des appels des différentes méthodes utilisées pour le transfert des blocs d'octets. Il faut effectivement vérifier que la méthode sauvegarde() est bien appelée avant de faire référence à la méthode envoiOctets(). De la même façon, nous vérifions l'ordre entre la méthode restituer() et la méthode recupereOctets(). Si l'ordre d'appels n'est pas respecté une exception est alors lancée pour que le client soit bien prévenu que l'utilisation du bean session est mal exploité.
package session; import java.io.*; import javax.annotation.Resource; import javax.ejb.*; import javax.interceptor.*; @Stateful @StatefulTimeout(20000) // délai d'expiration public class Archive implements ArchiveRemote { @Resource(name=) private String répertoire; @Resource(name=) private int BUFFER; private String nomFichier; private BufferedOutputStream enregistrement; private BufferedInputStream lecture; private int taille; private int nombre; private boolean sauvegarder, récupérer; @Override public int getBuffer() { return BUFFER; } @Override public String[] listeNomFichier() { return new File(répertoire).list(); } @Override public void suppression(String nomFichier) { new File(répertoire+nomFichier).delete(); } @Override public int sauvegarde(String nomFichier, int taille) throws IOException { this.nomFichier = nomFichier; enregistrement = new BufferedOutputStream(new FileOutputStream(répertoire + nomFichier)); this.taille = taille; return nombre = this.taille / BUFFER; } @Override public void envoiOctets(byte[] octets) throws IOException { enregistrement.write(octets); nombre--; if (nombre<0) { enregistrement.close(); sauvegarder = false; } } @Override public int restituer(String nomFichier) throws IOException { lecture = new BufferedInputStream(new FileInputStream(répertoire+nomFichier)); return lecture.available(); } @Override public byte[] recupereOctets() throws IOException { byte[] octets = lecture.available() >= BUFFER ? new byte[BUFFER] : new byte[lecture.available()]; lecture.read(octets); if (lecture.available() <= 0) { lecture.close(); récupérer = false; } return octets; } @Remove // expiration du bean session à l'issu de l'exécution de cette méthode public void annuler() throws IOException { lecture.close(); enregistrement.close(); } @AroundInvoke // Intercepteur autour des appels de méthode public Object gestionDesAppelsDeMéthode(InvocationContext ctx) throws Exception { String nomMéthode = ctx.getMethod().getName(); if (nomMéthode.equals()) sauvegarder = true; if (nomMéthode.equals() && !sauvegarder) throw new Exception(); if (nomMéthode.equals()) récupérer = true; if (nomMéthode.equals() && !récupérer) throw new Exception(); return ctx.proceed(); } }
<?xml version="1.0" encoding="UTF-8"?> <ejb-jar xmlns = "http://java.sun.com/xml/ns/javaee" version = "3.1" xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation = "http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/ejb-jar_3_1.xsd"> <enterprise-beans> <session> <ejb-name>Archive</ejb-name> <env-entry> <env-entry-name>repertoire</env-entry-name> <env-entry-type>java.lang.String</env-entry-type> <env-entry-value>F:/Archivage/</env-entry-value> </env-entry> <env-entry> <env-entry-name>buffer</env-entry-name> <env-entry-type>java.lang.Integer</env-entry-type> <env-entry-value>4096</env-entry-value> </env-entry> </session> </enterprise-beans> </ejb-jar>
Maintenant, lorsque le client effectue un appel sur la méthode qu'il désire, c'est d'abord la méthode gestionDesAppelsDeMéthode() qui est appelée. Ensuite, grâce à la méthode proceed(), la méthode souhaitée par le client est effectivement exécutée, à moins qu'une exception soit lancée, bien entendu.
Décrivons plus précisément l'ordre des différentes exécutions pour examiner ce qui se passe lorsqu'un client invoque la méthode sauvegarde() par exemple :
Cet appel est très important car, sans lui, la chaîne des intercepteurs serait rompue et la méthode métier ne serait plus du tout appelée.
.
Nous aurions pu rajouté quelques fonctionnalités supplémentaires.
.
L'étude précédente définit un intercepteur qui n'est disponible que pour le bean session Archive, mais la plupart du temps, nous souhaitons isoler un traitement transverse dans une classe distincte et demander au conteneur d'intercepter les appels de méthodes de plusieurs beans session.
L'enregistrement de journaux est un exemple typique de situation dans laquelle nous désirons enregistrer les entrées et les sorties de toutes les méthodes de tous les EJB. Pour disposer de ce type d'intercepteur, nous devons créer une classe distincte et informer le conteneur de l'appliquer à un bean précis ou à une méthode de bean particulière.
Le code suivant isole la méthode appels() dans une classe à part, Journal, qui est un simple POJO disposant d'une méthode annotée par @AroundInvoke
.
package session; import java.util.logging.*; import javax.interceptor.*; public class Journal { private Logger consignation = Logger.getLogger(); public Journal() { consignation.setLevel(Level.FINER); consignation.setUseParentHandlers(false); Handler console = new ConsoleHandler(); console.setLevel(Level.FINER); consignation.addHandler(console); } @AroundInvoke public Object appels(InvocationContext ctx) throws Exception { consignation.entering(ctx.getTarget().toString(), ctx.getMethod().toString()); try { return ctx.proceed(); } finally { consignation.exiting(ctx.getTarget().toString(), ctx.getMethod().toString()); } } }
Journal peut maintenant être utilisée de façon transparente par n'importe quel EJB souhaitant disposer d'un intercepteur. Pour ce faire, le bean doit informer le conteneur avec l'annotation @javax.interceptor.Interceptors :
package session; import java.io.*; import java.text.MessageFormat; import java.util.*; import java.util.concurrent.Future; import javax.annotation.Resource; import javax.ejb.*; @Singleton @Startup @Lock(LockType.READ) public class Conversion implements ConversionRemote { private final double TAUX = 6.55957; private List<Calcul> stockage = new ArrayList<Calcul>(); @Resource(name = "nomFichier") private String nomFichier; @Resource SessionContext ctx; @Override @Interceptors(Journal.class) public double francEuro(double franc) { double euro = franc / TAUX; enregistrer(euro, franc); return euro; } @Override @Interceptors(Journal.class) public double euroFranc(double euro) { double franc = euro * TAUX; enregistrer(euro, franc); return franc; } @Override @Asynchronous public void effacer() { stockage.clear(); } @Override @Asynchronous public Future<String> historique() { String motif = \n; StringBuilder résultat = new StringBuilder(); for (int i=0; i<stockage.size() && !ctx.wasCancelCalled(); i++) { Calcul calcul = stockage.get(i); résultat.append(MessageFormat.format(motif, calcul.getInstant(), calcul.getEuro(), calcul.getFranc())); } return new AsyncResult<String>(résultat.toString()); } @Asynchronous private void enregistrer(double euro, double franc) { stockage.add(new Calcul(euro, franc)); } @PreDestroy private void enregistrer() { try { ObjectOutputStream fichier = new ObjectOutputStream(new FileOutputStream(nomFichier)); fichier.writeObject(stockage); fichier.close(); } catch (IOException ex) { } } @PostConstruct private void lire() { try { ObjectInputStream fichier = new ObjectInputStream(new FileInputStream(nomFichier)); stockage = (List<Calcul>) fichier.readObject(); fichier.close(); } catch (Exception ex) { } } }
Maintenant, dans ce bean Conversion, cette annoation est placée sur les méthodes francEuro() et euroFranc(), ce qui signifie que tous les appels sur ces méthodes spécifiques seront interceptées par le conteneur qui invoquera la classe Journal pour consigner les entrées et les sorties.
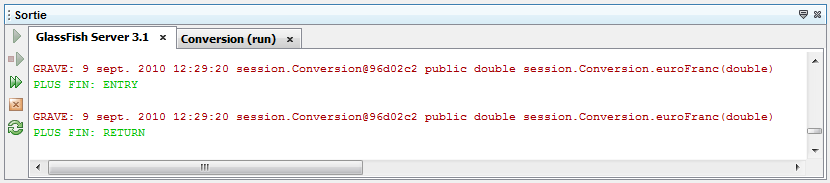
Si vous désirez que toutes les méthodes soient interceptées, vous placez l'annotation sur le bean lui-même :
@Singleton @Startup @Lock(LockType.READ) @Interceptors(Journal.class) public class Conversion implements ConversionRemote { ... public double francEuro(double franc) { ... } public double euroFranc(double euro) { ... } public void effacer() { ... } public Future<String> historique() { ... } private void enregistrer(double euro, double franc) { ... } private void enregistrer() { ... } private void lire() { ... } }
Si vous désirez que toutes les méthodes, sauf quelques unes, soient interceptées, utilisez l'annotation javax.interceptor.ExcludeClassInterceptors pour exclure les méthodes concernées :
@Singleton @Startup @Lock(LockType.READ) @Interceptors(Journal.class) public class Conversion implements ConversionRemote { ... public double francEuro(double franc) { ... } public double euroFranc(double euro) { ... } @ExcludeClassInterceptors public void effacer() { ... } public Future<String> historique() { ... } private void enregistrer(double euro, double franc) { ... } private void enregistrer() { ... } private void lire() { ... } }
Dans ce code, l'appel à effacer() ne sera pas intercepté alors que les appels à toutes les autres méthodes publiques le seront.
.
Dans la première partie de ce chapitre, nous avons vu comment gérer les méthodes de rappel dans un EJB. Avec une annotation de rappel, vous pouvez demander au conteneur d'appeler une méthode lors d'une phase précise du cycle de vie (@PostConstruct, @PrePassivate, @PostActivate et @PreDestroy).
Si vous souhaitez, par exemple, ajouter une entrée dans un journal à chaque fois qu'une instance d'un bean est créée, il suffit de placer l'annotation @PostConstruct sur une méthode du bean et d'ajouter un peu de code pour enregistrer l'entrée dans le journal.
Mais comment faire pour capturer les événements du cycle de vie entre plusieurs types de bean ? Les intercepteurs du cycle de vie permettent d'isoler du code dans une classe et de l'invoquer lorsque l'un de ces événements se déclenche.
Par exemple, la classe CycleVie proposent deux méthodes : début(), qui sera appelée après la construction d'une instance et fin(), qui sera invoquée avant la destruction de la classe.
package session; import java.util.logging.*; import javax.annotation.*; import javax.interceptor.InvocationContext; public class CycleVie { private Logger consignation = Logger.getLogger(); public CycleVie() { consignation.setLevel(Level.FINER); consignation.setUseParentHandlers(false); Handler console = new ConsoleHandler(); console.setLevel(Level.FINER); consignation.addHandler(console); } @PostConstruct public void début(InvocationContext ctx) { try { consignation.info(+ctx.getTarget().getClass().getName()); ctx.proceed(); } catch(Exception ex) { Logger.global.info(); } } @PreDestroy public void fin(InvocationContext ctx) { try { ctx.proceed(); consignation.info(+ctx.getTarget().getClass().getName()+); } catch(Exception ex) { Logger.global.info(); } } }
Comme vous pouvez le constater dans ce code, les méthodes intercepteurs du cycle de vie prennent en paramètre un objet InvocationContext, renvoient un void au lieu d'Object (car, comme nous l'avons expliqué antérieurement, les méthodes de rappel du cycle de vie renvoient systématiquement un void) et ne peuvent pas lancer d'exception contrôlées.
Pour appliquer l'intercepteur précédent, le bean session doit utiliser l'annotation @Interceptors. Dans le code source suivant, Conversion précise qu'il s'agit de la classe CycleVie.
... @Singleton @Lock(LockType.READ) @Interceptors(CycleVie.class) public class Conversion implements ConversionRemote { ... @Override public double francEuro(double franc) { double euro = franc / TAUX; enregistrer(euro, franc); return euro; } @Override public double euroFranc(double euro) { double franc = euro * TAUX; enregistrer(euro, franc); return franc; } @PreDestroy private void enregistrer() { try { ObjectOutputStream fichier = new ObjectOutputStream(new FileOutputStream(nomFichier)); fichier.writeObject(stockage); fichier.close(); } catch (IOException ex) { } } @PostConstruct private void lire() { try { ObjectInputStream fichier = new ObjectInputStream(new FileInputStream(nomFichier)); stockage = (List<Calcul>) fichier.readObject(); fichier.close(); } catch (Exception ex) { } } }
Dès lors, quand l'EJB sera instancié par le conteneur, la méthode début() de l'intercepteur sera invoquée avant la méthode lire(). Les appels aux méthodes francEuro() et euroFranc() ne seront en revanche pas interceptés, mais la méthode enregistrer() de l'intercepteur sera appelée avant que l'instance de Conversion ne soit détruite par le conteneur.
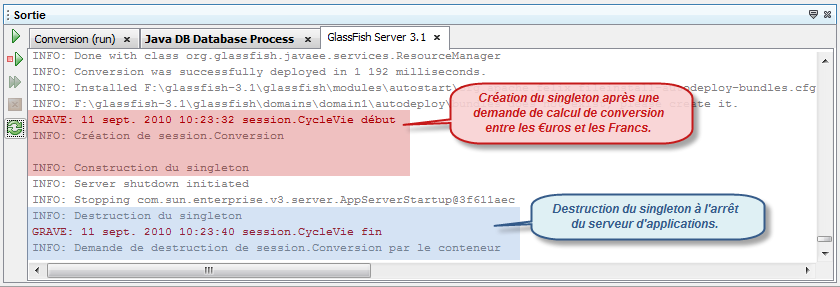
Les méthodes de rappel de cycle de vie et les méthodes @AroundInvoke peuvent être définies dans la même classe.
.
Nous venons de voir comment intercepter les appels dans un seul bean (avec @AroundInvoke) et entre plusieurs beans (avec @Interceptors). EJB 3.1 permet également de chaîner plusieurs intercepteurs et de définir des intercepteurs par défaut qui s'appliqueront à tous les beans session.
En fait, il est possible d'attacher plusieurs intercepteurs avec l'annotation @Interceptors en lui passant en paramètre une liste d'intercepteurs entre accolades, séparés par des virgules. En ce cas, l'ordre dans lequel ils seront invoqués est déterminé par leur ordre d'apparition dans cette liste.
@Singleton @Lock(LockType.READ) @Interceptors({Intercepteur1.class, Intercepteur2.class}) public class Conversion implements ConversionRemote { ... @Interceptors({Intercepteur3.class, Intercepteur4.class}) public double francEuro(double franc) { ... } public double euroFranc(double euro) { ... } @ExcludeClassInterceptors public void effacer() { ... } public Future<String> historique() { ... } private void enregistrer(double euro, double franc) { ... } private void enregistrer() { ... } private void lire() { ... } }
A titre d'exemple, nous pouvons reprendre l'étude sur le bean Conversion en proposant les deux intercepteurs mise en oeuvre précédemments, savoir Journal et CycleVie :
@Singleton @Lock(LockType.READ) @Interceptors({CycleVie.class, Journal.class}) public class Conversion implements ConversionRemote { ... }
Outre les intercepteurs au niveau des méthodes et des classes, EJB 3.1 permet de créer des intercepteurs par défaut, qui seront utilisés pour toutes les méthodes de tous les EJB d'une application.
<?xml version="1.0" encoding="UTF-8"?> <ejb-jar xmlns = "http://java.sun.com/xml/ns/javaee" version = "3.1" xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation = "http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/ejb-jar_3_1.xsd"> <assembly-descriptor> <interceptor-binding> <ejb-name>*</ejb-name> <interceptor-class>session.Journal</interceptor-class> </interceptor-binding> </assembly-descriptor> </ejb-jar>
Le caractère joker * dans l'élément <ejb-name> signifie que tous les EJB appliqueront l'intercepteur défini dans l'élément <interceptor-class>. Si vous déployez le bean Conversion avec cet intercepteur par défaut, le Journal sera invoqué avant tous les autres intercepteurs.
Si plusieurs types d'intercepteurs sont définis pour un même bean session, le conteneur les applique dans l'ordre décroissant des portées : le premier sera donc l'intercepteur par défaut et le dernier l'intercepteur de méthode.
Pour désactiver les intercepteurs par défaut pour un EJB spécifique, il suffit d'appliquer l'annotation @javax.interceptor.ExcludeDefaultInterceptors sur la classe ou sur les méthodes :
@Singleton @Lock(LockType.READ) @ExcludeDefaultInterceptors @Interceptors(CycleVie.class) public class Conversion implements ConversionRemote { ... public double francEuro(double franc) { ... } public double euroFranc(double euro) { ... } @ExcludeClassInterceptors public void effacer() { ... } public Future<String> historique() { ... } private void enregistrer(double euro, double franc) { ... } private void enregistrer() { ... } private void lire() { ... } }